论文_2015cvpr:FaceNet: A Unified Embedding for Face Recognition and Clustering
facenet代码使用方法解析:https://blog.csdn.net/u013044310/article/details/79556099
triplet loss 代码解析:https://blog.csdn.net/u011918382/article/details/79006782
三元组博客 :https://zhuanlan.zhihu.com/p/35560666
一、主要思想:
embedding映射关系:将特征从原来的特征空间映射到一个新的特征空间上,新的特征就称原来的特征嵌入,卷积末端全连接层输出为的特征映射到一个超球面上,使其特征二范数归一化。
通过 CNN人脸图像特征映射到欧式空间的特征向量上,计算不同图片人脸特征的距离,通过相同个体的人脸的距离,总是小于不同个体的人脸这一先验知识训练网络。测试时只需要计算人脸特征,然后计算距离使用阈值即可判定两张人脸照片是否属于相同的个体。识别:如每个人抽取512或者256维度,将维度上的值进行欧式距离计算,小于一个阈值则判定是同一个人,否者不是同一人。
亮点: embedding 嵌入层 特征提取 128 256 512 特征向量
triplet loss 用于粒度比较小的粒度。
二、网络结构:
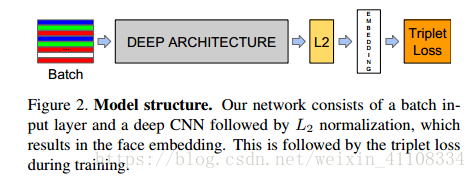
网络结构:传统的卷积神经网络,然后在求L2范数之前进行归一化,就建立了这个嵌入空间(512/256/128维),最后损失函数。
triplet loss 将嵌入层输出 例如:40postive 5个negative mini-batch 选出一个 hard 三元组 然后计算损失 反复 更新参数 更新 嵌入层embedding

三、triplet loss
1、三元组概念
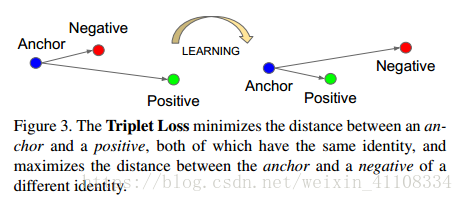
triplet loss 损失函数,用于训练差异性较小的样本
在有监督的机器学习领域,通常有固定的类别,这时就可以使用基于softmax的交叉熵损失函数进行训练。但有时,类别是一个变量,此时使用triplet loss就能解决问题。在人脸识别,Quora question pair任务中,triplet loss的优势在于细节区分,即当两个输入相似时,triplet loss能够更好地对细节进行建模,相当于加入了两个输入差异性差异的度量,学习到输入的更好表示,从而在上述两个任务中有出色的表现。当然,triplet loss的缺点在于其收敛速度慢,有时不收敛。
Triplet loss的motivation是要让属于同一个人的人脸尽可能地“近”(在embedding空间里),而与其他人脸尽可能地“远”。
anchor 为锚点 negative positive,经过learning使得离positive正 距离变小,negative负 距离变大,用于训练差异性较小的样本,
2、三元组定义
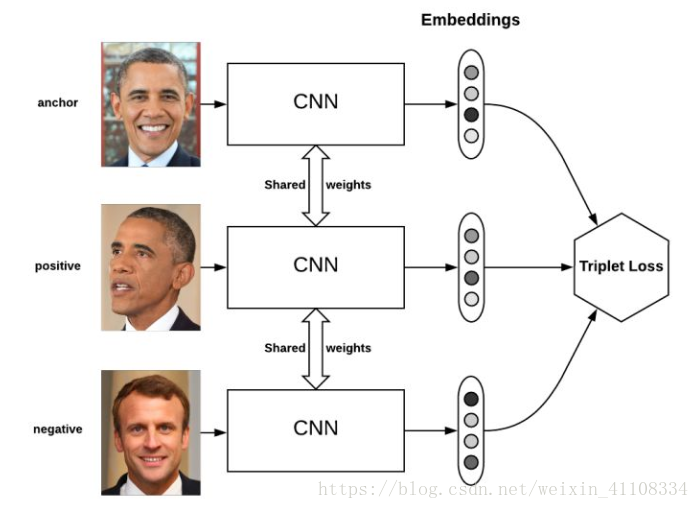
triplet loss的目标是:
两个具有同样标签的样本,他们在新的编码空间里距离很近。
两个具有不同标签的样本,他们在新的编码空间里距离很远。
进一步,我们希望两个positive examples和一个negative example中,negative example与positive example的距离,大于positive examples之间的距离,或者大于某一个阈值:margin。
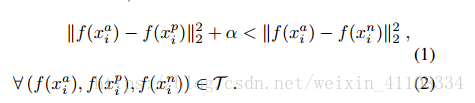
3、LOSS function

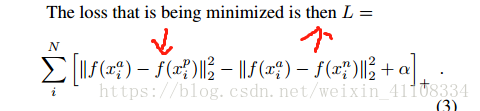
4、三元组分类 :
为了保证训练的收敛速度,选择距离最远的相同人像hard-positive,和最近的不同人像训练hard negative,在mini-batch中进行选择.

- easy triplets(简单三元组): triplet对应的损失为0的三元组,形式化定义为d(a,n)>d(a,p)+margin。
- hard triplets(困难三元组): negative example 与anchor距离小于anchor与positive example的距离,形式化定义为 d(a,n)<d(a,p)。
- semi-hard triplets(一般三元组): negative example 与anchor距离大于anchor与positive example的距离,但还不至于使得loss为0,即d(a,p)<d(a,n)<d(a,p)+margin。
上述三种概念都是基于negative example与anchor和positive距离定义的。类似的,可以根据上述定义将negative examples分为3类:hard negatives, easy negatives, semi-hard negatives。如下图所示,这个图构建了编码空间中三种negative examples与anchor和positive example之间的距离关系。

如何选择triplet或者negative examples,对模型的效率有很大影响。在上述Facenet论文中,采用了随机的semi-hard negative构建triplet进行训练,取得了不错的效果。
5、offline /online triplet mining
通过上面的分析,可以看到,easy negative example比较容易识别,没必要构建太多由easy negative example组成的triplet,否则会严重降低训练效率。若都采用hard negative example,又可能会影响训练效果。这时,就需要一定的方法进行triplet的挑选,也就是“mine the triplets”。
5.1 Offline triplet mining
离线方式的triplet mining将所有的训练数据喂给神经网络,得到每一个训练样本的编码,根据编码计算得到negative example与anchor和positive example之间的距离,根据这个距离判断semi-hard triplets,hard triplets还是easy triplets。offline triplet mining 仅仅选择select hard or semi-hard triplets,因为easy triplet太容易了,没有必要训练。
总得来说,这个方法不够高效,因为最初要把所有的训练数据喂给神经网络,而且每过1个或几个epoch,可能还要重新对negative examples进行分类。
5.2 Online triplet mining
Google的研究人员为解决上述问题,提出了online triplet mining的方法。该方法的motivation比较简单,将B张图片(一个batch)喂给神经网络,得到B张图片的embedding,将triplet的组合一共最多$B^3$个triplets,其中包含很多没用的triplet(比如,三个negative examples和三个positive examples,这种称作invalid triplets)。哪些是valid triplets呢?假设一个triplet$(B_i,B_j,B_k)$,如果样本i和j有相同的label且不是同一个样本,而样本k具有不同的label,则称其为valid triplet。
假设一个batch的数据包含P*K张人脸,P个人,每人K张图片。
针对valid triplet的“挑选”,有以下两个策略(来自论文[1703.07737] In Defense of the Triplet Loss for Person Re-Identification):
- batch all: 计算所有的valid triplet,对6hard 和 semi-hard triplets上的loss进行平均。
- 不考虑easy triplets,因为easy triplets的损失为0,平均会把整体损失缩小
- 将会产生PK(K-1)(PK-K)个triplet,即PK个anchor,对于每个anchor有k-1个可能的positive example,PK-K个可能的negative examples
- batch hard: 对于每一个anchor,选择hardest positive example(距离anchor最大的positive example)和hardest negative(距离anchor最小的negative example),
- 由此产生PK个triplet
- 这些triplet是最难分的
4. 那如何用tensorflow实现triplet loss呢?
4.1 offline triplets


4.2 online triplets
4.2.1 batch all的实现方式
- batch all: 计算所有的valid triplet,对6hard 和 semi-hard triplets上的loss进行平均。
- 不考虑easy triplets,因为easy triplets的损失为0,平均会把整体损失缩小
- 将会产生PK(K-1)(PK-K)个triplet,即PK个anchor,对于每个anchor有k-1个可能的positive example,PK-K个可能的negative examples
def batch_all_triplet_loss(labels, embeddings, margin, squared=False):
"""Build the triplet loss over a batch of embeddings.
We generate all the valid triplets and average the loss over the positive ones.
Args:
labels: labels of the batch, of size (batch_size,)
embeddings: tensor of shape (batch_size, embed_dim)
margin: margin for triplet loss
squared: Boolean. If true, output is the pairwise squared euclidean distance matrix.
If false, output is the pairwise euclidean distance matrix.
Returns:
triplet_loss: scalar tensor containing the triplet loss
"""
# Get the pairwise distance matrix
pairwise_dist = _pairwise_distances(embeddings, squared=squared)
anchor_positive_dist = tf.expand_dims(pairwise_dist, 2)
anchor_negative_dist = tf.expand_dims(pairwise_dist, 1)
# Compute a 3D tensor of size (batch_size, batch_size, batch_size)
# triplet_loss[i, j, k] will contain the triplet loss of anchor=i, positive=j, negative=k
# Uses broadcasting where the 1st argument has shape (batch_size, batch_size, 1)
# and the 2nd (batch_size, 1, batch_size)
triplet_loss = anchor_positive_dist - anchor_negative_dist + margin
# Put to zero the invalid triplets
# (where label(a) != label(p) or label(n) == label(a) or a == p)
mask = _get_triplet_mask(labels)
mask = tf.to_float(mask)
triplet_loss = tf.multiply(mask, triplet_loss)
# Remove negative losses (i.e. the easy triplets)
triplet_loss = tf.maximum(triplet_loss, 0.0)
# Count number of positive triplets (where triplet_loss > 0)
valid_triplets = tf.to_float(tf.greater(triplet_loss, 1e-16))
num_positive_triplets = tf.reduce_sum(valid_triplets)
num_valid_triplets = tf.reduce_sum(mask)
fraction_positive_triplets = num_positive_triplets / (num_valid_triplets + 1e-16)
# Get final mean triplet loss over the positive valid triplets
triplet_loss = tf.reduce_sum(triplet_loss) / (num_positive_triplets + 1e-16)
return triplet_loss, fraction_positive_triplets
4.2.2 batch hard的实现方式
- batch hard: 对于每一个anchor,选择hardest positive example(距离anchor最大的positive example)和hardest negative(距离anchor最小的negative example),
- 由此产生PK个triplet
- 这些triplet是最难分的
def batch_hard_triplet_loss(labels, embeddings, margin, squared=False):
"""Build the triplet loss over a batch of embeddings.
For each anchor, we get the hardest positive and hardest negative to form a triplet.
Args:
labels: labels of the batch, of size (batch_size,)
embeddings: tensor of shape (batch_size, embed_dim)
margin: margin for triplet loss
squared: Boolean. If true, output is the pairwise squared euclidean distance matrix.
If false, output is the pairwise euclidean distance matrix.
Returns:
triplet_loss: scalar tensor containing the triplet loss
"""
# Get the pairwise distance matrix
pairwise_dist = _pairwise_distances(embeddings, squared=squared)
# For each anchor, get the hardest positive
# First, we need to get a mask for every valid positive (they should have same label)
mask_anchor_positive = _get_anchor_positive_triplet_mask(labels)
mask_anchor_positive = tf.to_float(mask_anchor_positive)
# We put to 0 any element where (a, p) is not valid (valid if a != p and label(a) == label(p))
anchor_positive_dist = tf.multiply(mask_anchor_positive, pairwise_dist)
# shape (batch_size, 1)
hardest_positive_dist = tf.reduce_max(anchor_positive_dist, axis=1, keepdims=True)
# For each anchor, get the hardest negative
# First, we need to get a mask for every valid negative (they should have different labels)
mask_anchor_negative = _get_anchor_negative_triplet_mask(labels)
mask_anchor_negative = tf.to_float(mask_anchor_negative)
# We add the maximum value in each row to the invalid negatives (label(a) == label(n))
max_anchor_negative_dist = tf.reduce_max(pairwise_dist, axis=1, keepdims=True)
anchor_negative_dist = pairwise_dist + max_anchor_negative_dist * (1.0 - mask_anchor_negative)
# shape (batch_size,)
hardest_negative_dist = tf.reduce_min(anchor_negative_dist, axis=1, keepdims=True)
# Combine biggest d(a, p) and smallest d(a, n) into final triplet loss
triplet_loss = tf.maximum(hardest_positive_dist - hardest_negative_dist + margin, 0.0)
# Get final mean triplet loss
triplet_loss = tf.reduce_mean(triplet_loss)
return triplet_loss
在minist等数据集上的效果都是棒棒哒。
5. 总结
triplet loss的实现不是很简单,比较tricky的地方是如何计算embedding的距离,以及怎样识别并抛弃掉invalid和easy triplet。当然,如果您使用的是tensorflow,可以直接移步至[github repository](omoindrot/tensorflow-triplet-loss),有一份写好的triplet loss在等着你。。。
可能有人会有疑惑,siamese network, triplet network的输入都是成对的,或者triplet的三元组,怎么对一个样本进行分类啊?神经网络的优势在于表示学习,自动的特征提取,所以,成对或者triplet的输入能让神经网络学到输入的更好的表示,后面再接svm, logtistic regression就可以啦。