论文名称:Learning Transferable Architectures for Scalable Image Recognition
论文下载:https://arxiv.org/abs/1707.07012
论文年份:2018
论文被引:4092(2022/05/16)
论文代码:https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/nasnet.py#L562
论文总结
本文基于 Neural architecture search with rein- forcement learning 提出的强化学习NAS框架,搜索CNN架构,设计一个搜索空间,将架构的复杂性与网络的深度分离,搜索到的最佳模型架构称为 NASNet。NASNet先在小数据集 Cifar-10 图像分类任务上搜索,然后将搜索到的模型迁移到大数据集ImageNet上。作者使用500块K40 GPU训练了2000个小时。。。GPU成本2000万,打扰了。。。
此外,还提出了一种在 NASNet 有效正则化方法 Scheduled Drop Path,其是 DropPath [33] 的修改版本。
Abstract
Developing neural network image classification models often requires significant architecture engineering. In this paper, we study a method to learn the model architectures directly on the dataset of interest. As this approach is expensive when the dataset is large, we propose to search for an architectural building block on a small dataset and then transfer the block to a larger dataset. The key contribution of this work is the design of a new search space (which we call the “NASNet search space”) which enables transferability. In our experiments, we search for the best convolutional layer (or “cell”) on the CIFAR-10 dataset and then apply this cell to the ImageNet dataset by stacking together more copies of this cell, each with their own parameters to design a convolutional architecture, which we name a “NASNet architecture”. We also introduce a new regularization technique called ScheduledDropPath that significantly improves generalization in the NASNet models. On CIFAR-10 itself, a NASNet found by our method achieves 2.4% error rate, which is state-of-the-art. Although the cell is not searched for directly on ImageNet, a NASNet constructed from the best cell achieves, among the published works, state-of-the-art accuracy of 82.7% top-1 and 96.2% top-5 on ImageNet. Our model is 1.2% better in top-1 accuracy than the best human-invented architectures while having 9 billion fewer FLOPS – a reduction of 28% in computational demand from the previous state-of-the-art model. When evaluated at different levels of computational cost, accuracies of NASNets exceed those of the state-of-the-art human-designed models. For instance, a small version of NASNet also achieves 74% top-1 accuracy, which is 3.1% better than equivalently-sized, state-of-the-art models for mobile platforms. Finally, the image features learned from image classification are generically useful and can be transferred to other computer vision problems. On the task of object detection, the learned features by NASNet used with the Faster-RCNN framework surpass state-of-the-art by 4.0% achieving 43.1% mAP on the COCO dataset.
开发神经网络图像分类模型通常需要大量的架构工程。在本文中,我们研究了一种直接在感兴趣的数据集上学习模型架构的方法。由于当数据集很大时这种方法成本很高,建议在小数据集上搜索架构构建块,然后将块迁移到更大的数据集。这项工作的主要贡献是设计了一个新的搜索空间(称之为“NASNet 搜索空间”),它可以实现可迁移性 (transferability)。在我们的实验中,我们在 CIFAR-10 数据集上搜索最佳卷积层(或“单元”),然后通过将多个该单元的副本进行堆叠,将这个单元应用于 ImageNet 数据集,每个副本都有自己的参数来设计卷积架构,将其命名为“NASNet 架构”。我们还引入了一种称为 Scheduled Drop Path 的新正则化技术,它显着提高了 NASNet 模型的泛化能力。在 CIFAR-10 本身上,我们的方法找到的 NASNet 达到了 2.4% 的错误率,这是最先进的。尽管没有直接在 ImageNet 上搜索单元,但由最佳单元构建的 NASNet 在已发表的作品中实现了 ImageNet 上 82.7% top-1 和 96.2% top-5 的最新准确率。我们的模型在 top-1 准确度上比最好的人工发明架构高 1.2%,同时减少了 90 亿次 FLOPS——与之前最先进的模型相比,计算需求减少了 28%。当以不同的计算成本水平进行评估时,NASNets 的准确性超过了最先进的人工设计模型。例如,一个小版本的 NASNet 也达到了 74% 的 top-1 准确率,比同等大小的最先进的移动平台模型高 3.1%。最后,从图像分类中学习到的图像特征通常是有用的,可以迁移到其他计算机视觉问题。在目标检测任务中,NASNet 与 Faster-RCNN 框架一起使用的学习特征超过了现有技术 4.0%,在 COCO 数据集上实现了 43.1% 的 mAP。
1. Introduction
开发神经网络图像分类模型通常需要大量的架构工程。从 [32] 关于使用卷积架构 [17, 34] 进行 ImageNet [11] 分类的开创性工作开始,通过架构工程的连续进步取得了令人印象深刻的成果 [53, 59, 20, 60, 58, 68]。
在本文中,我们研究了一种设计卷积架构的新范例,并描述了一种可扩展的方法来优化感兴趣的数据集上的卷积架构,例如 ImageNet 分类数据集。我们的方法受到最近提出的神经架构搜索(NAS)框架 [71] 的启发,该框架使用强化学习搜索方法来优化架构配置。然而,将 NAS 或任何其他搜索方法直接应用于大型数据集(例如 ImageNet 数据集)的计算成本很高。因此,我们建议在代理数据集上搜索一个好的架构,例如较小的 CIFAR-10 数据集,然后将学习到的架构迁移到 ImageNet。我们通过设计一个搜索空间(“NASNet 搜索空间”)来实现这种可迁移性,这样架构的复杂性就与网络的深度和输入图像的大小无关。更具体地说,我们搜索空间中的所有卷积网络都由具有相同结构但权重不同的卷积层 (or “cells”) 组成。因此,搜索最佳卷积架构被简化为搜索最佳单元结构。搜索最佳单元结构有两个主要好处:它比搜索整个网络架构要快得多,并且单元本身更可能泛化到其他问题。在我们的实验中,这种方法显着加速了使用 CIFAR-10 搜索最佳架构的 7 倍,并学习了成功迁移到 ImageNet 的架构。
我们的主要结果是,在 CIFAR-10 上找到的最佳架构(称为 NASNet)在迁移到 ImageNet 分类时无需太多修改即可实现最先进的准确度。在 ImageNet 上,NASNet 在已发表的作品中达到了 82.7% top-1 和 96.2% top-5 的最新准确率。与人类发明的最佳架构相比,这一结果相当于 top-1 准确度提高了 1.2%,同时 FLOPS 减少了 90 亿。在 CIFAR-10 本身上,NASNet 达到了 2.4% 的错误率,这也是最先进的。
此外,通过简单地改变卷积单元的数量和卷积单元中滤波器的数量,我们可以创建具有不同计算需求的不同版本的 NASNet。由于单元 (cells) 的这种特性,可以生成一系列模型,这些模型在同等或更小的计算预算下实现了优于所有人类发明模型的精度 [60, 29]。值得注意的是,最小版本的 NASNet 在 ImageNet 上实现了 74.0% 的 top-1 准确率,比以前针对移动和嵌入式视觉任务的设计架构高 3.1% [24, 70]。
最后,我们表明 NASNets 学习到的图像特征通常是有用的,并且可以迁移到其他计算机视觉问题。在我们的实验中,NASNets 从 ImageNet 分类中学习到的特征可以与 Faster-RCNN 框架 [47] 相结合,为最大模型和移动优化模型实现最先进的 COCO 对象检测任务。我们最大的 NASNet 模型实现了 43.1% 的 mAP,比之前的最先进模型提高了 4%。
2. Related Work
所提出的方法与之前在超参数优化方面的工作有关 [44, 4, 5, 54, 55, 6, 40]。特别是最近设计架构的方法,如Neural Fabrics [48]、DiffRNN [41]、MetaQNN [3]和 DeepArchitect [43]。用于设计架构的更灵活的一类方法是进化算法 [65, 16, 57, 30, 46, 42, 67],但它们在大规模上并没有取得那么大的成功。 Xie 和 Yuille [67] 也将学习架构从 CIFAR-10 迁移到 ImageNet,但这些模型的性能(top-1 准确率 72.1%)明显低于以前的最新技术(表 2)。

让一个神经网络与第二个神经网络交互以帮助学习过程,或学习学习 ( learning to learn) 或元学习 (meta-learning) [23, 49] 的概念近年来引起了很多关注 [1, 62, 14, 19, 35, 45, 15]。这些方法中的大多数还没有扩展到像 ImageNet 这样的大问题。一个例外是最近专注于学习 ImageNet 分类优化器的工作,该工作取得了显着的改进 [64]。
我们的搜索空间的设计从 LSTM [22] 和神经架构搜索单元 [71] 中汲取了很多灵感。卷积单元的模块化结构也与 ImageNet 上的先前方法有关,例如 VGG [53],Inception [59, 60, 58],ResNet/ResNext [20, 68] 和 Xception/MobileNet [9, 24]。
3. Method
我们的工作利用搜索方法在感兴趣的数据集上找到好的卷积架构。我们在这项工作中使用的主要搜索方法是 [71] 提出的神经架构搜索(NAS)框架。在 NAS 中,控制器循环神经网络 (RNN) 对具有不同架构的子网络进行采样。子网络经过训练以收敛,以在保留的验证集上获得一定的准确性。产生的精度用于更新控制器,以便控制器随着时间的推移生成更好的架构。控制器权重使用策略梯度进行更新(参见图 1)。
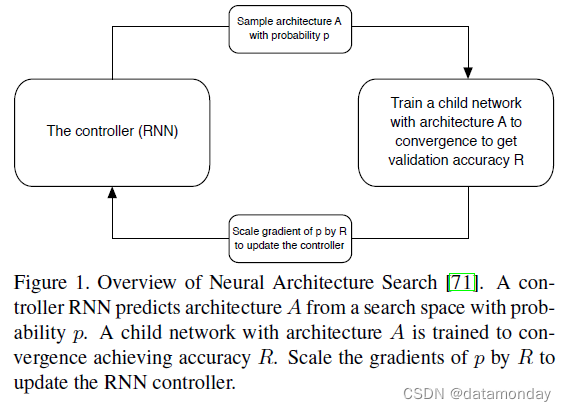
这项工作的主要贡献是设计了一个新颖的搜索空间,这样在 CIFAR-10 数据集上找到的最佳架构将在一系列计算设置中扩展到更大、更高分辨率的图像数据集。我们将此搜索空间命名为 NASNet 搜索空间,因为它产生了 NASNet,这是实验中发现的最佳架构。 NASNet 搜索空间的一个灵感是认识到 CNN 架构通常是由卷积滤波器组、非线性和谨慎选择连接组成的重复架构,以实现最先进的结果(例如重复模块存在于 Inception 和 ResNet 模型中 [59, 20, 60, 58])。这些观察表明,控制器 RNN 有可能预测用上述动机表示的通用卷积单元。然后可以将该单元串联堆叠以处理任意空间维度和滤波器深度的输入。
在我们的方法中,卷积网络的整体架构是手动预先确定的。它们由重复多次的卷积单元组成,每个卷积单元具有相同的架构,但权重不同。为了轻松地为任何大小的图像构建可扩展的架构,我们需要两种类型的卷积单元在将特征图作为输入时提供两个主要功能:
-
1)返回相同维度的特征图的卷积单元——Normal Cell (常规单元)
-
2)返回特征图的卷积单元——Reduction Cell (缩减单元),其中特征图的高度和宽度减少了两倍
对于 Reduction 单元,令应用于单元格输入的初始操作的步长为 2,以减小高度和宽度。我们考虑构建卷积单元的所有操作都可以选择跨步。
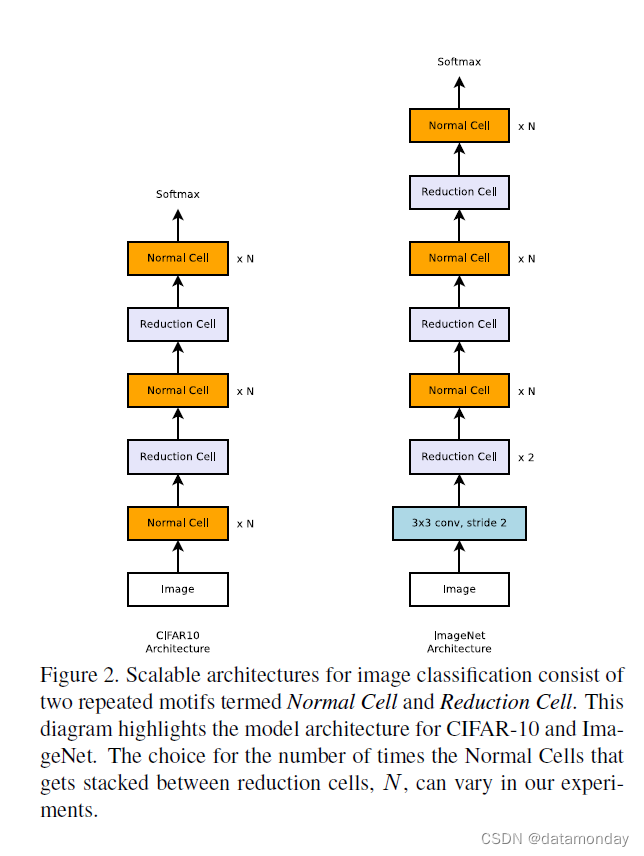
图 2 显示了我们为 CIFAR-10 和 ImageNet 放置的 Normal 和 Reduction Cell。在 ImageNet 上有更多的 Reduction Cells,因为传入的图像大小为 299x299,而 CIFAR 为 32x32。 Reduction 和 Normal Cell 可以具有相同的架构,但我们凭经验发现学习两种不同的架构是有益的。每当空间激活大小减小时,我们使用一种常见的启发式方法将输出中的滤波器数量加倍,以保持大致恒定的隐藏状态维度 [32, 53]。重要的是,与 Inception 和 ResNet 模型 [59, 20, 60, 58] 非常相似,我们将动机重复次数 (motif repetitions) N 和初始卷积滤波器的数量,视为我们根据图像分类问题的规模定制的自由参数。
动机重复次数 (motif repetitions):即本章第二段提到的,CNN 架构通常是由卷积滤波器组、非线性和谨慎选择连接组成的重复架构。
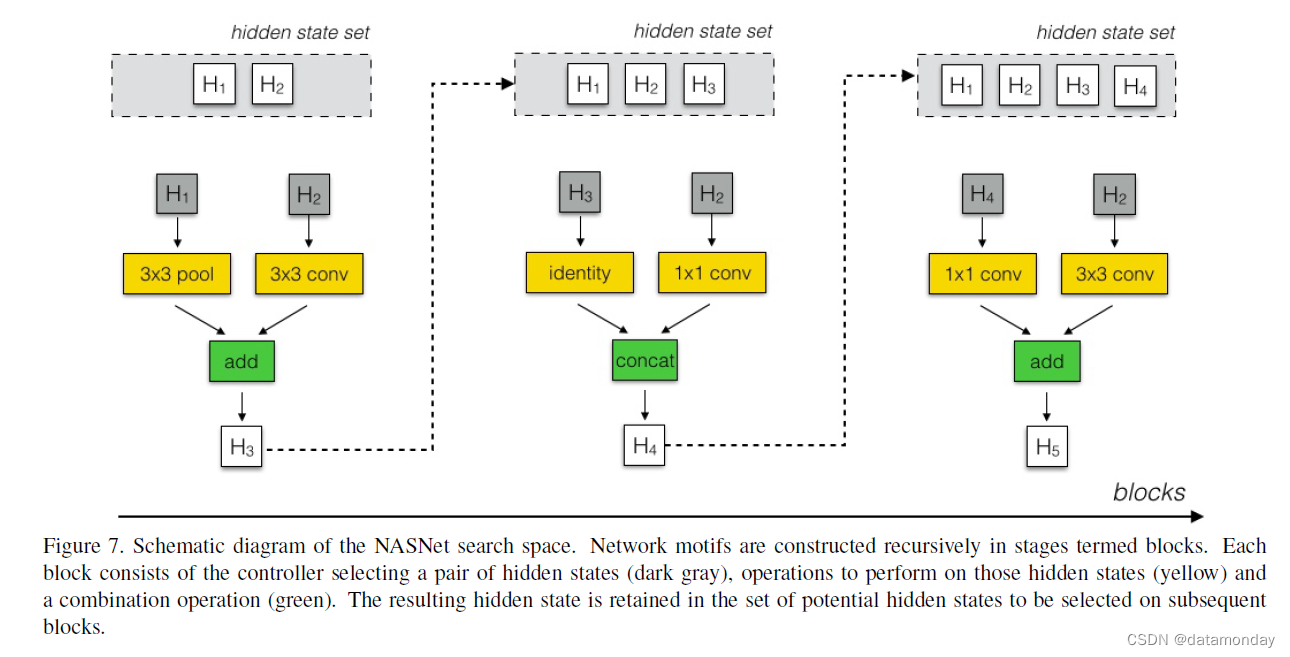
卷积网络中变化的是正常和缩减单元的结构,它们由控制器 RNN 搜索。可以在如下定义的搜索空间内搜索单元的结构(参见附录,图 7 的示意图)。在我们的搜索空间中,每个单元接收两个初始隐藏状态 hi 和 hi-1 作为输入,它们是前两个较低层或输入图像中的两个单元的输出。给定这两个初始隐藏状态,控制器 RNN 递归地预测卷积单元的其余结构(图 3)。控制器对每个单元的预测分为 B 个块,其中每个块有 5 个预测步骤,由 5 个不同的 softmax 分类器进行,对应于块元素的离散选择:
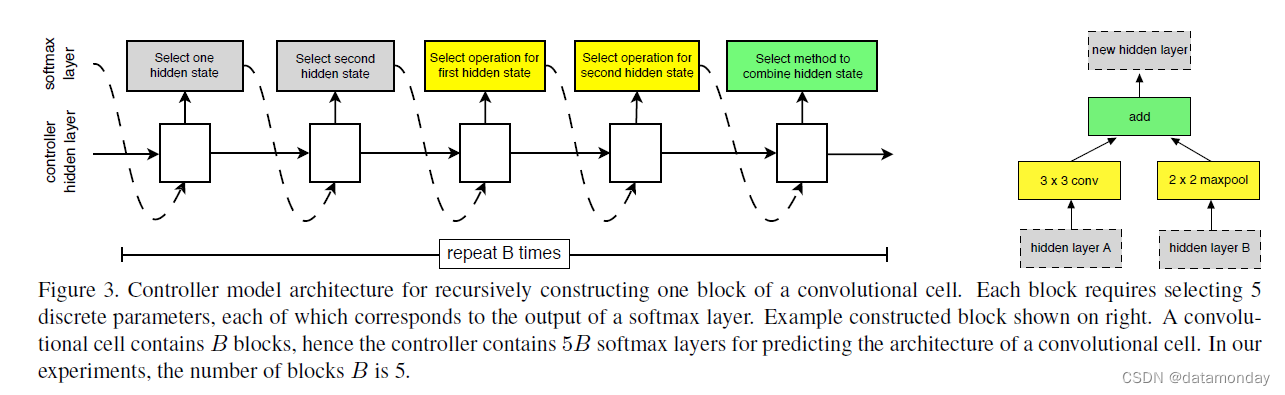
- 步骤 1:从 hi、hi-1 或从先前块中创建的隐藏状态集中选择隐藏状态。
- 步骤 2:从与步骤 1 相同的选项中选择第二个隐藏状态。
- 步骤 3:选择一个操作以应用于在步骤 1 中选择的隐藏状态。
- 步骤 4:选择一个操作以应用于在步骤 2 中选择的隐藏状态。
- 步骤 5:选择一种方法来组合步骤 3 和 4 的输出以创建新的隐藏状态。
该算法将新创建的隐藏状态附加到现有隐藏状态集合中,作为后续块中的潜在输入。控制器 RNN 将上述 5 个预测步骤重复 B 次,对应于卷积单元中的 B 个块。在我们的实验中,选择 B = 5 提供了很好的结果,尽管由于计算限制我们没有详尽地搜索这个空间。
在步骤 3 和 4 中,控制器 RNN 选择一个操作以应用于隐藏状态。我们根据它们在 CNN 文献中的普遍性收集了以下一组操作:
- identity
- 1x3 then 3x1 convolution
- 1x7 then 7x1 convolution
- 3x3 dilated convolution
- 3x3 average pooling
- 3x3 max pooling
- 5x5 max pooling
- 7x7 max pooling
- 1x1 convolution
- 3x3 convolution
- 3x3 depthwise-separable conv
- 5x5 depthwise-seperable conv
- 7x7 depthwise-separable conv
在步骤 5 中,控制器 RNN 选择一种方法来组合两个隐藏状态,或者(1)两个隐藏状态之间的元素相加或(2)两个隐藏状态之间沿着滤波器维度的连接。最后,将卷积单元中生成的所有未使用的隐藏状态深度连接在一起,以提供最终的单元输出。
为了让控制器 RNN 预测 Normal Cell 和 Reduction Cell,我们简单地让控制器总共有 2 × 5B 个预测,其中第一个 5B 预测是针对 Normal Cell 而第二个 5B 预测是针对 Reduction Cell。
最后,我们的工作利用了 NAS [71] 中的强化学习建议;但是,也可以使用随机搜索来搜索 NASNet 搜索空间中的架构。在随机搜索中,我们可以从均匀分布中采样决策,而不是从控制器 RNN 中的 softmax 分类器中采样决策。在我们的实验中,我们发现随机搜索比 CIFAR10 数据集上的强化学习略差。尽管使用强化学习是有价值的,但差距比 [71] 的原始工作中发现的要小。该结果表明 1) NASNet 搜索空间构造良好,因此随机搜索可以相当好地执行,并且 2) 随机搜索是一个难以击败的基线。我们将在 4.4 节比较强化学习和随机搜索。
4. Experiments and Results
在本节中,我们将使用上述方法描述我们的实验来学习卷积单元。总之,所有架构搜索都是使用 CIFAR-10 分类任务 [31] 执行的。控制器 RNN 使用近端策略优化 (Proximal Policy Optimization, PPO) [51] 通过使用全局工作队列系统来生成由 RNN 控制的子网络池进行训练。在我们的实验中,工作队列中的工作 (worker) 池由 500 个 GPU 组成。
这个搜索过程超过 4 天的结果产生了几个候选卷积单元。我们注意到,这个搜索过程比以前的方法 [71] 需要 28 天快 7 倍。1 此外,我们在下面证明了由此产生的架构在准确性上更优越。
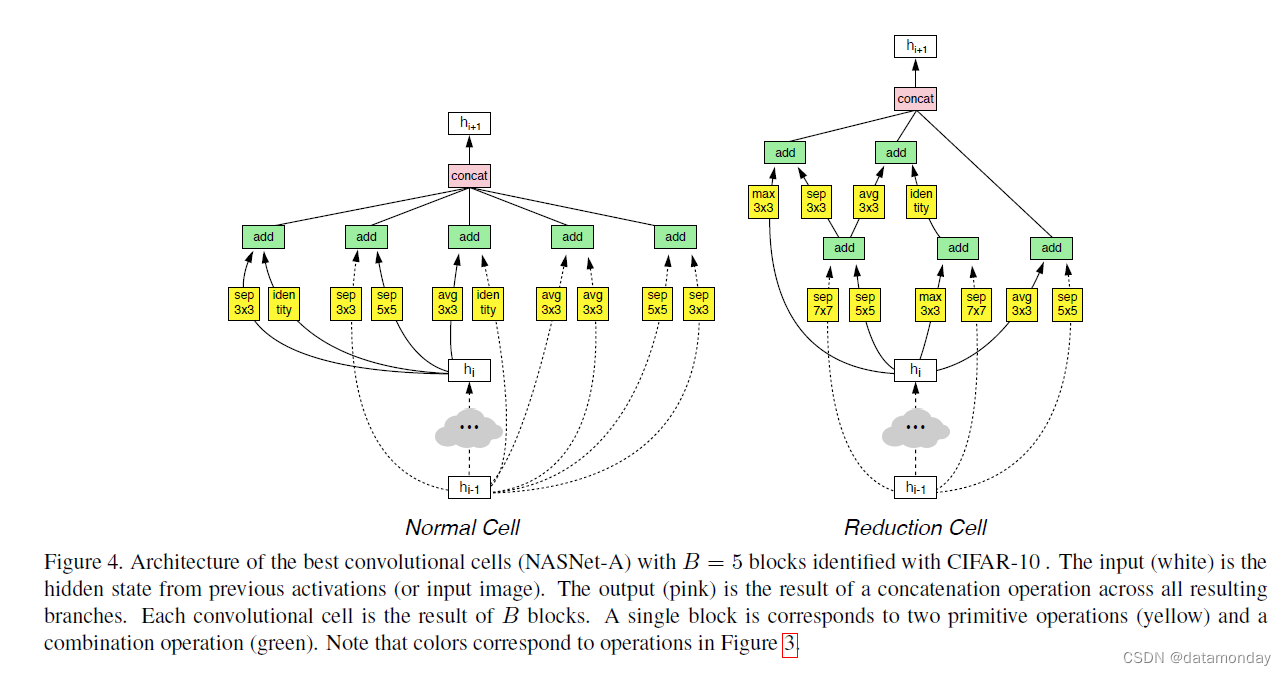
图 4. 使用 CIFAR-10 识别的 B = 5 个块的最佳卷积单元 (NASNet-A) 的架构。输入(白色)是来自先前激活(或输入图像)的隐藏状态。输出(粉红色)是跨所有结果分支的串联操作的结果。每个卷积单元是 B 个块的结果。单个块对应于两个原始操作(黄色)和一个组合操作(绿色)。请注意,颜色对应于图 3 中的操作。
图 4 显示了性能最佳的 Normal 单元和 Reduction 单元的图表。请注意与竞争架构相比,可分离卷积的普遍性和分支数量 [53, 59, 20, 60, 58]。随后的实验集中在这种卷积单元架构上,尽管我们检查了 ImageNet 实验中其他排名靠前的卷积单元的功效(在附录 B 中描述)并报告了它们的结果。我们将由最佳的三个搜索构建的三个网络称为 NASNetA、NASNet-B 和 NASNet-C。
我们通过在 CIFAR-10 和一系列 ImageNet 分类任务上使用这种学习架构来展示卷积单元的实用性。后一类任务在计算预算的几个数量级上进行了探索。在学习了卷积单元之后,可以探索几个超参数来为给定任务构建最终网络:
-
1)单元重复数 N
-
2)初始卷积单元中的滤波器数量
在选择了初始滤波器的数量后,我们使用常见的启发式方法在步长为 2 时将滤波器的数量加倍。最后,我们定义一个简单的符号,例如 4 @ 64,来表示所有网络中的这两个参数,其中 4 和 64 分别表示网络倒数第二层的单元重复次数和滤波器数量。
有关架构学习算法和控制器系统的完整详细信息,请参阅附录 A。重要的是,在训练 NASNet 时,我们发现 ScheduledDropPath,DropPath [33] 的修改版本,是 NASNet 的有效正则化方法。在 DropPath [33] 中,单元格中的每条路径在训练期间以某个固定概率随机丢弃。在我们的修改版本 ScheduledDropPath 中,单元格中的每条路径都以在训练过程中线性增加的概率被丢弃。我们发现 DropPath 不适用于 NASNets,而 ScheduledDropPath 在 CIFAR 和 ImageNet 实验中显着提高了 NASNets 的最终性能。
4.1. Results on CIFAR-10 Image Classification
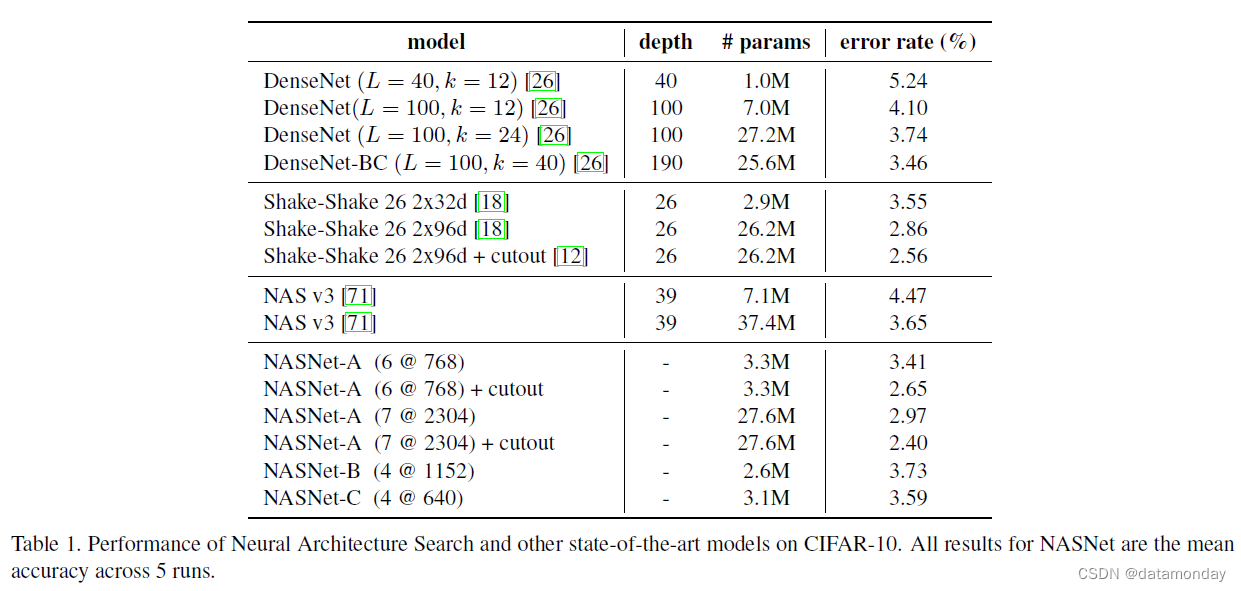
对于使用 CIFAR-10 进行图像分类的任务,我们设置 N = 4 或 6(图 2)。表 1 中报告了最佳架构的测试精度以及其他最先进的模型。从表中可以看出,具有剪切数据增强的大型 NASNet-A 模型 [12] 实现了 2.40% 的最新错误率(5 次运行的平均值),略好于之前的最佳[12] 记录的 2.56%。我们模型的最佳单次运行达到 2.19% 的错误率。
4.2. Results on ImageNet Image Classification
我们使用从 CIFAR-10 中学习到的最佳卷积单元在 ImageNet 上进行了几组实验。我们强调,我们只是从 CIFAR-10 迁移架构,而是从头开始训练所有 ImageNet 模型的权重。
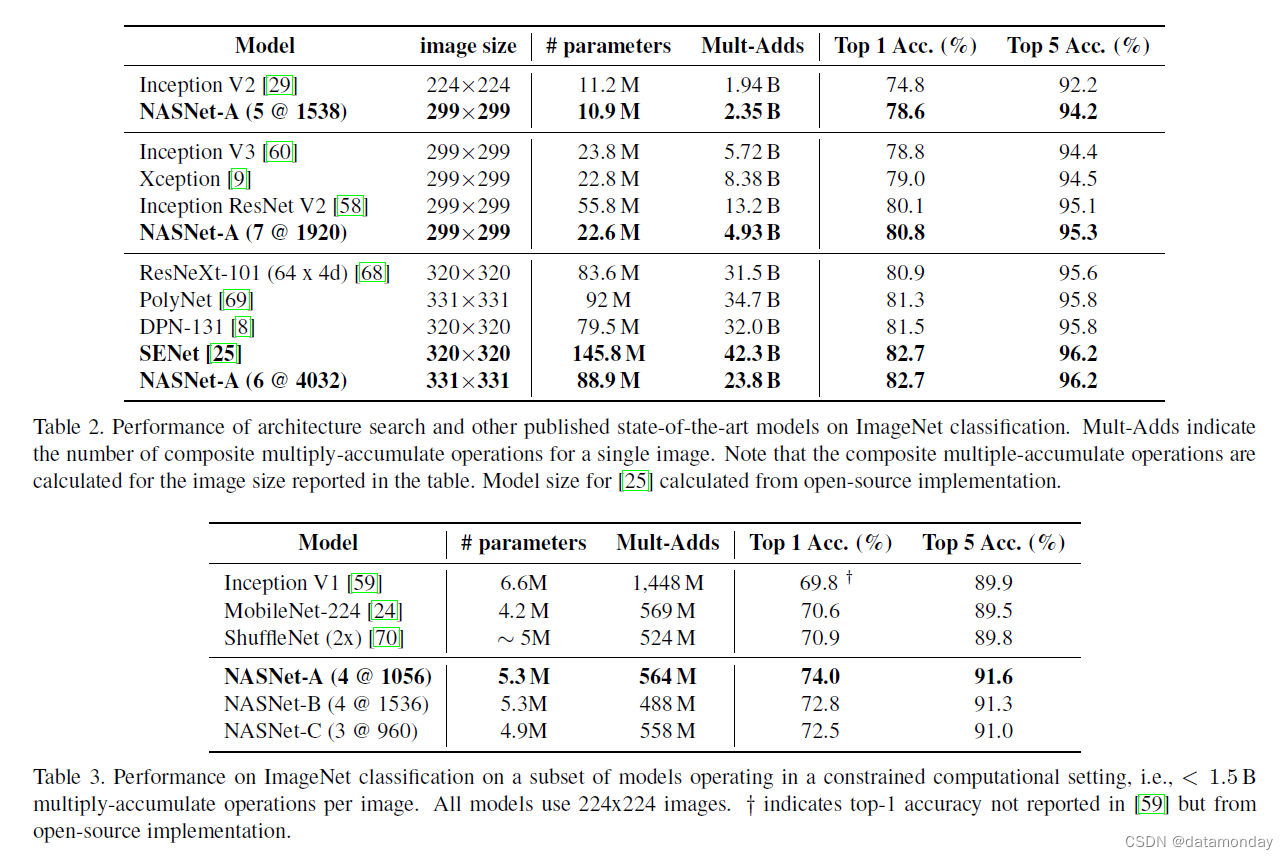
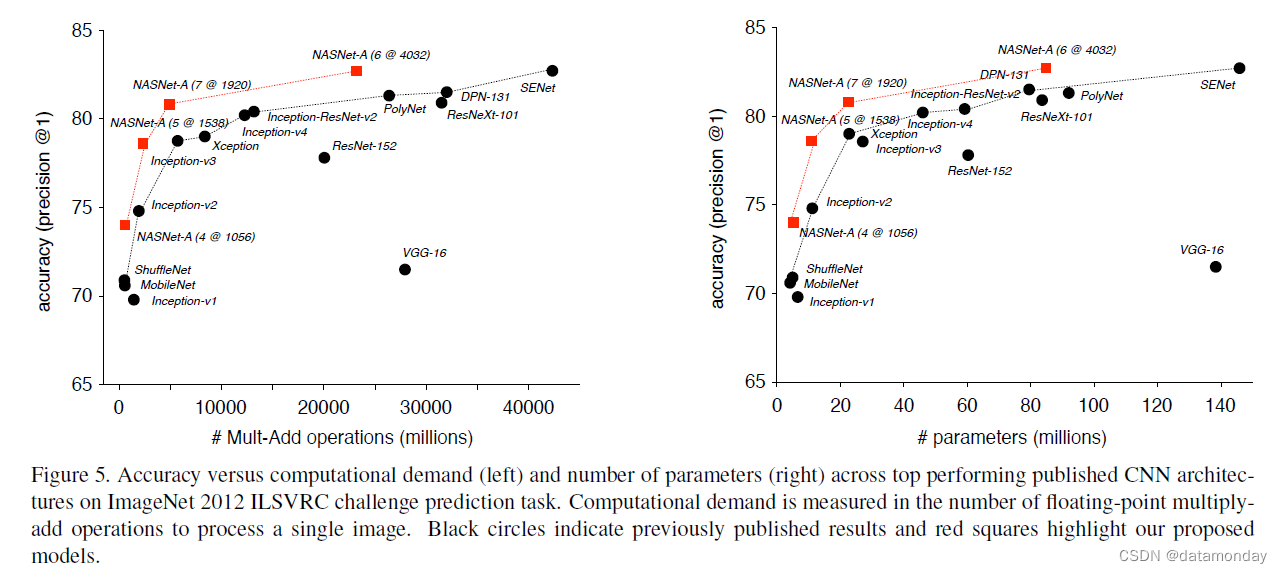
结果总结在表 2、3 和图 5 中。在第一组实验中,我们训练了几个在 299x299 或 331x331 分辨率图像上运行的图像分类系统,并根据计算需求进行了不同的实验,以创建计算成本大致相当的模型使用 Inception-v2 [29]、Inception-v3 [60] 和 PolyNet [69]。我们表明,与同类架构相比,这一系列模型以更少的浮点运算和参数实现了最先进的性能。其次,我们证明,通过调整模型的规模,我们可以在更小的计算预算下实现最先进的性能,超过为这种操作机制手动设计的流线型 CNN [24, 70]。
请注意,我们在卷积单元之间没有剩余连接,因为模型自己学习跳过连接。我们凭经验发现在单元之间手动插入残差连接无助于提高性能。我们在 ImageNet 上的训练设置类似于 [60],但请参阅附录 A 了解详细信息。
表 2 显示使用 CIFAR-10 发现的卷积单元很好地概括了 ImageNet 问题。特别是,每个基于卷积单元的模型都超过了相应手工设计模型的预测性能。重要的是,最大的模型基于单一的非集成预测为 ImageNet(82.7%)实现了新的最先进的性能,超过了之前发表的最佳结果 ∼1.2% [8]。在未发表的作品中,我们的模型与 82.7% [25] 的最佳报告结果相当,同时浮点运算明显减少。图 5 显示了我们的结果与其他已发表结果的比较的完整摘要。请注意,基于卷积单元的模型系列为人类发明的一大类架构提供了一个包络。
最后,我们测试了最佳卷积单元在资源受限的环境(例如移动设备)中的性能(表 3)。在这些设置中,浮点运算的数量受到严格限制,并且预测性能必须与计算资源有限的设备上的延迟要求进行权衡。 MobileNet [24] 和 ShuffleNet [70] 提供了最先进的结果,分别在 224x224 图像上使用 ∼550M 乘加操作获得了 70.6% 和 70.9% 的准确率。由最好的卷积单元构建的架构实现了优于以前模型的卓越预测性能(74.0% 准确度),但具有可比的计算需求。总之,我们发现学习的卷积单元在模型尺度上是灵活的,在计算预算中实现了近 2 个数量级的最先进性能。
4.3. Improved features for object detection
图像分类网络提供通用图像特征,可以迁移到其他计算机视觉问题 [13]。最重要的问题之一是图像中对象的空间定位。为了进一步验证 NASNet-A 网络系列的性能,我们测试了源自 NASNet-A 的对象检测系统是否会导致对象检测的改进 [28]。
为了解决这个问题,我们使用开源软件平台 [28] 将在 ImageNet 上预训练的 NASNet-A 网络系列插入 Faster-RCNN 对象检测管道 [47]。我们在组合 COCO 训练和验证数据集(不包括 8,000 个小型验证图像)上重新训练生成的对象检测管道。
我们使用每张图像 300-500 个 RPN 提议执行单一模型评估。换句话说,我们只通过单个网络传递单个图像。我们在 COCO mini-val [28] 和 test-dev 数据集上评估模型,并报告使用标准 COCO 度量库 [38] 计算的平均精度 (mAP)。我们对学习率计划进行简单搜索,以确定可能的最佳模型。最后,我们使用性能最佳的 NASNetA 图像特征化 (NASNet-A, 6 @ 4032) 以及面向移动平台的图像特征化 (NASNet-A, 4 @ 1056) 来检查两个对象检测系统的行为。
对于移动优化网络,我们得到的系统实现了 29.6% 的 mAP——超过了以前使用 Faster-RCNN 的移动优化网络 5.0% 以上(表 4)。对于最佳 NASNet 网络,我们在相同空间分辨率 (800 × 800) 的图像上运行的结果网络实现了 mAP = 40.7%,比基于性能较差的图像特征化(即 Inception-ResNet-v2)的等效对象检测系统高出 4.0% [28, 52](有关图像检测和并排比较的示例,请参见附录)。最后,增加输入图像的空间分辨率导致报告的最佳目标检测的单一模型结果为 43.1%,超过了之前最好的 4.0% 以上 [37]。2 这些结果进一步证明 NASNet 提供了优越的,可以跨其他计算机视觉任务传输的通用图像特征。附录 C 中的图 10 和图 11 显示了 NASNet-A 使用 Faster-RCNN 框架产生的对象检测结果的四个示例。
4.4. Efficiency of architecture search methods
虽然使用什么搜索方法不是本文的重点,但一个悬而未决的问题是强化学习搜索方法的效果如何。在本节中,我们研究强化学习在 CIFAR-10 图像分类问题上的架构搜索的有效性,并将其与暴力随机搜索(被认为是黑盒优化 [5] 的一个非常强大的基线)进行比较,给定一个等量的计算资源。
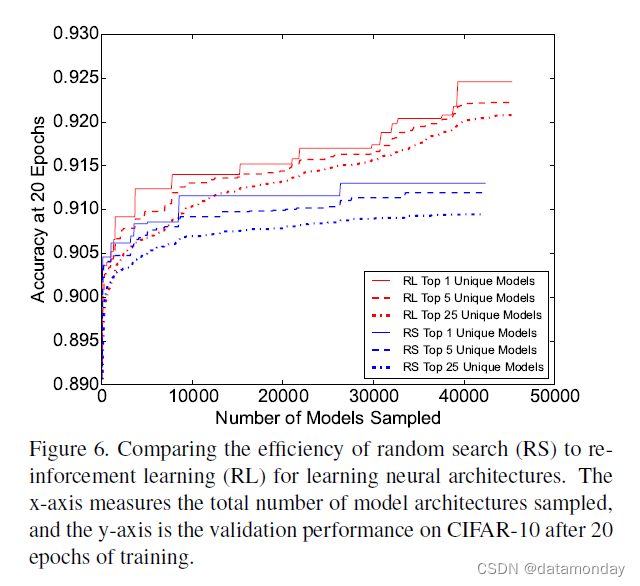
图 6 显示了强化学习 (RL) 和随机搜索 (RS) 在对更多模型架构进行采样时的性能。请注意,根据 CIFAR-10 的测量,使用 RL 确定的最佳模型明显优于 RS 找到的最佳模型超过 1%。此外,RL 发现了一系列质量优于随机搜索的模型。我们在 RL 与 RS 中确定的 top-5 和 top-25 模型的平均性能中观察到了这一点。我们将这些结果表明,尽管 RS 可能提供可行的搜索策略,但 RL 在 NASNet 搜索空间中找到了更好的架构。
5. Conclusion
在这项工作中,我们展示了如何从传输到多个图像分类任务的数据中学习可扩展的卷积单元。学习到的架构非常灵活,因为它可以根据计算成本和参数进行扩展,以轻松解决各种问题。在所有情况下,生成的模型的准确性都超过了所有人工设计的模型——从为移动应用程序设计的模型到旨在实现最准确结果的计算量大的模型。
我们方法的关键见解是设计一个搜索空间,将架构的复杂性与网络的深度分离。由此产生的搜索空间允许在小数据集(即 CIFAR-10)上识别良好的架构,并将学习的架构迁移到一系列数据和计算规模的图像分类。
由此产生的架构在 CIFAR-10 和 ImageNet 数据集中的性能接近或超过最先进的性能,而计算需求低于人工设计的架构 [60, 29, 69]。 ImageNet 结果特别重要,因为许多最先进的计算机视觉问题(例如,对象检测 [28]、人脸检测 [50]、图像定位 [63])从 ImageNet 分类模型中派生出图像特征或架构。例如,我们发现从 ImageNet 获得的图像特征与 Faster RCNN 框架结合使用可以实现最先进的目标检测结果。最后,我们证明了我们可以使用由此产生的学习架构来执行 ImageNet 分类,同时减少计算预算,其性能优于针对移动和嵌入式平台的流线型架构 [24, 70]。
A. Experimental Details
A.1. Dataset for Architecture Search
CIFAR-10 数据集 [31] 包含 10 个类别的 60,000 个 32x32 RGB 图像(50,000 个训练图像和 10,000 个测试图像)。我们从训练集中划分出 5,000 张图像的随机子集,用作控制器 RNN 的验证集。所有图像都被白化,然后经过几个数据增强步骤:我们从 40x40 大小的上采样图像中随机裁剪 32x32 块并应用随机水平翻转。这种数据增强过程在相关工作中很常见。
A.2. Controller architecture
控制器 RNN 是一个单层 LSTM [22],每层有 100 个隐藏单元,对与每个架构决策相关的两个卷积单元(其中 B 通常为 5)进行 2×5B 的 softmax 预测。控制器 RNN 的 10B 个预测中的每一个都与一个概率相关联。子网络的联合概率是这 10B 个 softmax 处所有概率的乘积。该联合概率用于计算控制器 RNN 的梯度。梯度由子网络的验证准确度缩放,以更新控制器 RNN,使得控制器为坏子网络分配低概率,为好子网络分配高概率。
与使用 REINFORCE 规则 [66] 更新控制器的 [71] 不同,我们采用学习率为 0.00035 的近端策略优化 (PPO) [51],因为使用 PPO 进行训练更快、更稳定。为了鼓励探索,我们还使用了权重为 0.00001 的熵惩罚。在我们的实现中,基线函数是先前奖励的指数移动平均值,权重为 0.95。控制器的权重在 -0.1 和 0.1 之间统一初始化。
A.3. Training of the Controller
对于分布式训练,我们使用工作队列系统,其中从控制器 RNN 生成的所有样本都添加到全局工作队列中。分布式工作池中的空闲“子”工作器向控制器请求来自全局工作队列的新工作。一旦子网络的训练完成,就会计算保留验证集的准确度并将其报告给控制器 RNN。在我们的实验中,我们使用大小为 450 的子工作器池,这意味着随时在 450 个 GPU 上同时训练 450 个网络。在收到足够的子模型训练结果后,控制器 RNN 将使用 PPO 对其权重执行梯度更新,然后对进入全局工作队列的另一批架构进行采样。这个过程一直持续到已经对预定数量的架构进行了采样。在我们的实验中,这个预定数量的架构是 20,000,这意味着搜索过程在 20,000 个子模型被训练后终止。此外,我们用 20 个架构的小批量更新控制器 RNN。一旦搜索结束,然后选择前 250 个架构进行训练,直到收敛到 CIFAR-10 以确定最佳架构。
A.4. Details of architecture search space
我们进行了初步实验,以确定有效学习的神经架构的灵活、富有表现力的搜索空间。一般来说,我们的初步实验策略涉及小规模探索,以确定如何运行大规模架构搜索。
- 所有卷积都采用ReLU 非线性。ELU 非线性实验 [10] 显示出最小的收益。
- 为确保形状在卷积单元中始终匹配,必要时插入 1x1 卷积。
- 与[24] 不同,所有深度可分离卷积在深度和点操作之间不使用批量归一化和/或ReLU。
- 所有卷积都遵循 [21] 之后的 ReLU、卷积操作和批量归一化的顺序。
- 每当模型架构选择可分离卷积作为操作时,可分离卷积将两次应用于隐藏状态。我们凭经验发现这可以提高整体性能。
A.5. Training with ScheduledDropPath
我们使用各种随机正则化方法进行了几次实验。在卷积滤波器中简单地应用 dropout [56] 会降低性能。然而,我们发现了一种称为 ScheduledDropPath 的新技术,它是 DropPath [33] 的修改版本,在正则化 NASNet 方面效果很好。在 DropPath 中,我们以一定的固定概率随机丢弃单元格中的每条路径(即图 4 中带有黄色框的边缘)。这类似于 [27] 和 [69],他们在训练期间丢弃了模型的全部部分,然后在测试时间通过在训练期间保持该路径的概率来缩放路径。有趣的是,我们还发现单独的 DropPath 对 NASNet 训练没有太大帮助,但是 DropPath 在训练过程中线性增加了丢弃路径的概率显着提高了 CIFAR 和 ImageNet 实验的最终性能。我们将此方法命名为 ScheduledDropPath。
A.6. Training of CIFAR models
我们所有的 CIFAR 模型都使用单周期余弦衰减,如 [39, 18]。所有模型都使用动量优化器,动量率设置为 0.9。所有模型也使用 L2 权重衰减。在架构搜索过程中,每个架构都在 CIFAR-10 上训练了 20 个固定的 epoch。此外,我们发现在 CIFAR 模型训练的 20 个时期内使用余弦学习率衰减是有益的,因为这有助于进一步区分良好的架构。我们还发现,让 CIFAR 模型在架构搜索过程中使用较小的 N = 2 可以让模型快速训练,同时仍然可以再次堆叠找到运行良好的单元。
A.7. Training of ImageNet models
我们使用 ImageNet 2012 ILSVRC 挑战数据进行大规模图像分类。该数据集包含约 120 万张标记在 1000 个类别中的图像 [11]。总的来说,我们的训练和测试程序几乎与 [60] 相同。 ImageNet 模型在 299x299 或 331x331 图像上使用与之前描述的相同的数据增强程序进行训练和评估 [60]。我们使用分布式同步 SGD 来训练具有 50 个 worker(和 3 个备份 worker)的 ImageNet 模型,每个worker都使用 Tesla K40 GPU [7]。我们使用衰减为 0.9 和 epsilon 为 1.0 的 RMSProp。使用随时间推移的参数的运行平均值计算评估,衰减率为 0.9999。我们对所有 ImageNet 模型使用值为 0.1 的标签平滑,如 [60] 中所做的那样。此外,所有模型都使用位于网络上方 2/3 处的辅助分类器。辅助分类器的损失权重为 0.4,如 [60] 中所做的那样。我们凭经验发现我们的网络对与此辅助分类器相关的参数数量以及与损失相关的权重不敏感。所有模型也使用 L2 正则化。学习率衰减方案是[60]中使用的指数衰减方案。 Dropout 以 0.5 的概率应用于最终的 softmax 矩阵。
B. Additional Experiments
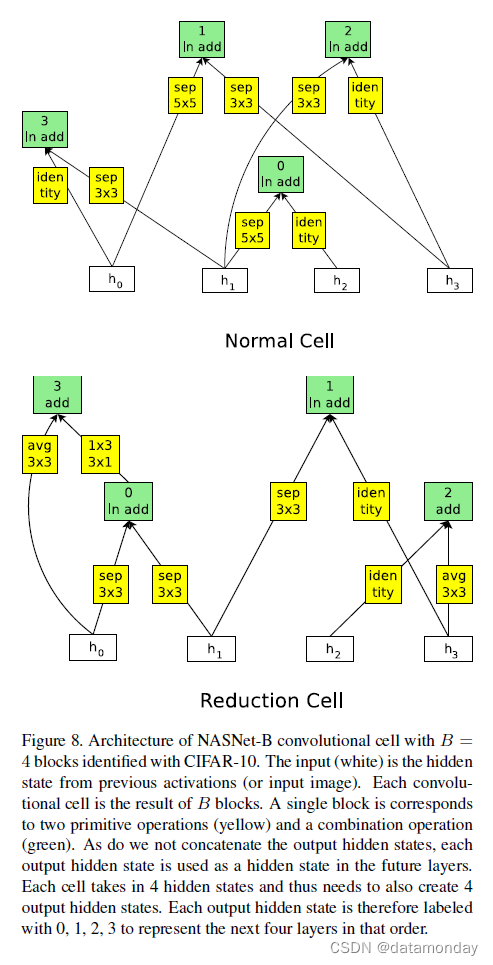
我们现在介绍另外两个在 CIFAR 和 ImageNet 上表现良好的单元。用于这些单元的搜索空间与用于 NASNetA 的搜索空间略有不同。对于图 8 中的 NASNet-B 模型,我们没有连接卷积单元中生成的所有未使用的隐藏状态。相反,在卷积单元中创建的所有隐藏状态,即使它们当前正在使用,也会被馈送到下一层。请注意,B = 4 并且有 4 个隐藏状态作为单元格的输入,因为这些数字必须匹配才能使该单元格有效。我们还允许将加法之后的层归一化 [2] 或实例归一化 [61] 预测为单元内的两个组合操作,以及加法或连接。
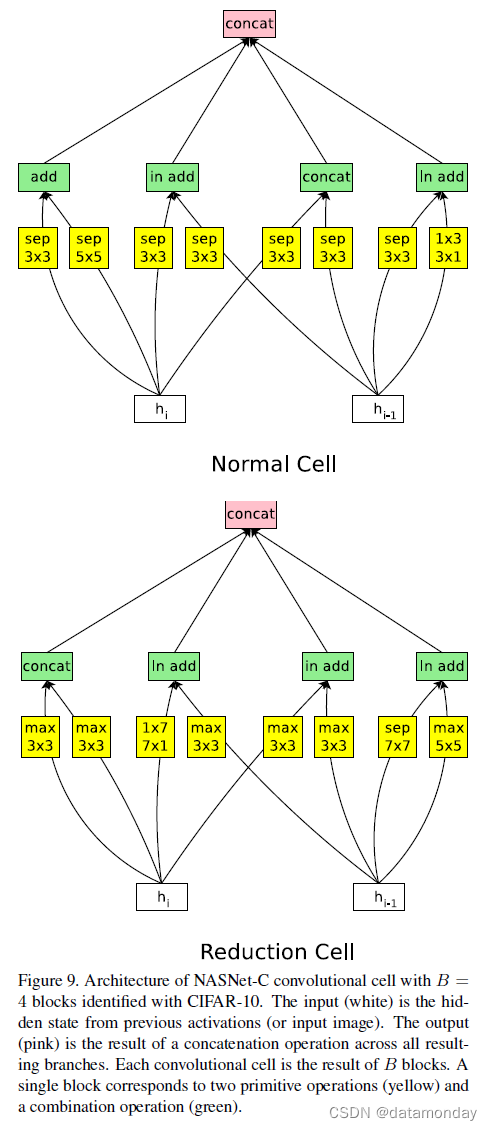
对于 NASNet-C(图 9),我们将卷积单元中生成的所有未使用的隐藏状态连接起来,就像在 NASNet-A 中一样,但现在我们允许预测加法,然后进行层归一化或实例归一化,就像 NASNet-B 中一样。
C. Example object detection results
最后,我们将在图 10 和图 11 中展示 COCO 数据集上的对象检测结果示例。从图中可以看出,NASNet-A featurization 与 Faster-RCNN 配合得很好,并且可以准确定位对象。
