典型的CNN架构:图像先进行多层卷积层(每个卷积层后一个接relu层和一个池化层)处理后输入给全连接神经网络层和relu层最后是输出层Softmax层输出预测的类概率,卷积层的卷积核过大会增加权重值的计算量卷积后的结果与小卷积核结果可能一致
图像模型评估:top-five错误率是测试图片系统判断前5个类别预测都没有包含正确答案的数量,由于CNN模型的出现,错误率从26%降到了3%
经典模型:LeNet-5架构(1998年)、AlexNet(2012年)、GoogLeNet(2014年,加深层次)、ResNet(2015年,层次循环)
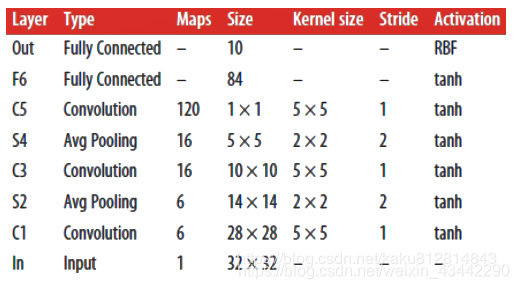
LeNet-5架构:最知名的CNN架构,Yann LeCun在1998年创建,用于MNIST手写体识别
使用均值池化,C3层没有全连接C2池化层,最后一层使用欧拉距离测量输入向量和对应权值向量距离(一般用交叉熵,惩罚错误的预测)
Dropout:在深度学习中,防止过拟合最常用的正则化技术,即使在顶尖水准的神经网络中也可以带来1%到2%的准确度提升,如果模型已经有了95%的准确率,获得2%的准确率提升意味着降低错误率大概40%,即从5%的错误率降低到3%的错误率,在每一次训练step中,每个神经元包括输入神经元不包括输出神经元有一个概率被临时的丢掉即将被忽视在整个这次训练step中,有可能下次再被激活,超参数p为dropout rate即神经元被忽略的概率,一般设置50%,训练完成后的模型不进行dropout
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data_bak/', one_hot=True)
sess = tf.InteractiveSession()
# ------------------------定义初始量---------------------------
# 截断的正太分布噪声,标准差设为0.1
# 同时因为我们使用ReLU,也给偏置项增加一些小的正值0.1用来避免死亡节点(dead neurons)
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 卷积层和池化层也是接下来要重复使用的,因此也为它们定义创建函数
# tf.nn.conv2d 是 TensorFlow 中的2维卷积函数,参数中x是输入,W是卷积的参数,比如[5, 5, 1, 32]
# 前面两个数字代表卷积核的尺寸,第三个数字代表有多少个channel,因为我们只有灰度单色,所以是1,
# 如果是彩色的 RGB 图片,这里是 3
# 最后代表核的数量,也就是这个卷积层会提取多少类的特征
# Strides代表卷积模板移动的步长,都是1代表会不遗漏地划过图片的每一个点!
# Padding代表边界的处理方式,这里的SAME代表给
# 边界加上Padding让卷积的输出和输入保持同样SAME的尺寸
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# tf.nn.max_pool 是 TensorFlow 中的最大池化函数,我们这里使用2*2的最大池化,
# 即将 2*2 的像素块降为 1*1 的像素
# 最大池化会保留原始像素块中灰度值最高的那一个像素,即保留最显著的特征,因为希望整体上缩小图片尺寸,
# 因此池化层
# strides 也设为横竖两个方向以2为步长。如果步长还是1,那么我们会得到一个尺寸不变的图片
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# --------------定义输入层---------------------------------
# 因为卷积神经网络会利用到空间结构信息,因此需要将 1D 的输入向量转为 2D 的图片结构,
# 即从 1*784 的形式转为原始的 28*28 的结构
# 同时因为只有一个颜色通道,故最终尺寸为 [-1, 28, 28, 1],前面的-1代表样本数量不固定,
# 最后的1代表颜色通道数量
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
x_image = tf.reshape(x, [-1, 28, 28, 1])
# ------------------定义第一个卷积层---------------------
# 我们先使用前面写好的函数进行参数初始化,包括weights和bias,
# 这里的[5, 5, 1, 32]代表卷积
# 核尺寸为5*5,1个颜色通道,32个不同的卷积核,然后使用conv2d函数进行卷积操作,
# 并加上偏置项,接着再使用ReLU激活函数进行
# 非线性处理,最后,使用最大池化函数max_pool_2*2对卷积的输出结果进行池化操作
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# ------------------定义第二个卷积层---------------------
# 第二层和第一个一样,但是卷积核变成了64
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# -------------------定义全连接层---------------------
# 因为前面经历了两次步长为2*2的最大池化,所以边长已经只有1/4了,图片尺寸由28*28变成了7*7
# 而第二个卷积层的卷积核数量为64,其输出的tensor尺寸即为7*7*64
# 我们使用tf.reshape函数对第二个卷积层的输出tensor进行变形,将其转成1D的向量
# 然后连接一个全连接层,隐含节点为1024,并使用ReLU激活函数
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# -------------------防止过拟合,使用Dropout层---------------------------
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# ---------------------接 Softmax分类------------------------------
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# ----------------------------定义损失函数-----------------------------
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv),
reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# -----------------------------训练------------------------------
tf.global_variables_initializer().run()
for i in range(20000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1],
keep_prob: 1.0})
print("step %d, training accuracy %g" % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print("test accuracy %g" % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0
}))