论文名称:RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
论文下载:https://arxiv.org/abs/2105.01883
论文年份:2022
论文被引:24(2022/05/21)
论文代码: https://github.com/DingXiaoH/RepMLP
Abstract
We propose RepMLP , a multi-layer-perceptron-style neural network building block for image recognition, which is composed of a series of fully-connected (FC) layers. Compared to convolutional layers, FC layers are more efficient, better at modeling the long-range dependencies and positional patterns, but worse at capturing the local structures, hence usually less favored for image recognition. We propose a structural re-parameterization technique that adds local prior into an FC to make it powerful for image recognition. Specifically, we construct convolutional layers inside a RepMLP during training and merge them into the FC for inference. On CIFAR, a simple pure-MLP model shows performance very close to CNN. By inserting RepMLP in traditional CNN, we improve ResNets by 1.8% accuracy on ImageNet, 2.9% for face recognition, and 2.3% mIoU on Cityscapes with lower FLOPs. Our intriguing findings highlight that combining the global representational capacity and positional perception of FC with the local prior of convolution can improve the performance of neural network with faster speed on both the tasks with translation invariance (e.g., semantic segmentation) and those with aligned images and positional patterns (e.g., face recognition).
我们提出了 RepMLP,这是一种用于图像识别的多层感知器式神经网络构建块,它由一系列全连接 (FC) 层组成。与卷积层相比,FC 层更有效,更擅长对远程依赖和位置模式进行建模,但在捕获局部结构方面更差,因此通常不太适合图像识别。我们提出了一种结构重新参数化技术,该技术将局部先验添加到 FC 中,使其在图像识别方面具有强大的功能。具体来说,我们在训练期间在 RepMLP 内构建卷积层,并将它们合并到 FC 中进行推理。在 CIFAR 上,一个简单的纯 MLP 模型显示出非常接近 CNN 的性能。通过在传统 CNN 中插入 RepMLP,我们将 ResNet 在 ImageNet 上的准确率提高了 1.8%,在人脸识别方面提高了 2.9%,在具有较低 FLOPs 的 Cityscapes 上提高了 2.3% mIoU。我们有趣的发现强调,将 FC 的全局表示能力和位置感知与卷积的局部先验相结合,可以在具有平移不变性的任务(例如语义分割)和对齐图像的任务中以更快的速度提高神经网络的性能和位置模式(例如,面部识别)。
1. Introduction
图像的局部性(即,一个像素与其邻居的关系比与远处的像素更相关)使得卷积神经网络 (ConvNet) 在图像识别中取得成功,因为卷积层只处理局部邻域。在本文中,我们将这种归纳偏差 (inductive bias) 称为局部先验 (local prior)。
最重要的是,我们还希望能够捕获远程依赖关系,这在本文中称为全局容量 (global capacity)。传统的 ConvNets 通过由深度堆叠的卷积层 [29] 形成的大感受野对远程依赖关系进行建模。然而,重复局部操作在计算上效率低下并且可能导致优化困难。一些先前的工作通过没有局部先验的基于自我注意的模块[29,11,27]增强了全局容量。例如,ViT [11] 是一个没有卷积的纯 Transformer 模型,它将图像作为序列输入到 Transformer 中。由于缺乏局部先验作为重要的归纳偏差,ViT 需要大量的训练数据(JFT-300M 中的 3 × 108 图像)来收敛。
另一方面,一些图像具有固有的位置先验,由于它在不同位置之间共享参数,因此不能被卷积层有效利用。例如,当有人试图通过人脸识别解锁手机时,人脸照片很可能会居中对齐,从而使眼睛出现在顶部,鼻子出现在中间。我们将利用这种位置先验的能力称为位置感知 (positional perception)。
本文重新审视全连接(FC)层,为传统的 ConvNet 提供全局容量和位置感知。在某些情况下,我们直接使用 FC 作为特征图之间的转换来代替 conv。通过展平特征图,通过 FC 馈送,然后重新整形,我们可以享受位置感知(因为它的参数与位置相关)和全局容量(因为每个输出点都与每个输入点相关)。就实际速度和理论 FLOP 而言,这样的操作是有效的,如表 4 所示,对于主要关注精度和吞吐量而不是参数数量的应用场景,人们可能更喜欢基于 FC 的模型而不是传统的 ConvNets。例如,GPU 推理服务通常有数十 GB 的内存,因此与计算和内部特征图所消耗的内存相比,参数占用的内存很小。
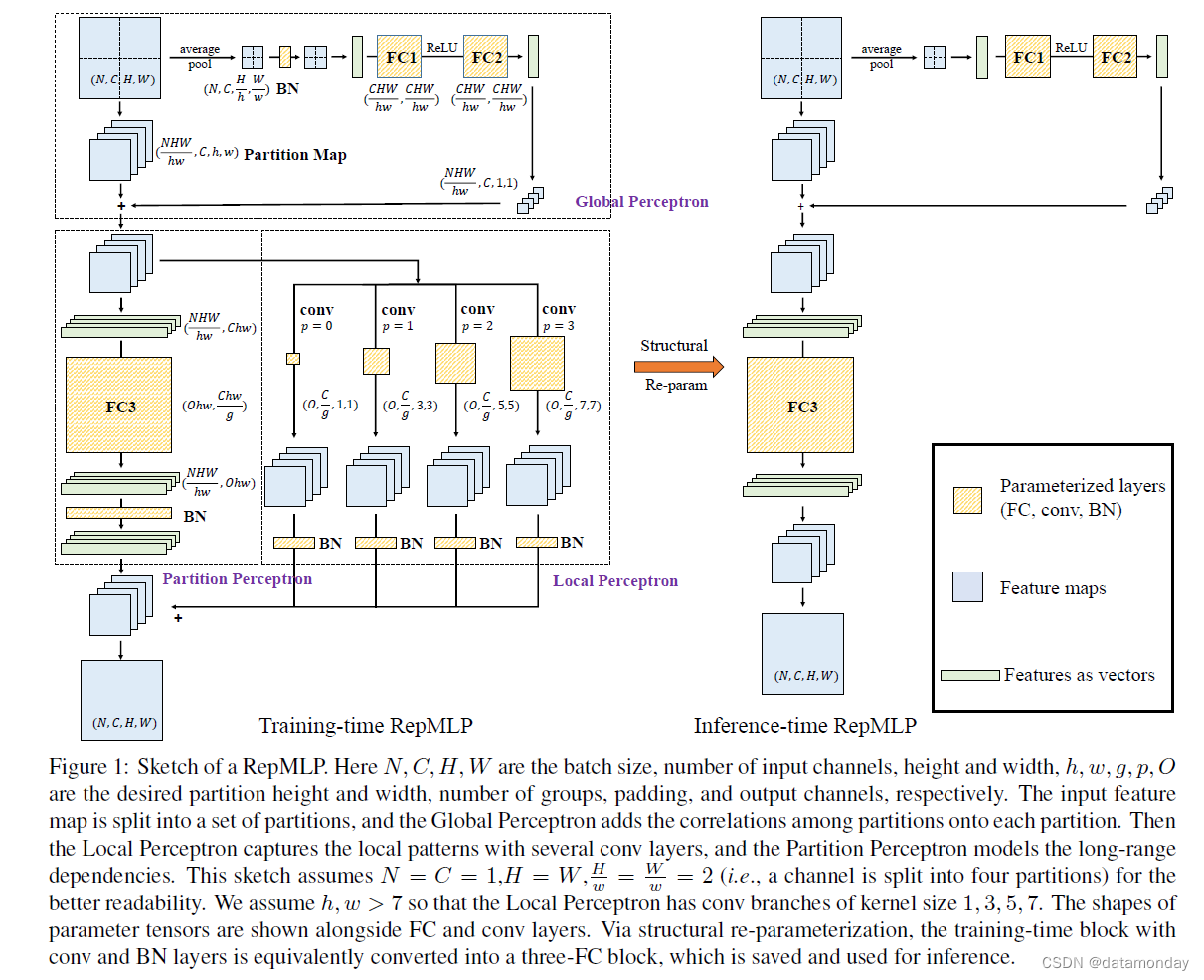
图 1:RepMLP 草图。这里 N、C、H、W 是批大小、输入通道数、高度和宽度,h、w、g、p、O 分别是所需的分区高度和宽度、组数、填充和输出通道数。输入特征图被分成一组分区,全局感知器将分区之间的相关性添加到每个分区上。然后 Local Perceptron 用几个 conv 层捕获局部模式,Partition Perceptron 对远程依赖关系进行建模。该草图假设 N = C = 1,H = W , H w = W w = 2(即,一个通道被分成四个分区)以获得更好的可读性。我们假设 h, w > 7,因此 Local Perceptron 具有内核大小为 1、3、5、7 的 conv 分支。参数张量的形状与 FC 和 conv 层一起显示。通过结构重参数化,将带有 conv 和 BN 层的训练时间块等价地转换为三个 FC 块,保存并用于推理。
但是,FC 没有局部先验,因为空间信息丢失了。在本文中,我们建议使用结构重新参数化技术将局部先验合并到 FC 中。具体来说,我们在训练期间构建与 FC 平行的卷积和批量归一化 (BN) [15] 层,然后将训练的参数合并到 FC 中以减少参数数量和推理延迟。基于此,我们提出了一种重新参数化的多层感知器(RepMLP)。如图 1 所示,训练时间 RepMLP 具有 FC、conv 和 BN 层,但可以等效地转换为只有三个 FC 层的推理时间块。结构重参数化的意思是训练时模型有一组参数,而推理时模型有另一组参数,我们用前者变换的参数对后者进行参数化。请注意,我们不会在每次推理之前导出参数。相反,将其转换一次,然后可以丢弃训练时模型。
与conv相比,RepMLP在相同数量的参数下运行速度更快,并且具有全局容量和位置感知。与自注意力模块 [29, 11] 相比,它更简单并且可以利用图像的局部性。如我们的实验所示(表 4、5、6),RepMLP 在各种视觉任务中都优于传统的 ConvNet,包括 1)一般分类(ImageNet [8]),2)具有位置先验的任务(人脸识别)和3)具有翻译不变性的任务(语义分割)。
我们的贡献总结如下。
- 我们建议利用FC 的全局能力和位置感知,并为其配备局部先验以进行图像识别。
- 我们提出了一种简单、与平台无关且可微分的算法,将并行 conv 和BN 合并到局部先验的FC 中,而无需任何推理时间成本。
- 我们提出了 RepMLP,一个高效的构建块,并展示了它在多视觉任务中的有效性。
2. Related Work
2.1. Designs for Global Capacity
Non-local Network [29] 提出通过自注意机制对远程依赖关系进行建模。对于每个查询位置,非局部模块首先计算查询位置与所有位置之间的成对关系以形成注意力图,然后通过加权和与注意力图定义的权重聚合所有位置的特征。然后将聚合的特征添加到每个查询位置的特征中。
GCNet [1] 创建了一个基于查询无关公式的简化网络,该网络以较少的计算量保持了非局部网络的准确性。 GC 块的输入经过全局注意力化、特征变换(1×1 卷积)和特征聚合。
与这些作品相比,RepMLP 更简单,因为它不使用自注意力并且只包含三个 FC 层。如表 4 所示,RepMLP对ResNet-50的性能比Non-local模块和GC块的提升更多。
2.2. Structural Re-parameterization
在本文中,结构重参数化是指构建与 FC 平行的 conv 和 BN 层进行训练,然后将参数合并到 FC 中进行推理。以下两个先前的工作也可以归类为结构重新参数化。
非对称卷积块(Asymmetric Convolution Block,ACB)[9] 是常规卷积层的替代品,它使用水平(例如,1×3)和垂直(3×1)卷积来加强方形(3×3)卷积的“骨架” 。在几个 ConvNet 基准上报告了合理的性能改进。
RepVGG [10] 是一种类似 VGG 的架构,因为它的主体仅使用 3 × 3 卷积和 ReLU 进行推理。这种推理时间架构是从具有identity和 1×1 分支的训练时间架构转换而来的。
RepMLP 与 ACB 更相关,因为它们都是神经网络构建块,但我们的贡献不是让卷积更强大,而是让 MLP 在图像识别方面强大,以替代常规卷积。此外,RepMLP 内部的训练时卷积可以通过 ACB、RepVGG 块或其他形式的卷积来增强,以进一步改进。
3. RepMLP
训练时 RepMLP 由三个部分组成,称为全局感知器、分区感知器和局部感知器(图 1)。在本节中,我们将介绍我们的公式,描述每个组件,并展示如何将训练时 RepMLP 转换为三个 FC 层进行推理,其中关键是一种简单、平台无关和可微分的方法,用于将 conv 合并到 FC .
3.1. Formulation
在本文中,特征图由张量 M ∈ R N × C × H × W M ∈ \mathbb{R}^{N×C×H×W} M∈RN×C×H×W 表示,其中 N N N 是批量大小, C C C 是通道数, H H H 和 W W W 分别是高度和宽度。我们分别使用 F 和 W 作为 conv 和 FC 的内核。为了简单和易于重新实现,我们使用与 PyTorch [22] 相同的数据格式,并以伪代码样式制定转换。例如,通过 K × K conv 的数据流可表述为
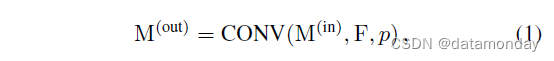
其中 M ( o u t ) ∈ R N × O × H ′ × W ′ M^{(out)} ∈ \mathbb{R}^{N×O×H'×W'} M(out)∈RN×O×H′×W′ 是输出特征图, O O O 是输出通道数, p p p 是要填充的像素数, F ∈ R O × C × K × K F ∈ \mathbb{R}^{O×C×K×K} F∈RO×C×K×K 是卷积核(我们暂时假设 conv 是密集的,即组数为 1)。从现在开始,为了简单起见,我们假设 H’ = H,W’ = W(即步幅为 1 且 p = K/2)。
对于一个 FC,设 P P P 和 Q Q Q 为输入和输出维度, V ( i n ) ∈ R N × P V^{(in)} ∈ \mathbb{R}^{N×P} V(in)∈RN×P 和 V ( o u t ) ∈ R N × Q V^{(out)} ∈ \mathbb{R}^{N×Q} V(out)∈RN×Q 分别为输入和输出,核为 W ∈ R Q × P W ∈ \mathbb{R}^{Q×P} W∈RQ×P,矩阵乘法 (MMUL) 表示为:
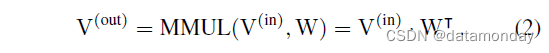
我们现在关注一个以 M(in) 作为输入并输出 M(out) 的 FC。我们假设 FC 不改变分辨率,即 H’ = H, W’ = W 。我们使用 RS(“reshape”的缩写)作为只改变张量的形状规格而不改变内存中数据顺序的函数,这是免费的。输入首先被展平为 N N N 个长度为 C H W CHW CHW 的向量,即 V ( i n ) = R S ( M ( i n ) , ( N , C H W ) ) V^{(in)} = RS(M^{(in)}, (N, CHW )) V(in)=RS(M(in),(N,CHW)) 乘以核 W ( O H W , C H W ) W(OHW, CHW ) W(OHW,CHW),然后输出 V ( o u t ) ( N , O H W ) V^{(out)}(N, OHW) V(out)(N,OHW) 被重新整形为 M ( o u t ) ( N , O , H , W ) M^{(out)}(N, O, H, W) M(out)(N,O,H,W)。
为了更好的可读性,如果没有歧义,我们省略 RS,
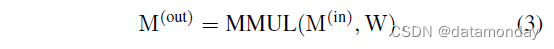
这样的 FC 不能利用图像的局部性,因为它根据每个输入点计算每个输出点,而不知道位置信息。
3.2. Components of RepMLP
上述方式没有使用 FC,因为不仅缺乏局部先验,而且参数数量巨大,即 C O H 2 W 2 COH^2W^2 COH2W2。使用常用设置,例如,H = W = 28,C = O = 128 在 ImageNet 上,这个单一的 FC 会有 10G 的参数,这显然是不可接受的。为了减少参数,我们提出了全局感知器和分区感知器来分别建模分区间和分区内的依赖关系。
Global Perceptron 对特征图进行拆分,以便不同的分区可以共享参数。例如,一个 (N, C, 14, 14) 输入可以拆分为 (4N, C, 7, 7),我们将每个 7 × 7 的块称为一个分区。我们使用一种有效的实现方式来实现这种拆分,只需一次内存重新排列操作。设 h 和 w 是每个分区的期望高度和宽度(我们假设 H,W 分别可被 h,w 整除,否则我们可以简单地填充输入),输入 M ∈ RN×C×H×W 首先被重新整形成 (N, C, H/h , h, W/w , w)。请注意,此操作是免费的,因为它不会在内存中移动数据。然后我们将轴的顺序重新排列为 (N, H/h , W/w , C, h, w),这样可以有效地移动内存中的数据。例如,它只需要 PyTorch 中的一个函数调用(permute)。然后 (N, H/h , W/w , C, h, w) 张量被重新整形(这又是无成本的)为 ( NHW/hw , C, h, w)(在图 1 中表示为分区图)。这样,所需的参数数量从 C O H 2 W 2 COH^2W^2 COH2W2 减少到 C O h 2 w 2 COh^2w^2 COh2w2。
但是,拆分会破坏同一通道的不同分区之间的相关性。换句话说,模型将单独查看分区,完全不知道它们是并排放置的。为了在每个分区上添加相关性,全局感知器
-
1)使用平均池化来获得每个分区的像素
-
2)通过 BN 和两层 MLP 将其输入
-
3)重塑并将其添加到分区图上
这种添加可以通过自动广播有效地实现(即,将 (NHW/hw , C, 1, 1) 隐式复制到 ( NHW/hw , C, h, w) 中),以便每个像素都与其他分区相关。然后将分区图输入分区感知器和局部感知器。请注意,如果 H = h,W = w,我们直接将输入特征图馈送到 Partition Perceptron 和 Local Perceptron 而不进行拆分,因此不会有 Global Perceptron。
分区感知器有一个 FC 和一个 BN 层,它采用分区图 (partition map)。输出 (N HW hw , O, h, w) 以与之前相反的顺序被重新整形、重新排列和重新整形为 (N, O, H, W)。我们进一步减少了受 groupwise conv [5, 31] 启发的 FC3 的参数。以 g 作为组数,我们将 groupwise conv 表示为
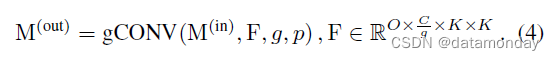
类似地,groupwise FC 的核是 W ∈ R Q × P / g W ∈ \mathbb{R}^{Q× P/g} W∈RQ×P/g ,它有 g× 更少的参数。尽管像 PyTorch 这样的一些计算框架并不直接支持 groupwise FC,但它也可以通过 groupwise 1 × 1 conv 来实现。该实现由三个步骤组成:
- 1)将 V(in) 重塑为空间大小为 1×1 的“特征图”;
- 2)对g组进行 1×1 conv;
- 3)将输出“特征图”重塑为 V(out)
我们将分组矩阵乘法(gMMUL)表示为
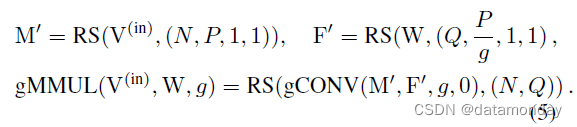
局部感知器通过几个卷积层提供分区图。受 [9, 10] 的启发,BN 跟随在每个 conv 之后。图 1 显示了 h, w > 7 和 K = 1, 3, 5, 7 的示例。理论上,对内核大小 K 的唯一约束是 K ≤ h, w(因为使用更大的内核没有意义比分辨率),但我们只使用奇数内核大小作为 ConvNet 中的常见做法。我们使用 K × K 只是为了简化表示法,并且非方形卷积(例如 1 × 3 或 3 × 5)也可以。 conv 的 padding 应配置为保持分辨率(例如,p = 0, 1, 2, 3 分别对应 K = 1, 3, 5, 7),组数 g 应与 Partition 相同感知器。所有 conv 分支和 Partition Perceptron 的输出相加作为最终输出。
3.3. A Simple, Platform-agnostic, Differentiable Algorithm for Merging Conv into FC
在将一个 RepMLP 转换为三个 FC 层之前,我们首先展示如何将一个 conv 合并到 FC 中。使用 FC 内核 W(1)(Ohw, Chw)、conv 内核 F(O, C, K, K) (K ≤ h, w) 和填充 p,我们希望构造 W0 使得
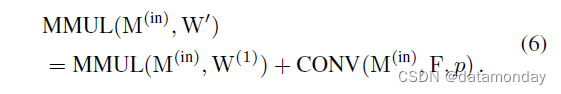
我们注意到,对于任何与 W(1) 形状相同的核 W(2),MMUL 的可加性确保
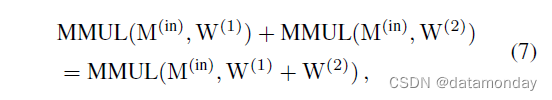
所以我们可以将 F 合并到 W(1) 中,只要我们设法构造与 W(1) 相同形状的 W(F,p) 满足
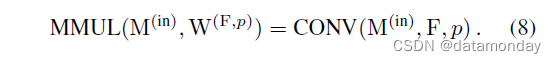
显然,W(F,p) 必须存在,因为 conv 可以被视为在空间位置之间共享参数的稀疏 FC,这正是其平移不变性的来源,但用给定的 F 和页。由于现代计算平台使用不同的卷积算法(例如,im2col-[2]、Winograd-[17]、FFT-[20]、MEC-[4] 和基于滑动窗口)以及数据的内存分配和填充的实现可能不同,在特定平台上构建矩阵的方法可能不适用于另一个平台。在本文中,我们提出了一个简单且与平台无关的解决方案。
如上所述,对于任何输入 M(in) 和卷积核 F,填充 p,存在一个 FC 核 W(F,p),使得
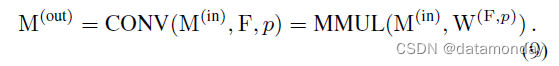
使用之前使用的公式(等式 2),我们有
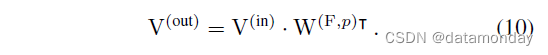
我们插入一个单位矩阵 I (Chw, Chw) 并使用结合律
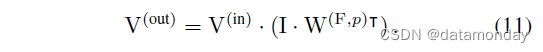
我们注意到因为 W(F,p) 是用 F 构造的,所以 I · W(F,p)T 是在从 I 重塑的特征图 M(I) 上与 F 的卷积。使用显式 RS,我们有
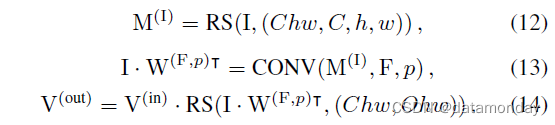
比较公式 10 与 13, 14,我们有
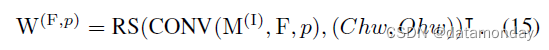
这正是我们希望用 F, p 构造 W(F,p) 的表达式。简而言之,conv 内核的等效 FC 内核是对单位矩阵进行适当整形的卷积结果。更好的是,转换是高效且可微的,因此可以在训练期间推导出 FC 内核并将其用于目标函数(例如,用于基于惩罚的剪枝 [13, 21])。分组情况的表达式和代码以类似的方式推导出来,并在补充材料中提供。
3.4. Converting RepMLP into Three FC Layers
要使用上述理论,我们首先需要通过将 BN 层等效地融合到前面的 conv 层和 FC3 中来消除 BN 层。令 F ∈ RO× C/g ×K×K 为卷积核,µ, σ, γ, β ∈ RO 为后面 BN 的累积均值、标准差和学习到的比例因子和偏差,我们构造核 F’ 和偏差 b‘ 为
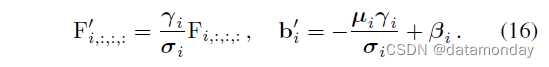
然后很容易验证等价性:
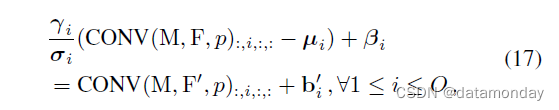
其中左侧是 conv-BN 的原始计算流程,右侧是构造的带有偏差的 conv。
Partition Perceptron 的 1D BN 和 FC3 以类似的方式融合为 ^W ∈ ROhw × Chw/g , ^b ∈ ROhw。然后我们通过公式 15 转换每个 conv,并将得到的矩阵添加到 ^W 上。 conv 的偏差被简单地复制了 hw 次(因为同一通道上的所有点共享一个偏差值)并添加到 b^b 上。最后,我们获得了一个单一的 FC 内核和一个单一的偏置向量,它们将用于参数化推理时间 FC3。
Global Perceptron 中的 BN 也被移除,因为移除相当于在 FC1 之前应用仿射变换,FC1 可以将其吸收,因为两个连续的 MMUL 可以合并为一个。补充材料中提供了公式和代码。
3.5. RepMLP-ResNet
RepMLP 的设计和将 conv 重新参数化为 FC 的方法是通用的,因此可用于许多模型,包括传统 CNN 和同时提出的全 MLP 模型,例如 MLP-Mixer [25]、ResMLP [26]、gMLP [19 ]、AS-MLP [18] 等。在本文中,我们在大部分实验中使用 ResNet 中的 RepMLP,因为这项工作是在上述所有全 MLP 模型公开之前完成的。RepMLP 在全 MLP 模型上的应用被安排为我们未来的工作。
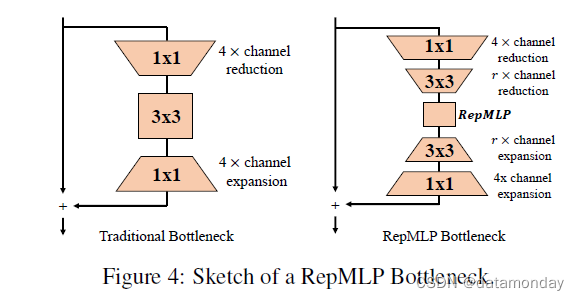
为了在 ResNet 中使用 RepMLP,我们遵循 ResNet-50 的瓶颈 [14] 设计原则,通过 1×1 conv 将通道减少 4 倍。此外,我们在 RepMLP 之前进一步执行 r× 通道缩减,之后通过 3 × 3 conv 执行 r× 通道扩展。整个块被称为 RepMLP 瓶颈(图 4)。对于特定阶段,我们将所有 stride-1 瓶颈替换为 RepMLP 瓶颈,并保留原始 stride-2(即第一个)瓶颈。
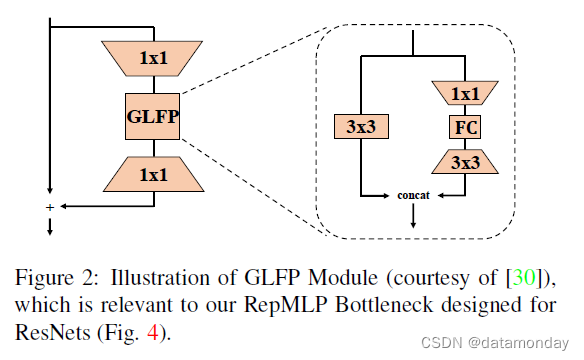
RepMLP Bottleneck 的设计与 GLFP Module [30] 相关,它使用具有 1×1、3×3 卷积和 FC 的瓶颈结构进行人脸识别,但差异很大。
-
1)GLFP 直接将输入特征图展平为向量,然后将它们馈送到 FC 层,这很新颖且富有洞察力,但在 ImageNet 分类和语义分割等具有大输入分辨率的任务上可能效率低下。相比之下,RepMLP 对输入特征图进行分区,并使用 Global Perceptron 添加全局信息。
-
2)GLFP 使用与 1×1-FC-3×3 分支平行的 3×3 conv 分支来捕获局部模式。与可以合并到 FC 进行推理的 RepMLP 的 Local Perceptron 不同,GLFP 的 conv 分支对于训练和推理都是必不可少的。
-
3)拓扑结构的一些差异(例如,加法与串联)。
需要再次说明的是,本文的核心贡献不是将 RepMLP 插入 ResNet 的解决方案,而是将 conv 重新参数化到 FC 的方法以及 RepMLP 的三个组件。
4. Experiments
4.1. Pure MLP and Ablation Studies
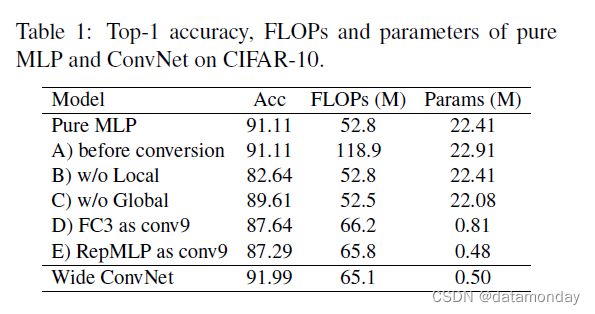
我们首先通过在 CIFAR-10 上测试纯 MLP 模型来验证 RepMLP 的有效性。更准确地说,由于 FC 等价于 1 × 1 conv,因此“纯 MLP”意味着不使用大于 1 × 1 的 conv 内核。我们将 RepMLP 和常规 FC (1 × 1 conv) 交错以构建三个阶段和通过最大池化进行下采样,如图 3 所示,并通过将 RepMLP 替换为 3 × 3 conv 来构建一个 ConvNet 对应物进行比较。对于可比较的 FLOP,三个阶段的通道对于纯 MLP 为 16,32,64,对于 ConvNet 为 32,64,128,所以后者被命名为Wide ConvNet。我们采用标准的数据增强[14]:填充到 40 × 40、随机裁剪和左右翻转。这些模型以 128 的批大小和 100 个 epoch 中从 0.2 退火到 0 的余弦学习率进行训练。如表 1 所示,纯 MLP 模型达到 91.11% 的准确率,只有 52.8M FLOPs。毫不奇怪,纯 MLP 模型的性能并不优于 Wide ConvNet,这促使我们将 RepMLP 和传统的 ConvNet 结合起来。
然后我们进行一系列消融研究。
- A)我们还报告了转换前 MLP 的 FLOP,它仍然包含 conv 和 BN 层。尽管额外的参数是边际的,但 FLOPs 要高得多,这表明了结构重新参数化的重要性。
- B)“w/o Local”是没有Local Perceptron的变体,准确率低8.5%,可见local prior的重要性。
- C)“w/o Global”移除 FC1 和 FC2 并将分区图直接馈送到 Local Perceptron 和 Partition Perceptron。
- D)“FC3 as conv9”将 FC3 替换为一个 conv(K = 9 和 p = 4,因此它的感受野大于 FC3),然后是 BN,以比较 FC3 与常规 conv 的表示能力。虽然比较偏向于 conv,因为它的感受野更大,但其准确度低 3.5%,这验证了 FC 比 conv 更强大,因为 conv 是退化的 FC。
- E)“RepMLP as conv9”直接用 9 × 9 conv 和 BN 替换 RepMLP。与 D 相比,它的准确性较低,因为它没有全局感知器。
4.2. RepMLP-ResNet for ImageNet Classification
我们以 ResNet-50 [14](torchvision 版本 [23])作为基础架构来评估 RepMLP 作为传统 ConvNet 中的构建块。为了公平比较,所有模型都在 100 个 epoch 中使用相同的设置进行训练:8 个 GPU 上的全局批量大小为 256,权重衰减为 10−4,动量为 0.9,余弦学习率从 0.1 退火到 0。我们使用 mixup [32] 和 Autoaugment [7] 的数据增强管道,随机裁剪和翻转。所有模型均使用单个中央裁剪进行评估,并在相同的 1080Ti GPU 上测试速度,批量大小为 128,以示例/秒为单位进行测量。为了公平比较,RepMLP 被转换,每个模型的所有原始 conv-BN 结构也被转换为带有偏差的卷积层以进行速度测试。
作为一种常见的做法,我们将 ResNet-50 的四个残差阶段分别称为 c2、c3、c4、c5。在 224 × 224 的输入下,四个阶段的输出分辨率分别为 56、28、14、7,四个阶段的 3 × 3 卷积层的 C = O = 64、128、256、512 分别为。为了用 RepMLP 替换大的 3 × 3 卷积层,我们在局部感知器中使用 h = w = 7 和三个卷积分支,其中 K = 1、3、5。
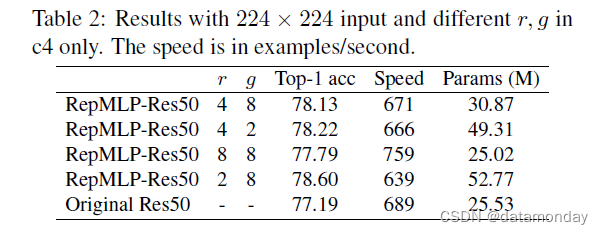
我们首先在 c4 中使用 RepMLP 并改变超参数 r 和 g 以测试它们如何影响精度、速度和参数数量(表 2)。值得注意的是,经过剧烈的 8 倍缩减(因此 RepMLP 的输入和输出通道为 256/8 = 32),RepMLP-Res50 的参数更少,运行速度比 ResNet-50 快 10%。前两行之间的比较表明,当前的 groupwise 1×1 conv 效率低下,因为参数增加了 59%,但速度仅下降了 0.7%。对 groupwise 1 × 1 conv 的进一步优化可能会使 RepMLP 更有效。在以下实验中,我们使用 r = 2 或 4 和 g = 4 或 8 进行更好的权衡。
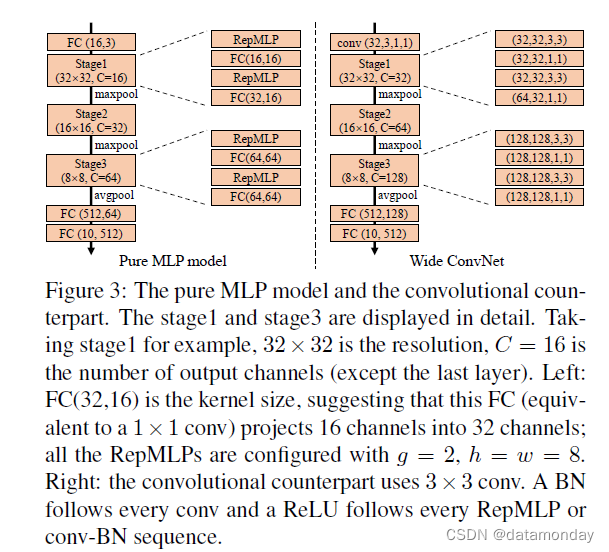

我们继续在不同阶段测试 RepMLP。具体来说,对于合理的模型大小,我们分别为 c2、c3、c4、c5 设置 g = 8 和 r = 2、2、4、4。桌子。从图 3 可以看出,用 RepMLP 瓶颈替换原来的瓶颈会导致非常小的减速,并且准确度得到了显着提高。仅在 c4 上使用 RepMLP 只会增加 5M 的参数,但准确度提高了 0.94%,并且在 c3 和 c4 中使用 RepMLP 提供了最佳权衡。它还建议 RepMLP 应该与传统的 conv 结合以获得最佳性能,因为在所有四个阶段中使用它提供的准确度低于 c2+c3+c4 和 c3+c4。我们在以下实验中在 与具有更高输入分辨率的大型传统 ConvNet 的比较(表 4)进一步证明了 RepMLP 的有效性并提供了一些有趣的发现。当使用 320 × 320 输入进行训练和测试时,我们使用 h = w = 10 的 RepMLP,局部感知器有四个分支,K = 1、3、5、7。我们还改变组的数量以生成三个具有不同尺寸。例如,g8/16 表示 c3 的 g = 8 和 c4 的 16。作为远程依赖建模的两个经典模型,我们按照原始论文中的说明构建了 Non-local [29] 和 GC [1] 对应物,并且使用相同的设置训练模型。

我们还将著名的 EfficientNet [24] 系列作为强基线再次使用相同的设置进行训练。我们有以下观察。3+c4 中使用 RepMLP。
- 1)与参数数量相当的传统ConvNets相比,RepMLP-Res50的FLOPs要低得多,速度更快。例如,与具有 224 × 224 输入的 ResNet-101 相比,RepMLPRes50 只有 50% 的 FLOPs 和 4M 的参数,运行速度快 50%,但它们的精度是相同的。凭借 320 × 320 的输入,RepMLP-Res50 在准确度、速度和 FLOP 方面的表现都大大优于其他方法。此外,ResNet-50 的改进不应简单地归因于深度的增加,因为它仍然比 ResNet-101 浅。
- 2)增加 RepMLPs 的参数会导致非常小的减速。从 RepMLP-Res50-g8/16 到 RepMLP-Res50-g4/8,参数增加了 47%,但 FLOPs 仅增加了 3.6%,速度仅降低了 2.2%。此属性对于大型服务器上的高吞吐量推理特别有用,其中吞吐量和准确性是我们的主要关注点,而模型大小则不是。
- 3)与Nonlocal和GC相比,RepMLP-Res50的速度几乎相同,但准确率高出1%左右。
- 4)与实际上在 GPU 上效率不高的 EfficientNets 相比,RepMLP-Res50 在速度和准确度上都表现出色。

我们在图 5 中可视化了 FC3 的权重,其中采样的输出点 (6,6) 用虚线正方形标记。原始 FC3 没有局部先验作为标记点,并且邻域没有比其他更大的值。但是在合并 Local Perceptron 之后,得到的 FC3 内核在标记点周围具有更大的值,表明该模型更关注邻域,这是意料之中的。此外,全局容量并没有丢失,因为在最大卷积核(本例中为 7 × 7,由蓝色方块标记)之外的一些点(用红色矩形标记)仍然比内部的点具有更大的值。
我们还在附录中介绍了另一种瓶颈设计(RepMLP Light Block),它不使用 3×3 卷积,但仅使用 1×1 进行 8× 通道缩减/扩展。与原始的 ResNet-50 相比,它实现了相当的准确度(77.14% 对 77.19%),FLOP 降低了 30%,速度提高了 55%。
4.3. Face Recognition
与 conv 不同,FC 不是平移不变的,这使得 RepMLP 对于具有位置先验的图像(即人脸)特别有效。我们用于训练的数据集是 MS1M-V2,这是一个包含来自 85k 名人的 580 万张图像的大规模人脸数据集。它是 MS-Celeb-1M 数据集 [12] 的半自动精炼版本,其中包含来自 10 万个identity的 100 万张照片,并且有许多嘈杂的图像和错误的 ID 标签。我们使用 MegaFace [16] 进行评估,其中包括 60k identity的 100 万张图像作为图库集,以及来自 FaceScrub 的 530 个identity的 100k 图像作为探针集。也是人工清零的精炼版。我们使用 96 × 96 的输入进行训练和评估。
除了 MobileFaceNet [3] 作为众所周知的基线(最初是为低功耗设备设计的)外,我们还使用定制的 ResNet(在本文中称为 FaceResNet)作为更强的基线。与常规的 ResNet-50 相比,c2,c3,c4,c5 中的块数从 3,4,6,3 减少到 3,2,2,2,宽度从 256,512,1024,2048 减少到128,256,512,1024,3×3的通道从64,128,256,512增加到128,256,512,1024。换句话说,残差块中的 1×1 卷积层不会减少或扩展通道。因为输入分辨率为 96 × 96,所以 c2,c3,c4,c5 的空间大小分别为 24,12,6,3。对于 RepMLP 对应项,我们通过用 h = w = 6, r = 2 的 RepMLP 瓶颈替换 c2、c3、c4 的 stride1 瓶颈(即 c2 的最后两个瓶颈和 c3、c4 的最后块)来修改 FaceResNet , g = 4。
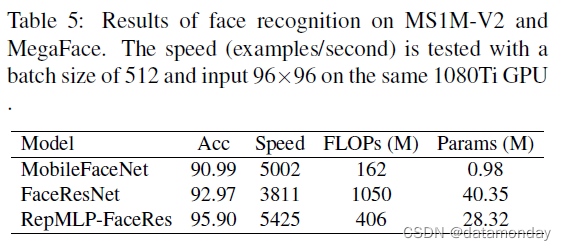
对于训练,我们使用 512 的批大小、0.9 的动量、AM-Softmax 损失 [28] 和 [3] 之后的权重衰减。所有模型都经过 420k 迭代训练,学习率从 0.1 开始,在 252k、364k 和 406k 迭代时除以 10。为了评估,我们报告了 MegaFace 上的 top1 准确度。表 5 显示,FaceResNet 提供了比 MobileFaceNet 更高的准确度,但运行速度较慢,而 RepMLP-FaceRes 在准确度和速度上都表现出色。与 MobileFaceNet 相比,RepMLPFaceRes 的准确率提高了 4.91%,运行速度提高了 8%(尽管它有 2.5 倍的 FLOPs),这显然更适合高功率设备。
4.4. Semantic Segmentation
语义分割是具有翻译不变性的代表性任务,因为汽车可能出现在左侧或右侧。我们验证了 ImageNetpretrained RepMLP-Res50 在 Cityscapes [6] 上的泛化性能,其中包含 5K 精细标注的图像和 19 个类别。我们使用 RepMLP-Res50-g4/8 和在 ImageNet 上以 320 × 320 预训练的原始 ResNet-50 作为主干。为了更好的可重复性,我们简单地采用了 PSPNet [34] 框架的官方实现和默认配置 [33]:poly learning rate policy,base 为 0.01,power 为 0.9,权重衰减为 10−4,全局 batch size 为 16在 8 个 GPU 上运行 200 个 epoch。在 PSPNet50 之后,我们在两个模型的 c5 和原始 ResNet-50 的 c4 中使用 dilated conv。我们没有在 RepMLP-Res50-g4/8 的 c4 中使用 dilated conv,因为它的感受野已经很大。由于 c3 和 c4 的分辨率变为 90 × 90,全局感知器将有每个通道的 81 个分区,因此 FC1 和 FC2 中的参数更多。我们通过将 c3 的 FC1 的输出维度和 FC2 的输入维度减少 4 倍和 c4 的 8 倍来解决这个问题。 FC1 和 FC2 是随机初始化的,其他所有参数都继承自 ImageNet 预训练模型。
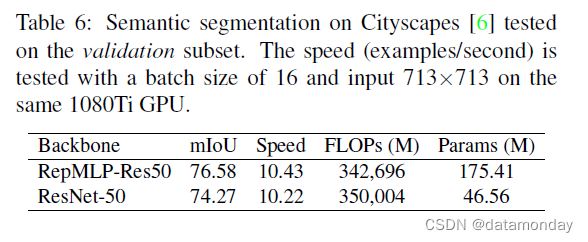
表 6 显示具有 RepMLP-Res50g4/8 的 PSPNet 在 mIoU 方面比 Res-50 主干网络高 2.21%。虽然它有更多的参数,但 FLOPs 更低,速度更快。值得注意的是,我们的 PSPNet 基线低于报告的 PSPNet-50,因为后者是为语义分割定制的(在最大池化之前增加了两层),但我们的不是。
5. Conclusion
FC 比 conv 具有更强的表示能力,因为后者可以被视为具有共享参数的稀疏 FC。然而,FC 没有局部先验,这使得它不太适合图像识别。在本文中,我们提出了 RepMLP,它利用 FC 的全局容量和位置感知,并通过简单且与平台无关的算法将卷积重新参数化,将局部先验合并到 FC 中。从理论上讲,将 conv 视为 FC 的退化案例开辟了一个新的视角,这可能会加深我们对传统 ConvNets 的理解。值得一提的是,RepMLP 是为主要关注推理吞吐量和准确性的应用场景而设计的,较少关注参数的数量。
Appendix A: RepMLP-ResNet for High Speed
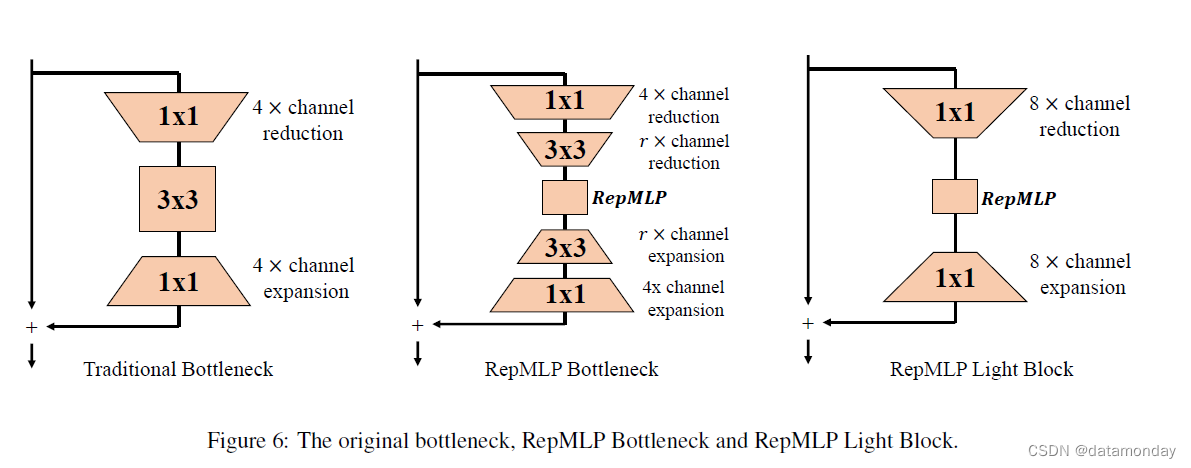
论文中提出的 RepMLP 瓶颈旨在提高准确性。在这里,我们提出了另一种在 ResNet 中使用 RepMLP 以获得更高速度的方法。具体来说,我们构建了一个 RepMLP Light Block(图 6),没有 3 × 3 conv,但在 RepMLP 之前和之后通过 1 × 1 conv 进行了剧烈的 8x 通道缩减/扩展。与论文中报道的 78.55%-accuracy RepMLP-ResNet50 相同,我们在 Local Perceptron 中使用 h = w = 7, g = 8 和三个 conv 分支,K = 1, 3, 5。速度测试相同与论文中报告的所有模型一样。表 7 显示带有 RepMLP Light Block 的 ResNet 实现了与原始 ResNet50 几乎相同的准确度,但 FLOP 降低了 30%,速度提高了 55%。

值得注意的是,RepMLP 是一个可以以各种方式与许多其他结构组合的构建块。我们只提出了两种在 ResNet 中使用 RepMLP 的方法,这可能不是最优的。我们将公开代码和模型以鼓励进一步研究。
Appendix B: Converting Groupwise Conv into FC
将 conv 转换为 FC 的 groupwise 情况稍微复杂一些,可以通过先将输入分成 g 个并行组,然后将每个组分别转换来推导出。 PyTorch 代码显示在 Alg 1中和提交的 repmlp.py 包含一个可执行的例子来验证等价性。很容易验证 g = 1 的代码完全实现了论文中公式15。

Appendix C: Absorbing BN into FC1
Global Perceptron 中的 BN 对输入应用线性缩放和偏置。在与 FC1 内核进行矩阵乘法后,将添加的偏差投影,然后添加到 FC1 的偏差上。因此,可以通过缩放 FC1 的内核和改变 FC1 的偏差来抵消这个 BN 的去除。代码显示在 Alg 2 中和提交的 repmlp.py 包含一个可执行的例子来验证等价性。
