文章摘要
这篇文章研究了一种基于特征层面对虚拟样本有效性进行评价的基本思路。即利用特征评价中的“互信息”、“欧式距离”以及最后的总体识别精度作为对构建虚拟样本有效性的评价;并针对“重采样”、“奇异值重构”、“轮廓波重构”三种方法生成的虚拟样本的有效性进行了实验验证和有效性评价,实验结果表明论文使用的三种虚拟样本生成算法能实现对原始样本的有效扩充,并改善识别效果。
文章思路
1.1 介绍虚拟样本生成技术的背景与应用前景
1.2 虚拟样本生成技术的国内外研究现状
1.3 论文主要内容及章节结构
2.1—2.3 介绍基于机器学习的图像识别算法理论基础
2.4实验:降维对算法的有效性分析
实验目的:证明降维对于识别系统的必要性。
实验平台:ORL数据库,ORL 数据库中有 40 人的共计 400 幅人脸图像样本,每人 10 幅图像。每幅图像大小为 92*112像素。
实验流程:随机选择每人 5 幅作为训练样本,其余则作为测试样本集。 采用上文介绍的 SVM 与 DBN两种机器学习算法。并通过添加与不添加 PCA 与 LBP 进行特征提取降维来对比说明采用特征提取降维的必要性。
实验中 SVM 中将训练集整体(或经过 PCA 降维处理)作为输入, 选择 RBF 核函数, 核函数中的 gamma 函数设置值为 0.35。 DBN 算法中将根据 2.2.4 节给出的对比散度的快速学习算法, DBN 共设置 4 层网络,将训练集整体(或经过等价模式 LBP 按 4×4分块降维处理)作为DBN 模型第一层 RBM 可见层的输入,其中的两个隐层设置层数均为 100, 迭代次数为 30,学习率为 0.001。
实验结果见下表:

由表中数据可以看出,通过降维处理后的 SVM 识别效果较好。而未经降维处理的数据由于维数过大,*每个样本维数为 10304 维,远远大于训练集中图像的数目,出现了过拟合的现象。*最终预测结果将所有 200 个测试样本分为了一类, 导致识别率过低。而基于深度学习的 DBN 虽然能有效的挖掘数据集当中的的特征关系,在未进行降维与特征提取的前提下仍然取得了较好的分类效果,然而由于维数过于庞大导致了整个识别系统运算效率的急剧下降。从运行时间和识别分类效果两个方面,都说明了降维与特征提取步骤的必要性。
点评:
样本数量稀少,本身就极容易面临着过拟合问题,在这里作者用样本数量和特征数量的比对,来描述过拟合的程度。如果将图像识别过程类比为信息采样与还原的过程,那么奈奎斯特采样频率是否也适用于图像识别过程中呢,样本数量到底是多少才是合适,这应该与神经网络的规模息息相关,但是具体的数量关系是什么呢。
这里转自知乎作者的一个相关回到,或许有借鉴意义:
从深度学习系统看,最本质需要考察的是多少样本可以有效覆盖问题空间,在这个前提下,才能考虑样本数量对网络训练的影响,否则如果样本少到不足以覆盖整个问题空间,那么系统出现信息缺失,
此时考虑网络性能意义就失去了。比如如果你仅有一个数据来训练网络,那么系统即使拟合的很好,依然无法泛化到问题空间。如果样本数据足够有代表性,可以较好拟合问题数据的分布,然后我们可以考虑样本数目和网络模型体积的关系。网络结构和配置作为目标问题的一个表示,其性能会受到网络结构和训练数据的双重影响。所谓足够的训练数据,其实就是采样可以以足够精度拟合输入数据分布以及输出空间的分布,这一点显然是严重依赖于问题数据和系统性能要求的,简单说,依赖于问题本身复杂度,不会有统一的答案。在满足上述条件的前提下,才能考察训练数据和模型的匹配与互动问题。如果网络复杂度足够覆盖问题的解,训练数据足够体现问题空间的各种分布,那么问题就变成输入样本的区分度是否和网络可以提供的区分度匹配的问题,或者说网络要对不同的样本信息在网络中的信息运行模式有区分,如果网络结构合理,网络提供的区分度和训练数据的区分度应该大致相当的。最后,样本应该是多多益善,合适的数量就是样本训练构造的网络的区分度达到问题要求的时候,就是合适的训练数据数量。至于从网络结构的复杂度来估计训练数据数量,很难,因为网络一般是过参数化的且具有相当的随意性,在网络配置训练确立以前,甚至网络的复杂度都是不容易定义的,至少只看权重的某个范数是不合适的。
作者:匿名用户
链接:https://www.zhihu.com/question/352261733/answer/868941654
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
3.1.1虚拟样本的相关基础
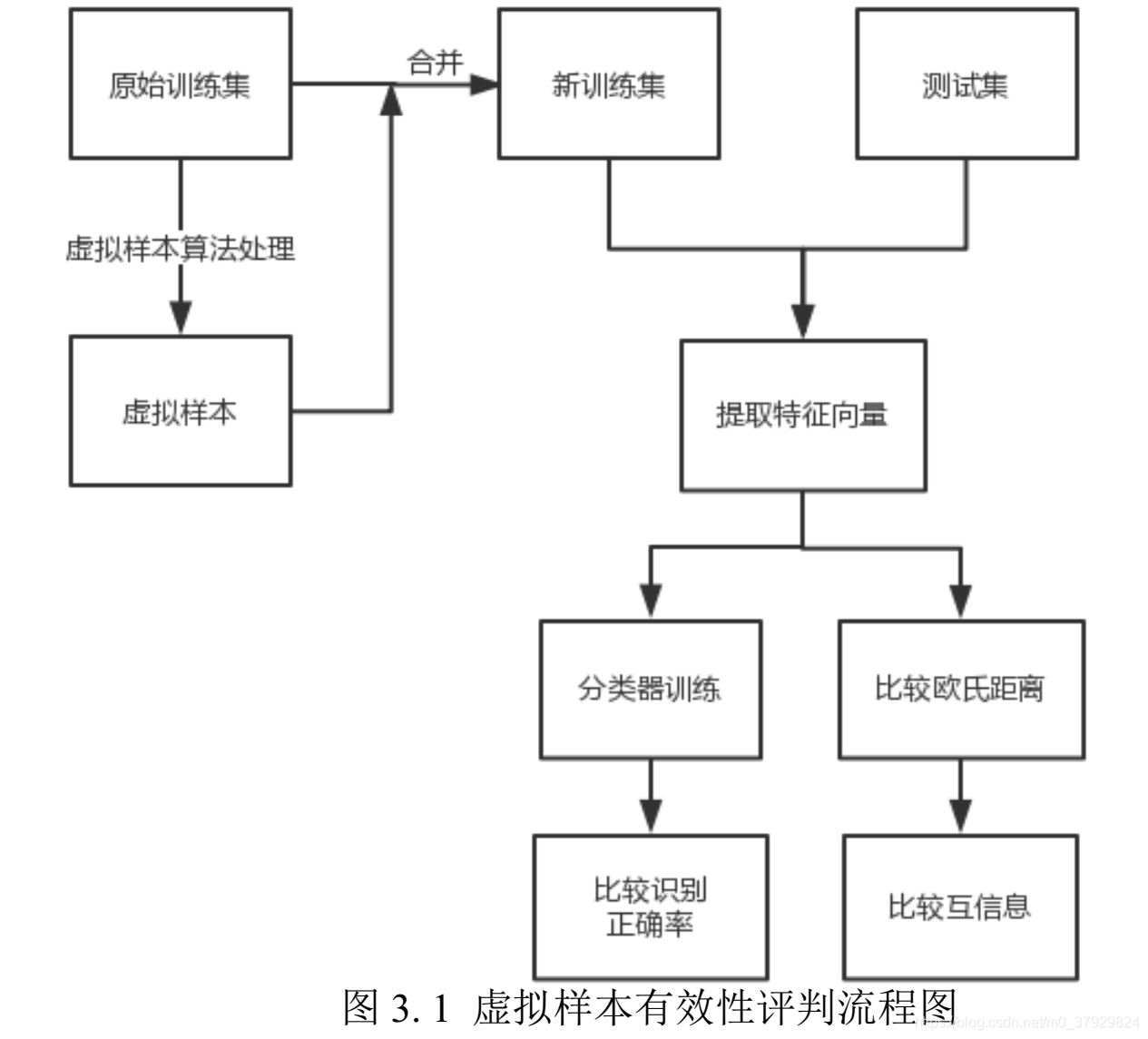
3.1.2 评判虚拟样本的有效性
有效的虚拟样本即是能够通过添加虚拟样本从而提高不同类别样本之间的区分能力。 对于虚拟样本的评判准则目前还没有产生一个公认的标准。
由于大部分机器学习算法都需要对样本集进行特征提取以进行进一步的训练识别工作, 且所提取的特征分量对于最终的识别性能有着至关重要的影响。
所以在此,本文引入特征选择[38]相关概念以评价生成的虚拟样本的有效性。
这里查看参考文献【38】
[38]张靖. 面向高维小样本数据的分类特征选择算法研究[博士学位论文]. 合肥工业大学, 2014
本文从样本特征子集的角度建立了一个对于所构建出的虚拟样本的有效性评价的标准:
1、 虚拟样本要保留目标的主要特征成分,同时去除无关的特征分量。
2、 虚拟样本相较于原样本特征上要有一定的变化,同时不能泛化特征
这里是阐述作者建立的指标的原则标准。
对于虚拟样本的有效性评判的的依据,本文将通过以添加虚拟样本前后的特征分量进行评估,以此来说明虚拟样本的有效性。一般来说对于特征的评价标准分为独立标准以及相关标准。
独立标准包括:距离、信息、相关性、一致性等等。
相关标准是使用特定分类器对所指定的特征集分类后的分类精度。本章所选用的是添加虚拟样本前后训练集与测试集之间经过 PCA特征提取的特征分量所对应的欧氏距离以及其互信息[39]作为衡量特征的独立标准。 同时将结合使用SVM 而得到的分类识别正确率作为相关标准来评价本文虚拟样本算法所生成的虚拟样本的有效性。
简单来说,这篇文章选择了两个标准,一个是欧氏距离标准、另一个是互信息标准,作者用以上两个标准衡量虚拟样本的有效性,关键在于这块是直接选择而非经过严格的数学推导与证明。而这也是这篇论文的核心。
3.2基于虚拟样本构建图像
在这部分,作者介绍了三种获得虚拟样本的方法及背后的数学原理,这三种方法包括重采样法(最近邻插值、双线性内插法、双立方插值法)、基于奇异值重构法构建虚拟图像、基于轮廓波重建构建虚拟图像
实验:添加虚拟样本后查看对实验效果的改进
实验目的:在原始数据中,添加上述三种方法生成的实验数据,验证理论的正确性。
实验平台:实验数据集采用公共数据集 ORL 人脸数据库进行实验。利用 matlab2016 对原始数据进行生成,采用PCA进行降维型, PCA 选取主成分分量在 90% 以上的部分, SVM 使用 RBF 核函数, 核函数中的gamma 函数值选0.35.
实验流程:1.1、选择不同的插值方法,计算准确率,并尝试通过用自己的理论指标解释(即欧式距离与互信息);1.2、对比完成;



因此,作者选用双线性插值样本进行数据扩充。
同理,作者对其他两种方法也进行了同样的参数调整,进行相关实验




实验结果:

实验结论:
本章介绍了虚拟样本基本原理,同时讨论了基于特征层面的虚拟样本评价标准以及评价依 据。介绍了本文所使用的三种虚拟样本算法的基本概念与思路, 采用虚拟样本算法可以有效的 扩充训练集大小,改善识别情况。 通过欧氏距离、互信息以及识别精度实验详细讨论了几种虚拟样本算法具体的参数选取,以保证取得最佳的识别改善效果, 同时将确定参数的虚拟样本与单纯添加数量的原样本复制、添加噪声样本进行对比验证了本章之前所使用的虚拟样本有效性 评价准则。
文中使用的虚拟样本算法在特征层面上从相关性与独立性的角度均对其有效性进行了实验 验证,由此设计的虚拟样本算法具有一定的依据性, 可以为之后有关机器学习方面研究中不同 识别算法提供有效帮助。
点评:
个人认为这个实验有个最大的问题是控制变量的问题,站在不确定度这门课的角度来说,是否真正系统的分析了这个的影响来源,对此我还是持怀疑态度,不过这两个指标也确实反映了一部分真实,但是如何统一目前尚未定论。
第四部分 虚拟样本的应用研究
人脸识别实验
实验目的:验证这个算法的有效性
实验平台:
实验数据集采用 4.1.2 小节所介绍的 ORL 人脸数据库、 YALE 数据库以及 FERET 人脸数据 库进行实验。利用matlab2016 对原始数据首先进行不同虚拟样本的生成, 为了引入空间结合性 同时保证较小的维度,我们还需要对数据进行降维。对训练测试数据经过降维处理以及预处理 后的数据输入到识别模型进行模型构建和训练。本节实验分别选用 PCA+SVM 支持向量机和 LBP+DBN 深度置信网络两种常用的降维与机器学习识别模型,以验证不同种类虚拟样本对于 机器学习算法识别性能的改善程度。 PCA+SVM 中 PCA 选取主成分分量在 90%以上的部分, SVM 使用 RBF 核函数, 核函数中的 gamma 函数设置值为 0.35。 LBP+DBN 中 LBP 使用的是等 价模式, 半径邻域大小为 1 像素, 像素点数为 8 个, 对图片进行采用 4*4分块,每块进行等价 模式 LBP 将原始数据固定降维至 59 维作为 DBN 的输入, DBN 中每次随机选取经过虚拟样本 扩充后的人脸图像样本作为 DBN 模型第一层 RBM 可见层的输入,根据 2.2.4 节给出的对比散 度的快速学习算法进行训练, DBN 共设置 4 层网络,其中的两个隐层设置层数均为 100, 迭代 次数为 30,学习率为 0.001。
实验步骤:
ORL 人脸数据库内包含 40 人的共计 400 幅人脸图像样本。每次训练集分别随机选择 2~5张人脸图像,并按照 1:1 的比例添加通过3.3 节所确定具体参数的三种虚拟样本。分别通过PCA+SVM 支持向量机和 LBP+DBN 深度置信网络进行识别对比。重复实验 5 次取平均值后所得到的具体结果见表 4.1。
YALE 人脸数据库内共有 15 人,每人 11 幅共 165 幅图像样本数据。 同样每次训练集分别随机选择 2~5 张人脸图像,并按照1:1 的比例添加通过 3.2 节确定具体参数的三种虚拟样本。分别通过 PCA+SVM 支持向量机和 LBP+DBN深度置信网络进行识别对比。重复实验 5 次取平均值后所得到的具体结果见表 4.2
FERET 人脸数据库内共有 200 人,每人 7 幅共 1400 幅图像样本数据。 同样每次训练集分别随机选择 2~5 张人脸图像,并按照 1:1 的比例添加通过 3.3 小节确定具体参数的三种虚拟样本。分别通过 PCA+SVM 支持向量机和 LBP+DBN 深度置信网络进行识别对比。重复实验 5 次取平均值后所得到的具体结果见表 4.3
实验结果:



关于添加虚拟样本比例的讨论:
上节中的实验都是按照 1:1的比例添加虚拟样本进行扩充训练集并识别的。然而实际上对于虚拟样本添加的比例有必要进行讨论,本节中为了研究虚拟样本的添加比例对识别结果的影响,以 ORL 人脸数据库为例,使用 SVM 与 DBN 两种机器学习算法进行实验。实验训练集随机选取 5 幅图像作为训练样本,并通过三种虚拟样本方法分别对其中 1、 2、 3、 4、 5 幅图像进行扩展,生成相应的虚拟图像加入训练集共同训练重复5 次实验后取平均识别结果。 使用 SVM识别的实验结果见图 4.9。 使用 DBN 识别的实验结果见图 4.10。可以看出选择添加不同比例的虚拟样本会对最终的识别结果造成一定的影响。三种虚拟样本添加不同比例后识别结果均在1%~2%之间波动,而非单调升高或降低。然而全部按照 1:1 的比例添加普遍不会达到识别率的最大值,该实验说明虚拟样本的添加确实存在一定比例,且添加不同方法生成的虚拟样本,其比例的具体大小会有所不同。具体的适宜添加比例仍然需要进一步的深入研究。
参考文献
[1]郑儒楠.用于机器学习中图像识别的虚拟样本算法研究及应用[D].江苏:南京航空航天大学,2017.
总结:
这篇文章主要是提出了一种评价数据生成好坏的指标,主要从欧式距离和互信息两个角度进行评价,这篇文章总结的三种数据扩充方法即重采样、轮廓波、奇异值重构,却是我没有接触过的数据扩充方式,或许可以一试。
