GPU技术市场战火
图形处理器(英语:graphics processing unit,缩写:GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。
GPU使显卡减少了对CPU的依赖,并进行部分原本CPU的工作,尤其是在3D图形处理时GPU所采用的核心技术有硬件T&L(几何转换和光照处理)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬件T&L技术可以说是GPU的标志。GPU的生产商主要有NVIDIA和ATI。
一个光栅显示系统离不开图形处理器,图形处理器是图形系统结构的重要元件,是连接计算机和显示终端的纽带。
参考文献链接
https://mp.weixin.qq.com/s/BctPZOl69XDkwa-zQuC6KA
https://mp.weixin.qq.com/s/tLl4v_d09CMKXzpukST_oA
https://mp.weixin.qq.com/s/QKNhsQnIYd3gCODDpYCMJA
https://mp.weixin.qq.com/s/lmdeB70oIT_reZGN4zJUng
https://baike.baidu.com/item/%E5%9B%BE%E5%BD%A2%E5%A4%84%E7%90%86%E5%99%A8/8694767?fromtitle=gpu&fromid=105524&fr=aladdin
应该说有显示系统就有图形处理器(俗称显卡),但是早期的显卡只包含简单的存储器和帧缓冲区,实际上只起了一个图形的存储和传递作用,一切操作都必须由CPU来控制。这对于文本和一些简单的图形来说是足够的,但是当要处理复杂场景特别是一些真实感的三维场景,单靠这种系统是无法完成任务的。所以后来发展的显卡都有图形处理的功能。不单单存储图形,而且能完成大部分图形功能,这样就大大减轻了CPU的负担,提高了显示能力和显示速度。随着电子技术的发展,显卡技术含量越来越高,功能越来越强,许多专业的图形卡已经具有很强的3D处理能力,而且这些3D图形卡也渐渐地走向个人计算机。一些专业显卡具有的晶体管数甚至比同时代的CPU的晶体管数还多。比如2000年加拿大ATI公司推出的 RADEON显卡芯片含有3千万颗晶体管,达到每秒15亿个象素填写率。
图形处理器由以下器件组成:
(1)显示主芯片显卡的核心,俗称GPU,主要任务是对系统输入的视频信息进行构建和渲染。
(2)显示缓冲存储器用来存储将要显示的图形信息以及保存图形运算的中间数据;显示缓存的大小和速度直接影响着主芯片性能的发挥。
(3)RAMD/A转换器把二进制的数字转换成为和显示器相适应的模拟信号。
计算能力和计算模式方面的问题
当前 GPU 的基础 ———传统 Z-buffer 算法不能满足新的应用需求。在实时图形和视频应用中 ,需要更强大的通用计算能力 ,比如支持碰撞检测、近似物理模拟;在游戏中需要图形处理算法与人工智能和场景管理等非图形算法相结合。当前的GPU 的体系结构不能很好地解决电影级图像质量需要解决的透明性、高质量反走样、运动模糊、景深和微多边形染色等问题 ,不能很好的支持实时光线跟踪、Reyes(Renders everything you ever saw) 等更加复杂的图形算法 ,也难以应对高质量的实时3D图形需要的全局光照、动态和实时显示以及阴影和反射等问题。需要研究新一代的 GPU 体系结构突破这些限制。随着 VLSI 技术的飞速发展 ,新一代 GPU芯片应当具有更强大的计算能力 ,可以大幅度提高图形分辨率、场景细节 (更多的三角形和纹理细节)和全局近似度。图形处理系统发展的趋势是图形和非图形算法的融合以及现有的不同染色算法的融合。新一代的图形系统芯片需要统一灵活的数据结构、新的程序设计模型、多种并行计算模式。认为发展的趋势是在统一的、规则并行处理元阵列结构上 ,用数据级并行、操作级并行和任务级并行的统一计算模式来解决当前图形处理系统芯片面临的问题。
制造工艺方面的问题
集成电路发展到纳米级工艺 ,不断逼近物理极限 ,出现了所谓红墙问题:一是线的延迟比门的延迟越来越重要。长线不仅有传输延迟问题 , 而且还有能耗问题。二是特征尺寸已小到使芯片制造缺陷不可避免 ,要从缺陷容忍、故障容忍与差错容忍等三个方面研究容错与避错技术。三是漏电流和功耗变得非常重要 ,要采用功耗的自主管理技术。现代的图形处理器芯片在克服红墙问题的几个方面有了显著的进步:利用了大量的规则的 SIMD 阵列结构;分布存储器接近了运算单元 ,减少了长线影响;硬件多线程掩盖了部分存储延迟的影响。但是随着工艺进一步发展 ,当前 GPU 的体系结构难以适应未来工艺发展 ,没有在体系结构上应对长线问题、工艺偏差和工艺缺陷问题的措施 ,特别是没有考虑如何适应三维工艺。当前最先进工艺的晶体管的栅极厚度已经大约是五个原子,在制造时,少了一个原子就造成20 %的工艺偏差。因此工艺的偏差成为SoC设计不能不考虑的问题。特别是到 2018 年后的纳电子集成电路 ,可以通过随机自组装产生规则的纳米器件。因此,新一代系统芯片的体系结构必须利用规则的结构并且容忍工艺偏差 ,具有容错、避错和重组的能力。认为采用大量同构处理器元之间的邻接技术 ,适应纳米级工艺和未来的三维工艺 ,采用新型体系结构和相关的低功耗、容错和避错的设计策略 ,对于未来的图形处理系统芯片具有重要的科学意义。
GPU战火重燃
从早期“百家争雄”,到英伟达“一统江湖”,再到如今AMD、英特尔欲“三分天下”。
GPU在技术与市场的不断变换轮转中,迎来一次次蜕变与重塑。
GPU(Graphic Processing Unit),图形处理器,又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备上做图像和图形相关运算工作的微处理器。
由于可视化需要大量的图形、图像计算能力,无论是云端还是边缘侧都需要大量的高性能图像处理能力,因此近年来GPU实现了较快的市场增速。同时,随着GPU自身在并行处理和通用计算的优势,逐步拓展了其在服务器、汽车、矿机、人工智能、边缘计算等领域的衍生需求。
据数据统计,2020年全球GPU行业规模为200亿美元,预计2021年将增长15%。从2015年到2025年,GPU行业预计平均每年增长13%,将从80亿美元扩展到350亿美元的规模。
GPU可以按照两种方式进行分类:按照接入方式可以分为集成GPU和独立GPU,集成GPU将图形核心以单独芯片的方式集成在主板上或CPU芯片上,并且动态共享部分系统内存作为显存使用,因此能够提供简单的图形处理能力,以及较为流畅的编码应用;独立GPU拥有单独的图形核心和独立的显存,能够满足复杂庞大的图形处理需求,并提供高效的视频编码应用。
另一种是根据应用端的不同可以分为PC GPU、移动GPU和服务器GPU。PC GPU是用于PC端,既有独立也有集成;移动GPU用于移动端,一般都是集成;服务器GPU是专为计算加速或深度学习应用的独立GPU。
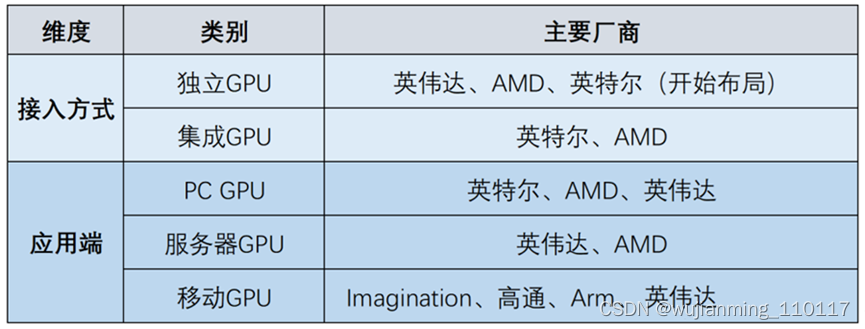
GPU分类及代表厂商
GPU发展历程,英伟达一统江湖
• GPU的诞生和演进
在PC诞生之初,并不存在GPU这个概念,所有的图形和多媒体运算都由CPU负责。但是由于X86 CPU的暂存器数量有限,适合串行计算而不适合并行计算。以英特尔为代表的厂商多次推出SSE等多媒体拓展指令集试图弥补CPU的缺陷,但仅仅在指令集方面的改进起不到根本效果,所以诞生了图形加速器作为CPU的辅助运算单元。
追溯GPU的历史,要从图形显示控制器说起。世界上第一台个人电脑IBM5150于1981年由IBM公司发布,这台PC搭载了黑白显示适配器(MDA)和彩色图形适配器(CGA),这便是最早的图形显示控制器。后来,IBM又推出EGA,并于1987年提出了VGA标准,VGA在文字模式下可支持720×400分辨率,绘图模式下可支持640×480×16色和320×200×256色输出,为了保证兼容性,当今的显卡依然会遵循VGA标准。
从MDA到VGA,图形图像的运算都由CPU来完成,图形卡的作用主要是将其显示出来。1991年,S3 Graphics推出的“S3 86C911”,正式开启2D图形硬件加速时代,能进行字符、基本2D图元和矩形的绘制。到了1995年,几乎所有的显卡都具备2D加速功能,2D图形接口GDI、DirectFB等也都相继出现,并延续至今。
1994年,3DLabs发布的Glint 300SX是第一颗用于PC的3D图形加速芯片,支持高氏着色、深度缓冲、抗锯齿、Alpha混合等特性,开启了显卡的3D加速时代。然而这个阶段的显卡大多没有执行统一的标准,加速功能也不尽相同。能够看到,GPU概念推出之前,ATI、英伟达、3DFX等公司在此领域展开激烈竞争,推动着图形处理芯片的发展。
直到1999年,英伟达推出GeForce256图形处理芯片时,首次提出了GPU的概念,整合了硬件变换和光照(T&L)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,并且兼容DirectX和OpenGL,被称为世界上第一款GPU。
GPU的出现(硬件T&L的引入)使计算机减少了对CPU的依赖,并解放了部分原本CPU的工作。2001年微软发布DirectX 8,提出了渲染单元模式(shader model)的概念。从此,GPU从硬件T&L进入shader时代,此时的GPU架构还是固定管线。
固定管线架构持续多年,直到微软推出DirectX 10,shader不再扮演固定的角色,每一个shader都可以处理顶点和像素,这就是统一渲染着色器(unified shader),出现避免了固定管线中顶点着色器和像素着色器资源分配不合理的现象发生,使得GPU利用率更高。
第一款采用统一渲染架构的GPU是ATI在2005年与微软合作的游戏主机XBOX 360上采用的Xenos,ATI第一代统一渲染架构。而真正具有影响力的,是英伟达在2006年发布的GeForce 8800 GTX(核心代号G80),成为第一款采用统一渲染架构的桌面GPU,其架构影响了日后的数代产品,是一款极具划时代意义的GPU。
与G80一同发布的,还有著名的CUDA,能利用英伟达 GPU的运算能力进行并行计算,拓展了GPU的应用领域,然而这时的CUDA只能算是GPU的副业。2011年TESLA GPU计算卡发布,标志着英伟达将正式用于计算的GPU产品线独立出来,凭借着架构上的优势,GPU在通用计算及超级计算机领域,逐渐取代CPU成为主角。
• 英伟达“一统江湖”
在早期的图形处理器市场中玩家众多,3DFX通过推出Voodoo 3D加速卡在当时领先于市场同行。英伟达由于蔑视当时的主流标准,采用自创的四边形成像(QTM)技术,在同时期打造的NV1和NV2都未成功。此后陆续推出RIVA系列和TNT、TNT2,逐渐占据市场主流地位,并最终通过1999年的GeForce256击败3DFX,并于2000年英伟达将3DFX的知识产权买断。
在进入21世纪后,英伟达从此前的蛮荒时代中脱颖而出,市场中主要还剩下英伟达和ATI。ATI在1985年至2006年之间是全球重要的显示芯片公司,2000年ATI推出Radeon品牌,从此与英伟达开创了独立GPU领域两强争霸的格局。2006年AMD斥资54亿美元收购ATI,旨在融合CPU和GPU。在AMD收购ATI之后的重心更多地转向中低端市场,性能端渐渐落后于英伟达。而后英伟达牢牢掌控着高端市场,AMD的GPU则成为了性价比的代名词。
目前,独立显卡市场主要由英伟达和AMD两家占据。市场调查机构——Jon Peddie Research发布的二季度显卡市场报告显示,在目前独立显卡市场中,目前AMD和NIVDIA两大厂商居于统治地位,从市场份额上来看,AMD独显份额为17%,英伟达则增长到了83%。英特尔在前不久宣布进军高端独立显卡市场,预计首款产品将于明年问世。
报告显示,英伟达在显卡市场中表现强劲,市场占有率和出货量均有明显增长。AMD则需要面临显卡和处理器双线作战,产能更显紧张,所以市场份额呈现了下降的趋势。
英伟达的GPU架构自2008年以来几乎一直保持着每2年一次大更新的节奏,带来更多更新的运算单元和更好的API适配性。在工艺制程方面,英伟达GPU从2008年GT200系列的65nm制程逐步升级到了RTX3000系列的7/8nm制程,在整个过程中,晶体管数量提升了20多倍,使英伟达GPU的能效提升了数十倍,占领了独立显卡技术的制高点。
英伟达通过对产品的打磨,从众多显卡厂商中脱颖而出,铸就了GPU高端市场的垄断地位。同时随着自动驾驶、AI、AR/VR等领域的兴起,拥有领先优势的英伟达有望继续领跑市场,凭借产品的领先性和稀缺性,巩固自身行业地位。
根据前十多年的GPU发展轨迹来看,GPU微架构的升级趋势可以简要地概括为“更多、更专、更智能”。“更多”指的是晶体管数量和运算单元的增加,其中包括流处理器单元、纹理单元、光栅单元等数量上升;“更专”是指除了常规的计算单元,GPU还会增加新的运算单元。例如,英伟达的图灵架构相较于帕斯卡架构新增加了光追单元(RT Cores)和张量单元(Tensor Core),分别处理实时光线追踪和人工智能运算;“更智能”是指GPU的AI运算能力上升。如第三代的张量单元相较于上代在吞吐量上提升了1倍。
此外,在整个过程中,英伟达一直坚持不采用IDM的模式,而是让台积电负责GPU的制造,自生专注于芯片设计,充分发挥比较优势,分散了GPU设计和制造的风险,符合半导体分工的大趋势。
英特尔、AMD奋起直追,欲三分天下
目前在全球GPU市场中主要的3个玩家:英伟达、AMD和英特尔。英伟达专注于GPU领域,由于此前不具备CPU业务,公司重心放在更高性能的独立显卡方向。AMD和英特尔由于自身有CPU业务,在2009年后两家厂商都各自大力发展内置于CPU的高性能集成式图形处理内核。
瞄准了未来的市场需求,以及英伟达在独显市场的垄断地位,英特尔、AMD奋起直追,想要三分天下。
• 英特尔直面出击
由于英特尔在CPU市场的巨大市场优势,带动了集成显卡的出货。英特尔凭借在CPU市场60%以上的市场份额,获得了GPU市场份额上的领先地位。
英特尔是全球最大的PC GPU供应商,也是PC和服务器显卡唯一的IDM厂商。英特尔的GPU最早可以追溯到1998年的i740,但是由于羸弱的性能和缓慢的更新速度,一直没有非常大的起色。进入酷睿i时代后,英特尔通过将核芯显卡和CPU进行捆绑销售,利用CPU的庞大市场份额,确立了公司在集成GPU领域的寡头垄断地位。
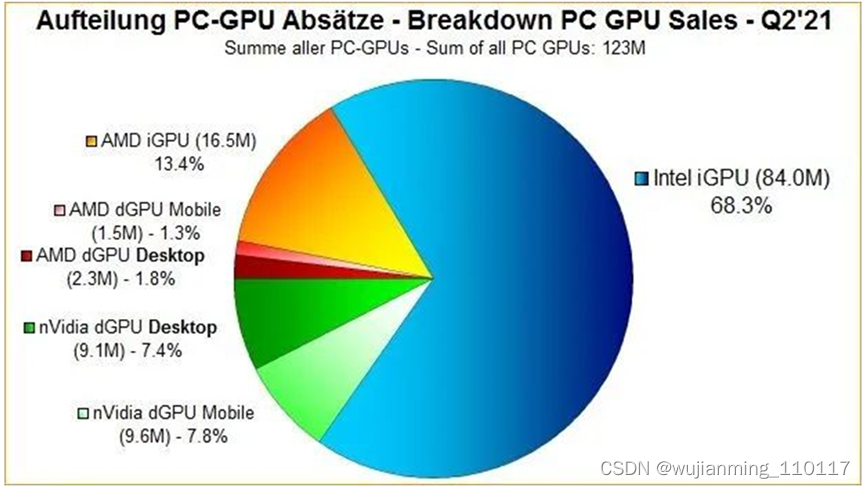
英特尔核芯显卡市占率达到68.3%(图源:JPR)
近日,英特尔CEO Pat Gelsinger在受访中表示,目前独显市场几乎由英伟达占据,在许多显示技术应用变得更偏重使用英伟达提供产品,使其变得过于专有,对于市场生态发展显然不利。因此英特尔希望借助接下来持续更新的oneAPI框架设计,让开发者、硬件厂商能更容易统整CPU、GPU,乃至于以FPGA形式建构更具弹性的运算方式,解决编码模型在不同微架构间的壁垒,最大化跨平台表现和最小化开发成本,以一种对行业及其创新且更有利和开放的方式来实现更加友好的生态系统。
Gelsinger进一步说明了英特尔打算如何在GPU市场上提供有吸引力的产品,并谈到将如何在英特尔平台上实现从集成到分立的无缝过渡。他表示,英特尔聘请了AMD前顶级GPU架构师Vineet Goel来监督GPU产品基于的Xe GPU架构,负责“架构、设计和验证英特尔的Xe IP路线图”。
Xe GPU架构是2020年英特尔在其架构日中首次推出的,Xe微架构可以满足从集成/入门图形需求到数据中心和高性能计算的需求,Xe的推出标志着英特尔向高性能独立显卡领域的扩张。
Xe系列可以细分为集成/低功耗的Xe-LP、娱乐/游戏的Xe-HPG、数据中心/高性能的Xe-HP、高性能计算的Xe-HPC。英特尔独立GPU分为锐炬Xe MAX和服务器GPU,均隶属于Xe LP系列,微架构与核显Xe相同,采用标准封装和10nm SuperFin制程。
目前,Xe-LP的集成版本已经被第11代酷睿所采用。Xe-LP的移动独立GPU版本DG1和服务器独立GPU版本SG1也已发布。未来,英特尔还将推出面向游戏和高性能桌面的Xe HPG产品线,增加光线追踪等硬件支持,采用传统封装,外包生产。英特尔服务器GPU将使用Xe HPC、Xe HP微架构,采用2.5D和3D先进封装,10nm SuperFin及更先进自家或外包工艺。
根据Pat Gelsinger的说法,强调本身在CPU设计本质上的优势,加上目前持续在GPU产品设计上精进,配合oneAPI框架设计,借此针对不同运算需求搭配最佳组合。相比英伟达将主力放在GPU产品设计,英特尔在产品设计将能统筹更多运算应用资源,能以相对更低价格取得,预期能带动更大的规模和使用效益。
从英特尔即将推出的 Xe-HPG 显卡背后的期待来看,英特尔有了一个好的开端。至于与AMD的斗争,Gelsinger认为,英特尔即将推出的Alder Lake和Sapphire Rapids将有可能终结对手近年来的成功。
• AMD双向突围
AMD是全球唯一可以同时提供高性能GPU和CPU的企业,且能够同时提供独立GPU和集成GPU,其集成GPU主要运用在Ryzen APU、嵌入式、半定制平台中。独立GPU分为Radeon和Instinct系列,主要用于游戏、专业视觉、服务器等应用。
AMD近年来的势不可挡之势。“除了Ryzen 5000系CPU的发布,AMD还发布了再次震惊世界的Radeon 6000系列GPU,性能摸到了RTX 3090的水准,可以说一举追平了跟英伟达多年的差距。2019年以来,RDNA架构显卡的成功试水,使得连续三年业绩飘红的AMD在原有市值基础上继续大幅上涨,2022年前,AMD将基于更先进的制程打造RDNA3微架构,进一步强化光追等计算表现。”
过去六年,AMD的计算和图形收入的营收由18.05亿美元上升至64.32亿美元,年复合增速29%。未来五年,AMD计划成为高性能计算的领导者,提供颠覆性的CPU和GPU方案。
从Mercury Research的数据可以看到,经过长达六年的重返数据中心的争夺战,到2021年第一季度,AMD的X86处理器在数据中心的销售份额达到了11.5%,并且制定了可靠的路线图,以应对不断壮大且正在复苏的英特尔的竞争。同时,这对于更愿意组合GPU和CPU的优势互相促进产品销量的AMD来讲,无疑也将给英伟达带来一定程度上的冲击。
综合来看,全球GPU已经进入了寡头垄断的格局。在传统GPU市场中,排名前三的英伟达、AMD、英特尔的营收几乎可以代表整个GPU行业的收入。
独立显卡领域主要由英伟达和AMD控制,而集成显卡领域由英特尔和AMD掌控。就整个GPU市场而言,英特尔在核心GPU上获得桂冠,市场份额为68%,英伟达和AMD为15%上下。
对于英伟达来说,主要对手就是英特尔和AMD,虽然英伟达的独立GPU全球第一,但是其并不具备CPU设计能力,相反AMD一直以来都是CPU和GPU同步发展,而且都还做得不错,专注于CPU的英特尔也开始计划搞独立GPU了,而且英特尔除了X86之外,还押宝了RISC-V,都在针对CPU和GPU同时布局。
因此,押宝Arm成了英伟达一个非常好且不容错过的机会,此举可以让英伟达具备CPU设计能力,也可以做到CPU和GPU同时发展,甚至未来还能和X86展开竞争。可以预见,如果Arm的收购能成功,英伟达将会更加强大。
中国市场的X因素
全球GPU市场表现为寡头垄断下的高增长,年复合增速超过30%,主要市场份额被英伟达、英特尔、AMD等美系企业占领。在此宏观背景下,国产GPU企业蓬勃发展,在GPU软硬件方面同时出击。
国产GPU的发展落后于国产CPU,在国产GPU的开发中,GPU对CPU的依赖性和GPU的高研发难度,阻碍了该产业的快速发展。直到2014年,长沙景嘉微才成功研发出了国内首款国产高性能、低功耗GPU芯片——JM5400,打破了国外产品长期垄断国GPU市场的局面。
中国GPU市场规模和潜力非常大,庞大的整机制造能力意味着巨量的GPU需求。另外,国内在物联网、车联网、人工智能等新兴计算领域,对GPU也存在海量需求。据IDC预测,2024年中国GPU服务器市场规模将达到64亿美元,市场空间巨大。
有观点表示,AI技术的爆发和信创产业的起步给国产GPU带来了真正的发展机遇。
GPU在并行计算、浮点以及矩阵运算方面具有强大的性能,逐渐在高性能计算、云端AI应用等场景中处于主导地位。虽然英伟达在这个领域占据主导地位,由于其产品价格昂贵,且国内对产业链安全的考量,国产通用GPU有着广阔的成长空间。同样,由于信创产业的发展,国内的桌面GPU也得到了难得的发展机遇。
在图形GPU领域,还是以景嘉微、航锦科技等为代表的传统企业为主力。另外,国内从事CPU研发的企业(如兆芯、龙芯等),也开始切入这个赛道,增强了国内GPU企业的整体研发实力。以国产替代为核心驱动力,在政策指引和充足资金保障下,整个信创产业将为国产GPU带来巨大的市场空间,远超以往的军用等专业市场。
虽然国产GPU与主流厂商的差距仍很大,但是GPU国产化的道路仍在持续推进。2021年,景嘉微的JM9系列芯片流片、封装顺利。虽然比此前的量产计划晚了1-2年,但产品研发量产工作仍在稳步推进。JM9系列产品对标英伟达的GTX1080。虽然按之前JM7系列情况看,在使用上可能出现效果打折的情况,但比上一代产品有望实现较大的提升。
国内GPU厂商和产品不完全统计:
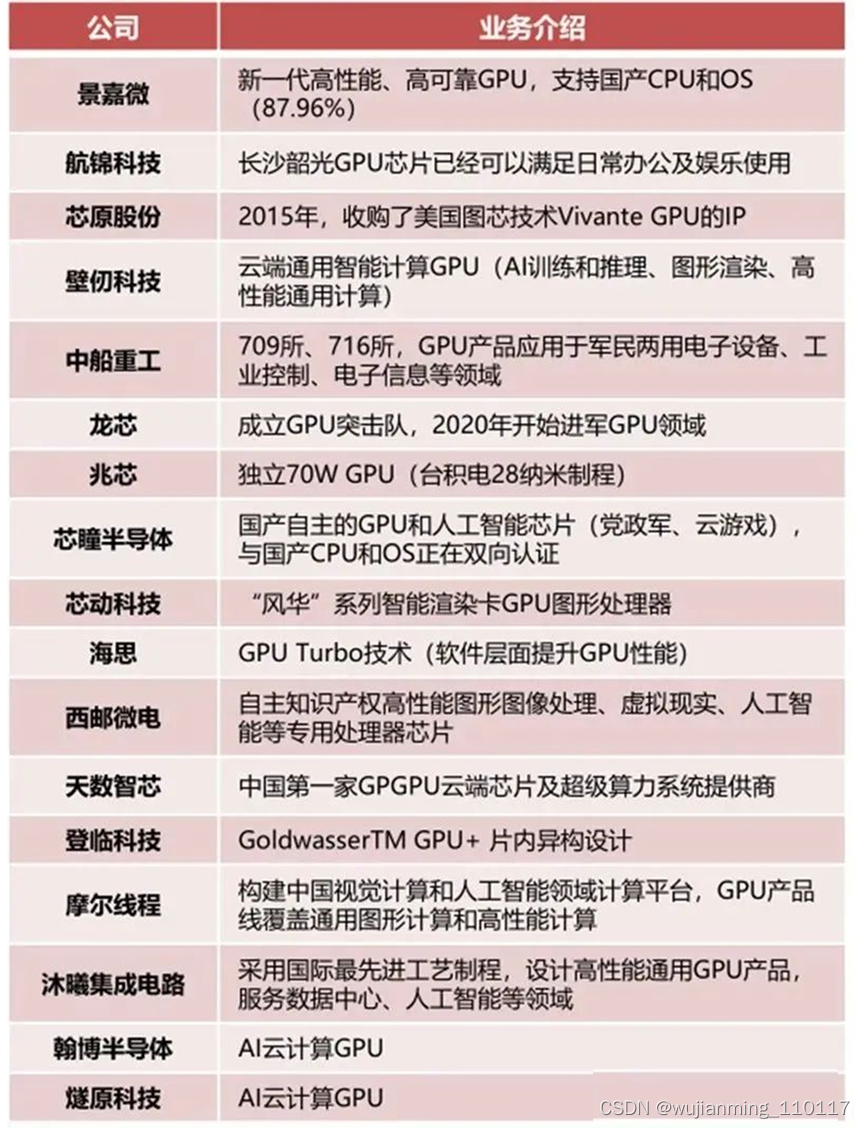
国内GPU厂商不完全统计(如有遗漏,欢迎补充)
当前,国产GPU已经能完成日常办公等基本的任务需求,有望先从军工领域拓展至国内政企办公领域,但是在性能和使用效果方面的差距还是难以打开民用市场。
GPU的使用效果主要受到硬件和驱动两方面的影响。从国产GPU的发展情况看,硬件端的追赶较容易实现,工艺制程、显存位宽、显存大小、时钟频率和显存频率等GPU的外在指标,可以通过逆向开发较快实现。但即使在相同的硬件情况下,GPU驱动也将明显影响使用效果,之前AMD显卡出问题也大多是驱动造成的。因此,对于国产GPU在驱动方面需要更长的时间去追赶。
GPGPU蔚然成风
2018年6月,图灵奖获得者John Hennessy 和 David Patterson发表了《计算机架构新的黄金时代》的主题演讲,提出了特定领域架构(DSA)的概念,旨在为计算机架构带来创新并努力迈向新的黄金时代。
顾名思义,GPU就是用于3D图形领域的DSA,其目标是在3D虚拟世界中渲染照片般逼真的图像。过去20多年里,GPU的基本需求就源于视频加速,2D/3D游戏,图像渲染。
然而,除了3D用途之外,几乎所有人工智能研究人员都使用GPU来探索超越3D图形领域的概念。GPU运用自身在并行处理和通用计算的优势,逐步开拓服务器、汽车、矿机、人工智能、边缘计算等领域的衍生需求。虽然GPU无法离开CPU独立运作,但是在当前“云化”加速的时代,离开了GPU的CPU也无法胜任庞大的计算需求。所以GPU和CPU组成了异构运算体系,从底层经由系统软件和驱动层支持着上层的各种应用。GPU已经成为了专用计算时代的刚需。
将这种设计理念称为通用GPU,即GPGPU,是一种利用GPU处理图形渲染之外通用计算任务的高性能芯片。近年来,在摩尔定律演进的放缓和GPU在通用计算领域的高速发展的此消彼长之下,通用图形处理器(GPGPU)逐渐“反客为主”,利用GPU来计算原本由CPU处理的通用计算任务。
在GPGPU领域,目前各个GPU厂商的GPGPU的实现方法不尽相同,如英伟达使用的CUDA技术、原ATI的ATI Stream技术、Open CL联盟、微软的Directcompute技术。这些技术可以让GPU在媒体编码加速、视频补帧与画面优化、人工智能与深度学习、科研领域、超级计算机等方面发挥异构加速的优势。
以上几种技术中,只有OpenCL支持跨平台和开放标注的特性,还可以使用专门的可编程电路来加速计算,业界支持非常广泛。但是,从市占率角度来看,英伟达无疑是行业的标杆,其不仅拥有百万开发者支持的CUDA,还在指令集的覆盖面、颗粒度、效率等维度有领先优势,早早凭借强大的GPU+CUDA方案切入深度学习领域,用大笔研发投入和时间堆积起坚不可摧的生态城墙,鲜有能与其相提并论的玩家。
在2021年以前,中国企业虽然在一些专用芯片领域多有突破,但在GPGPU领域仍是空白。再考虑到产业生态,国产GPGPU替代还有很长的路要走。以中国的云端AI训练芯片市场为例,最大的供应商为国外厂商,其市场份额达90%。
今年以来,壁仞科技、登临科技、天数智芯等本土厂商在GPGPU市场英伟达一家独大的背景下,相继进行流片量产,正在努力改变现况。除此之外,若想真正实现自主可控,GPGPU创企们还需在CUDA生态的基础上来推广自己的芯片,随着初代国产芯片陆续顺利落地,打造完整的国产核心技术生态体系也将是必经之路。
因其强大的并行处理能力和存储带宽,GPGPU在人工智能市场和高性能市场有广阔的应用空间。有数据预计,到2025年,国GPGPU芯片板卡的市场规模将达458亿元,2019年到2025年的年复合增长率将高达32%。按行业来分,互联网及云数据中心为228亿元,安防与政府数据中心为142亿元,行业AI应用为37亿元,高性能计算为28亿元。
由此可见,从预期市场和国产替代的紧迫性来讲,GPGPU拥有大好前景,一旦突破国际巨头在“硬件+生态”层面的壁垒,本土企业的前景将十分美好。
从GPU行业厂商的动态和布局来看,战火已经燃起,都在谋划着自己的保卫或突击之战。国产GPU厂商的兴起,将给行业带来新的不确定因素,机遇和挑战同样巨大。
最后,引用AI芯天下的观点,谈谈国内GPU行业要克服的“几座大山”:
(1)产品方面。与英伟达等国际巨头相比,国内GPU尚属于起步阶段。在图形GPU方面,国内领先的景嘉微公司,其最新产品也只相当于英伟达几年前的产品水平。未来更多高清3D应用的出现将带来GPU需求的持续增长,对GPU处理能力也是一项不小的挑战,持续改进GPU系统架构和设计方法,提高运算能力和综合显示能力,以应对新形势提出的发展要求。
(2)专利方面。数据显示,全球GPU技术领域专利数量排名前20的公司占有全球70%的GPU专利。英伟达,英特尔和AMD还是GPU技术领域全球专利家族持有数量排名的前三。其中,英伟达持有专利数量占全球总量的近20%。所谓得专利者得天下,本土厂商需要在此发力,构建出可靠的护城河。
(3)在图形领域,GPU对于CPU和操作系统的依附性很强。在GPGPU领域,CUDA生态是国内企业必须要翻越的一座大山。当前的AI开发工程师,多数是在CUDA平台上进行开发的。因此,即使有国产GPU芯片可以实现替代,但要开发者实现迁移则是一项更为艰巨的工作。
(4)近些年,国外GPU技术快速发展,已经大大超出了其传统功能的范畴。国内GPU芯片的研制虽然可满足目前大多数图形应用需求,但在科学计算、人工智能及新型的图形渲染技术方面仍然和国外领先水平存在较大差距,未来持续发展国产GPU势在必行。
国产GPU芯片企业20家
图形处理器(英语:graphics processing unit,缩写:GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。 其中注重算力的服务器和注重便携性的移动端分别采用独立和集成GPU,而汽车、游戏主机、PC等主要采用独立+集成的GPU接入方式。
全球GPU市场表现为寡头垄断下的高增长,年复合增速超过30%,主要市场份额被英伟达等美系企业占领。
当前国产GPU产业链进口替代:设计环节,景嘉微、芯动科技、摩尔线程、沐曦科技等企业正在在不断追赶。芯榜盘点整理了国产GPU企业(约20家),供大家参考:
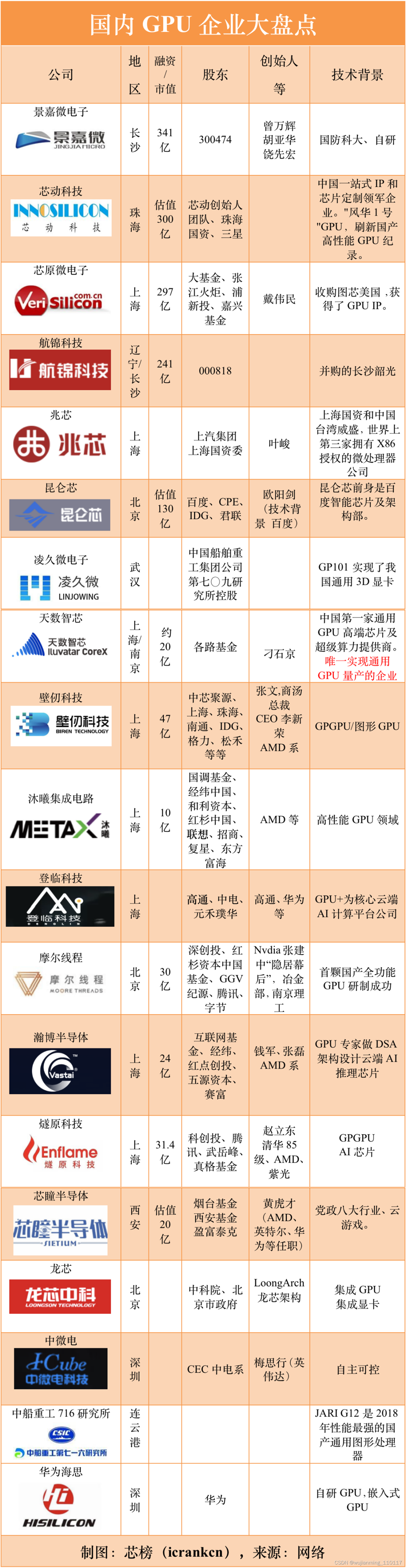
国产GPU的四大难题
编者按:自1956年中国将半导体作为国家重要的发展领域后,今年是第66个年头。回望66年的发展,从无到有、从小到大,半导体产业经历了风雨坎坷同时又迸发出无限的生机。在中国“十四五”提出数字经济发展规划,瞄准集成电路等战略性领域之际,半导体产业纵横推出“国产化进程”系列专题,讲述当今中国半导体各领域发展进程,解析国产化最新态势,本期为“国产化进程”专题集成电路篇第三篇文章:GPU。
近年来,国产GPU频频传出好消息。景嘉微宣布其JM9系列第二款GPU已经完成流片、封装阶段工作。芯动科技在去年底推出一颗“风华1号”,填补了国产4K级桌面显卡和服务器级显卡两大空白。2020年成立的摩尔线程在1年后发布了第一代MUSA系统架构GPU,并可量产交付。壁仞科技也紧跟着宣布首款通用GPU芯片点亮成功。
在市场和政策的推动下,曾经蒙尘的国产GPU开始闪烁自己的光芒。这是国产GPU的黄金时代。

国产GPU的发展到什么地步?
据Verified Market Research数据显示,2020年中国大陆的独立GPU市场规模为47.39亿美元,预计2027年中国大陆GPU市场规模将超过345.57亿美元。
如此广阔的中国市场中,国产GPU的市占比却少的可怜。2019年,中国芯片的自给率仅为30%左右,从中国主要芯片国产化率来看,射频芯片、移动通信终端、模拟芯片、闪存、微控制器、内存、可编辑逻辑器件的国产化率分别为40%、24%、15%、5%、3%、1%、1%。谨慎估计GPU芯片的国产化规模约37亿元。
但属于高端芯片的GPU研发却并不容易。Intel一直想踏足高端GPU领域,但仍未成功。英特尔最早的GPU研发可以追溯到 1997 年,英特尔通过收购C&T 获得了 2D 显示核心技术,3D 技术源于拥有 20%股权的 Real3D。但直到2022年4月,Intel仍未推出自己消费级的独立 GPU 产品。
国内GPU究竟达到国际的什么水平?
从国内GPU龙头景嘉微的产品来看,景嘉微在2021年9月推出的JM9231和JM9271将采用业界主流的统一渲染架构,支持 OpenGL4.5接口,可以无缝兼容市面上主流的CPU、操作系统和应用程序。
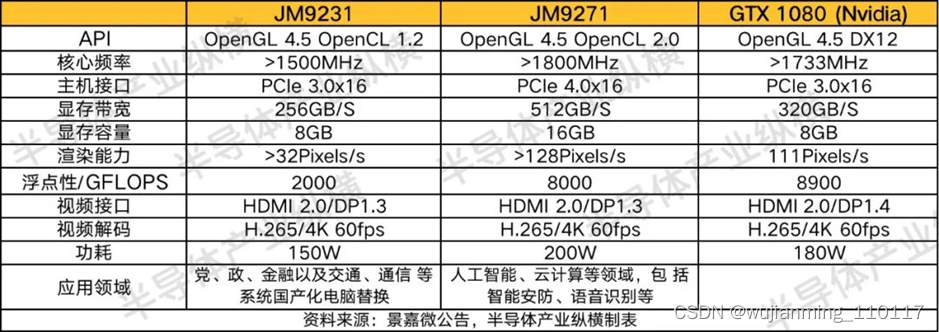
JM9231性能与国际同类公司2016年中低端产品性能相当,主要针对国产化办公电脑,便携式计算机、中低端的游戏机和高端嵌入式系统等消费电子领域。JM9271在JM9231基础上对科学计算能力进行大幅度提高和改进,可以达到国际同类公司2017年中高端产品的性能。
可以看出,相较于国际巨头,国内GPU的性能差距还很远。因此对于中国来说,推动GPU的自主研发刻不容缓。
国产GPU的黄金时代
尽管国内GPU的发展存在很多问题,但现在的时代是国产GPU发展的黄金时代。
正在进入“一切需要可视化的时代”,这几年市场对于GPU的需求增长极快。可视化需要大量的图形、图像计算能力,无论是云端还是边缘侧都需要大量的高性能图像处理能力。
GPU在AI、数据中心领域需求极大。根据IDC数据,2022年全球AI芯片市场将达352亿美元。其中GPU占比最大,Goldman预计到2025年GPU占比将达到57%。
GPU巨头英伟达2022年发布的财报中各项经营指标惊人,2022财年全年营收269亿美元,相比2021财年增加103亿美元,同比增长61%;净利润97.5亿美元,同比增长122%。不管是营收还是净利润,均创纪录 。
无论是客户需求还是供应商的市值变化都在证明——GPU市场正处于火爆时刻。
在2006年,国务院颁布了《国家中长期科学和技术发展规划纲要(2006年-2020年)》,“核心电子器件、高端通用芯片及基础软件产品”(简称“核高基重大专项”)位列16个科技重大专项首位,也被称之为“01专项”,国产GPU位列其中。
国务院印发《新时期促进集成电路产业和软件产业高质量发展的若干政策》,《若干政策》强调,集成电路产业和软件产业是信息产业的核心,是引领新一轮科技革命和产业变革的关键力量。国务院发布的相关数据显示,中国芯片自给率要在2025年达到70%
自2017年以来,多个中国新一代初创型GPU研发公司相继成立,逐渐成为中国GPU历史舞台上的一员。
在图形GPU领域,国内以景嘉微、航锦科技等为代表的传统企业为主力。另外,从事CPU研发的企业(如兆芯、龙芯等),也开始切入这个赛道,增强了国内GPU企业的整体研发实力。
景嘉微是中国第一家成立的GPU公司,公司产品主要分为图形图像处理系统、小型雷达系统、GPU 芯片,广泛应用于军工行业。公司图形显控领域产品包括图显模块和加固类产品,其中图显模块是核心产品。
景嘉微成立当年,恰逢国军用飞机图形显控系统由使用 DSP 与 FPGA 图形加速器向使用 GPU 图形处理器升级,公司准确把握机遇,将大量资源投入飞机图形显控领域的研究。也正因如此,景嘉微最初是制作军工产品起家。
摩尔线程在2020年6月成立,用18个月发布全新统一系统架构MUSA和全能GPU产品“苏堤”等系列新品。其公司创始人兼CEO张建中此前曾任英伟达全球副总裁、中国区总经理,在GPU行业深耕超过15年,带领英伟达开拓建立了GPU在中国的完整的生态系统。
沐曦集成电路在2021年完成数亿元PreA+轮融资,融资由两家“国家队”:国调基金、中网投联合领投,联想创投等多家机构跟投。据称这家高性能通用GPU芯片设计公司的创始团队主要来自AMD等国际公司,拥有从40nm到7nm制程GPU芯片的设计和量产经验。
芯瞳半导体创始团队来自西邮GPU研发团队,这家专注于计算机图形和高性能计算的芯片设计初创公司将在南京投资1.5亿元,开发高性能、高可靠和高稳定性的国产自主GPU和人工智能芯片。
天数智芯自研的一款7纳米GPGPU(通用图形处理器)芯片产品卡——BI成功发布,这是中国第一款全自研且有产品面世的GPGPU的芯片。其首款全自研GPU架构下的7nm云端训练芯片及GPGPU产品卡已亮相,这款芯片采用台积电7nm制程、容纳240亿晶体管及采用2.5DCoWoS晶圆封装技术。
国产GPU发展困境
IP授权
国产GPU最近一段时间借助IP授权多点开花,纷纷流片成功或量产,算是迈出了艰难的第一步。
任何一款高端芯片的打造都离不开IP。一个GPU中行业IP核占用的面积超过了80%。但IP的研发并不轻松,GPU IP自研需要36-48个月以及200个工程师,采用外购IP的方式,可以减少12-18个月开发周期。
芯动科技于去年发布的GPU“风华1号”,其IP购买自英国GPU技术授权公司Imagination。获得架构许可后,芯动科技探索了很多自己的方案,包括自研的Cache一致性Innolink Chiplet技术,内置国产物理不可克隆iUnique Security PUF信息安全加密技术等。因此“风华1号”GPU80%以上的IP都属于自主研发。
外购IP加上自研设计非常有利于商业变现,可以快速获得成熟系统和后端版图,同时也有利于快速构建软件栈和底层工业API适配,极大的降低研发周期和风险。如今国内主要的通用计算+图形GPU创业公司,如芯动、摩尔线程、壁仞等等都使用Imagination IP或者芯原授权的IP。但使用IP授权也有缺点,即核心电路专利无法自控和自主迭代。
创业热潮下的生产困境
随着GPU成为AI计算的必需品,一波GPU创业潮在中国市场兴起。据统计仅2020~2021年,GPGPU领域就有近20起融资事件发生。2018年12月瀚博半导体在上海成立,目前已经完成总计5000万美元的A轮融资;2019年成立的壁仞科技,在2021年3月完成了B轮融资,18月累计融资超过47亿元;同年11月芯瞳半导体成立;2021年,沐曦集成电路宣布完成10亿元人民币A轮融资。
但初创之下国产GPU仍然面临生产困难。目前和AI相关的大芯片,因为需要CoWoS等先进封装,所涉及的中介层原材料非常紧缺,在目前产能吃紧的情况下,对于已经推出一些产品的初创GPU企业,会面临短期盈利的问题。
并且GPU市场早已被虎视眈眈的英伟达、AMD包围,中国GPU芯片初创公司需要和这些拥有技术、经济实力的巨头竞争,必然是处于劣势。
成本难降,量产数量少
芯片量产前还要经历冗长的设计测试流程。通常一款高端芯片前端和后端设计要耗13年,设计完成后流片环节需要36个月,期间还会有流片失败一切重来的风险。即使成功流片,还需经过3~12个月的产品测试调优,才能开启量产。
因此尽管越来越多的GPU厂商涌入,但阵阵喧闹过后,市场上仍未见可与国际巨头对标的量产产品。
国内GPU生态突围
此外,对于国产GPU来说,产品如何实现规模化商用,搭建国产GPU生态同样是一个难题。芯片的成功和成熟需要大量的验证和出货,而找到可持续的落地场景才是长期发展的关键驱动力。
ICViews采访业内人士其表示:“目前国产GPU在相同性能下,价格更贵。同时,由于英伟达等国外龙头推出GPU时间更长,长期使用国外GPU的厂商出于惯性也不会突然更换国产GPU。”

尚未成熟的GPU在搭建国内生态上也捉襟见肘。
风口之下,国产GPU如何发展?
GPU是一个高技术含量的赛道,而且国在这一领域发展已经落后许久。尽管近年来突然开始有不少初创公司踏足GPU领域,并受到资本青睐,但国想要彻底打破GPU垄断并不是一件易事。
GPU 设计是一项系统工程,包含硬件架构、算法、软件生态等多个组成,缺一不可。从GPU的发展历程来看,GPU单芯片算力增长速度超过CPU,在算力竞争上,GPU也比CPU更胜一筹。
沐曦集成电路CEO陈维良曾表示:“全球高性能GPU市场被国外公司垄断,核心算力芯片受制于人,国家安全以及国计民生存在巨大的不可控风险,国产替代势在必行。”
在市场、政策的推动下,国产GPU百花齐放,这将是国产GPU最好的时代。
国产高端GPU芯片来了!GPU市场迎变数
GPU IP巨头Imagination中国战略市场及生态副总时昕博士在一场演讲中曾说道。
那究竟什么是GPU呢?维基百科定义,GPU中文名为图形处理器,是一种在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。

VR、区块链、3D建模、渲染等一切跟图像有关的处理过程都需要GPU。当下最热门的元宇宙,集以上图像处理需求大成,对GPU的需求也不言而喻。除了图形处理功能,GPU还是目前公认最好的AI加速器,尤其是在云端训练大模型应用场景中。更有意思的是,在自动驾驶的赛道上,GPU也杀了进来:全球GPU龙头英伟达正对接越来越多的车企合作订单。
只要有高清画质需求,只要有AI处理需求,就离不开GPU。因此,随着这两大需求的持续增长和巨大的市场想象空间,全球GPU龙头英伟达凭借GPU芯片的优势,市值就高达7410亿美元(约合人民币47198亿元,截至2021年12月23日),晋升为当下全球市值最高的半导体企业。
GPU芯片研发有多难?
GPU需求大,价值高,反观国内芯片企业在该领域却进度缓慢。目前中国在桌面和移动端领域的GPU供应基本被英伟达、AMD、ARM垄断,国产GPU是个巨大的蓝海市场且鲜有企业涉足。
近年来,在市场和国家战略替代的需求下,国内掀起一股“GPU投资热潮”,涌现了一批国产GPU初创企业。尽管投资热度高涨,国内初创企业多以技术难度更低的通用计算型GPU(GPGPU)切入赛道,能做高性能商业化的渲染GPU产品的企业依旧凤毛麟角。
这么重要的芯片为何鲜有国产企业踏足,GPU难在哪里呢?

芯动科技展示的“风华1号”GPU在ICCAD上引发了强烈关注
在12月23日落幕的“中国集成电路设计业2021年会暨无锡集成电路产业创新发展高峰论坛(ICCAD 2021)”上,国内芯片企业芯动科技公开展示了其今年11月最新发布的首款国产高性能4K级显卡GPU芯片——“风华1号”,引发了业内人士的强烈关注,盛赞芯动科技是“中国版的英伟达”。以芯动科技为样本,综合其“风华1号”发布会上的介绍,或能解答这一问题。

芯师爷从不久前举办的“风华1号”发布会上了解到,“风华1号”GPU在多个领域表现上取得了第一,如第一款渲染能力达到5T-10T FLOPS的国产GPU显卡;第一款图形API达到OpenGL4.0以上,并能实际演示4.0 benchmark的GPU;还是第一款支持多路渲染+编解码+AI服务,硬件虚拟化和chiplet可延展的国产GPU等。

芯动云计算总裁敖海先生发布“风华1号”GPU芯片
芯动科技SoC体系架构师何颖提及,单从算力对标的话,采用“风华1号”双芯片的显卡可对标英伟达T4系列产品。换而言之,“风华1号”是一颗“真正”的高端国产GPU芯片,即便是对标全球GPU龙头企业产品也不遑多让。
据芯师爷复盘“风华1号”的研发之路,发现国内企业做GPU主要有两大难,一是难在专利壁垒;二是难在GPU芯片的体系化创新。
在专利壁垒方面,GPU是先进制程数字芯片,对于GPU企业来说,高技术含量的自有IP的持续演进是技术自主和市场竞争优势的保障。但在该领域起步早的全球GPU巨头们已筑建了层层专利保护墙。以GPU架构IP专利为例,就连全球科技领头羊企业苹果,在该领域也绕不开专利授权:苹果从A4到A10X所有处理器芯片都是采用Imagination的IP,到A10之后苹果通过架构授权,有了自己的GPU架构把控,依然是基于Imagination的TBDR架构专利授权,隶属于该架构分支。但一旦架构授权后独立演进了,也就不再被专利卡脖子了。
在GPU芯片设计方面,GPU也绝非简单的芯片设计,其设计较一般芯片更复杂,系统更庞大,涉及面更广。做GPU需要极其专业的团队,团队从前到后要包圆,做到软硬全栈。专业人才要涵盖架构、算法、硬件、软件以及各种验证方式,包括后端、版图、驱动、测试、机械结构、生产、供应链等领域。这意味着,GPU研发团队需要在全链条节点上都配备丰富的量产经验人才,才能完成这样非常商业化的体系。
为何是芯动科技突围而出?
芯动科技从0-1直接突围高端GPU芯片的研发,这样的成果值得溯源与反思:为什么是芯动科技一鸣惊人,突破了国内企业做GPU芯片的困局?
芯师爷了解到,芯动科技是中国一站式IP和芯片定制及GPU领军企业,成立至今已15年。15年间芯动科技作为幕后英雄,为各国产半导体代工厂和300家全球知名客户提供顶尖IP和芯片定制,协助了包括瑞芯微、君正、微软、AMD、亚马逊等知名公司各种芯片量产,而且所有技术自研可控,能持续迭代,不断超越。逾50亿颗先进SoC芯片成功推向市场的背后,比如大家每天用的轨道交通身份证识别和全球顶级示波器,都有用到芯动科技的IP技术。广泛的合作使得芯动科技在To B的圈子非常知名,更值得一提的是,在芯片IP领域,芯动科技还是TSMC 2021全球研讨会认可的唯一大陆合作伙伴,其技术和量产积累之深厚可见一斑。
正是在为各合作伙伴提供IP和芯片定制期间,芯动科技积累了GPU所需要的全套高端IP、图形芯片内核定制技术和先进工艺经验,形成了从工艺到设计,到器件,到量产,到封装,到整机的完整芯片设计验证条流程。这为“风华1号”GPU芯片的研发奠定了稳固的基础。芯动科技SoC体系架构师何颖透露,“风华1号”集成了GDDR6/6X、PCIe 4、Chiplet Innolink、HDMI 2.1 、Display port 、VDAC、PLL、TV Sensor、PUF等高端自研IP技术,IP全自主研发,远高于友商。
其中,GDDR6/6X、Chiplet Innolink均为GPU业内顶尖技术。以GDDR6X技术为例,GDDR6X并非简单的超频技术,为了数据密度更高,使用了32位并行单端PAM4技术,比业界常见的串口差分PAM4技术,难不止一个数量级,全球除了英伟达,一个公司都做不出来,每个时钟周期可以传输多次数据——数据吞吐量越大,芯片并行计算能力越大,GPU能够同时渲染的像素点越多,画质越清晰。使用GDDR6X技术可满足4K高刷新率画面需求;在提升接口数据传输速率的同时,实际内核频率甚至可以做到比上一代技术更低一些。
GDDR6X显存技术研发难度极高,目前全球只有英伟达和芯动科技两家拥有。芯动科技GDDR6X研发负责人高专表示,GDDR6X的PAM4并行技术是英伟达与美光在一栋楼里共同研发两年才研发出来,而芯动团队是全球唯一一家,仅凭有限的远程技术支持,只用一年时间就做出来了,连AMD目前都还没有做到成功研发该技术。这都是基于芯动科技团队十多年的技术基础积累和200次流片打磨的经验。
此外,为了保持技术的领先,芯动科技还立足全球和GPU全产业链,持续引入了大量GPU领域顶尖专业人才。
芯动首席算法科学家杨喜乐博士是顶级的架构师,她自从博士毕业之后,曾在英国Imagination公司担任架构师,过去的25年间一直从事GPU核心图形引擎的建模和创新,是全球GPU芯片领域从几何物理渲染到计算引擎领域的知名专家,持有GPU 3D计算机图形学核心领域顶级图形专利共计125项,目前Imagination、苹果等公司最新的核心GPU产品的设计、优化和迭代都离不开她的专利和算法。在芯动科技的邀请下,她回国投身国产GPU图形引擎的持续创新。

芯动首席算法科学家杨喜乐博士
在芯动科技GPU专家团队的努力下,“风华1号”GPU架构目前已在Imagination GPU的架构授权下,自主研发了两代,把原生移动端的架构拓展到了高性能计算、云计算的场景,在架构自主可控上不存在被“卡脖子”风险。
芯动科技DX团队负责人章涛也是其从海外招揽的技术大咖。据悉,章涛是来自前AMD的图形框架开发的领军人物。他表示,“投身芯动开发GPU软件感觉非常棒!芯动团队从老板到员工,都在专心做事。”章涛透露,明年芯动科技就会发布风华显卡Windows操作系统的DX框架。
芯动云计算总裁敖海在“风华1号”发布会上曾这样总结:“‘风华1号’凝聚了芯动科技自有的众多技术积累,又有世界著名GPU公司顶尖人才的联合参与的加持,是芯动人努力和成果的结晶,也是芯动科技完成‘让风华GPU走进千家万户,让大家习惯用国产的GPU办公和娱乐’使命的开端。风华系列GPU赋能国产生态正加紧奋勇向前,目前芯动科技正在加紧与合作伙伴进行‘风华1号’适配调优,在向数据中心和国产桌面GPU 等合作伙伴送样的同时,风华2号和3号已经在路上了。”
在半导体供应链面临不确定风险的产业环境下,芯动科技瞄准高速成长的高清画质云渲染和元宇宙需求,推出的“风华1号”正当其时,填补了国产4K级桌面显卡和服务器显卡两大空白,为国产新基建5G数据中心、桌面、元宇宙、云游戏、云桌面等千亿级产业提供了有力支持,值得国产半导体产业为其喝彩。
同时,也该注意到,罗马不是一天建成的,发展中的中国GPU产业和国际巨头之间仍有不小的差距。芯动科技选择的是既充满机遇、又充满挑战的GPU市场,未来国产GPU生态的长期发展也需要国产GPU产业链企业的持续支持。
巨大的研发费用和长期资本开支,在已经多年持续盈利的芯动科技看来,并非很大挑战。芯动科技工程副总毛鸣明认为,硬科技要“十年坐得板凳冷”,需要长期打磨,不是像互联网靠砸钱就能成功的,投资人需要非常清楚这一点。长远来看,国产GPU芯片技术突围最终还是需要靠经年累月的迭代和优化, 通过不断试错,走进应用于千家万户的终端产品供应链中取胜。
芯动科技SoC体系架构师何颖也表示:“芯动科技是全球6大晶圆代工厂签约支持的技术合作伙伴,有着众多自研IP和强大稳定的团队执行力,在多年的持续奋斗中,芯动科技在跨工艺研发和供应链能力上极具优势,令合作客户长期受惠。而国产GPU上下游产业链的长期、持续商用也会成为芯动科技GPU芯片发展的强大驱动力。未来,芯动科技将根据产业链客户需求,为风华系列GPU产品找到更多可持续落地场景,完成让风华GPU走进大家生活的使命。”
参考文献链接
https://mp.weixin.qq.com/s/BctPZOl69XDkwa-zQuC6KA
https://mp.weixin.qq.com/s/tLl4v_d09CMKXzpukST_oA
https://mp.weixin.qq.com/s/QKNhsQnIYd3gCODDpYCMJA
https://mp.weixin.qq.com/s/lmdeB70oIT_reZGN4zJUng
https://baike.baidu.com/item/%E5%9B%BE%E5%BD%A2%E5%A4%84%E7%90%86%E5%99%A8/8694767?fromtitle=gpu&fromid=105524&fr=aladdin