GPU技术与动态
图形处理器(英语:graphics processing unit,缩写:GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。
GPU使显卡减少了对CPU的依赖,并进行部分原本CPU的工作,尤其是在3D图形处理时GPU所采用的核心技术有硬件T&L(几何转换和光照处理)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬件T&L技术可以说是GPU的标志。GPU的生产商主要有NVIDIA和ATI。
一个光栅显示系统离不开图形处理器,图形处理器是图形系统结构的重要元件,是连接计算机和显示终端的纽带。
应该说有显示系统就有图形处理器(俗称显卡),但是早期的显卡只包含简单的存储器和帧缓冲区,它们实际上只起了一个图形的存储和传递作用,一切操作都必须由CPU来控制。这对于文本和一些简单的图形来说是足够的,但是当要处理复杂场景特别是一些真实感的三维场景,单靠这种系统是无法完成任务的。所以后来发展的显卡都有图形处理的功能。它不单单存储图形,而且能完成大部分图形功能,这样就大大减轻了CPU的负担,提高了显示能力和显示速度。随着电子技术的发展,显卡技术含量越来越高,功能越来越强,许多专业的图形卡已经具有很强的3D处理能力,而且这些3D图形卡也渐渐地走向个人计算机。一些专业显卡具有的晶体管数甚至比同时代的CPU的晶体管数还多。比如2000年加拿大ATI公司推出的 RADEON显卡芯片含有3千万颗晶体管,达到每秒15亿个象素填写率。
本文参考文献链接
https://mp.weixin.qq.com/s/ANOEtc6-0vNuJfhtO9S6Og
https://mp.weixin.qq.com/s/tLl4v_d09CMKXzpukST_oA
https://mp.weixin.qq.com/s/lmdeB70oIT_reZGN4zJUng
https://mp.weixin.qq.com/s/8_Cw6lhFC4nvQTfL_Jd81A
https://baike.baidu.com/item/%E5%9B%BE%E5%BD%A2%E5%A4%84%E7%90%86%E5%99%A8/8694767?fromtitle=gpu&fromid=105524&fr=aladdin
英伟达的这款GPU太强了!
今年 3 月 21 日 - 24 日举办的 NVIDIA GTC 2022 大会可谓是亮点十足。NVIDIA 不仅一口气更新了 60 多个 SDK 应用程序,继续加大在 Omniverse、机器人平台、自动驾驶和量子计算等领域中的布局 ,还重磅发布了基于全新 Hopper 架构的 H100 GPU!
Amusi 听说 H100 性能炸裂,应用在 AI 领域上会有数倍的性能提升。看看这一波刷屏的 Hopper 架构和首款产品 H100 GPU 究竟有多强!据了解,NVIDIA H100 将于 2022 年第三季度起开始供货,也期待能尽快上手实测一波~

图1 NVIDIA H100 GPU
首款 Hopper 架构 GPU:H100
NVIDIA 每代 GPU 的架构命名都是有出处的,今年 Hopper 架构是以计算机科学家先驱 Grace Murray Hopper 的姓氏命名(Hopper 为夫姓)。她是世界最早一批的程序员之一,也是最早的女性程序员之一,而且创造了现代第一个编译器 A-0 系统,以及第一个高级商用计算机程序语言 “COBOL” ,还被誉为 “COBOL 之母” ,据说是世界上第一个发现【bug】的人,debug 这个词也因此诞生。

图2 1960年在 UNIVAC 键盘前的 Hopper
一图看尽 Hopper H100 GPU 上的六大项突破性创新:
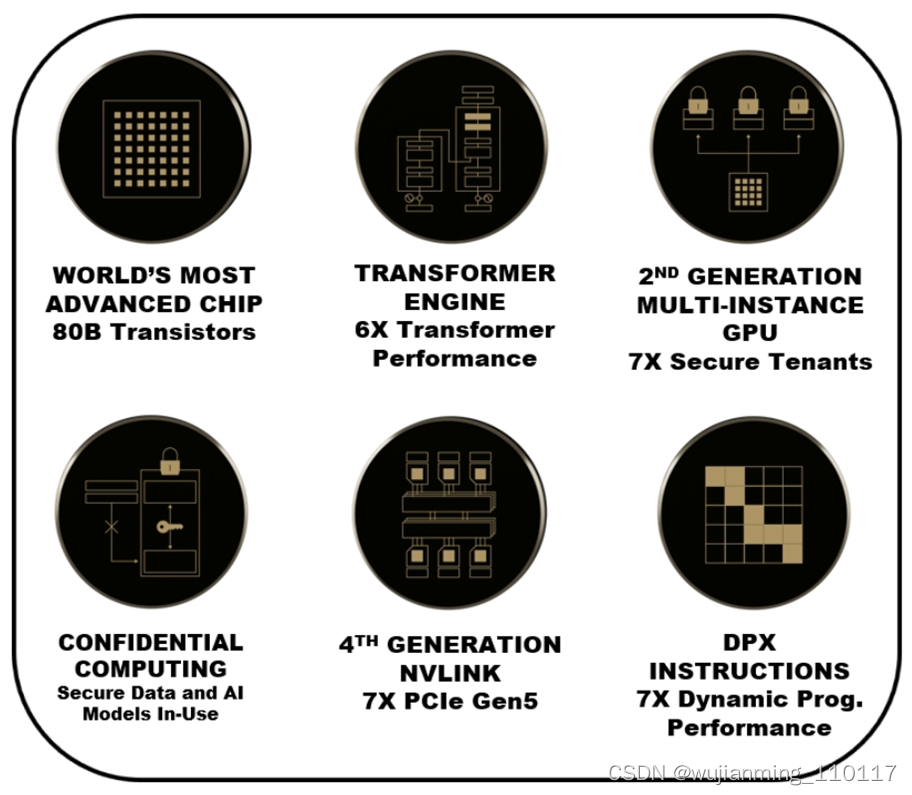
图3 H100 上的六大项突破性创新
- 集成超过 800 亿个晶体管(台积电 4nm 工艺)
- Transformer Engine
- 第二代 MIG:多实例 GPU(Multi-Instance GPU)
- NVIDIA 机密计算(Confidential Computing)
- 第四代 NVLink
- 全新 DPX 指令
NVIDIA H100 GPU 硬件上的参数太炸裂,比如有:英伟达定制的台积电4nm工艺、单芯片设计、800 亿个晶体管、132 组 SM、16896 个 CUDA Core,528 个第四代Tensor Core,3TB/s 的 HBM3 显存等等。
特别值得提一下:4 nm 工艺使得 H100 时钟频率速度增加了 1.3 倍,SM 数量增加了 1.2 倍。

图4 GH100 Full GPU with 144 SMs
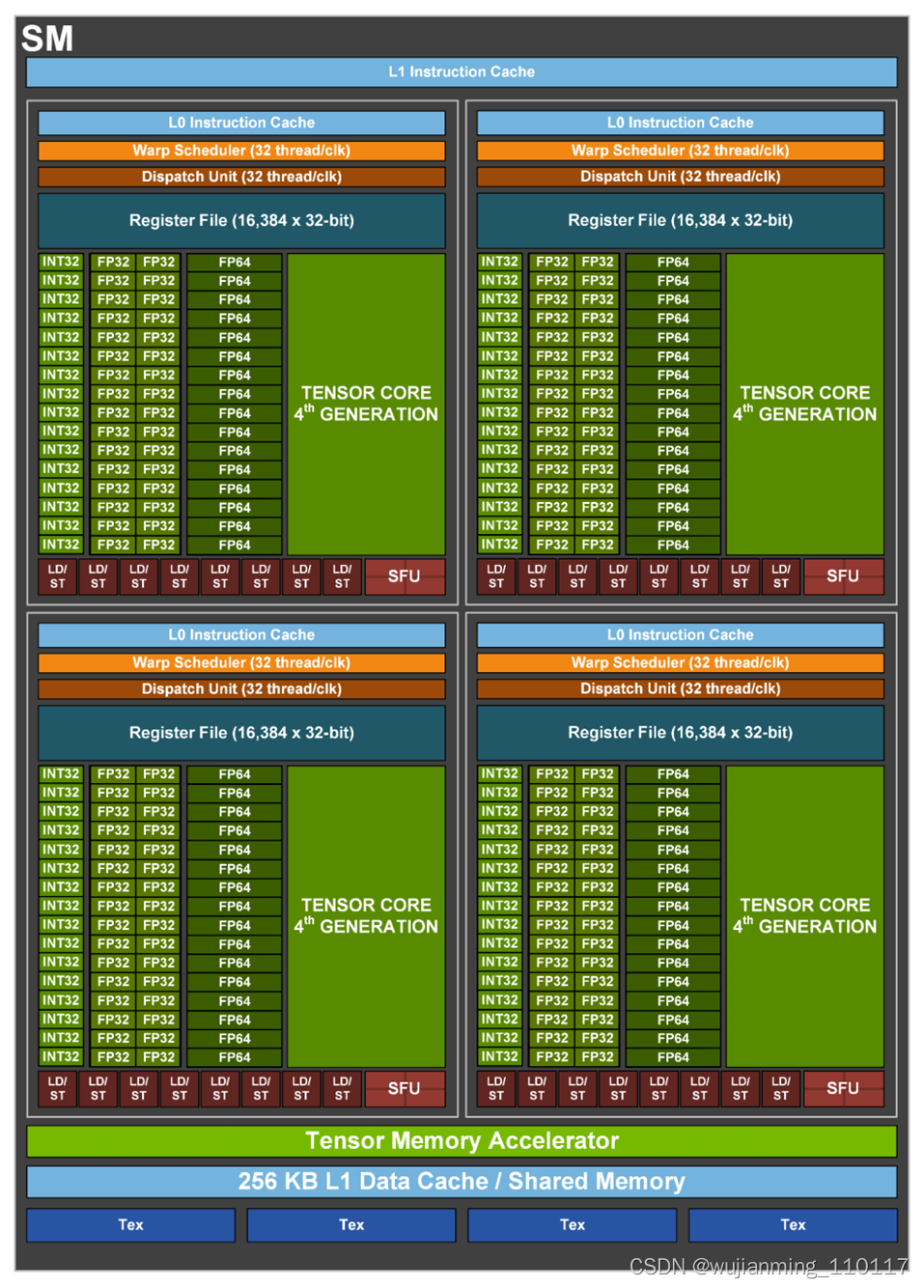
图5 GH100 Streaming Multiprocessor (SM)
更多硬件参数这里就不展开说了,感兴趣的同学可以直接看 NVIDIA H100 白皮书深入了解。这里重点介绍 NVIDIA H100 GPU 在 AI 上的性能突破。
与上一代 A100 相比,H100 的 AI 性能更加强大。在计算机视觉、自然语言处理等领域,H100 比 A100 的性能增强数倍,部分数据如下图所示:
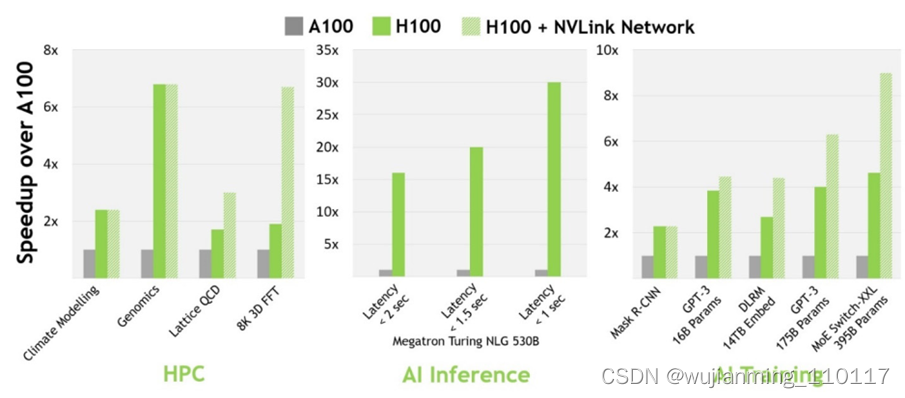
图6 H100 实现 AI 和 HPC 突破
第四代 Tensor Core Architecture
第四代 Tensor Core 是 H100 AI 性能提升的一大神器!Tensor Core 是用于矩阵乘积和累加(MMA)数学运算的专用高性能计算核心 ,可为人工智能(AI)高性能计算(HPC)提供突破性的性能加速。第一代 Tensor Core 首次出现在 Volta 架构,从 Volta 到 Turing、Ampere 再到2022 最新的 Hopper 架构,Tensor Core 已经发展到了第四代。
H100 GPU 中特别加入了 FP8 Tensor Core 来加速 AI 训练和推理。与上一代 A100 GPU(Ampere 架构)上的 FP16 相比,FP8 精度可提供高达 6 倍的性能。

图7 H100 FP8 和 A100 FP16
FP8 Tensor Core 支持 FP32、FP16 累加器和两种新的 FP8 输入类型:E4M3 和 E5M2。E5M2 是与 FP16 保持相同的动态范围,但精度大大降低,而 E4M3 精度稍高但动态范围较小。Tensor Core 中的 FP8 matrix 可以累加成 FP16 或 FP32,并且根据神经网络中的偏差,进一步输出转换为 FP8、BF16、FP16 或 FP32 格式。
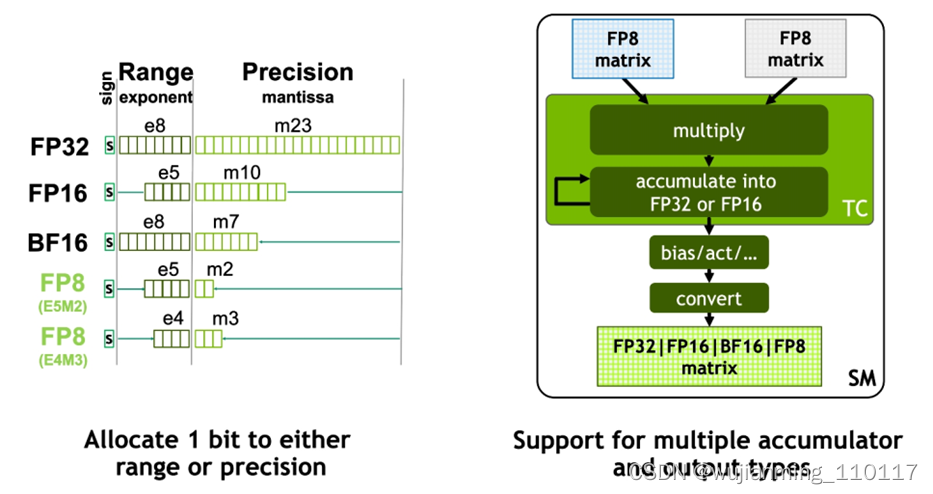
图8 Hopper FP8
除了新增的 FP8 有恐怖的性能之外,第四代 Tensor Core 还整体加强了 FP16、FP64、TF32 和 INT8 等 Tensor Core。基本都是 3 倍及以上的性能提升,具体参数如下图所示(太强了):
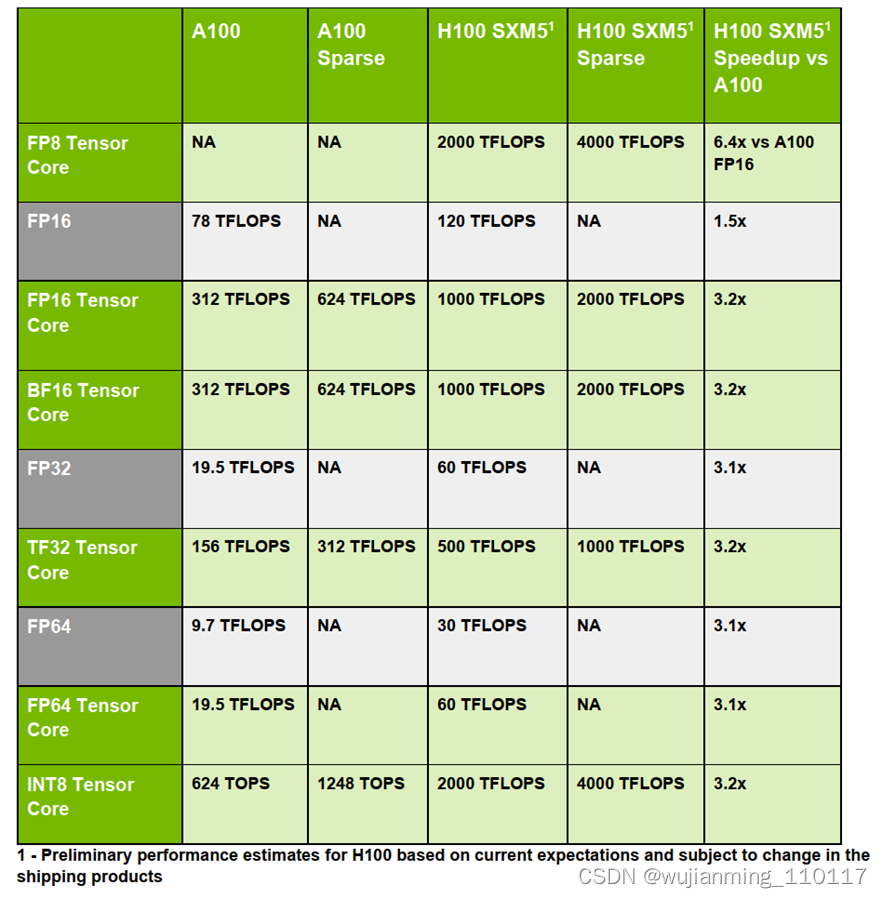
图9 H100 和 A100 Tensor Core对比
Transformer Engine
这里要重点聊聊 NVIDIA H100 最新推出的 Transformer Engine!
先介绍一下 Transformer 是什么来头?AI 领域的人应该都知道,但还是要强调一下其重要性(不然也不会特别推出定制版的 Engine)。
2017 年,Transformer 横空出世!快速席卷并统治了自然语言处理(NLP)领域;接着 2020 年,Vision Transformer 横空出世,成功将 Transformer 应用到了计算机视觉(CV)领域,目前也是屠榜了 CV 领域中的很多方向,比如目标检测、图像分割、目标跟踪等;而且 Transformer 在音频/语音、药物发现等领域也都有广泛应用。
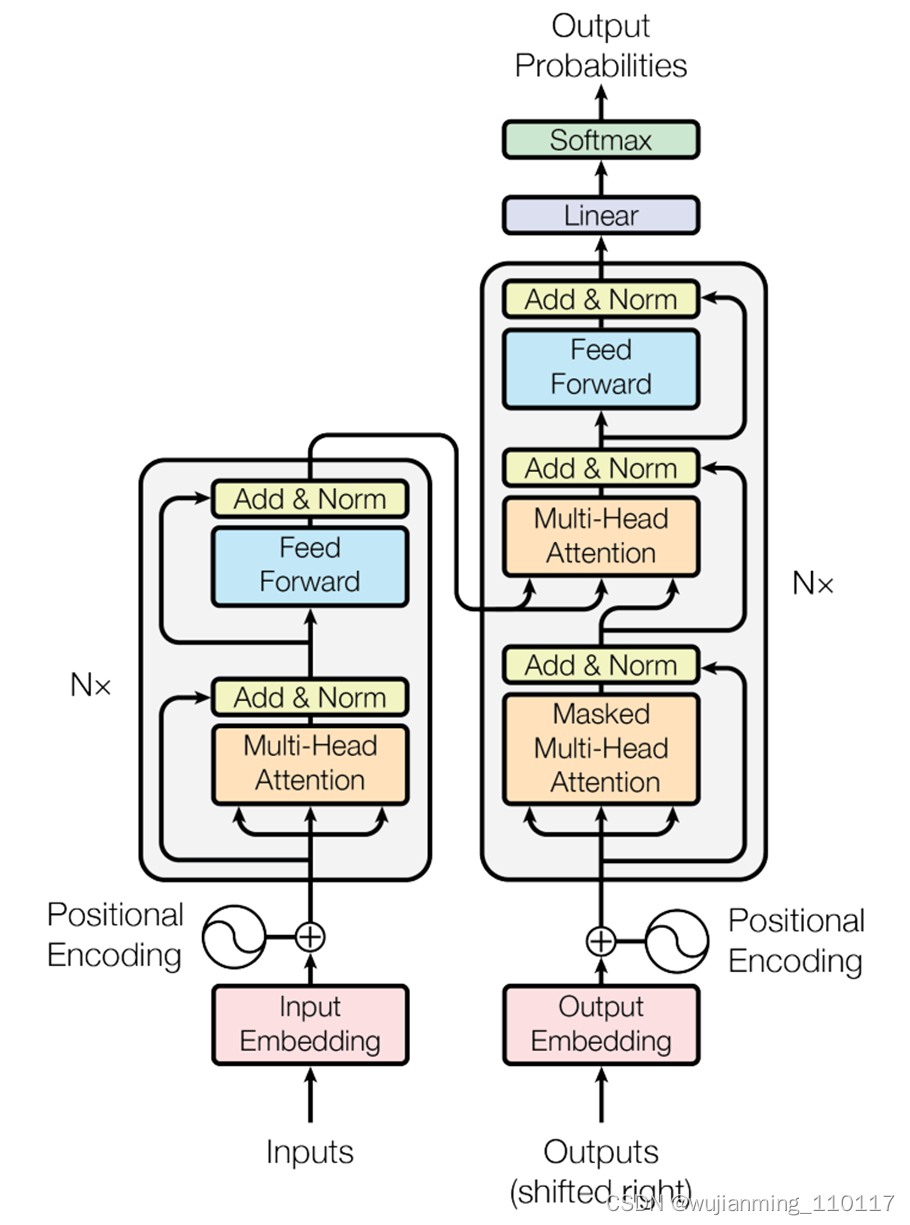
图10 Transformer 架构
可见 Transformer 已经成为 AI 领域中举足轻重的通用模型,但由于在过去五年中,Transformer 模型大小的增长速度比大多数其他 AI 模型快得多,每两年接近增长 275 倍,所以 Transformer 网络的训练时间会很长,而且部署应用也会因为算力原因受到很大限制。
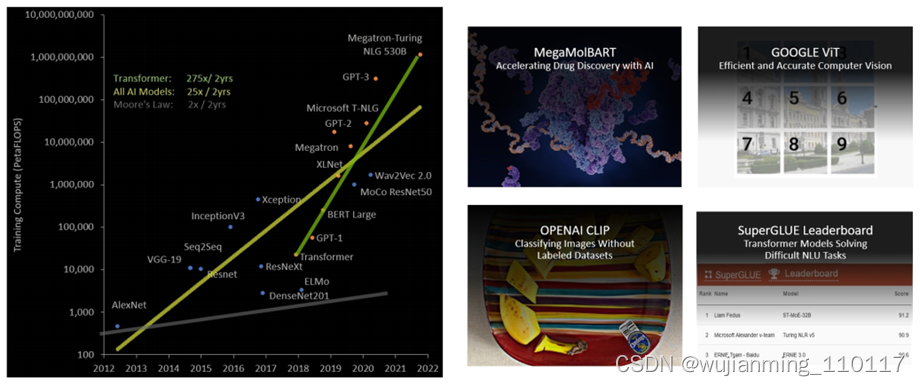
图11 Transformer 模型大小呈指数增长
为此,NVIDIA 特别打造了 Transformer Engine:一项由软件和定制的 Hopper Tensor Core 硬件相结合的专门用于加速 Transformer 模型计算的技术。Hopper Tensor Core 能够利用混合的 FP8 和 FP16 精度格式,减少内存使用,大幅加速 Transformer 训练的 AI 计算,同时保持准确性。
具体工作原理:在 Transformer 模型的每一层,Transformer Engine 都会分析 Tensor Core 产生的输出值的统计数据。了解了接下来会出现哪种类型的神经网络层以及它需要什么精度后,Transformer Engine 还会决定将 Tensor 转换为哪种目标格式,然后再将其存储到内存中。FP8 的范围比其他数字格式更有限。为了优化使用可用范围,Transformer Engine 还使用从 Tensor 统计中计算出的缩放因子(Scaling Factors)动态地将 Tensor 数据缩放到可表示的范围内。因此,每一层都在会其所需的范围内运行,并以最佳方式加速。
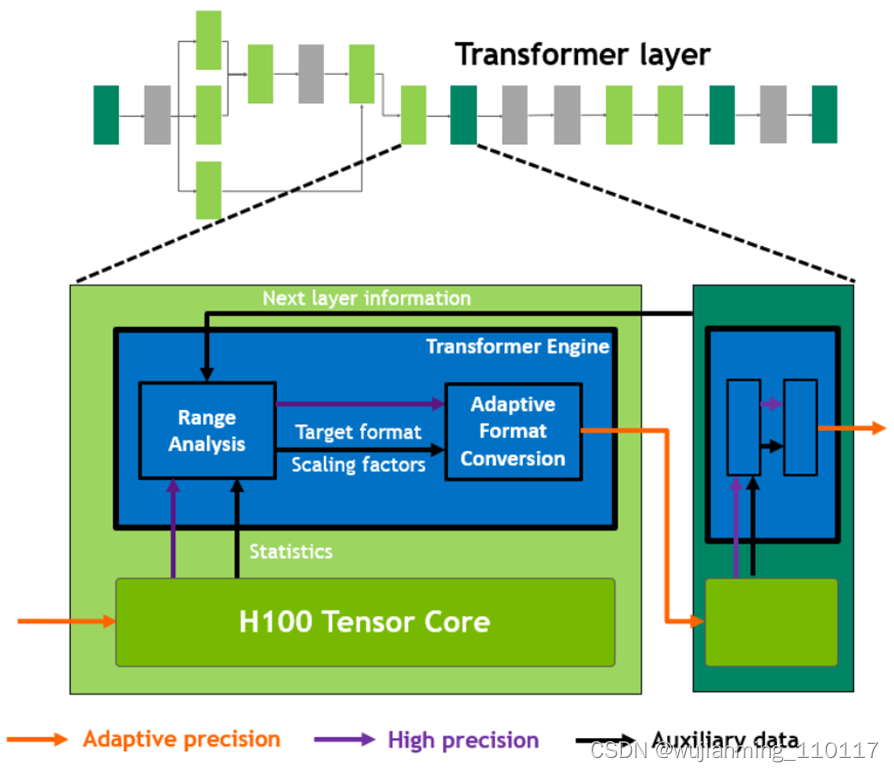
图12 Transformer Engine 概念操作
借助全新 Transformer Engine 和基本硬件参数提升使 H100 在大型语言模型上的 AI 训练速度提高了 9 倍,AI 推理速度提高了 30 倍。
下面举几个例子,1750 亿参数的 GPT-3 训练时间从 5 天缩短至 19 个小时;3950 亿参数的混合专家模型训练时间从 7 天 缩短至 20 个小时。
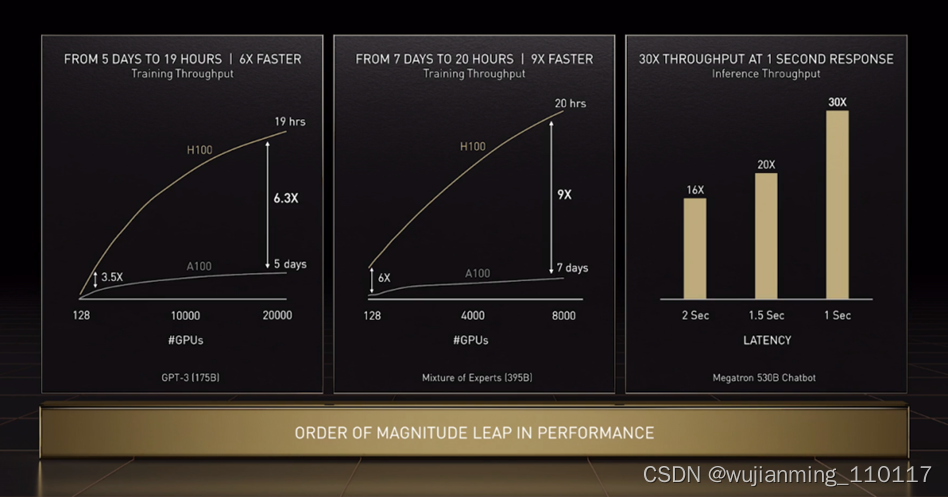
图12 GPT-3/MoE/Megatron
上面介绍的第四代 Tensor Core 和 Transformer Engine 对于 H100 的计算性能(Compute Performance)提升尤为重要,如下图所示:
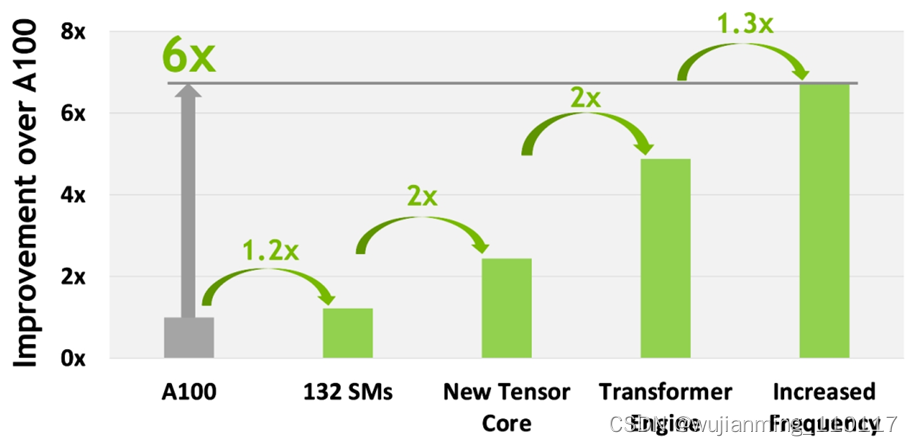
图13 H100 计算性能改进
DPX 指令
NVIDIA H100 新推出的 DPX 指令可以将动态规划(Dynamic Programming)的性能提高多达 7 倍,可大大加快疾病诊断、物流路径优化和缩短图分析的时间。
下图展示的两个示例包括用于基因组学和蛋白质测序的 Smith-Waterman 算法,以及用于为机器人车队在动态仓库环境中寻找最佳路线的 Floyd-Warshall 算法。
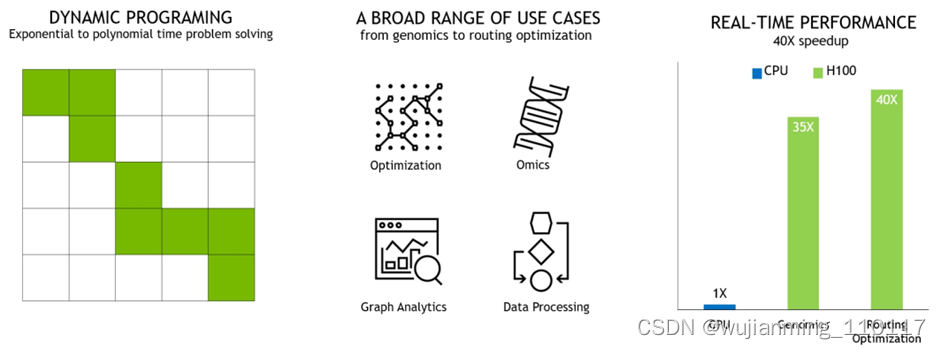
图14 DPX 指令加速动态规划

图15 用于基因组测序的 Smith-Waterman 算法
第四代 NVLink 和 第三代 NVSwitch
NVLink 是 NVIDIA 开发的一种高带宽、节能、低延迟、高速 GPU 互连技术,能够实现显存和性能扩展。

图16 NVIDIA NVLink
NVIDIA NVLink 第四代互连技术与上一代 NVLink 相比,通信带宽增加了 50%。H100 包含 18 条第四代 NVLink 链路,可提供 900 GB/秒的总带宽,是 PCIe Gen 5 带宽的 7 倍。
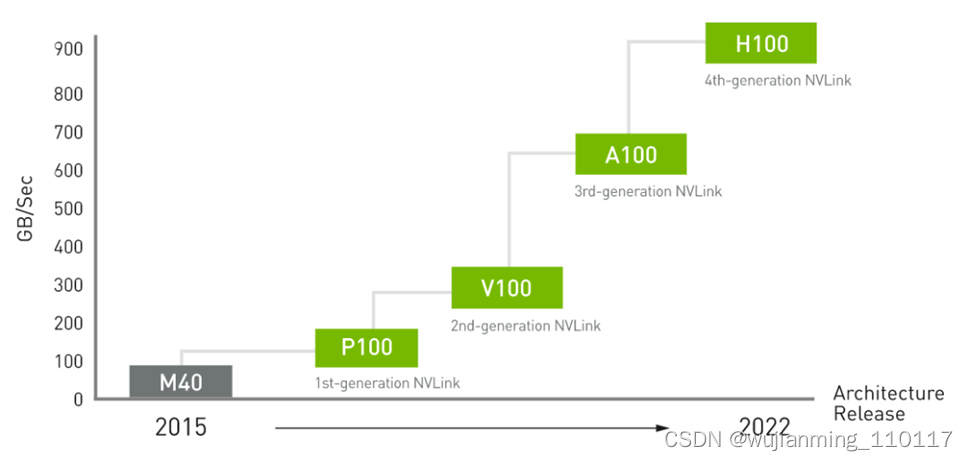
图17 NVLink 性能改进
第三代 NVSwitch 技术包括位于节点内部和外部的交换机,用于连接服务器、集群和数据中心环境中的多个 GPU。每个 NVSwitch 提供 64 个第四代 NVLink 链路端口,以加速多 GPU 连接。总交换机吞吐量从上一代的 7.2 Tbits/sec 增加到 13.6 Tbits/sec。新的第三代 NVSwitch 技术并配有 NVIDIA SHARP 引擎,可用于网络内归约和组播加速。
新的 NVLink Switch System
为加速大型 AI 模型,可以将第四代 NVLink 和第三代 NVSwitch 结合以构建 NVLink Switch System networks。最多支持连接 256 个 H100 GPU(全新的NVIDIA SuperPOD 因此而生),实现 57.6 TB/s 的多对多总带宽。而且新的 NVLink Switch System 在针对一些大型计算工作负载任务,比如需要在多个GPU加速节点上进行模型并行化时,能够通过互联调整负载,可以再次提高性能。
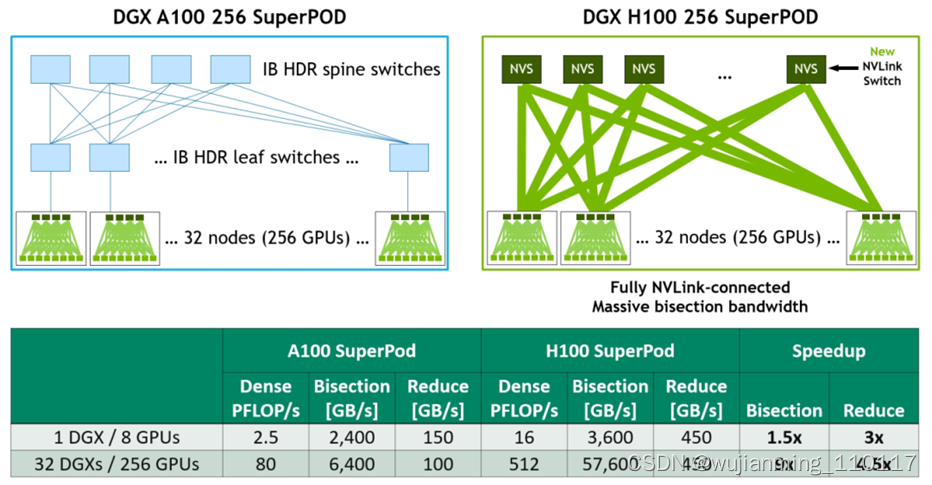
图18 DGX A100 vs DGX H100 32-node, 256 GPU NVIDIA SuperPOD Comparison
下面再介绍几款以 H100 为"基本单位" 构建的大型 AI 计算产品。
NVIDIA DGX H100
NVIDIA DGX H100 是世界上第一个专用 AI 基础架构的第四代产品 ,也是一个专用于训练,推理和分析的通用高性能 AI 系统,集成了 8 个 NVIDIA H100 GPU, 拥有总计 6400 亿个晶体管,总 GPU 显存高达 640GB ,可满足自然语言处理、深度学习推荐系统和医疗健康研究等大型工作负载的需求。

图19 DGX H100
NVIDIA DGX H100 SuperPOD
专为企业级 AI 设计的全新 DGX SuperPOD !预计 2022 年底即将推出!
DGX SuperPOD 由 32 个 DGX H100 组成,被称为“可扩展单元”,共集成了 256 个 H100 GPU,通过基于第三代 NVSwitch 技术的新的第二级 NVLink 交换机连接,提供前所未有的 FP8 稀疏 AI 计算性能的 exaFLOP 。非常适合扩展基础架构,支持更大规模、更复杂的 AI 工作负载,例如使用 NVIDIA NeMo 的大型语言模型和深度学习推荐系统。

图20 NVIDIA DGX H100 SuperPOD
NVIDIA Eos 全球最快 AI 超算
NVIDIA Eos 是目前世界上最快的人工智能超算(AI Supercomputer),共有 576 个 DGX H100 系统,4,608 个 H100 GPU。NVIDIA Eos 预计将提供 18 exaflops 的 AI 计算性能,比目前世界上最快的系统日本的 Fugaku 超算快 4 倍的 AI 处理速度。

图21 NVIDIA Eos
总结和展望
基于全新 Hopper 架构的 H100 GPU 算力再创新高!最新换代的 TensorCore,最新推出的 FP8、Transformer Engine 等等创新都将助力 H100 在 AI 上的性能提升。
而且 H100 GPU 上面还有一些专项的增强,比如专门针对 Video 解码的 NVDEC(支持 H264 / HEVC / VP9 等格式)和专门针对 JPEG 解码的 NVJPG (JPEG) Decode。NVDEC 和 NVJPG 可以大大提高计算机视觉数据在训练和推理过程中的处理性能(高速吞吐量)。H100 相较于上一代 A100 ,NVDEC 和 NVJPG 的解码吞吐能力提高了2倍以上。
Amusi 相信 H100 GPU 可以进一步推进 AI、元宇宙、自动驾驶等领域的发展!
GPU进入新三国鼎立时代
近些年,GPU在业界的重要性愈加凸出,无论是在高性能计算,还是在消费级领域,其对用户的粘性越来越强,英伟达的火爆就是得益于其核心的GPU技术和产品,在这种情况下,传统巨头英特尔坐不住了,原本只是在消费级市场生产集成GPU显卡,市场需求的变化使得英特尔开始组建独立GPU研发团队,并投入了越来越多的资源,以应对英伟达和AMD的竞争,特别是在高性能计算领域。
在高性能应用领域,对GPU的功耗和成本可控的要求越来越高,这就对相关技术提出了更高的要求,包括芯片设计方法、EDA工具、制程工艺,以及封装技术,要想实现高性能与功耗、成本的有效平衡,以上这些技术环节缺一不可,而随着摩尔定律的逐步“失效”,先进封装技术的重要性越来越凸出,而英特尔、AMD和英伟达这三巨头都看到了这一环节的重要性,并不断加强研发力度。特别是在近期,这三家公司不约而同地在MCM(多芯片模块)方面披露了重要信息。
MCM打入GPU
MCM是为解决单一芯片集成度低和功能不够完善的问题而生的,它把多个高集成度、高性能、高可靠性的die,在高密度多层互联基板上用SMD技术组成多种多样的电子模块系统,形成多芯片模块。MCM具有以下特点:封装延迟时间缩小,易于实现模块高速化;缩小整机/模块的封装尺寸和重量;系统可靠性大大提高。
以前,MCM主要用于CPU和存储设备,特别是在CPU领域应用较为普遍,如早期IBM的Power4 双核处理器,就是4块双核Power4 以及附加的 L3 高速缓存形成的MCM,还有英特尔的Pentium D(研发代号:Presler)、Xeon,以及AMD的Zen 2架构Ryzen (核心代号:Matisse)、EPYC处理器等,都是应用MCM的典型代表。
近些年,在AMD的引领下,MCM封装技术开始走向GPU。之所以如此,主要是因为传统显卡是带有多个GPU的PCB板卡,需要连接两个独立显卡的Crossfire或SLI桥接器。传统的SLI 和 CrossFire需要 PCIe 总线来交换数据、纹理、同步等。由于GPU之间的渲染时间会产生同步问题,因此在许多情况下,传统的双GPU显卡,即单个PCB上的两个芯片由它互连,每个芯片都有自己的VRAM。SLI或CrossFire的能耗很大,冷却也是一个挑战,这些在很长一段时间内都困扰着工程师。
MCM GPU则是一个单独的封装,其板载桥接器取代了传统两个独立显卡之间的Crossfire或SLI桥接器。
在高性能计算应用领域,这种MCM GPU的优势很明显,也值得花费更多时间和精力在解决封装和互连方面的软件问题,以应对更高的MCM设计复杂度。目前来看,MCM GPU主要用于数据中心和云计算应用领域。随着技术的不断成熟,以及PC应用性能的提升,其在消费电子领域的应用也将会出现。
三巨头发力
最早将MCM封装技术引入GPU的是AMD。2020年,该公司把游戏卡与专业卡的GPU架构分家了,游戏卡的架构是RDNA,而专业卡的架构叫做CDNA,首款产品是Instinct MI100系列。2021年,AMD的Q2财报确认CDNA 2 GPU已经向客户发货了,其GPU核心代号是Aldebaran,它成为AMD第一款采用MCM封装的产品,是为数据中心准备的。在PC方面,2022年引入下一代RDNA 3架构后,基于MCM的消费级Radeon GPU也会出现。
制造多芯片计算 GPU 类似于制造多核 MCM CPU,例如Ryzen 5000或Threadripper处理器。首先,将芯片靠得更近可以提高计算效率。AMD 的 Infinity 架构确保了高性能互连,有望使两个芯片的效率接近一个的。其次,使用先进的工艺技术批量生产多个小芯片比大芯片更容易,因为小芯片通常缺陷较少,因此比大芯片的产量更好。
前些天,在2021年财报电话会议上,AMD确认,今年会有几项重要产品发布,包括基于RDNA 3架构的GPU,也就是Radeon RX 7000。目前来看,该系列最新显卡会有三款GPU,分别是Navi 31、Navi 32和Navi 33,其中,Navi 31和Navi 32将采用MCM封装。之前有传闻称,Navi 31和Navi 32的Infinity Cache将采用3D堆栈的设计,会单独添加到MCD小芯片中,与Zen 3架构上采用3D V-Cache的原理类似,性能会有较大提升。
由于Navi 31和Navi 32采用了MCM封装,AMD将会使用两种不同制程,GPU会使用台积电的5nm工艺,缓存I/O芯片则会采用台积电的6nm工艺。
英伟达也在跟进MCM封装GPU。
2017年,英伟达展示了通过四个小芯片构建的设计方案,不但提升了性能,还有助于提高产量(较小的芯片良品率会提高),而且还允许将更多的计算资源集合在一起。这种多芯片设计还有助于提高供电效率,具有更好的散热效果。
近日,英伟达研究人员发表了一篇技术文章,概述了该公司对MCM的探索,英伟达目前在MCM封装GPU上的做法称为“Composable On Package GPU”(COPA),该团队讲述了COPA GPU 的各项优势,尤其是能够适应各种类型的深度学习工作负载。
由于传统融合 GPU 解决方案正迅速变得不太实用,研究人员才想到到 COPA-GPU 的理念。融合GPU解决方案依赖于由传统芯片组成的架构,辅以高带宽内存(HBM)、张量核心/矩阵核心(Matrix Cores)、光线追踪(RT)等专用硬件的结合。
此类硬件或在某些任务下非常合适,但在面对其它情况时却效率低下。与当前将所有特定执行组件和缓存组合到一个包中的单片 GPU 设计不同,COPA-GPU 架构具有混合 / 匹配多个硬件块的能力。如此一来,它就能够更好地适应当今高性能计算只能呈现的动态工作负载、以及深度学习(DL)环境。
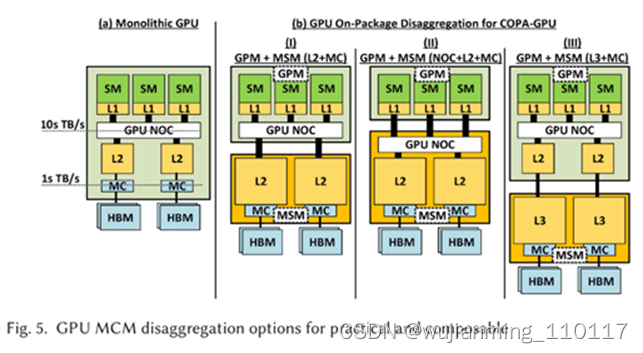
这种整合更适应多种类型工作负载的能力,可带来更高水平的 GPU 重用。更重要的是,对于数据科学家们来说,这使他们更有能力利用现有资源,来突破潜在的界限。
面向数据中心和消费市场,英伟达将分别推出基于Hopper架构和Ada Lovelace架构的GPU。据悉,该公司只会在Hopper架构GPU上采用MCM技术,Ada Lovelace架构GPU仍会保留传统的封装设计,并不会像AMD基于RDNA 3架构的Navi 31那样,将MCM多芯片封装引入到消费级GPU。
近日,有消息称,基于Hopper架构的GH100的晶体管数量将达到1400亿,这几乎是目前基于Ampere架构的GA100(542亿)或AMD基于CDNA 2架构的Instinct MI200系列(580亿)的2.5倍。据称GH100的芯片尺寸接近900mm²,比此前传言的1000mm²要小,不过比GA100(862mm²)和Instinct MI200系列(约790mm²)要大一些。传闻GH100总共配置了288个SM,可以提供三倍于A100计算卡的性能。
据悉,作为英伟达第一款基于MCM技术的GPU,Hopper架构产品将采用台积电5nm制程工艺,支持HBM2e和其他连接特性,预计会在2022年中旬亮相,竞争对手将是英特尔的Xe-HP架构GPU和AMD的CDNA 2架构产品。
不过,以上说法还未得到官方证实,英伟达将于今年3月21日召开GTC 2022大会,届时,可能会公布Hopper架构,以及相应的加速卡方案。
作为独立GPU的后来者,英特尔最近也是动作频频。
近期,英特尔公布新专利,描述多个计算模组如何协同工作执行图像渲染,代表英特尔GPU将采用MCM封装技术,大幅提高运作效能。
英特尔针对数据中心和超级计算机Ponte Vecchio的CPU已使用多芯片设计,并采用MCM封装技术。在新专利中,英特尔提出GPU图像渲染解决方案,将多芯片整合至同单元,解决制造和功耗等问题,同时优化可扩展性和互联性。
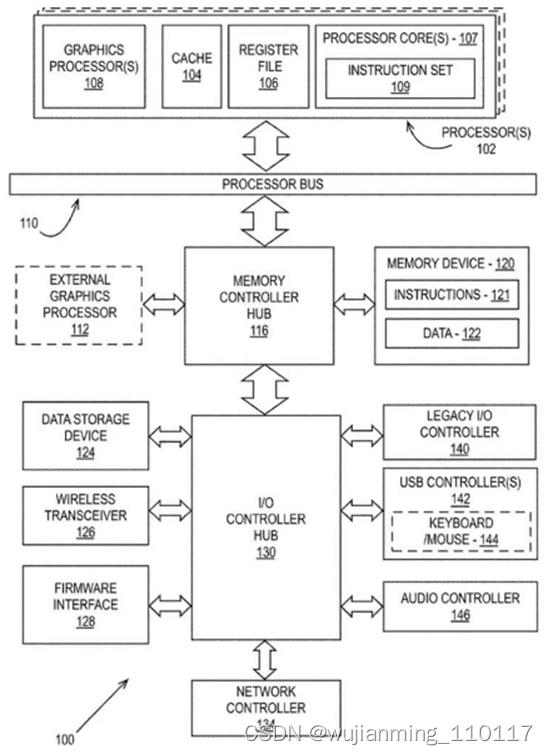
目前,这类图像渲染问题会通过交替渲染技术(Alternate Frame Rendering,AFR)或拆分帧渲染(Scissor Frame Rendering,SFR)等算法解决,但英特尔是整合运算模组的棋盘格式渲染,同时有分布式运算,使多芯片设计GPU有更高运算效率。虽然英特尔没有多描述架构层面细节,但可预期Intel Arc品牌显卡搭载MCM封装技术GPU应只是时间问题。
结语
在GPU研发方面,英特尔、AMD和英伟达显得越来越“同步”,特别是在制程工艺和封装技术方面,制程都依赖台积电,封装都看重MCM,在这两方面原本领先的AMD,其优势越来越小,特别是在MCM方面,英伟达和英特尔发展速度很快,不仅是在高性能计算领域,在消费级市场,虽说AMD首先将MCM技术应用于PC,但英伟达和英特尔也在加快进度,相信不久也会有相应的方案推出。
MCM封装GPU开始进入三国鼎立时代。
国产GPU芯片企业20家!
图形处理器(英语:graphics processing unit,缩写:GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。 其中注重算力的服务器和注重便携性的移动端分别采用独立和集成GPU,而汽车、游戏主机、PC等主要采用独立+集成的GPU接入方式。
全球GPU市场表现为寡头垄断下的高增长,年复合增速超过30%,主要市场份额被英伟达等美系企业占领。
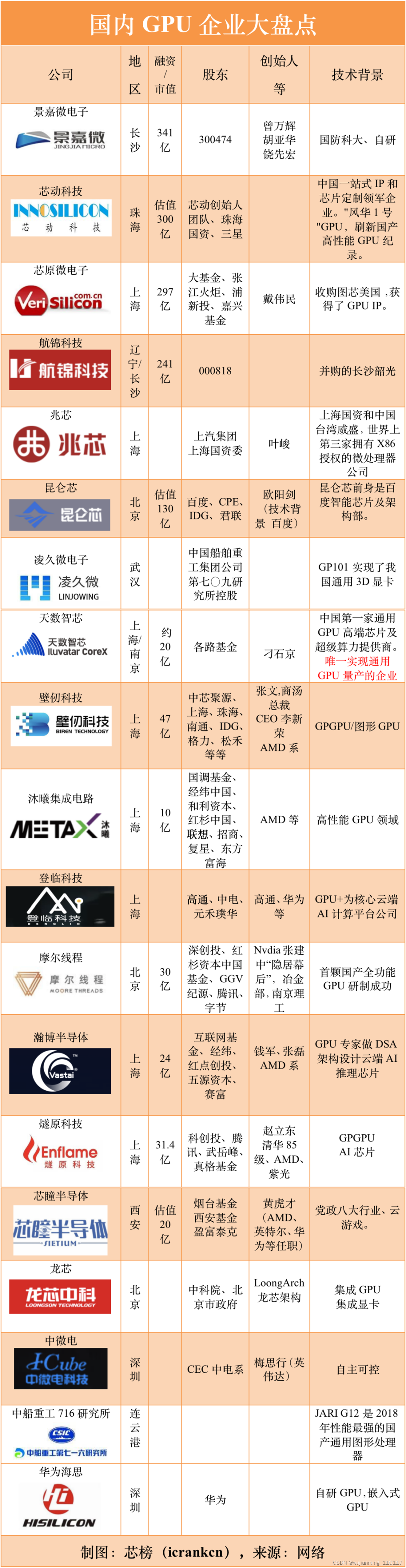
当前国产GPU产业链进口替代:设计环节,景嘉微、芯动科技、摩尔线程、沐曦科技等企业正在在不断追赶。芯榜盘点整理了国产GPU企业(约20家),供大家参考:
首款国产高端GPU芯片来了!GPU市场迎变数
GPU IP巨头Imagination中国战略市场及生态副总时昕博士在一场演讲中曾说道。
那究竟什么是GPU呢?维基百科定义,GPU中文名为图形处理器,是一种在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。

VR、区块链、3D建模、渲染等一切跟图像有关的处理过程都需要GPU。当下最热门的元宇宙,集以上图像处理需求大成,对GPU的需求也不言而喻。除了图形处理功能,GPU还是目前公认最好的AI加速器,尤其是在云端训练大模型应用场景中。更有意思的是,在自动驾驶的赛道上,GPU也杀了进来:全球GPU龙头英伟达正对接越来越多的车企合作订单。
简而言之,只要有高清画质需求,只要有AI处理需求,就离不开GPU。因此,随着这两大需求的持续增长和巨大的市场想象空间,全球GPU龙头英伟达凭借GPU芯片的优势,市值就高达7410亿美元(约合人民币47198亿元,截至2021年12月23日),晋升为当下全球市值最高的半导体企业。
GPU芯片研发有多难?
GPU需求大,价值高,反观国内芯片企业在该领域却进度缓慢。目前中国在桌面和移动端领域的GPU供应基本被英伟达、AMD、ARM垄断,国产GPU是个巨大的蓝海市场且鲜有企业涉足。
近年来,在市场和国家战略替代的需求下,国内掀起一股“GPU投资热潮”,涌现了一批国产GPU初创企业。尽管投资热度高涨,国内初创企业多以技术难度更低的通用计算型GPU(GPGPU)切入赛道,能做高性能商业化的渲染GPU产品的企业依旧凤毛麟角。
这么重要的芯片为何鲜有国产企业踏足,GPU难在哪里呢?

芯动科技展示的“风华1号”GPU在ICCAD上引发了强烈关注
在12月23日落幕的“中国集成电路设计业2021年会暨无锡集成电路产业创新发展高峰论坛(ICCAD 2021)”上,国内芯片企业芯动科技公开展示了其今年11月最新发布的首款国产高性能4K级显卡GPU芯片——“风华1号”,引发了业内人士的强烈关注,盛赞芯动科技是“中国版的英伟达”。以芯动科技为样本,综合其“风华1号”发布会上的介绍,或能解答这一问题。

从不久前举办的“风华1号”发布会上了解到,“风华1号”GPU在多个领域表现上取得了第一,如第一款渲染能力达到5T-10T FLOPS的国产GPU显卡;第一款图形API达到OpenGL4.0以上,并能实际演示4.0 benchmark的GPU;还是第一款支持多路渲染+编解码+AI服务,硬件虚拟化和chiplet可延展的国产GPU等。

芯动云计算总裁敖海先生发布“风华1号”GPU芯片
芯动科技SoC体系架构师何颖提及,单从算力对标的话,采用“风华1号”双芯片的显卡可对标英伟达T4系列产品。换而言之,“风华1号”是一颗“真正”的高端国产GPU芯片,即便是对标全球GPU龙头企业产品也不遑多让。
据芯师爷复盘“风华1号”的研发之路,发现国内企业做GPU主要有两大难,一是难在专利壁垒;二是难在GPU芯片的体系化创新。
在专利壁垒方面,GPU是先进制程数字芯片,对于GPU企业来说,高技术含量的自有IP的持续演进是技术自主和市场竞争优势的保障。但在该领域起步早的全球GPU巨头们已筑建了层层专利保护墙。以GPU架构IP专利为例,就连全球科技领头羊企业苹果,在该领域也绕不开专利授权:苹果从A4到A10X所有处理器芯片都是采用Imagination的IP,到A10之后苹果通过架构授权,有了自己的GPU架构把控,依然是基于Imagination的TBDR架构专利授权,隶属于该架构分支。但一旦架构授权后独立演进了,也就不再被专利卡脖子了。
在GPU芯片设计方面,GPU也绝非简单的芯片设计,其设计较一般芯片更复杂,系统更庞大,涉及面更广。做GPU需要极其专业的团队,团队从前到后要包圆,做到软硬全栈。专业人才要涵盖架构、算法、硬件、软件以及各种验证方式,包括后端、版图、驱动、测试、机械结构、生产、供应链等领域。这意味着,GPU研发团队需要在全链条节点上都配备丰富的量产经验人才,才能完成这样非常商业化的体系。
为何是芯动科技突围而出?
芯动科技从0-1直接突围高端GPU芯片的研发,这样的成果值得溯源与反思:为什么是芯动科技一鸣惊人,突破了国内企业做GPU芯片的困局?
芯师爷了解到,芯动科技是中国一站式IP和芯片定制及GPU领军企业,成立至今已15年。15年间芯动科技作为幕后英雄,为各国产半导体代工厂和300家全球知名客户提供顶尖IP和芯片定制,协助了包括瑞芯微、君正、微软、AMD、亚马逊等知名公司各种芯片量产,而且所有技术自研可控,能持续迭代,不断超越。逾50亿颗先进SoC芯片成功推向市场的背后,比如大家每天用的轨道交通身份证识别和全球顶级示波器,都有用到芯动科技的IP技术。广泛的合作使得芯动科技在To B的圈子非常知名,更值得一提的是,在芯片IP领域,芯动科技还是TSMC 2021全球研讨会认可的唯一大陆合作伙伴,其技术和量产积累之深厚可见一斑。
正是在为各合作伙伴提供IP和芯片定制期间,芯动科技积累了GPU所需要的全套高端IP、图形芯片内核定制技术和先进工艺经验,形成了从工艺到设计,到器件,到量产,到封装,到整机的完整芯片设计验证条流程。这为“风华1号”GPU芯片的研发奠定了稳固的基础。芯动科技SoC体系架构师何颖透露,“风华1号”集成了GDDR6/6X、PCIe 4、Chiplet Innolink、HDMI 2.1 、Display port 、VDAC、PLL、TV Sensor、PUF等高端自研IP技术,IP全自主研发,远高于友商。
其中,GDDR6/6X、Chiplet Innolink均为GPU业内顶尖技术。以GDDR6X技术为例,GDDR6X并非简单的超频技术,为了数据密度更高,它使用了32位并行单端PAM4技术,比业界常见的串口差分PAM4技术,难不止一个数量级,全球除了英伟达,一个公司都做不出来,每个时钟周期可以传输多次数据——数据吞吐量越大,芯片并行计算能力越大,GPU能够同时渲染的像素点越多,画质越清晰。使用GDDR6X技术可满足4K高刷新率画面需求;在提升接口数据传输速率的同时,它实际内核频率甚至可以做到比上一代技术更低一些。
GDDR6X显存技术研发难度极高,目前全球只有英伟达和芯动科技两家拥有。芯动科技GDDR6X研发负责人高专表示,GDDR6X的PAM4并行技术是英伟达与美光在一栋楼里共同研发两年才研发出来,芯动团队是全球唯一一家,仅凭有限的远程技术支持,只用一年时间就做出来了,连AMD目前都还没有做到成功研发该技术。这都是基于芯动科技团队十多年的技术基础积累和200次流片打磨的经验。
此外,为了保持技术的领先,芯动科技还立足全球和GPU全产业链,持续引入了大量GPU领域顶尖专业人才。
芯动首席算法科学家杨喜乐博士是顶级的架构师,她自从博士毕业之后,曾在英国Imagination公司担任架构师,过去的25年间一直从事GPU核心图形引擎的建模和创新,是全球GPU芯片领域从几何物理渲染到计算引擎领域的知名专家,持有GPU 3D计算机图形学核心领域顶级图形专利共计125项,目前Imagination、苹果等公司最新的核心GPU产品的设计、优化和迭代都离不开她的专利和算法。在芯动科技的邀请下,回国投身国产GPU图形引擎的持续创新。

芯动首席算法科学家杨喜乐博士
在芯动科技GPU专家团队的努力下,“风华1号”GPU架构目前已在Imagination GPU的架构授权下,自主研发了两代,把原生移动端的架构拓展到了高性能计算、云计算的场景,在架构自主可控上不存在被“卡脖子”风险。
芯动科技DX团队负责人章涛也是其从海外招揽的技术大咖。据悉,章涛是来自前AMD的图形框架开发的领军人物。表示,“投身芯动开发GPU软件感觉非常棒!芯动团队从老板到员工,都在专心做事。”章涛透露,明年芯动科技就会发布风华显卡Windows操作系统的DX框架。
芯动云计算总裁敖海在“风华1号”发布会上曾这样总结:“‘风华1号’凝聚了芯动科技自有的众多技术积累,又有世界著名GPU公司顶尖人才的联合参与的加持,是芯动人努力和成果的结晶,也是芯动科技完成‘让风华GPU走进千家万户,让大家习惯用国产的GPU办公和娱乐’使命的开端。风华系列GPU赋能国产生态正加紧奋勇向前,目前芯动科技正在加紧与合作伙伴进行‘风华1号’适配调优,在向数据中心和国产桌面GPU 等合作伙伴送样的同时,风华2号和3号已经在路上了。”
写在最后
在半导体供应链面临不确定风险的产业环境下,芯动科技瞄准高速成长的高清画质云渲染和元宇宙需求,推出的“风华1号”正当其时,填补了国产4K级桌面显卡和服务器显卡两大空白,为国产新基建5G数据中心、桌面、元宇宙、云游戏、云桌面等千亿级产业提供了有力支持,值得国产半导体产业为其喝彩。
同时,也该注意到,罗马不是一天建成的,发展中的中国GPU产业和国际巨头之间仍有不小的差距。芯动科技选择的是既充满机遇、又充满挑战的GPU市场,未来国产GPU生态的长期发展也需要国产GPU产业链企业的持续支持。
巨大的研发费用和长期资本开支,在已经多年持续盈利的芯动科技看来,并非很大挑战。芯动科技工程副总毛鸣明认为,硬科技要“十年坐得板凳冷”,需要长期打磨,不是像互联网靠砸钱就能成功的,投资人需要非常清楚这一点。长远来看,国产GPU芯片技术突围最终还是需要靠经年累月的迭代和优化, 通过不断试错,走进应用于千家万户的终端产品供应链中取胜。
芯动科技SoC体系架构师何颖也表示:“芯动科技是全球6大晶圆代工厂签约支持的技术合作伙伴,有着众多自研IP和强大稳定的团队执行力,在多年的持续奋斗中,芯动科技在跨工艺研发和供应链能力上极具优势,令合作客户长期受惠。而国产GPU上下游产业链的长期、持续商用也会成为芯动科技GPU芯片发展的强大驱动力。未来,芯动科技将根据产业链客户需求,为风华系列GPU产品找到更多可持续落地场景,完成让风华GPU走进大家生活的使命。”
本文参考文献链接
https://mp.weixin.qq.com/s/ANOEtc6-0vNuJfhtO9S6Og
https://mp.weixin.qq.com/s/tLl4v_d09CMKXzpukST_oA
https://mp.weixin.qq.com/s/lmdeB70oIT_reZGN4zJUng
https://mp.weixin.qq.com/s/8_Cw6lhFC4nvQTfL_Jd81A
https://baike.baidu.com/item/%E5%9B%BE%E5%BD%A2%E5%A4%84%E7%90%86%E5%99%A8/8694767?fromtitle=gpu&fromid=105524&fr=aladdin