ubuntu下安装: https://www.eet-china.com/mp/a130167.html
一、下载与安装
2022版本的安装包跟之前的不一样地方包括:
- OpenCV部分不在默认安装包中
- Dev Tools 跟 Runtime安装方式不同
- Dev Tools包模型转换器跟其它开发组件
- Runtime主要负责模型推理,支持Python跟C++
在intel官方下载页面选择如下:

下载之后点击【Continue】-> 【Install】安装即可
二、配置OpenVINO2022开发环境
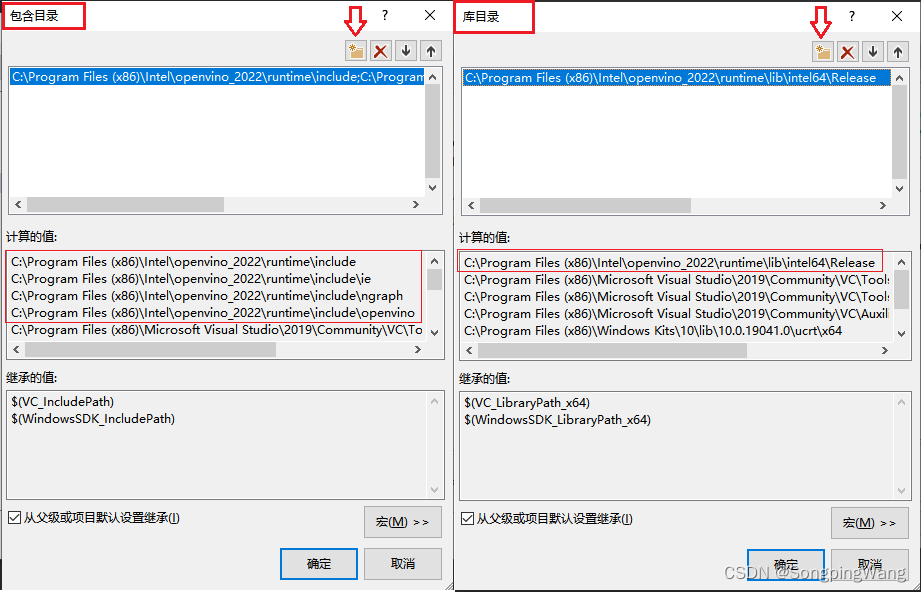
主要是针对C++部分,使用VS2017配置。这部分跟以前没有太大差异,同样需要配置包含目录,库目录与附加依赖项添加,跟环境变量,这几个部分的配置分别如下:
若你同我一样默认安装路径直接复制即可(无需任何改动,复制进去直接回车即可)
包含目录
C:\Program Files (x86)\Intel\openvino_2022\runtime\include;C:\Program Files (x86)\Intel\openvino_2022\runtime\include\ie;C:\Program Files (x86)\Intel\openvino_2022\runtime\include\ngraph;C:\Program Files (x86)\Intel\openvino_2022\runtime\include\openvino
库目录
C:\Program Files (x86)\Intel\openvino_2022\runtime\lib\intel64\Release
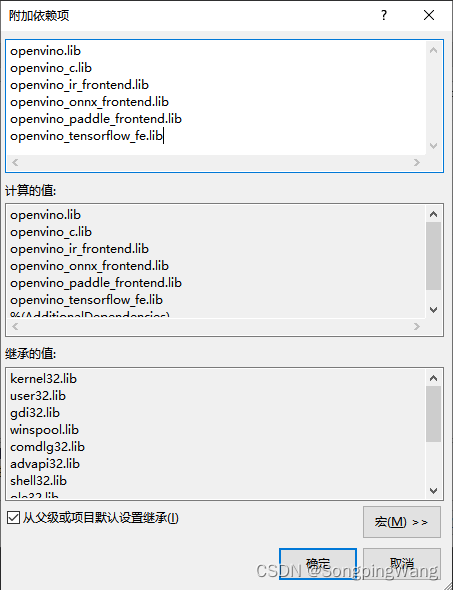
输入依赖项
openvino.lib
openvino_c.lib
openvino_ir_frontend.lib
openvino_onnx_frontend.lib
openvino_paddle_frontend.lib
openvino_tensorflow_fe.lib
最后配置好环境变量
变量名:INTEL_OPENVINO_DIR
变量值:C:\Program Files (x86)\Intel\openvino_2022\runtime\bin\intel64\Release;C:\Program Files (x86)\Intel\openvino_2022\runtime\3rdparty\tbb\bin

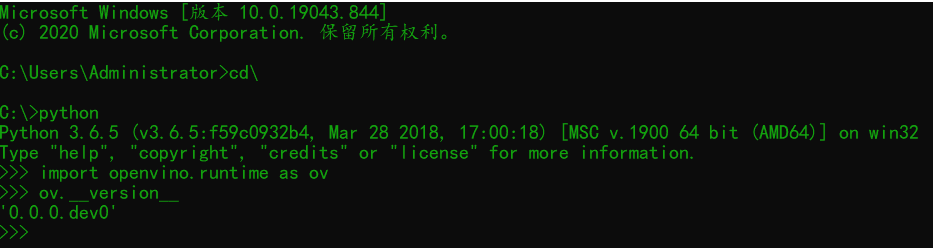
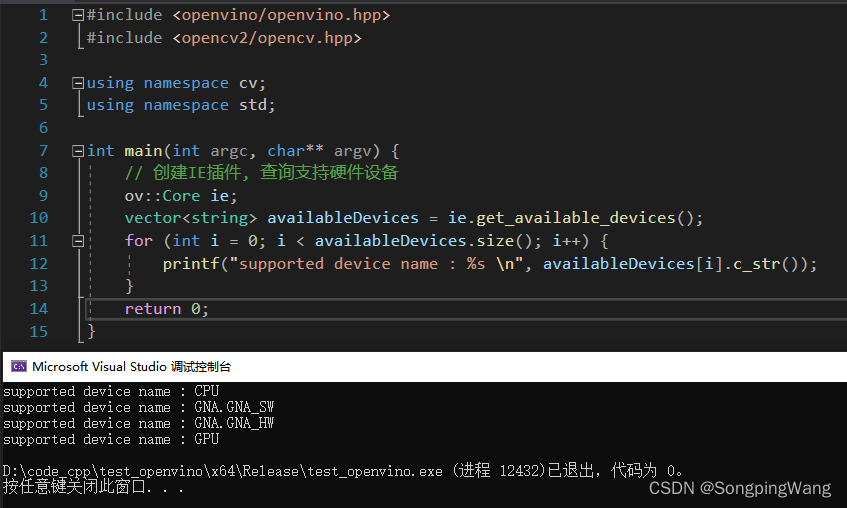
然后重启VS2019,执行如下代码测试:
#include <openvino/openvino.hpp>
#include <opencv2/opencv.hpp>
using namespace cv;
using namespace std;
int main(int argc, char** argv) {
// 创建IE插件, 查询支持硬件设备
ov::Core ie;
vector<string> availableDevices = ie.get_available_devices();
for (int i = 0; i < availableDevices.size(); i++) {
printf("supported device name : %s \n", availableDevices[i].c_str());
}
return 0;
}
运行结果如下:
最新SDK使用解析
OpenVINO2022版本推理开发跟之前版本最大的不同在于全新的SDK设计,新的SDK设计显然对齐了ONNXRUNTIME,libtorch等这些部署框架简约SDK设计中的优点,从模型的读取,到数据预处理,到模型推理、预测结果解析,在数据流通跟推理流程方面都比之前的SDK简单易学,非常方便开发者使用。
01模型加载
ov::CompiledModel compiled_model = ie.compile_model(onnx_path, "AUTO");
ov::InferRequest infer_request = compiled_model.create_infer_request();
两行代码就搞定了,之前的SDK比较啰嗦,很不符合设计的KISS规则,现在直接两行代码就可以得到推理请求了。另外支持”AUTO”自动模式硬件支持,让开发这不用在选择硬件平台
02获取输入
ov::Tensor input_tensor = infer_request.get_input_tensor();
ov::Shape tensor_shape = input_tensor.get_shape();
也是两行代码搞定,另外再也不用手动设置各种数据格式了,这样可以避免开发者犯一些数据类型设置错误,提高了开发接口的易用性,这点必须点赞!
03把图像填充输入tensor数据
size_t num_channels = tensor_shape[1];
size_t h = tensor_shape[2];
size_t w = tensor_shape[3];
Mat blob_image;
resize(src, blob_image, Size(w, h));
blob_image.convertTo(blob_image, CV_32F);
blob_image = blob_image / 255.0;
// NCHW
float* image_data = input_tensor.data();
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
image_data[row * w + col] = blob_image.at(row, col);
}
}
跟之前类似,这步一直很简单,这样就OK了。
4推理跟后处理
// 执行预测
infer_request.infer();
// 获取输出数据
auto output_tensor = infer_request.get_output_tensor();
const float* detection = (float*)output_tensor.data();
01输入与输出获取
ov::InferRequest支持直接获取输入跟输出tensor,分别对应方法是
get_input_tensor()
get_output_tensor()
这两个方法只有在模型只有一个输入跟输出的时候才会正确工作。当模型有多个输入跟输出的时候请使用
get_tensor(name)
方法, 它支持名称作为参数获取多个输入跟输出tensor。
04Python版本支持
只需要再做一步即可,打开环境变量,新建PYTHONPATH,如下图:
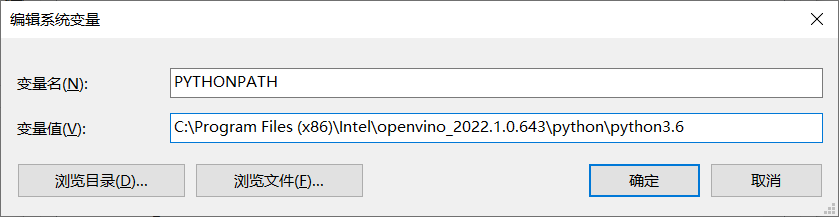
记得输入的路径最后版本号一定要跟系统安装的python版本号保持一致。测试: