参考PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】P16~24
nn.Module
神经网络的基本骨架,所有神经网络模块的基类。
官方文档
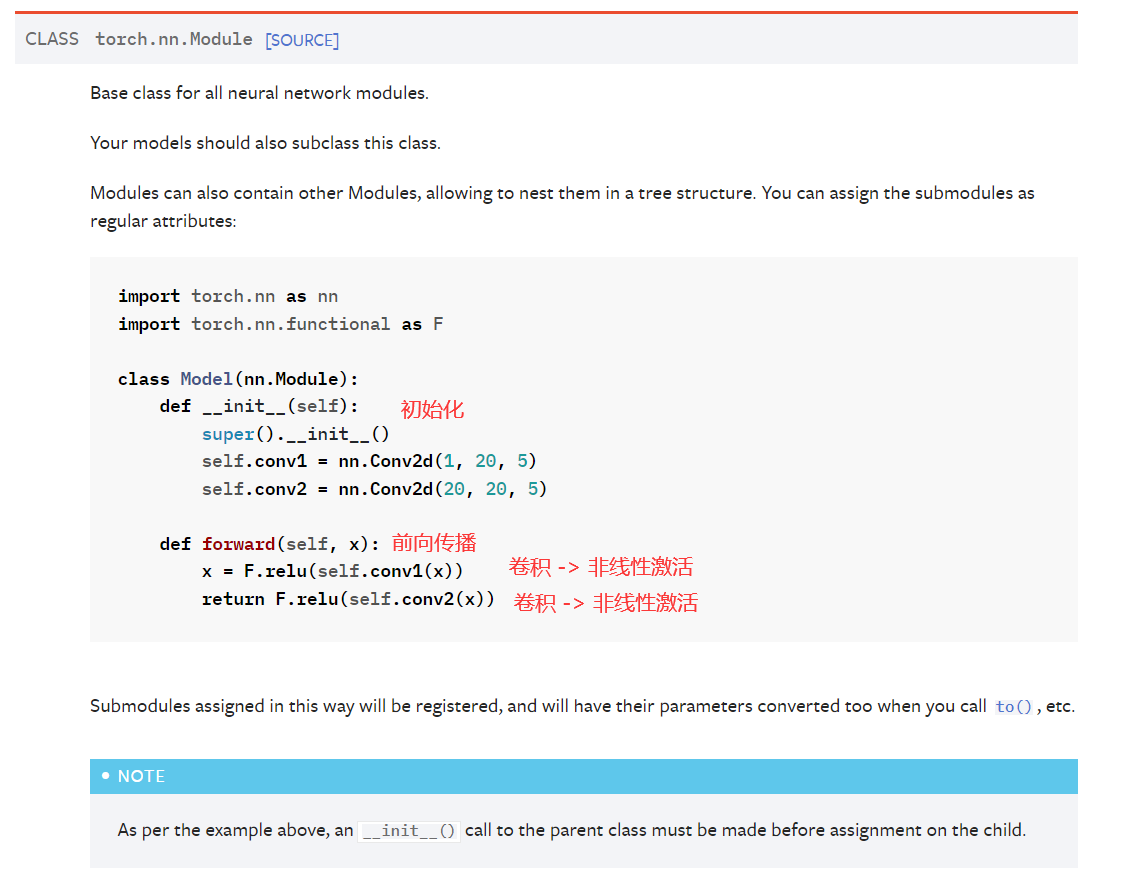
例子
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self): # 这里是有操作的,code -> generate -> override methods -> --init__(self.Module) 可以快速重写这部分内容补全
super().__init__()
def forward(self, input):
output = input + 1
return output
tudui = Tudui() # 用 Tudui 为模板,创建的神经网络实例
x = torch.tensor(1.0) # 这一步,处理x,使其成为 tensor 形式,这里不仅可以输入数字,还可以是图像或者其他内容
output = tudui(x) # 这一步是把 x 放进神经网络当中,命名为 output
print(output)
# tensor(2.)
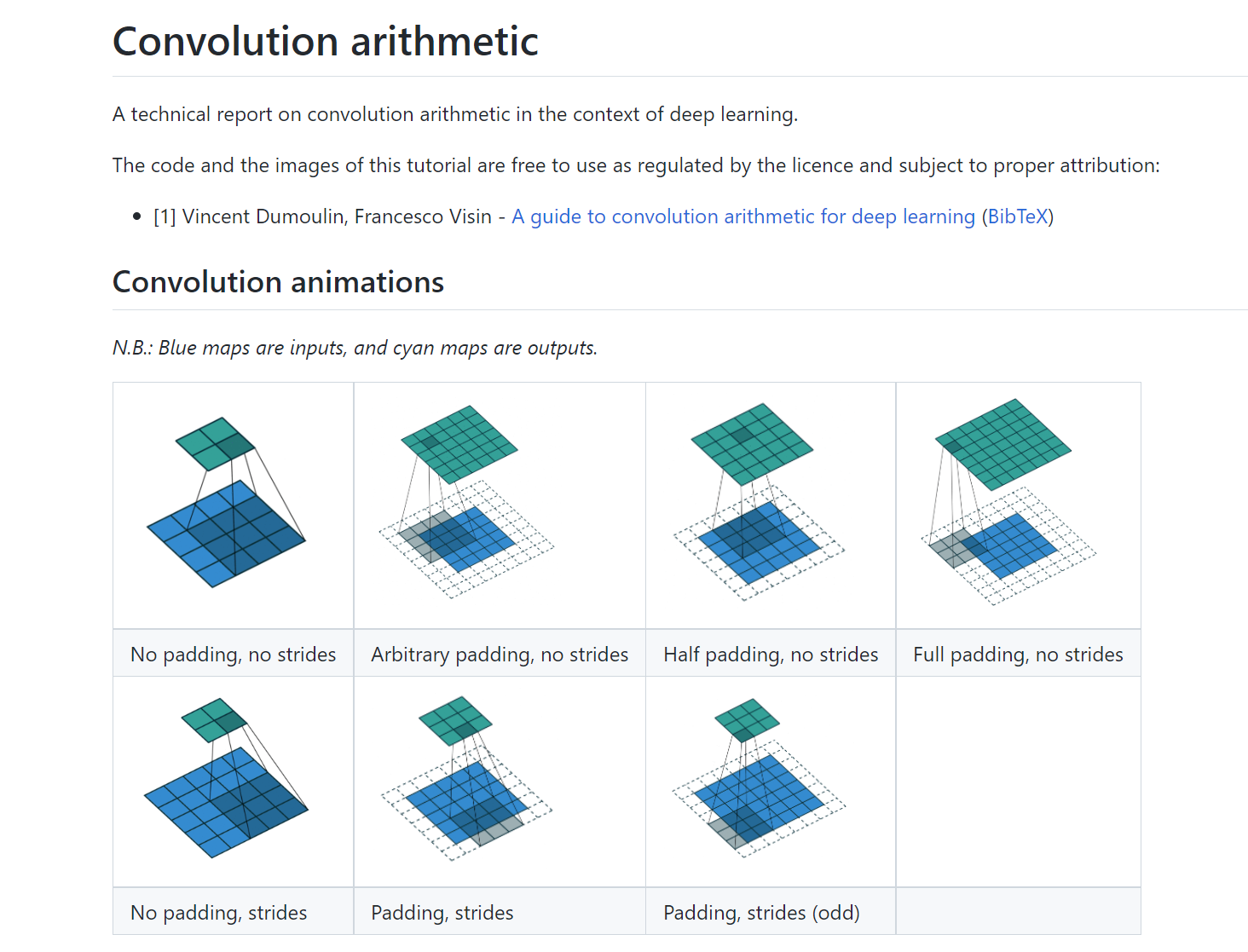
卷积
torch.nn.functional可以查看具体的卷积操作
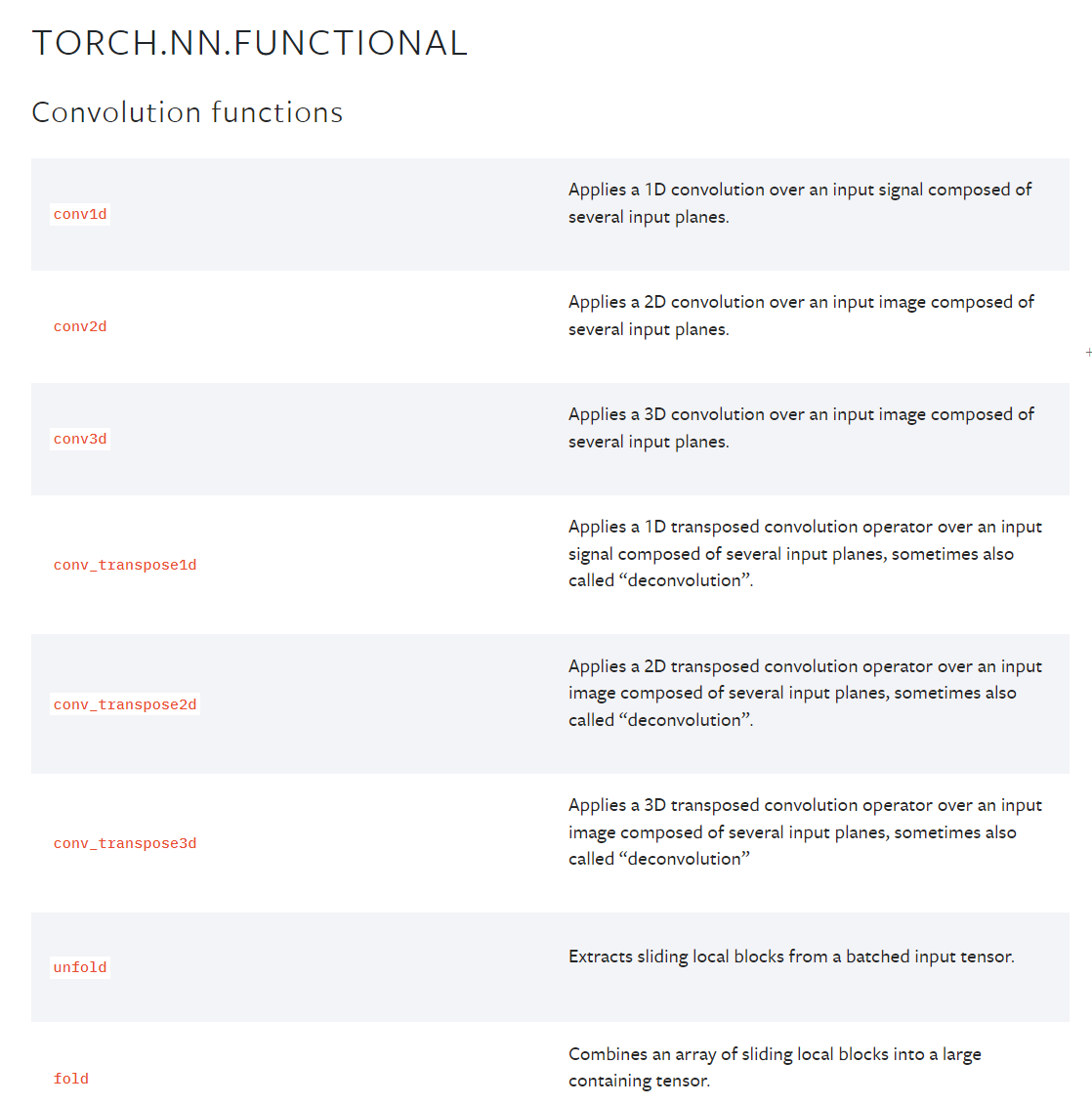
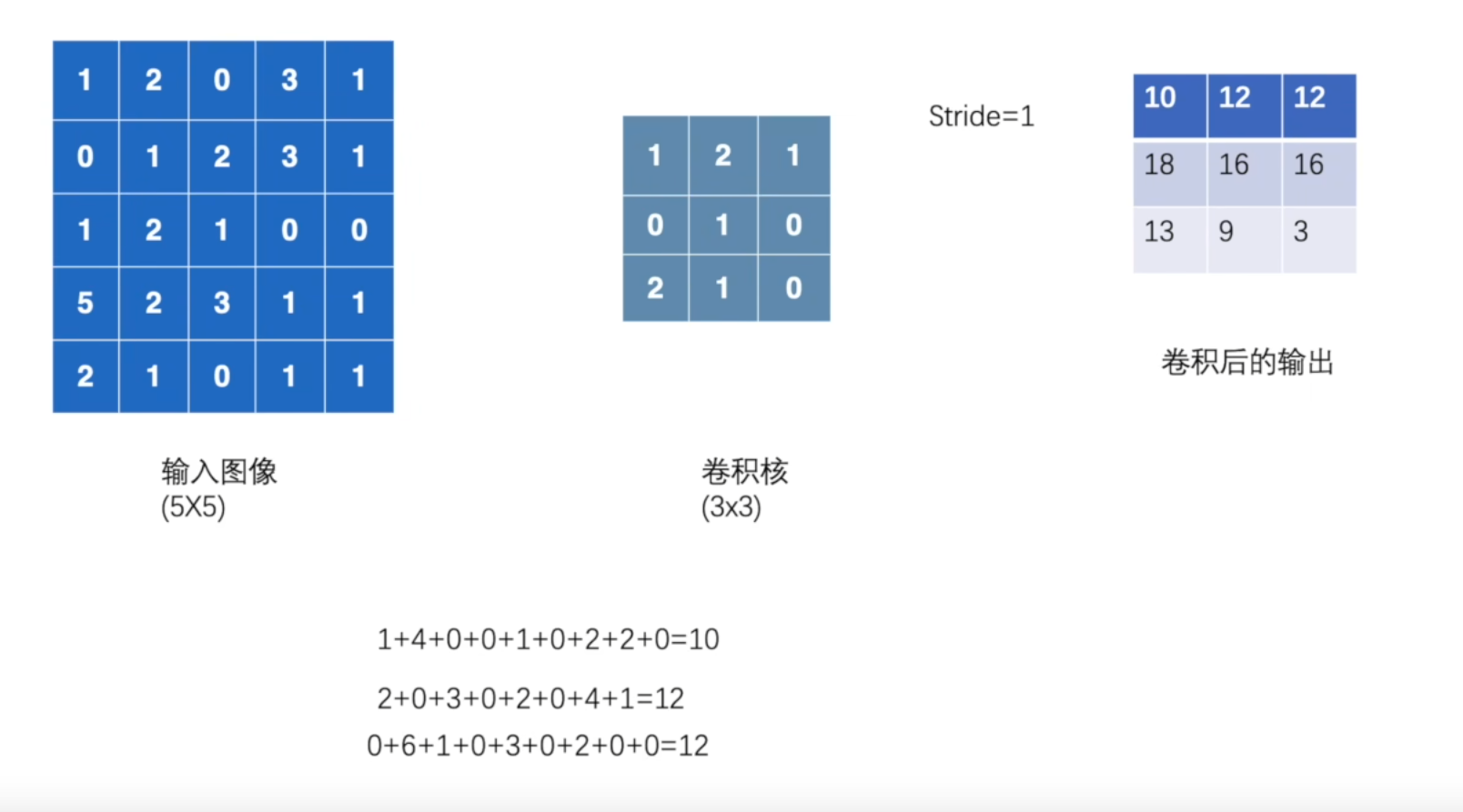
以conv2d为例

stride = 1, padding = 0
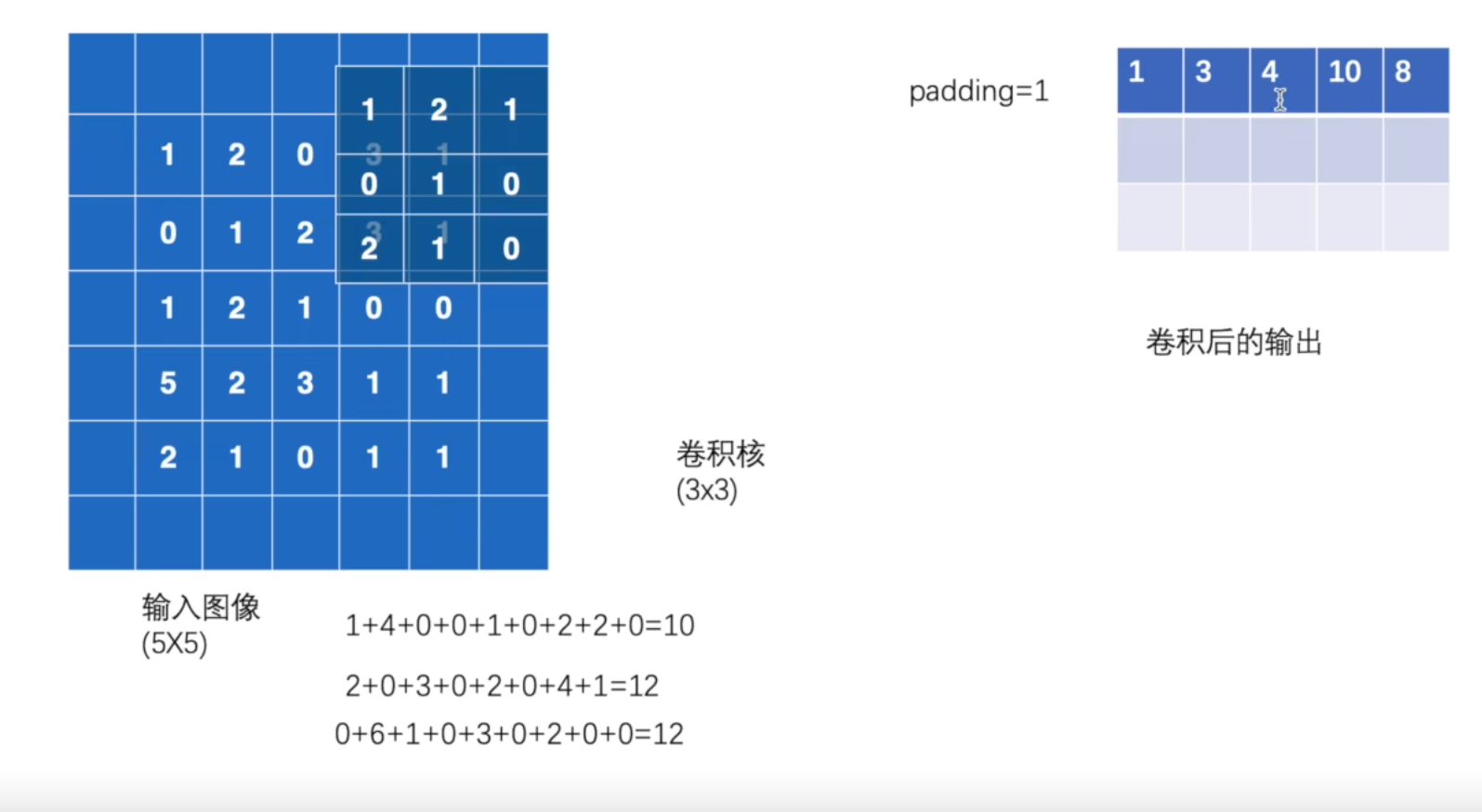
stride = 1, padding = 1
'''
torch.nn 和 torch.nn.functional 是包含关系,functional 指的是具体的函数源代码,而 torch.nn 是封装好的,可以直接使用
他们的区别,从conv的大小写(Conv和conv),也能看出来。而且,torch.nn.functional中,带着 functional,torch.nn 是不用加的
本节的内容,都是结合torch.nn.functional 实现的,具体的查看 :
https://pytorch.org/docs/stable/generated/torch.nn.functional.conv2d.html#torch.nn.functional.conv2d
具体的函数,以及参数,都有讲到
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1) → Tensor
'''
import torch
import torch.nn.functional as F # 制作一个函数的句柄,后面方便直接使用了
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
print("input:", input)
'''
input: tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
'''
print("kernel:", kernel)
'''
kernel: tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
'''
print("input.shape:", input.shape)
# input.shape: torch.Size([5, 5])
print("kernel.shape:", kernel.shape)
# kernel.shape: torch.Size([3, 3])
# 要想用 torch.nn.functional.conv2d 这个函数,就必须满足形状的要求,上述的尺寸不满足,要做处理
# 上述的尺寸,只有input.shape: torch.Size([5, 5]), kernel.shape: torch.Size([3, 3]),并没有4个通道
input = torch.reshape(input, (1, 1, 5, 5)) # 注意这4个数字的意义,分别是:batch_size, in_channel, H, W , 变换形状之后,重新赋值给 input
kernel = torch.reshape(kernel, (1, 1, 3, 3)) # 注意这4个数字的意义,跟上面的不一样了
print("input.shape:", input.shape)
# input.shape: torch.Size([1, 1, 5, 5])
print("kernel.shape:", kernel.shape)
# kernel.shape: torch.Size([1, 1, 3, 3])
output = F.conv2d(input, kernel, stride=1)
print(output)
'''
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
'''
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
'''
tensor([[[[10, 12],
[13, 3]]]])
'''
output3 = F.conv2d(input, kernel, stride=1, padding=1) # padding 设置的值,是往外扩充的行列数,值都是0,至于想要修改这个值,还有另外一个参数,一般不改
print(output3)
'''
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
'''
output4 = F.conv2d(input, kernel, stride=1, padding=0) # padding 默认值是 0
print(output4)
'''
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
'''
卷积层



stride和padding
查看不同stride和padding情况,link
kernel_size
卷积核大小,在计算过程中会自行调整,这里只是设置一个初始值
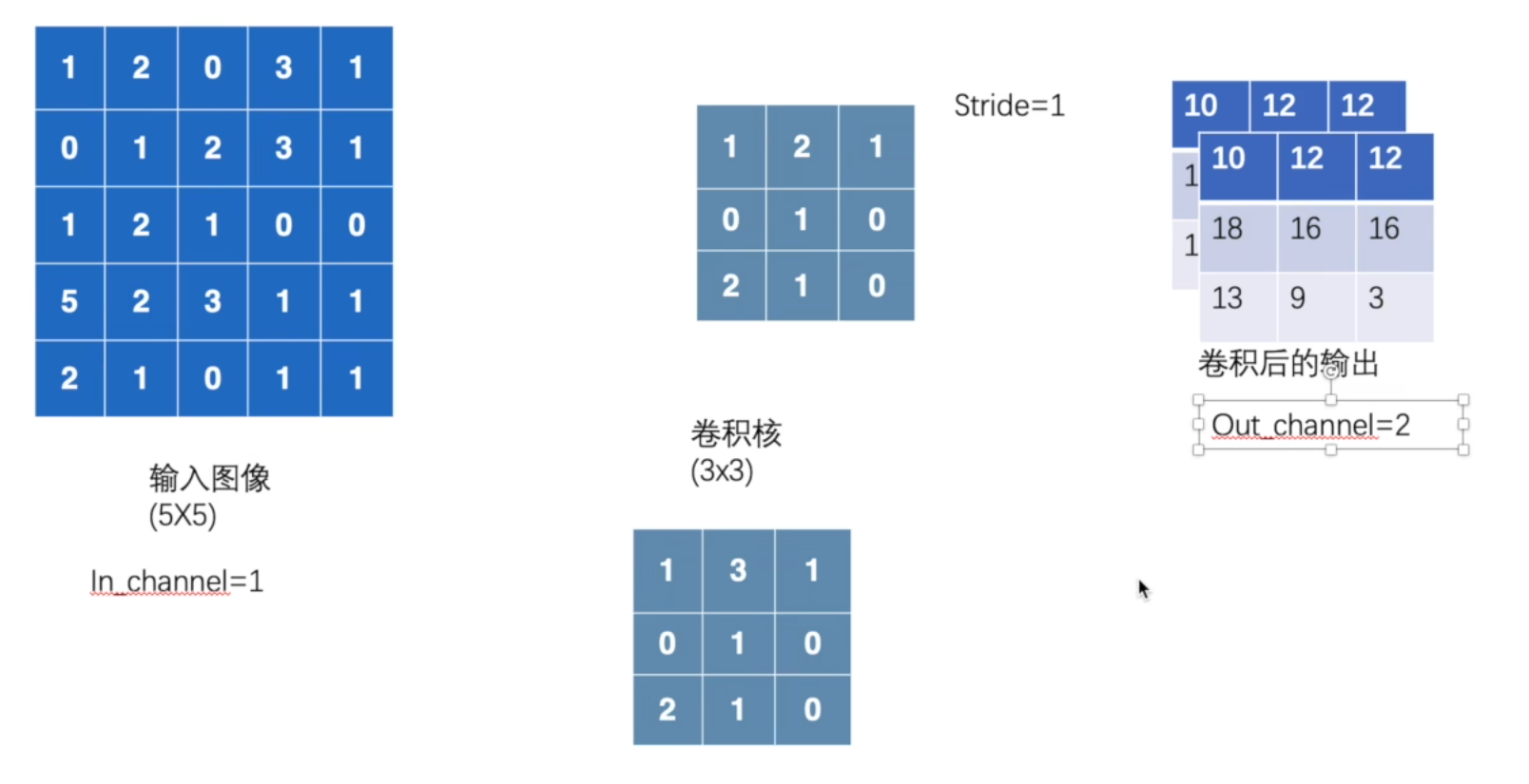
in_channels和out_channels
in_channels = 1, out_channels = 1
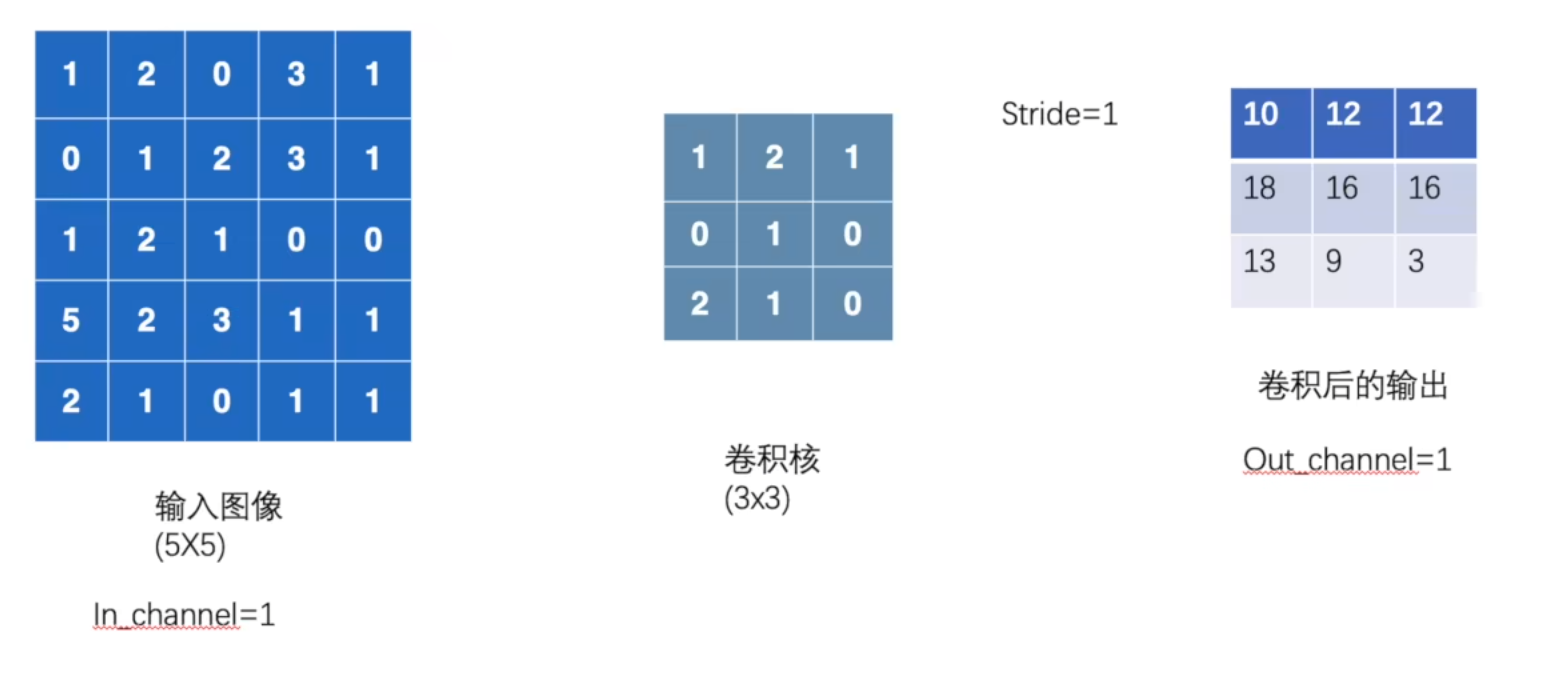
in_channels = 1, out_channels = 2
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0) # 初始化中,有了一个卷积层
def forward(self, x):
x = self.conv1(x) # x 已经放到了卷积层 conv1当中了
return x
tudui = Tudui() # 初始化网络
print(tudui)
'''
Tudui(
(conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
)
'''
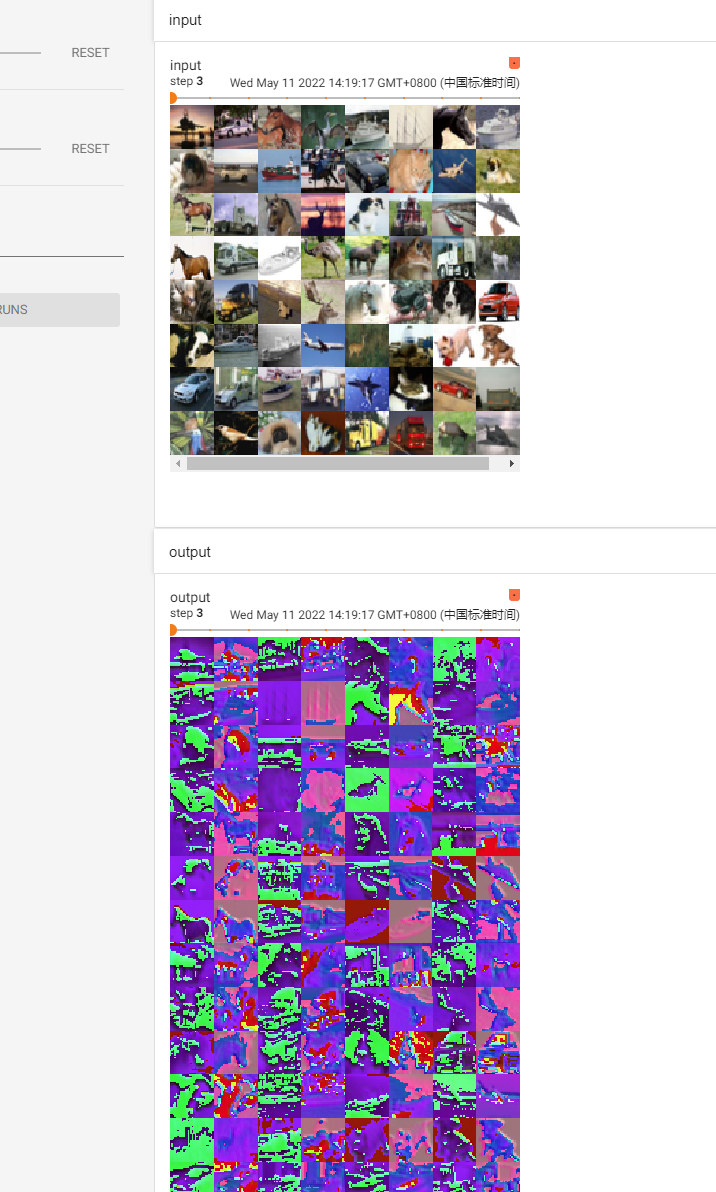
# 下面把每一张图像都进行卷积
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data # data 由 imgs 和 targets 组成的,已经获得了图片,并且经过了 ToTensor的转换,已经是tensor类型,可以直接放进网络当中
output = tudui(imgs)
print("imgs.shape:", imgs.shape)
# imgs.shape: torch.Size([64, 3, 32, 32])
print("output.shape:", output.shape) # 其中的 64,就是指的 DataLoader 中的 batch_size = 64, channel 由 3 变成了 6
# output.shape: torch.Size([64, 6, 30, 30])
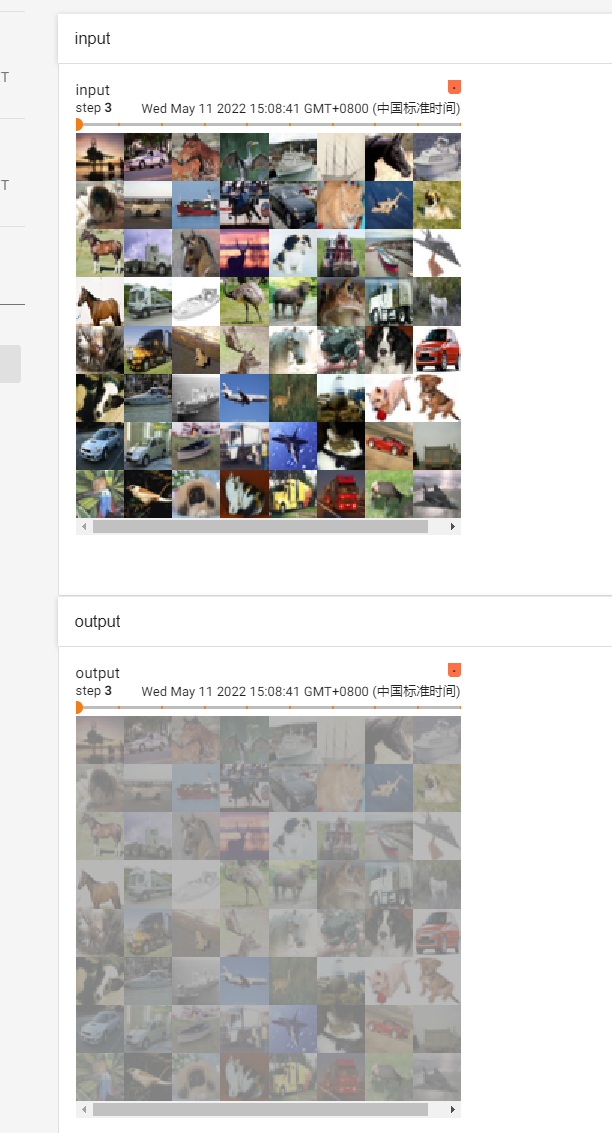
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30]) 由于 6 个 channel 的图像,是无法显示的,所以,对这个图像进行处理,这里是通过batch_size来调整channel的,理论其实是有些站不住脚的
# torch.Size([xxx, 3, 30, 30])
output = torch.reshape(output, (-1, 3, 30, 30)) # 这个方法不是很严谨,目的是将 batch_size 降低,当不知道设置为多少合适时,设置为 -1 ,后面的参数会自己计算的
writer.add_images("output", output, step)
step += 1
writer.close()
根据input的H和W,以及padding、stride、dilation、kernel_size可以计算出output的H和W

池化
最大池化的作用:
保留特征的同时,还能减小数据尺寸,加快训练
往往卷积之后,加一层池化,再归一化(归一化要在非线性激活也就是激活函数之前),后面再非线性激活,也就是:conv -> pooling -> batch normalization -> relu
官方文档
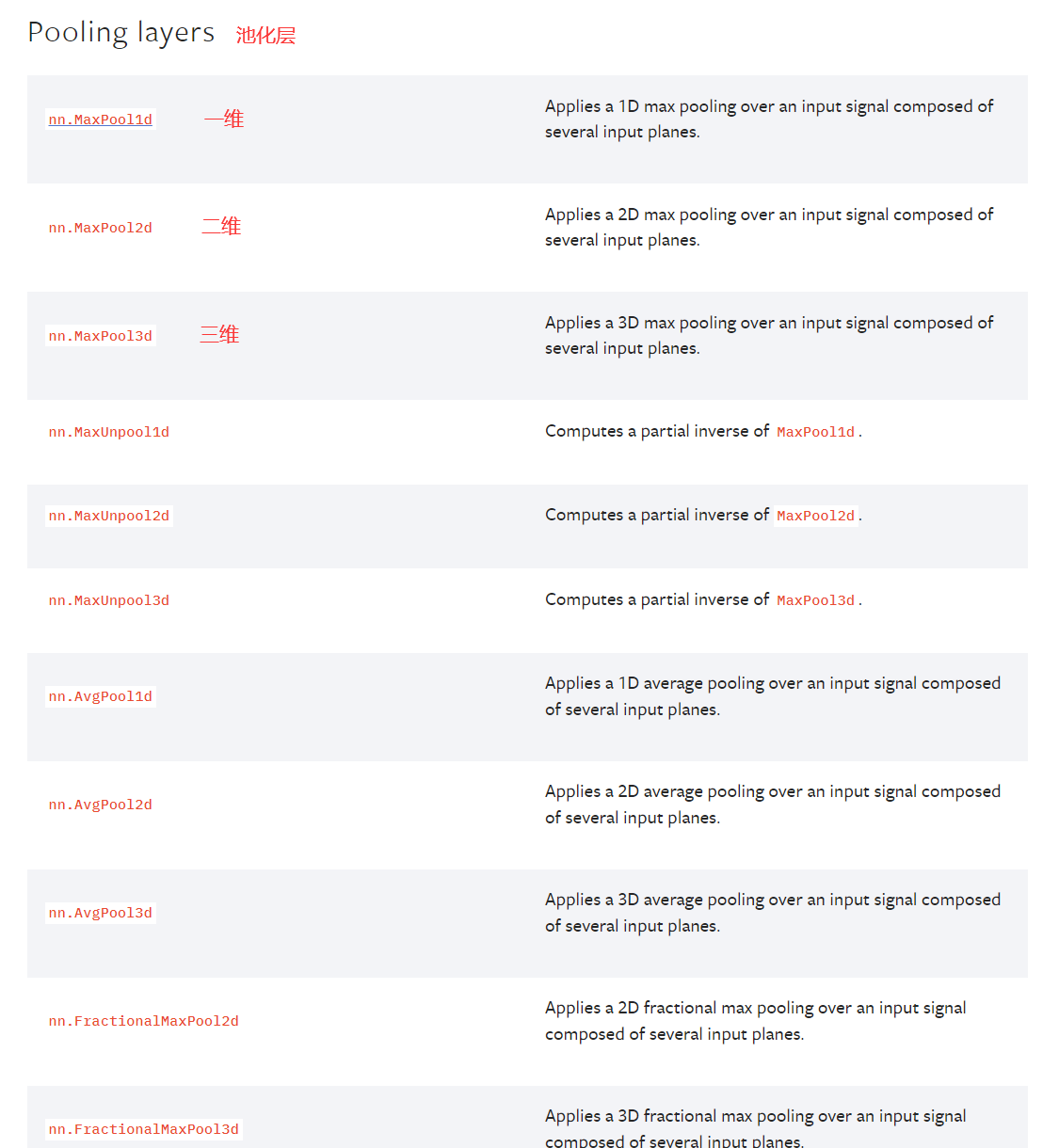
以nn.MaxPool2d为例

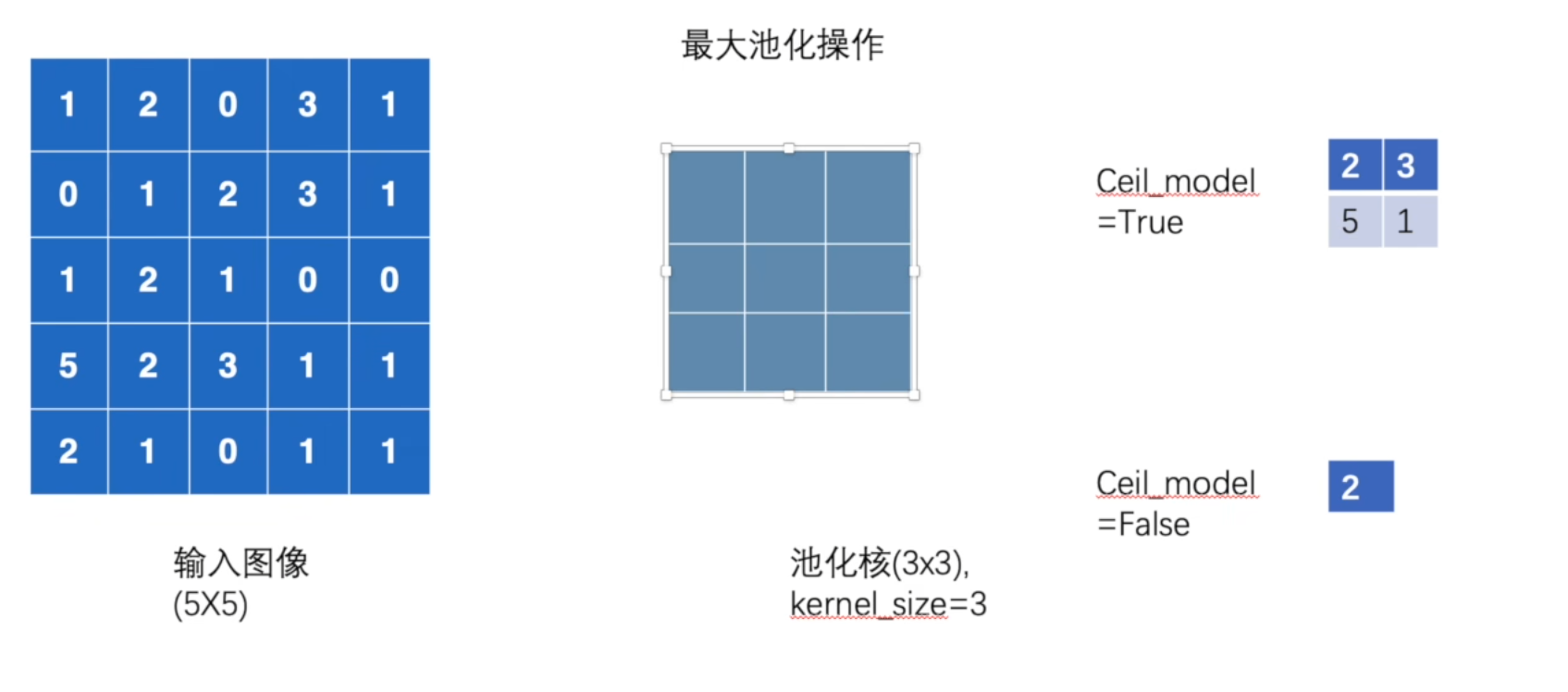
ceil_mode作用可以查看这张图,当kernel_size = 3时,ceil_mode = True保留不满 3 3 3的区域,ceil_mode = False丢弃不满 3 3 3的区域
例子
from torch import nn
from torch.nn.modules.pooling import MaxPool2d
'''
通过官方文档介绍参数,一般只需要设置 kernel size
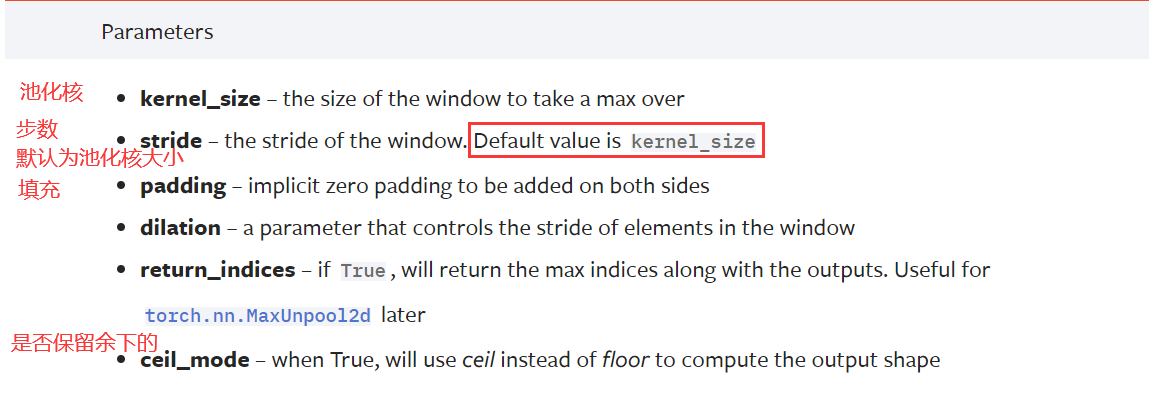
其中,ceil_mode是一个重要参数,当kernel滑动,省下的位置,不够kernel的大小,那这组数据还要不要,就是通过ceil_mode来选择的
stride滑动的默认值,是kernel的大小,跟conv不一样,注意
'''
import torch
# 这里要指定input的数据类型,否则报错,long
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
input = torch.reshape(input, (-1, 1, 5, 5)) # -1 仍然是让他自己计算batch_size,1是channel数
print("input.shape:", input.shape)
# input.shape: torch.Size([1, 1, 5, 5])
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
tudui = Tudui()
output = tudui(input)
print("output:", output)
'''
output: tensor([[[[2., 3.],
[5., 1.]]]])
'''
'''
当 ceil_mode = False 时,输出就只有:
tensor([[[[2.]]]])
'''
应用
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output = self.maxpool1(input)
return output
tudui = Tudui()
writer = SummaryWriter("logs_maxpool")
step = 0
for data in dataloader:
imgs, targets = data
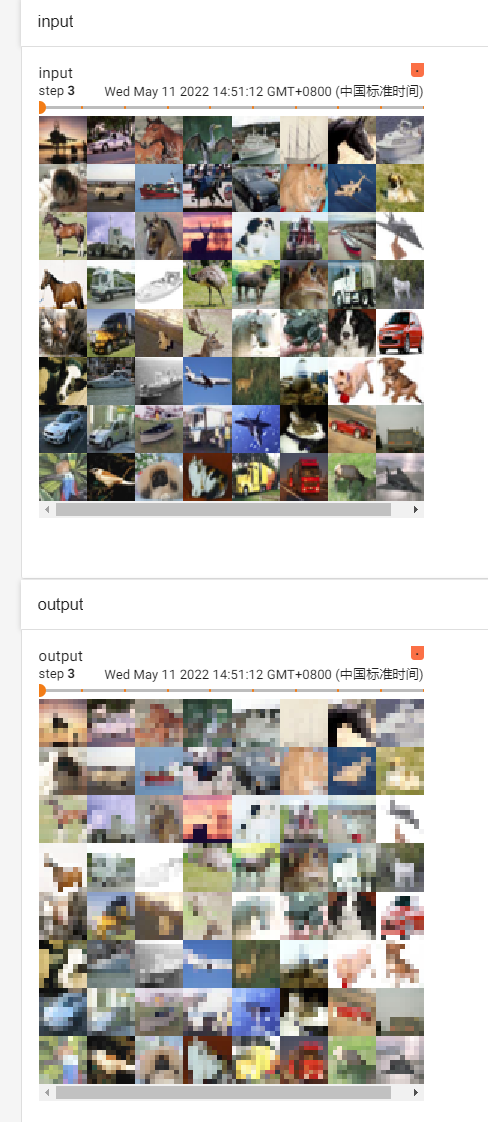
writer.add_images("input", imgs, step)
output = tudui(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
非线性激活
非线性变换的主要目的就是给网中加入一些非线性特征,非线性越多才能训练出符合各种特征的模型;否则,泛化能力不好
官方文档
RELU
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1, -0.5],
[-1, 3]])
# 非线性激活层,只有一个batch_size一个参数需要设置
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
# torch.Size([1, 1, 2, 2])
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU()
def forward(self, input):
output = self.relu1(input)
return output
tudui = Tudui()
output = tudui(input)
print(output)
'''
tensor([[[[1., 0.],
[0., 3.]]]])
'''

import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
tudui = Tudui()
writer = SummaryWriter("logs_relu")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, global_step=step)
output = tudui(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()
线性层
官方文档
线性层:这里的线性层,跟非线性激活,形成对比;线性层,是 k k k和 b b b,对输入数据 x x x进行一次函数的处理,而非线性激活(激活函数)是在对神经元或者输入,做非线性处理。
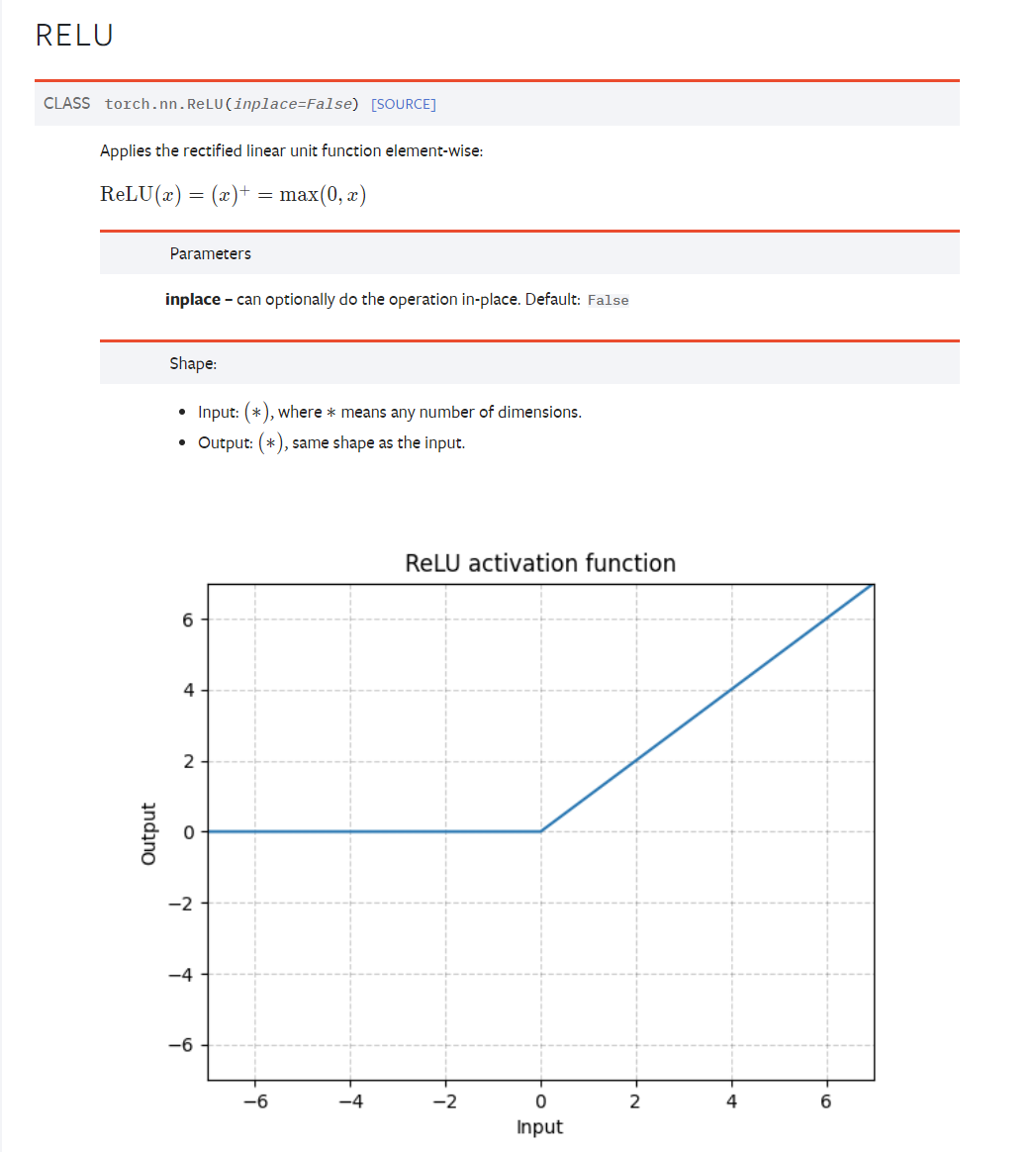
LINEAR

import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.linear1 = Linear(196608, 10) # 196608个输入变为10个输出
def forward(self, input):
output = self.linear1(input)
return output
tudui = Tudui()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
# torch.Size([64, 3, 32, 32])
# output = torch.reshape(imgs, (1, 1, 1, -1))
output = torch.flatten(imgs)
print(output.shape)
# torch.Size([196608])
output = tudui(output)
print(output.shape)
# torch.Size([10])
搭建小实战和Sequential的使用
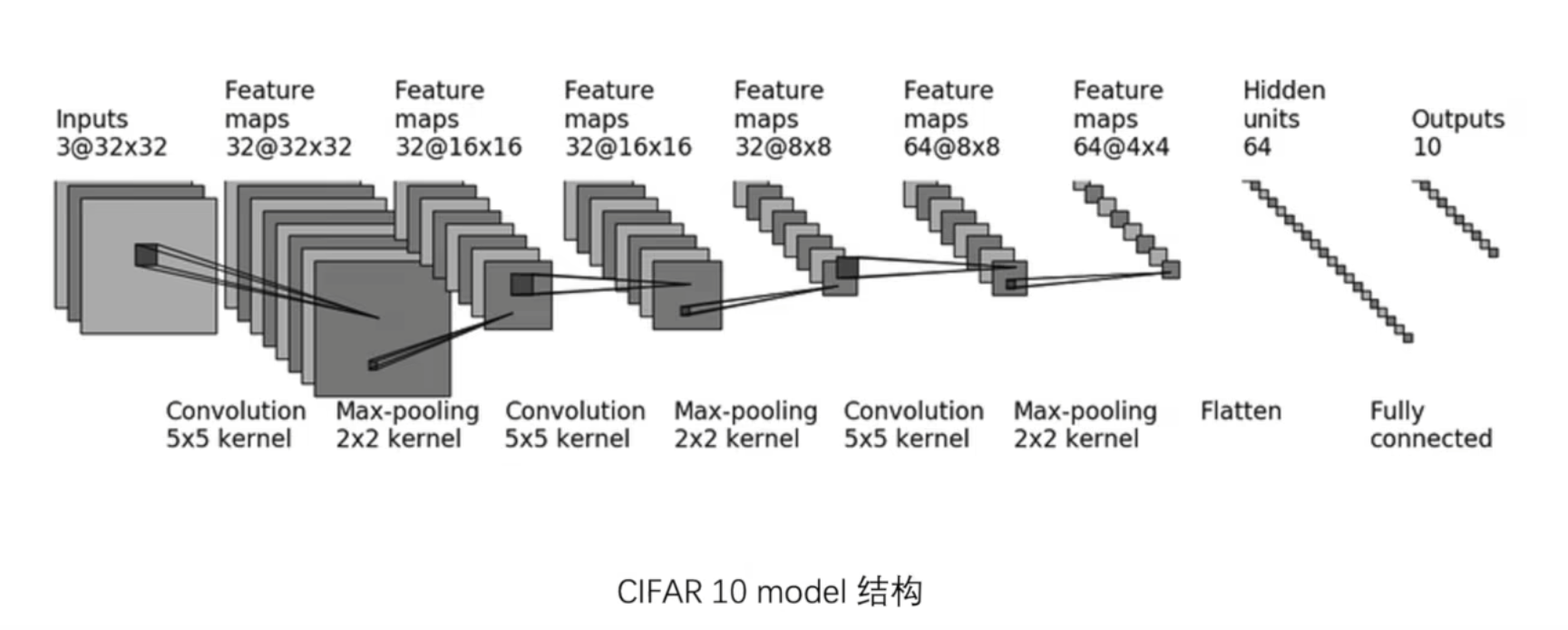
在第一个卷积过程中channel从 3 3 3变为 32 32 32,kernel为 5 5 5,默认dilation为 1 1 1
input与output的H和W都为 32 32 32
根据公式
由 H o u t ( 32 ) = ⌊ H i n ( 32 ) + 2 × p a d d i n g − d i a l a t i o n ( 1 ) × ( k e r n e l _ s i z e ( 5 ) − 1 ) − 1 s t r i d e + 1 ⌋ H_{out}(32) = \lfloor{ \frac{H_{in}(32) + 2 \times padding - dialation(1) \times (kernel\_size(5) -1) -1}{stride} +1}\rfloor Hout(32)=⌊strideHin(32)+2×padding−dialation(1)×(kernel_size(5)−1)−1+1⌋
可得 27 + 2 × p a d d i n g s t r i d e = 1 \frac{27+2\times padding}{stride}=1 stride27+2×padding=1
所以padding = 2,stride = 1
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear
from torch.nn.modules.flatten import Flatten
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(3, 32, 5, padding=2) # input_channel = 3, output_channel = 32, kernel_size = 5 * 5 ,padding是计算出来的
self.maxpool1 = MaxPool2d(2) # maxpooling只有一个kernel_size参数
self.conv2 = Conv2d(32, 32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten() # 展平操作
self.linear1 = Linear(64 * 4 * 4, 64)
self.linear2 = Linear(64, 10)
def forward(self, m):
m = self.conv1(m)
m = self.maxpool1(m)
m = self.conv2(m)
m = self.maxpool2(m)
m = self.conv3(m)
m = self.maxpool3(m)
m = self.flatten(m)
m = self.linear1(m)
m = self.linear2(m)
return m
tudui = Tudui()
print("tudui:", tudui)
'''
tudui: Tudui(
(conv1): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=1024, out_features=64, bias=True)
(linear2): Linear(in_features=64, out_features=10, bias=True)
)
'''
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print("output.shape:", output.shape)
# output.shape: torch.Size([64, 10])
使用Sequential()把网络集成在一起,方便使用
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
print(tudui)
'''
Tudui(
(model1): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
'''
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
# torch.Size([64, 10])
writer = SummaryWriter("logs_seq")
writer.add_graph(tudui, input)
writer.close()
同时可以用SummaryWriter()查看网络
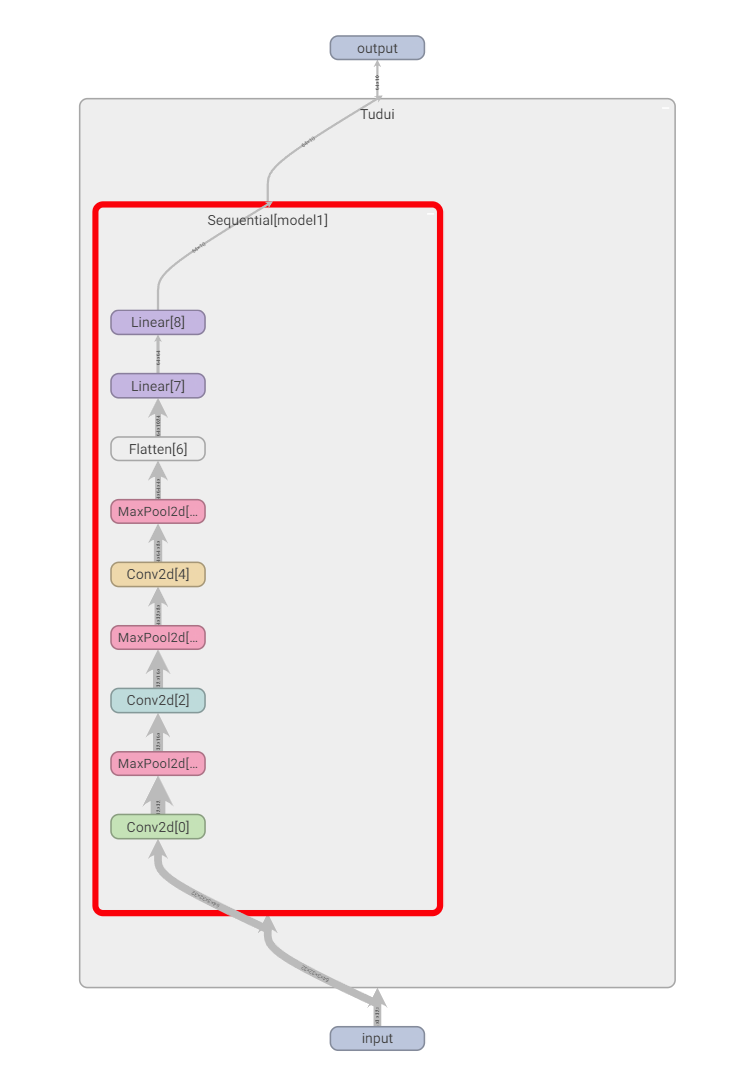
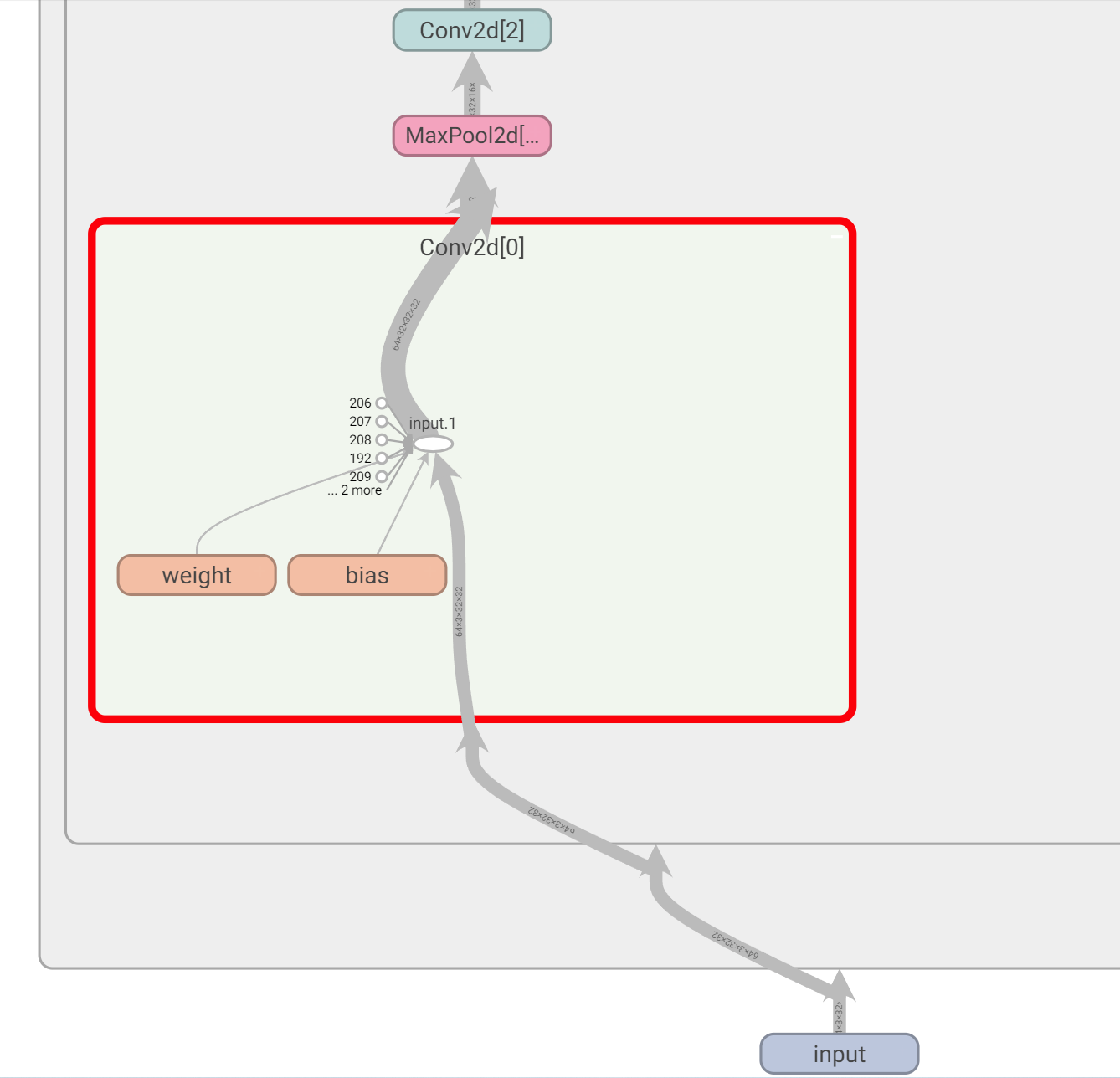
损失函数与反向传播


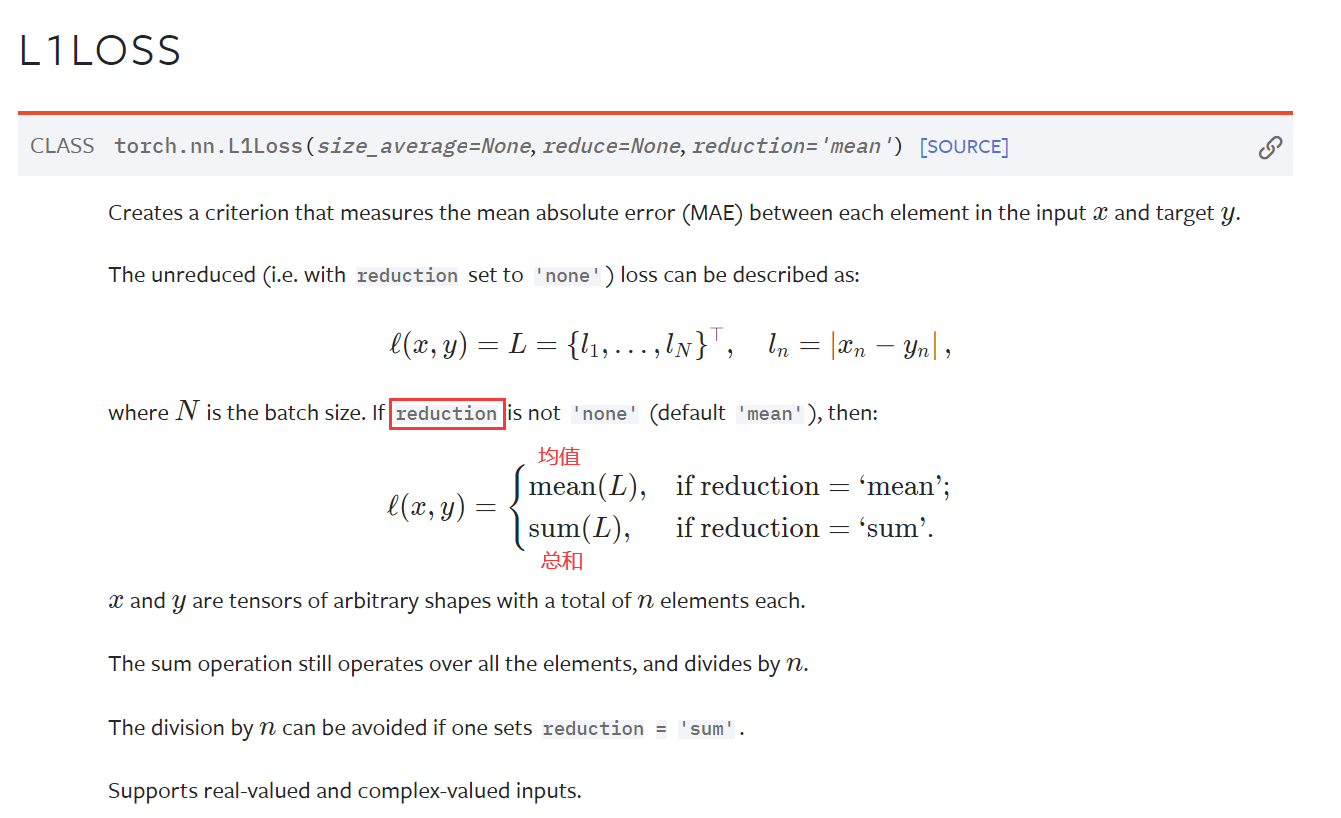
import torch
from torch import nn
from torch.nn import L1Loss
# 需要类型为float
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3)) # batch_size, channel, 1行, 3列
targets = torch.reshape(targets, (1, 1, 1, 3))
# reduction='mean'
loss = L1Loss(reduction='mean')
result = loss(inputs, targets) # (0 + 0 + 2.0) / 3
print(result)
# tensor(0.6667)
# reduction='sum'
loss = L1Loss(reduction='sum')
result = loss(inputs, targets) # 0 + 0 + 2.0
print(result)
# tensor(2.)
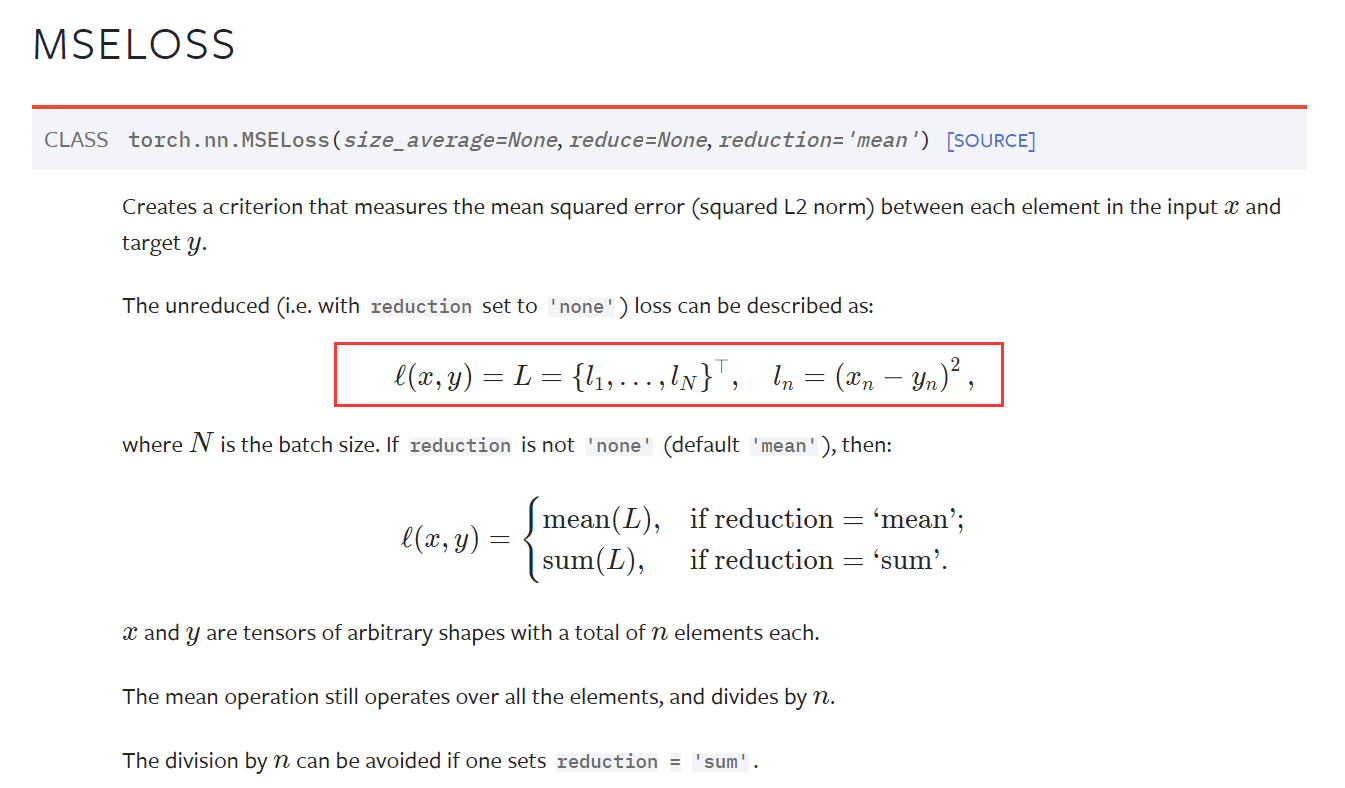
import torch
from torch import nn
# 需要类型为float
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3)) # batch_size, channel, 1行, 3列
targets = torch.reshape(targets, (1, 1, 1, 3))
# reduction='mean'
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets) # (0 + 0 + 2.0^2) / 3
print(result_mse)
# tensor(1.3333)
CROSSENTROPYLOSS交叉熵


举例
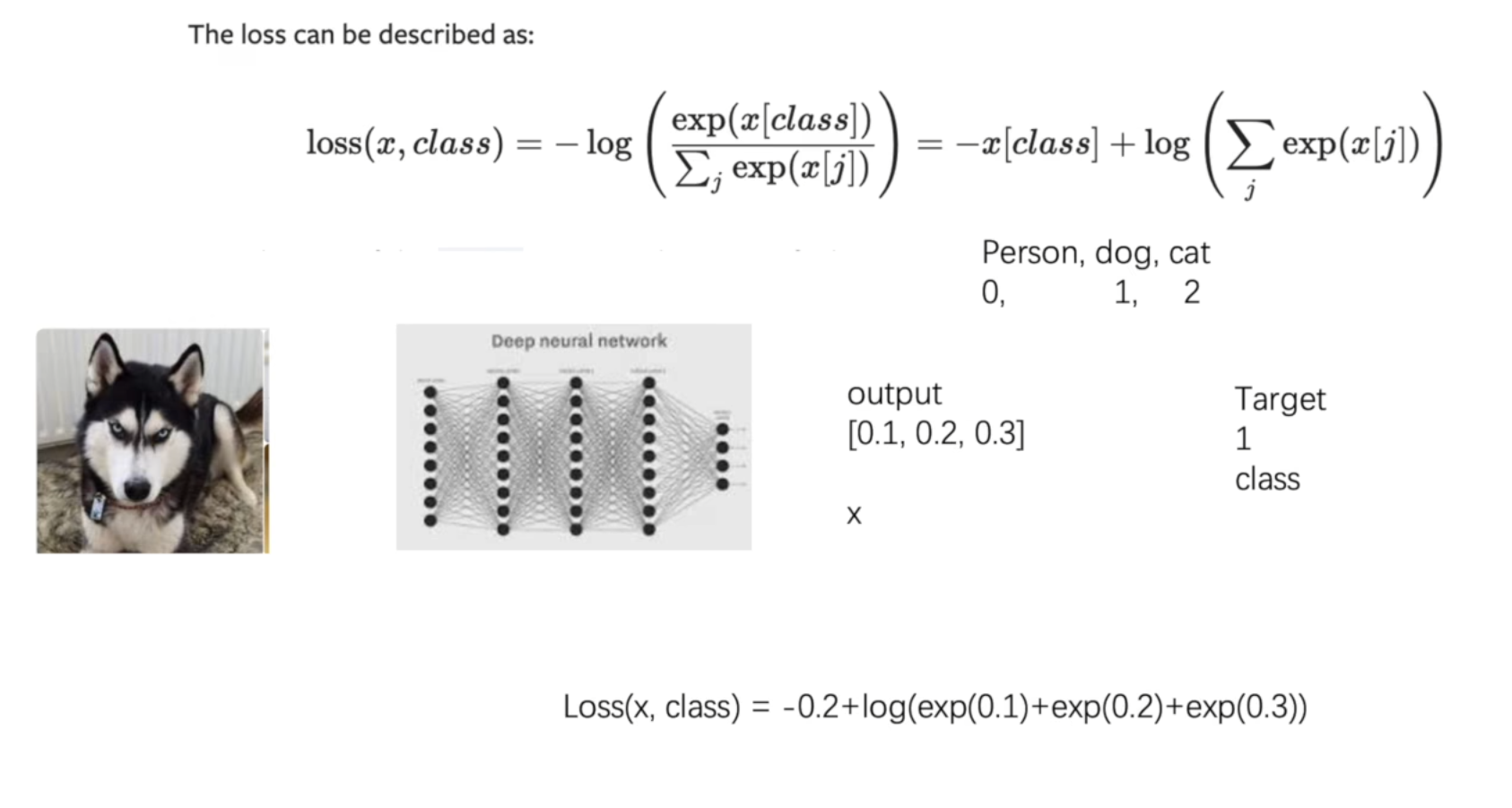
import torch
from torch import nn
x = torch.tensor([0.1, 0.2, 0.3]) # x 即output
y = torch.tensor([1]) # class 即 Target
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
# Loss(x,class) = -0.2(-x[1]) + log(exp(0.1(x[0]))+exp(0.2(x[1]))+exp(0.3(x[2])))
print(result_cross)
# tensor(1.1019)
运用
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
print(outputs,targets)
'''
outputs:
tensor([[ 0.0422, -0.0303, 0.0420, 0.0605, -0.0930, 0.0747, -0.0928, -0.1026,
0.0826, 0.0360]], grad_fn=<AddmmBackward0>)
targets: tensor([3])
'''
print(result_loss)
# tensor(2.2465, grad_fn=<NllLossBackward0>)
反向传播
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear, Sequential
from torch.nn.modules.flatten import Flatten
from torch.utils.data import DataLoader
'''
如何在之前的写的神经网络中用到Loss Function
'''
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss() # 定义损失函数
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets) # 调用损失函数
result_loss.backward() # 反向传播, 这里要注意不能使用定义损失函数那里的 loss,而要使用 调用损失函数之后的 result_loss
print("OK") # 这部分,在debug中可以看到 grad 通过反向传播之后,才有值,debug修好了之后,再来看这里
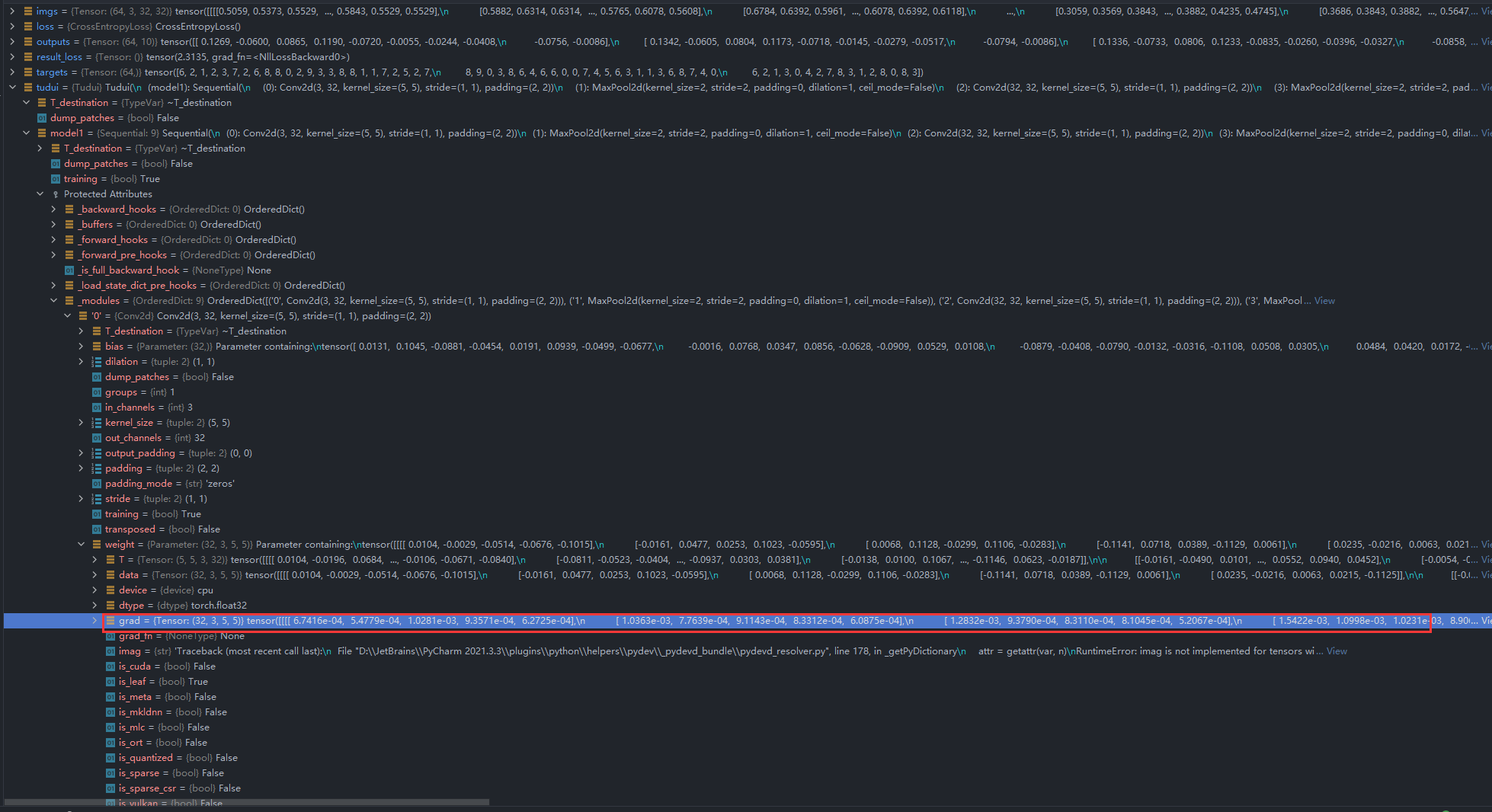
通过调试发现执行result_loss.backward()前grad的值为None
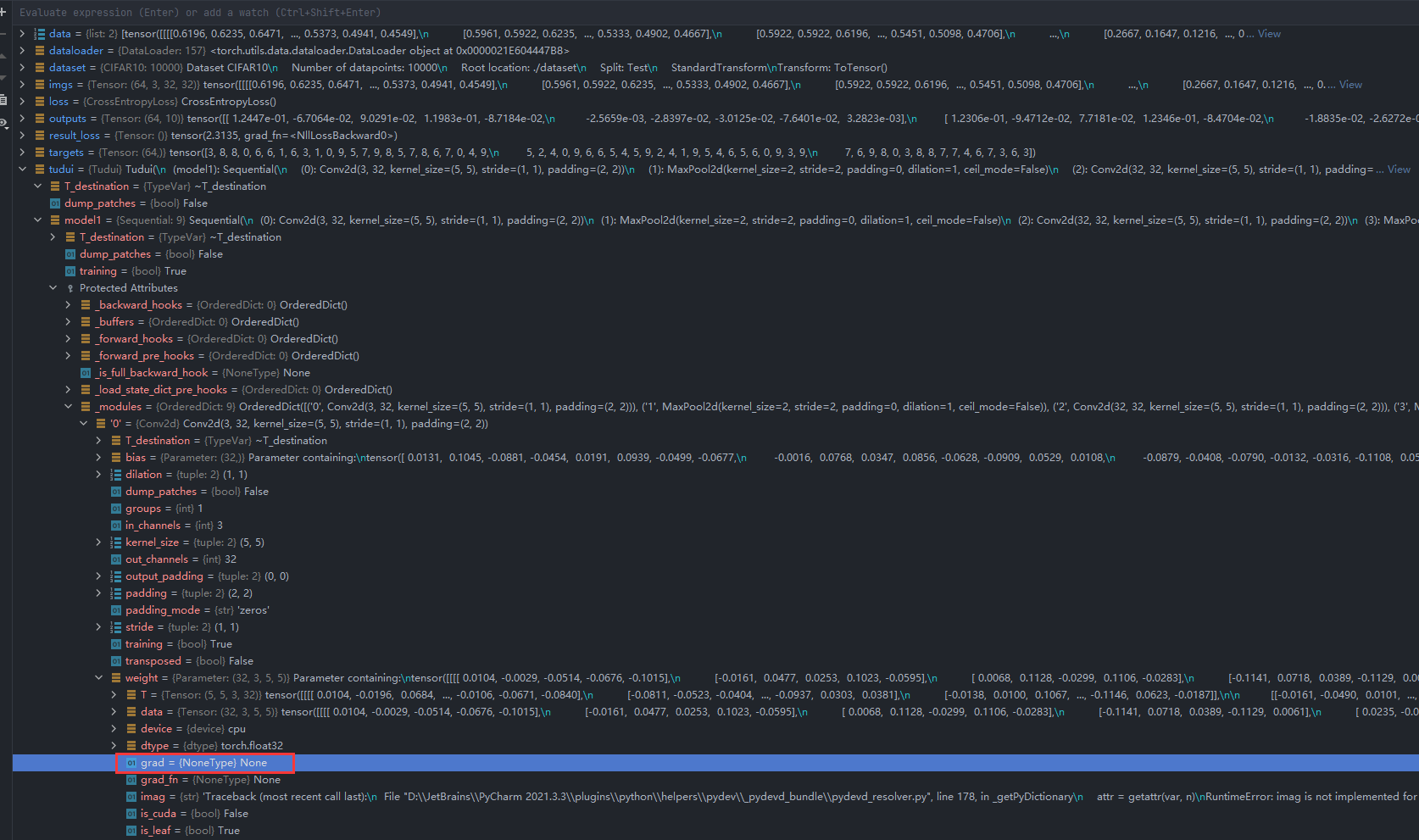
执行result_loss.backward()后grad的梯度数据已经计算出来了
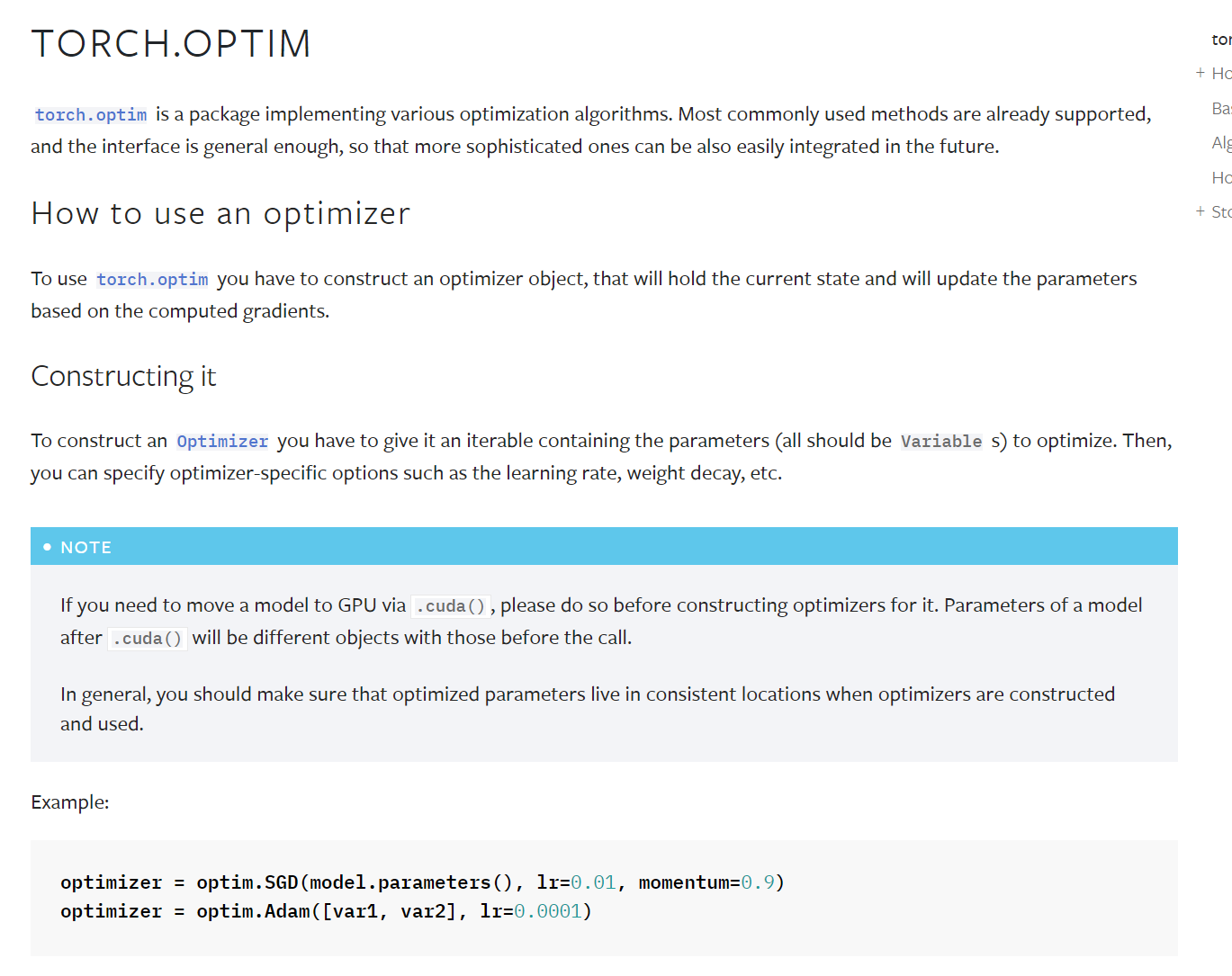
优化器
优化器利用反向传播,对参数进行调整
如果不深究,只要parameter和lr需要设置,其他的都是默认参数,其中lr为学习率
官方文档
代码核心部分
optim.zero_grad() # 优化器调优梯度清零
result_loss.backward() # 反向传播,这里要注意不能使用定义损失函数那里的 loss,而要使用 调用损失函数之后的 result_loss
optim.step() # 得到反向传播后的梯度,调用优化器对模型进行调优
一轮学习往往优化效果并不明显,因此往往是经过成百上千的学习优化
完整步骤
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear, Sequential
from torch.nn.modules.flatten import Flatten
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss() # 定义损失函数
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
for epoch in range(20):
running_loss = 0.0 # 总损失值
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets) # 调用损失函数
optim.zero_grad() # 优化器调优梯度清零
result_loss.backward() # 反向传播,这里要注意不能使用定义损失函数那里的 loss,而要使用 调用损失函数之后的 result_loss
optim.step() # 得到反向传播后的梯度,调用优化器对模型进行调优
running_loss = running_loss + result_loss
print(running_loss)
'''
tensor(360.2752, grad_fn=<AddBackward0>)
tensor(356.5604, grad_fn=<AddBackward0>)
tensor(343.3807, grad_fn=<AddBackward0>)
tensor(319.6839, grad_fn=<AddBackward0>)
tensor(309.4354, grad_fn=<AddBackward0>)
tensor(299.9025, grad_fn=<AddBackward0>)
tensor(290.8708, grad_fn=<AddBackward0>)
tensor(283.1693, grad_fn=<AddBackward0>)
tensor(276.0163, grad_fn=<AddBackward0>)
tensor(269.6815, grad_fn=<AddBackward0>)
tensor(263.8935, grad_fn=<AddBackward0>)
tensor(258.3795, grad_fn=<AddBackward0>)
tensor(253.1637, grad_fn=<AddBackward0>)
tensor(248.4202, grad_fn=<AddBackward0>)
tensor(244.1374, grad_fn=<AddBackward0>)
tensor(240.1671, grad_fn=<AddBackward0>)
tensor(236.4057, grad_fn=<AddBackward0>)
tensor(232.7907, grad_fn=<AddBackward0>)
tensor(229.3051, grad_fn=<AddBackward0>)
tensor(225.8931, grad_fn=<AddBackward0>)
'''