论文原名
Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting

论文粗读
原始Transformer中的Self-Attention结构如下:
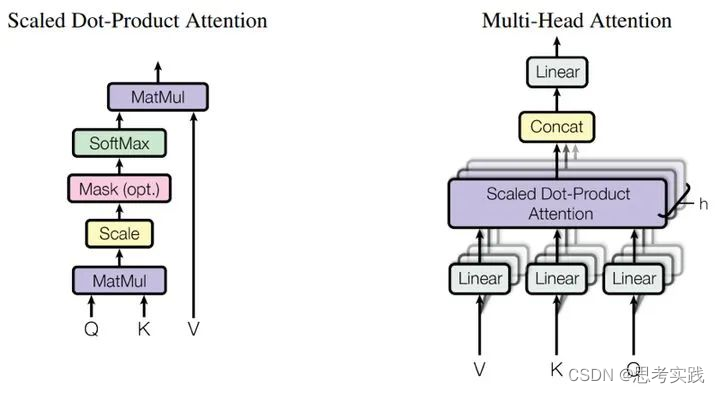

而论文中设计的Convolutional Self-Attention更适合时序数据, 因为它能够增强模型对时间序列中局部上下文信息的建模能力,从而降低异常点对预测结果的影响程度,提高预测准确性。这也是ConvTrans(Convolution Transformer)的名称由来。
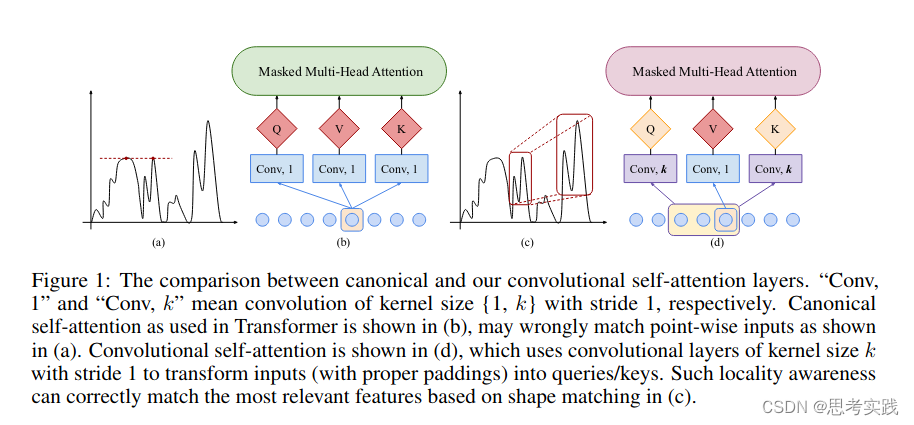
Self-Attention中的计算 Q、K、V 的过程可能导致数据的关注点出现异常,如上图中(a)所示,由于之前的注意力得分仅仅是单时间点之间关联的体现,(a)中中间的红点只关注到与它值相近的另一单时间红点,而没有考虑到自身上下文(即变化趋势)。即希望增强局部上下文的建模能力,得到图(c)中的效果。
作者们提出的改进方法是在计算 Query 和 Key 时采用大小大于1(等于1就是原始Transformer)的卷积核来进行卷积操作,如图中(d)所示,从而实现使注意力关注局部上下文,使得更相关的特征能够得到匹配。
论文链接
https://arxiv.org/pdf/1907.00235.pdf
参考资料