一、背景和目的
该数据集包含使用信用卡进行的金融交易的数据。这些数据是指欧洲运营商的客户,指的是 2013/9年期间。
该研究的目的是创建一个预测模型,该模型能够从通过数据集获得的“学习”中识别欺诈交易。信用卡公司能够提前识别欺诈行为至关重要。
数据集内容
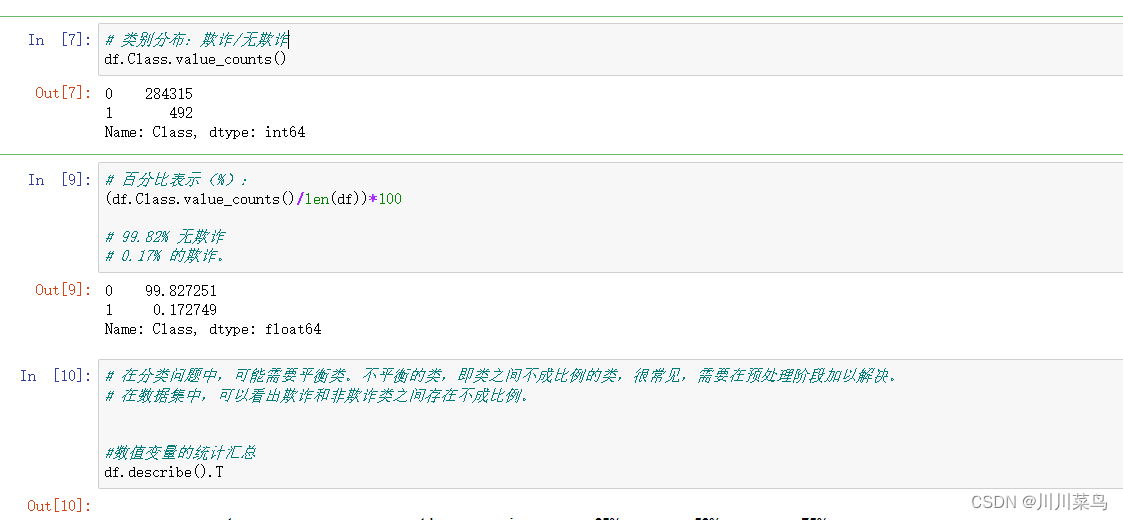
交易发生在两天内,总共 284,807 笔交易中有 492 笔是欺诈。数值变量是通过 PCA 变换(降维)获得的。
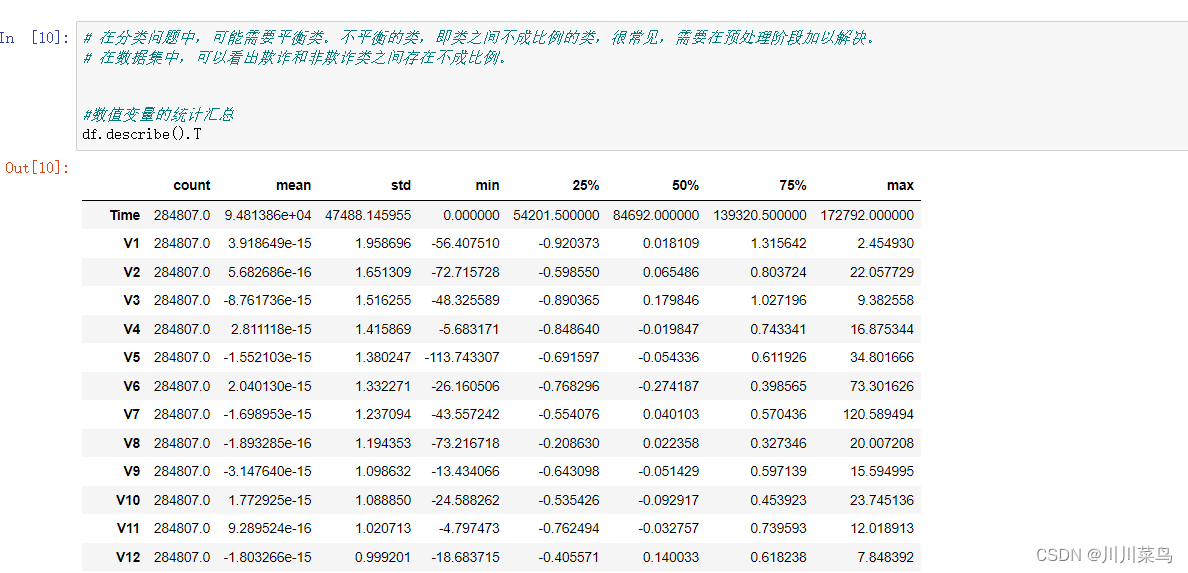
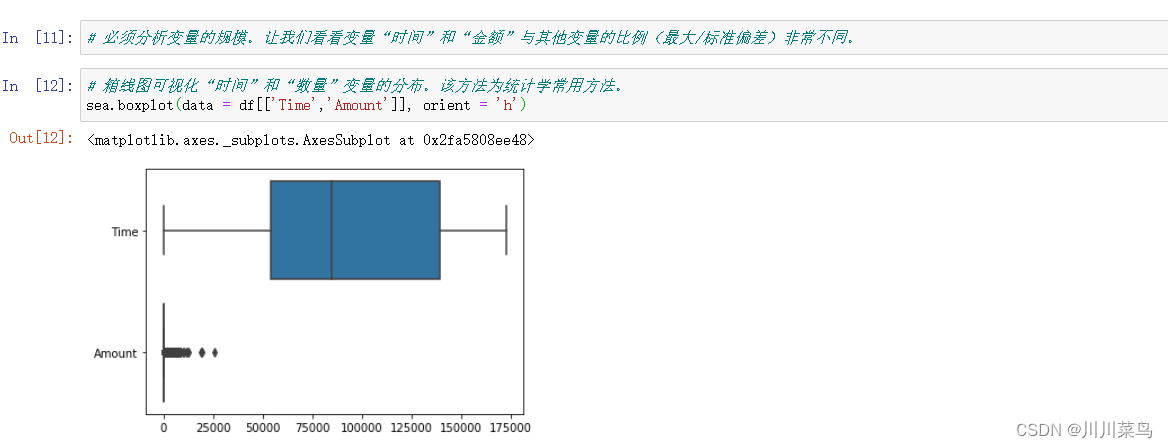
特征 V1、V2、… V28 是使用 PCA 获得的主成分,唯一没有使用 PCA 转换的特征是“时间”和“金额”。特征“时间”包含每个事务与数据集中第一个事务之间经过的秒数。特征“金额”是交易金额,该特征可用于依赖示例的成本敏感学习。特征“类”是响应变量,在欺诈的情况下取值为 1,否则为 0。
二、探索性数据集分析 (EDA)
导入数据:
# 导入模块
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt # para plotar gráficos
import seaborn as sea # para plotar gráficos
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv('creditcard.csv')
df.head()
如下:

基本分析:
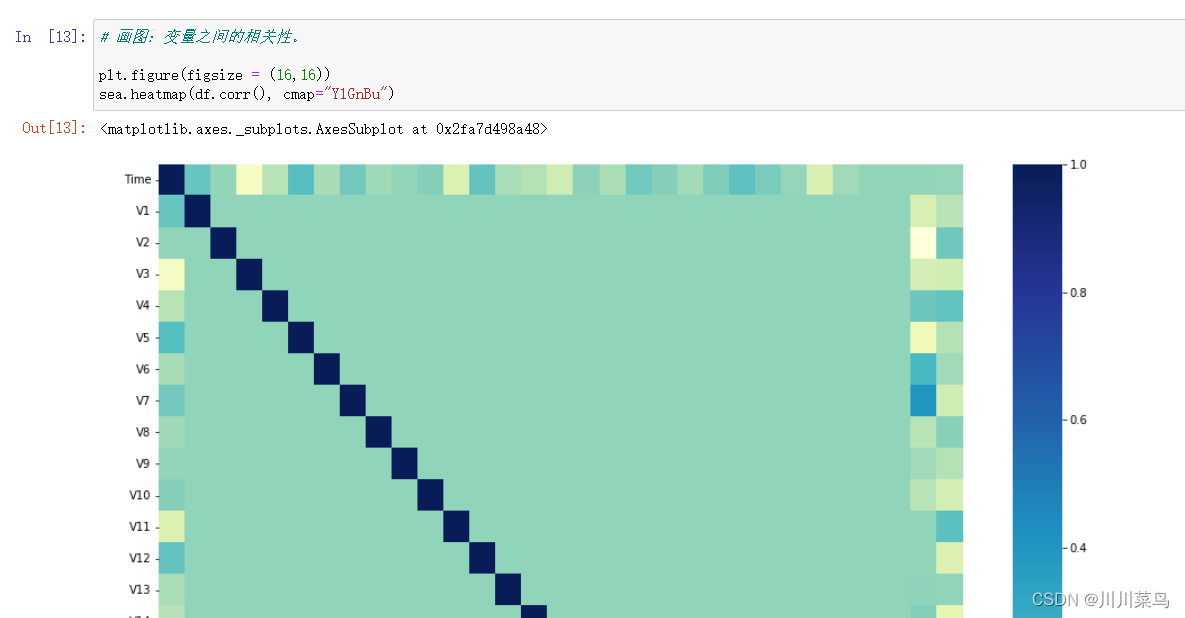
三、模型创建

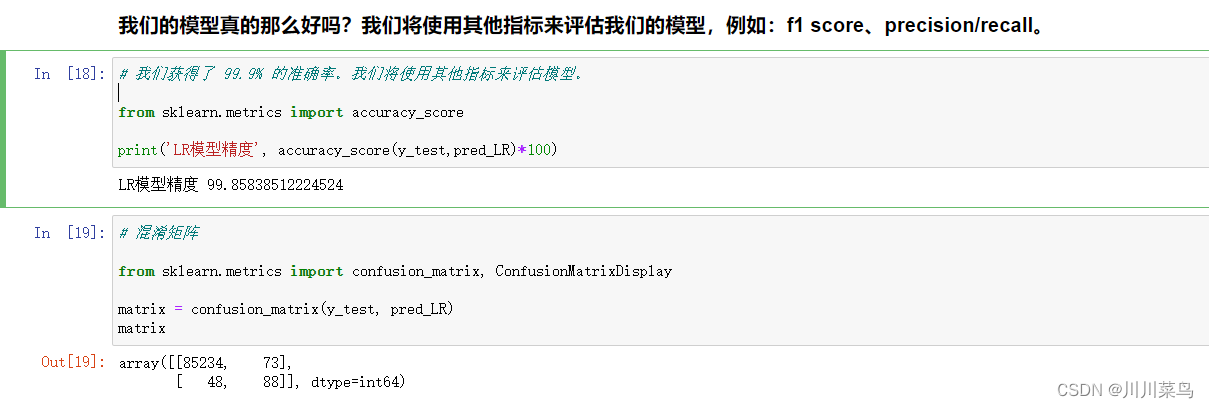
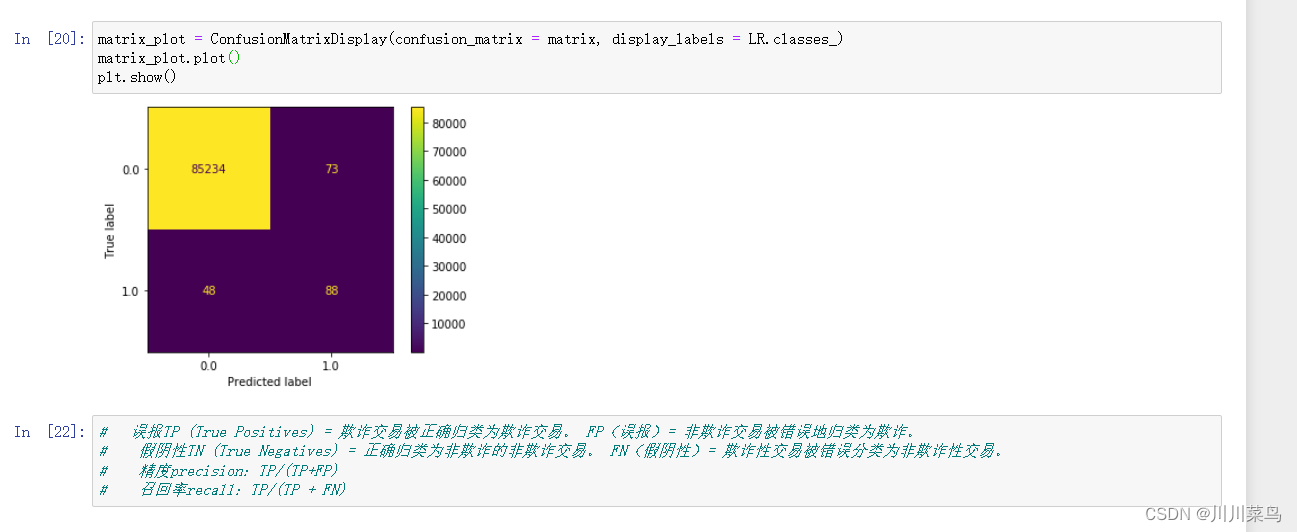
f1 score、precision/recall
省略一堆。。。。
中间省略的部分有:SMOTE - 合成少数过采样技术,使用交叉验证的决策树分类器,可以得到如下可视化图:
还有交叉验证。
展示一下XGBoost模型
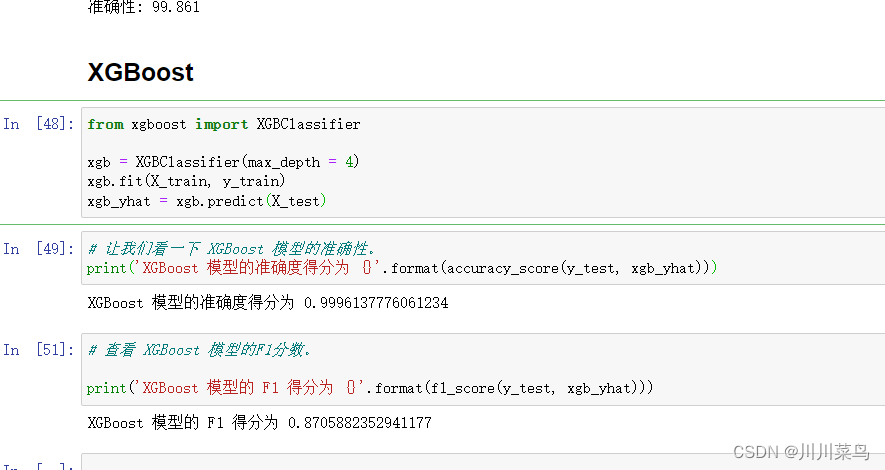
四、总结
综合上述使用的模型有:逻辑回归模型,决策树模型,XGBoost模型,随机森林。你可以根据这些模型的评分来选择一个最佳,在探索性数据集分析过程中使用到了比较多的数理统计概念,也有较多的数据可视化。
需要完整源码+v:hxgsrubxjogxeeag