最近为了毕设的车牌识别准备学习一下opencv这里记录一下学习的过程和笔记
opencv
图像操作
imread 读取图像
使用cv.imread()函数读取图像。图像应该在工作目录或图像的完整路径应给出。
第二个参数是一个标志,它指定了读取图像的方式。
cv.IMREAD_COLOR: 加载彩色图像。任何图像的透明度都会被忽视。它是默认标志。
cv.IMREAD_GRAYSCALE:以灰度模式加载图像
cv.IMREAD_UNCHANGED:加载图像,包括alpha通道
注意 除了这三个标志,你可以分别简单地传递整数1、0或-1。
cv2.imread()读取图片后以多维数组的形式保存图片信息,前两维表示图片的像素坐标,最后一维表示图片的通道索引,具体图像的通道数由图片的格式来决定
if __name__ == '__main__':
car=cv2.imread('./car4.jpg')
print(car.shape) #(300, 560, 3)数组形状 高度:300像素 宽度:560像素 3维
print(type(car)) #numpy数组
print(car) #三维数组 (彩色图片:高度,宽度,像素 红绿蓝)
cv2.imshow('car',car[::-1,:,:]) # 弹出窗口
#第一维表示高度 ::-1表示翻转,颠倒,上下颠倒
#第二维代表宽度
#第三维代表颜色 蓝0绿1红2
cv2.waitKey() #等待键盘输入,任意输出,发出这个代码窗口消失 0表示无限等待 ;1000毫秒
cv2.destroyAllWindows() #销毁内存
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread('car4.jpg', cv2.IMREAD_UNCHANGED) # 包含alpha通道
cv2.imshow('car',img)
img2 = cv2.imread('car4.jpg', cv2.IMREAD_COLOR) # 彩色图像
cv2.imshow('car2',img2)
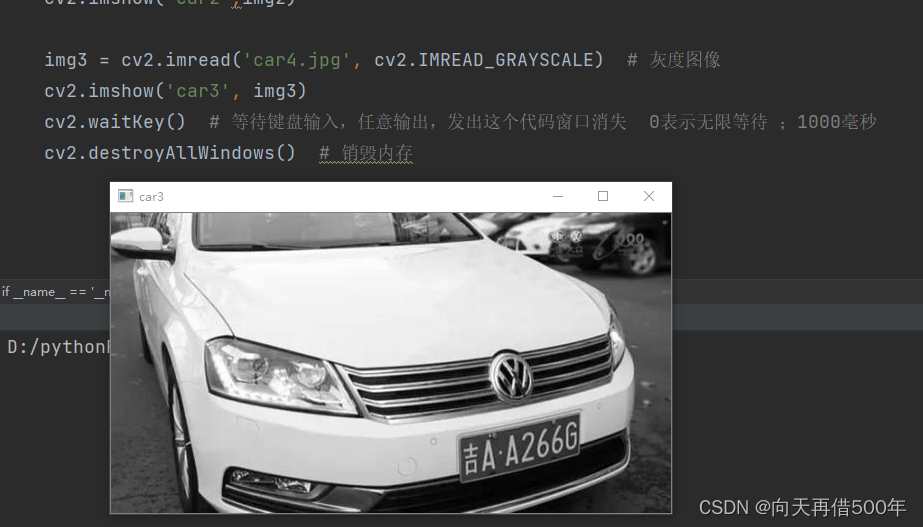
img3 = cv2.imread('car4.jpg', cv2.IMREAD_GRAYSCALE) # 灰度图像
cv2.imshow('car3', img3)
cv2.waitKey() # 等待键盘输入,任意输出,发出这个代码窗口消失 0表示无限等待 ;1000毫秒
cv2.destroyAllWindows() # 销毁内存

从详细信息可以看到,car4.jpg含有3个通道(R G B)即位深为24,每一个通道占8位,所以不包含alpha通道,所以前两个读出来是一样的效果
imshow显示图像
使用函数**cv.imshow()**在窗口中显示图像。窗口自动适合图像尺寸。
第一个参数是窗口名称,它是一个字符串。第二个参数是我们的对象。你可以根据需要创建任意多个窗口,但可以使用不同的窗口名称。
img3 = cv2.imread('car4.jpg', cv2.IMREAD_GRAYSCALE) # 灰度图像
cv2.imshow('car3', img3)
cv2.waitKey() # 等待键盘输入,任意输出,发出这个代码窗口消失 0表示无限等待 ;1000毫秒
cv2.destroyAllWindows() # 销毁内存
waitKey
waitKey()是一个键盘绑定函数。其参数是以毫秒为单位的时间。该函数等待任何键盘事件指定的毫秒。如果您在这段时间内按下任何键,程序将继续运行。如果0被传递,它将无限期地等待一次敲击键。它也可以设置为检测特定的按键,例如,如果按下键 a 等,我们将在下面讨论。
注意 除了键盘绑定事件外,此功能还处理许多其他GUI事件,因此你必须使用它来实际显示图像。
cv.destroyAllWindows()只会破坏我们创建的所有窗口。如果要销毁任何特定的窗口,请使用函数 cv.destroyWindow()在其中传递确切的窗口名称作为参数。
注意 在特殊情况下,你可以创建一个空窗口,然后再将图像加载到该窗口。在这种情况下,你可以指定窗口是否可调整大小。这是通过功能cv.namedWindow()完成的。默认情况下,该标志为cv.WINDOW_AUTOSIZE。但是,如果将标志指定为cv.WINDOW_NORMAL,则可以调整窗口大小。当图像尺寸过大以及向窗口添加跟踪栏时,这将很有帮助。
cv.namedWindow('image',cv.WINDOW_NORMAL)
cv.imshow('image',img)
cv.waitKey(0)
cv.destroyAllWindows()
resize改变图像大小
函数功能: 缩小或者放大函数至某一个大小
resize(InputArray src, OutputArray dst, Size dsize,
double fx=0, double fy=0, int interpolation=INTER_LINEAR )
参数解释:
InputArray src :输入,原图像,即待改变大小的图像;
OutputArray dst: 输出,改变后的图像。这个图像和原图像具有相同的内容,只是大小和原图像不一样而已;
dsize:输出图像的大小。
如果这个参数不为0,那么就代表将原图像缩放到这个Size(width,height)指定的大小;如果这个参数为0,那么原图像缩放之后的大小就要通过下面的公式来计算:
dsize = Size(round(fxsrc.cols), round(fysrc.rows))
其中,fx和fy就是下面要说的两个参数,是图像width方向和height方向的缩放比例。
fx:width方向的缩放比例,如果它是0,那么它就会按照(double)dsize.width/src.cols来计算;
fy:height方向的缩放比例,如果它是0,那么它就会按照(double)dsize.height/src.rows来计算;
使用注意事项:
dsize和fx/fy不能同时为0,
要么你就指定好dsize的值,让fx和fy空置直接使用默认值,就像resize(img, imgDst, Size(30,30));
要么你就让dsize为0,指定好fx和fy的值,比如fx=fy=0.5,那么就相当于把原图两个方向缩小一倍!
img.shape #(300, 560, 3)数组形状 高度:300像素 宽度:560像素 3维 先高度再宽度
resize 是先宽度在高度
car=cv2.imread('./car4.jpg')
car2=cv2.resize(car,(150,280))
cv2.imshow('car',car) # 弹出窗口
cv2.waitKey() #等待键盘输入,任意输出,发出这个代码窗口消失 0表示无限等待 ;1000毫秒
cv2.destroyAllWindows() #销毁内存
cvtColor改变颜色
cvtcolor()函数是一个颜色空间转换函数,可以实现RGB颜色向HSV,HSI等颜色空间转换。也可以转换为灰度图
car=cv2.imread('./car4.jpg')
car2=cv2.cvtColor(car,code=cv2.COLOR_BGR2GRAY)
cv2.imshow('car',car2) # 弹出窗口
cv2.waitKey() #等待键盘输入,任意输出,发出这个代码窗口消失 0表示无限等待 ;1000毫秒
cv2.destroyAllWindows() #销毁内存

car=cv2.imread('./car4.jpg')
car2=cv2.cvtColor(car,code=cv2.COLOR_BGR2HSV)
cv2.imshow('car',car2) # 弹出窗口
cv2.waitKey() #等待键盘输入,任意输出,发出这个代码窗口消失 0表示无限等待 ;1000毫秒
cv2.destroyAllWindows() #销毁内存

imwrite 写入图像
使用函数cv.imwrite()保存图像。
第一个参数是文件名,第二个参数是要保存的图像。 cv.imwrite(‘messigray.png’,img)
这会将图像以PNG格式保存在工作目录中。
img3 = cv2.imread('car4.jpg', cv2.IMREAD_GRAYSCALE) # 灰度图像
cv2.imwrite('./car3.jpg',img3)
hsv
HSV(Hue, Saturation, Value)是根据颜色的直观特性的一种颜色空间

这个模型中颜色的参数分别是:色调(H),饱和度(S),明度(V)
import cv2
import numpy as np
if __name__ == '__main__':
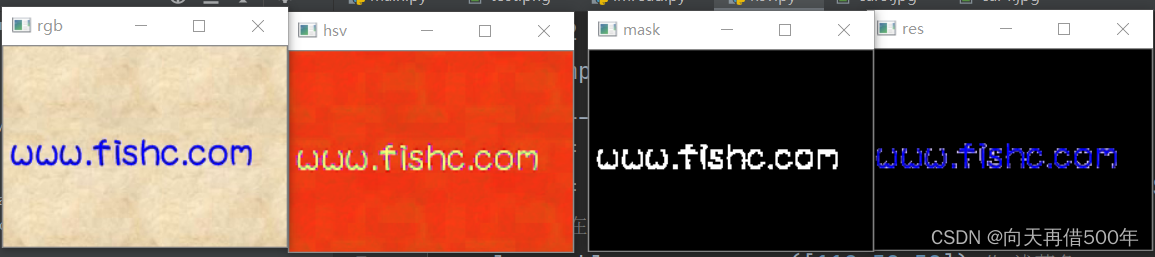
img1 = cv2.imread('./test.png') # 颜色空间BGR
img2 = cv2.cvtColor(img1,code = cv2.COLOR_BGR2HSV) # 颜色空间的转变
# 定义在HSV颜色空间中蓝色的范围
lower_blue = np.array([110,50,50]) # 浅蓝色
upper_blue = np.array([130,255,255]) # 深蓝色
# 根据蓝色的范围,标记图片中哪些位置是蓝色
# inRange 是否在这个范围内 lower_bule ~ upper_blue:蓝色
# 如果在那么就是255,不然就是0
mask = cv2.inRange(img2,lower_blue,upper_blue)
res = cv2.bitwise_and(img1, img1,mask = mask) # 位运算:与运算!
cv2.imshow('rgb',img1)
cv2.imshow('hsv',img2)
cv2.imshow('mask',mask)
cv2.imshow('res',res)
cv2.waitKey(0)
cv2.destroyAllWindows() # 键盘输入,窗口,销毁,释放内存
如何找到要追踪的HSV值?
这是在stackoverflow.com上发现的一个常见问题。它非常简单,你可以使用相同的函数cv.cvtColor()。你只需传递你想要的BGR值,而不是传递图像。例如,要查找绿色的HSV值,
green = np.uint8([[[0,255,0 ]]])
hsv_green = cv.cvtColor(green,cv.COLOR_BGR2HSV)
print( hsv_green )
[[[ 60 255 255]]]
马赛克
后面都将以这个图片为例,宽350,高232
马赛克方式一
就是把图片先缩小,在放大,其实就是让图片变模糊
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread('./bao.jpeg')
print(img.shape) # 高度232,宽度350
# 马赛克方式一
img2 = cv2.resize(img,(35,23))
img3 = cv2.resize(img2,(350,232))
cv2.imshow('bao',img3)
cv2.waitKey(0)
cv2.destroyAllWindows()

马赛克方式二
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread('./bao.jpeg')
print(img.shape) # 高度232,宽度350
img2 = cv2.resize(img,(35,23)) #先缩小10倍
img3 = np.repeat(img2,10,axis=0) # 重复行
img4 = np.repeat(img3,10,axis=1) # 重复列
cv2.imshow('bao',img4)
cv2.waitKey(0)
cv2.destroyAllWindows()

马赛克方式三
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread('./bao.jpeg')
print(img.shape) # 高度232,宽度350
# 马赛克方式3
img2 = img[::10, ::10] # 每10个中取出一个像素,细节
cv2.namedWindow('bao', flags=cv2.WINDOW_NORMAL)
cv2.resizeWindow('bao', 350, 232)
cv2.imshow('bao', img2)
cv2.waitKey(0)
cv2.destroyAllWindows()

人脸马赛克
import numpy as np
import cv2
if __name__ == '__main__':
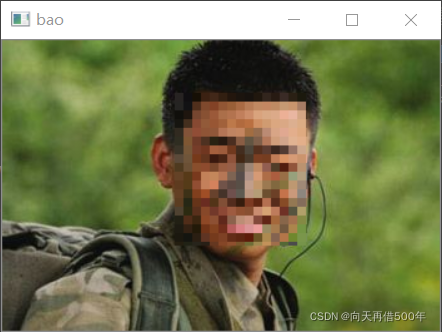
img = cv2.imread('./bao.jpeg')
# 1、人为人脸定位
# 人脸左上角坐标(143,42);右下角(239,164)(x,y)(宽度、高度)
# 2、切片获取人脸
face = img[42:164,138:244]
# 3、间隔切片,重复,切片,赋值
face = face[::7,::7] # 每7个中取出一个像素,马赛克
face = np.repeat(face,7,axis = 0) # 行方向重复7次
face = np.repeat(face, 7, axis=1) # 列方向上重复7次
img[42:164,138:244] = face[:122,:106] # 填充,尺寸一致
# 4、显示
cv2.imshow('bao',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
人脸检测
首先到github 搜opencv,
我这里用的第一个特征的xml
import numpy as np
import cv2
if __name__ == '__main__':
img = cv2.imread('./bao.jpeg')
# 人脸特征详细说明,1万多行,计算机根据这些特征,进行人脸检测
# 符合其中一部分,算做人脸
# 级联分类器,检测器,
face_detector = cv2.CascadeClassifier('./haarcascade_frontalface_alt.xml')
faces=face_detector.detectMultiScale(img) # 前两个是人脸坐标 x,y 后两个是宽和高
print(faces) # [[125 38 133 133]] x,y,w,h
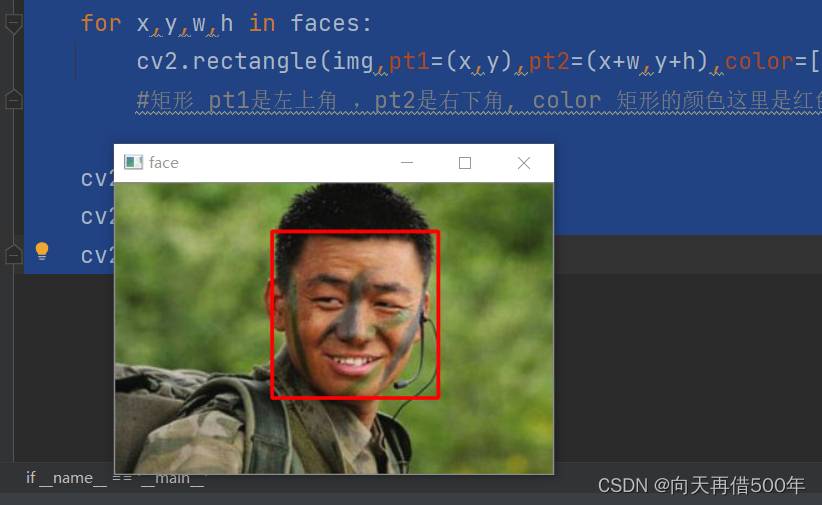
for x,y,w,h in faces:
cv2.rectangle(img,pt1=(x,y),pt2=(x+w,y+h),color=[0,0,255],thickness=2)
#矩形 pt1是左上角 ,pt2是右下角, color 矩形的颜色这里是红色 ,thickness粗细 值越大越粗
cv2.imshow('face',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
多张人脸检测
import numpy as np
import cv2
if __name__ == '__main__':
img = cv2.imread('./sew2.jpeg')
gray = cv2.cvtColor(img,code=cv2.COLOR_BGR2GRAY) # 使用灰白可以使数据变少
# 人脸特征详细说明,1万多行,计算机根据这些特征,进行人脸检测
# 符合其中一部分,算做人脸
# 级联分类器,检测器,
face_detector = cv2.CascadeClassifier('./haarcascade_frontalface_alt.xml')
faces = face_detector.detectMultiScale(gray,
scaleFactor=1.05,# 缩放
minNeighbors=10,minSize=(60,60)) # 坐标x,y,w,h
# 可以调整参数使算法检测到人脸,
for x,y,w,h in faces: # for循环可以进行数组遍历!
# cv2.rectangle(img,
# pt1=(x,y),
# pt2=(x + w,y+h),
# color = [0,0,255],
# thickness=2) # 矩形
cv2.circle(img,center=(x + w//2,y+h//2),# 圆心
radius=w//2, # 半径
color=[0,0,255],thickness=2)
cv2.imshow('face',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
- image表示的是要检测的输入图像
- objects表示被检测物体的矩形框向量组;
- scaleFactor表示每次图像尺寸减小的比例
- minNeighbors表示构成检测目标的相邻矩形的最小个数(默认为3个)。如果组成检测目标的小矩形的个数和小于 min_neighbors - 1 都会被排除。如果min_neighbors 为 0, 则函数不做任何操作就返回所有的被检候选矩形框
- minSize为目标的最小尺寸
- maxSize为目标的最大尺寸

这里一定要加上minSize=(60,60)因为有个人的领带会被识别成人脸,通过打印可以看到这个图只有(53,53)比正常的人脸要小一些,所以就可以通过最小大小过滤掉
多张人脸检测+马赛克
import numpy as np
import cv2
if __name__ == '__main__':
img = cv2.imread('./sew2.jpeg')
gray = cv2.cvtColor(img,code=cv2.COLOR_BGR2GRAY) # 数据变少
# 人脸特征详细说明,1万多行,计算机根据这些特征,进行人脸检测
# 符合其中一部分,算做人脸
# 级联分类器,检测器,
face_detector = cv2.CascadeClassifier('./haarcascade_frontalface_alt.xml')
faces = face_detector.detectMultiScale(gray,
scaleFactor=1.05,# 缩放
minNeighbors=10,minSize=(60,60)) # 坐标x,y,w,h
print(faces)
for x,y,w,h in faces: # for循环可以进行数组遍历!
face = img[y:y+h,x:x+w]
face = face[::10,::10]
face = np.repeat(face, 10, axis=0)
face = np.repeat(face, 10, axis=1)
img[y:y+h,x:x+w] = face[:h,:w]
cv2.imshow('face',img)
cv2.waitKey(0)
cv2.destroyAllWindows()

人脸贴纸画

import cv2
import numpy as np
if __name__ == '__main__':
img=cv2.imread('./han.jpeg')
gray=cv2.cvtColor(img,code=cv2.COLOR_BGR2GRAY)
star=cv2.imread('./star.jpg')
# 级联分类器,检测器,
face_detector = cv2.CascadeClassifier('./haarcascade_frontalface_alt.xml')
faces = face_detector.detectMultiScale(gray) # 前两个是人脸坐标 x,y 后两个是宽和高
for x,y,w,h in faces:
cv2.rectangle(img, pt1=(x, y), pt2=(x + w, y + h), color=[0, 0, 255], thickness=2)
# 矩形 pt1是左上角 ,pt2是右下角, color 矩形的颜色这里是红色 ,thickness粗细 值越大越粗
img[y:y+h//4,x+3*w//8:x+w//4+3*w//8]=cv2.resize(star,(w//4,h//4))#将坐标移到正中央
cv2.imshow('face', img)
cv2.waitKey(0)
cv2.destroyAllWindows()

import cv2
if __name__ == '__main__':
img = cv2.imread('./han.jpeg')
gray = cv2.cvtColor(img, code=cv2.COLOR_BGR2GRAY)
face_detector = cv2.CascadeClassifier('./haarcascade_frontalface_alt.xml')
faces = face_detector.detectMultiScale(gray)
star = cv2.imread('./star.jpg')
for x,y,w,h in faces:
star_s = cv2.resize(star, (w // 2, h // 2))
w1 = w//2
h1 = h//2
for i in range(h1):
for j in range(w1):#遍历 图片数据
if not (star_s[i,j] > 180).all():# 红色
img[i+y,j+x+w//4] = star_s[i,j]
cv2.imshow('face',img)
cv2.waitKey(0)
cv2.destroyAllWindows()

手工绘制轮廓
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread('./flower.jpg') # 蓝绿红,适合显示图片
hsv = cv2.cvtColor(img, code=cv2.COLOR_BGR2HSV) # 颜色空间,适合计算
# 轮廓查找,使用的是,颜色值,进行的
lower_red = (156,50,50) # 浅红色
upper_red = (180,255,255) # 深红色
mask = cv2.inRange(hsv, lower_red, upper_red)
# # 手工绘制轮廓
h,w,c = img.shape
mask = np.zeros((h, w), dtype=np.uint8)
x_data = np.array([124, 169, 208, 285, 307, 260, 175])+110 # 横坐标
y_data = np.array([205, 124, 135, 173, 216, 311, 309])+110# 纵坐标
pts = np.c_[x_data,y_data] # 横纵坐标合并,点(x,y)
print(pts)
cv2.fillPoly(mask, [pts], (255)) # 绘制多边形!
res = cv2.bitwise_and(img, img, mask=mask)
cv2.imshow('flower',res)
cv2.waitKey(0)
cv2.destroyAllWindows()


查找轮廓边界
import cv2
import numpy as np
if __name__ == '__main__':
dog = cv2.imread('./head.jpg')
gray = cv2.cvtColor(dog, cv2.COLOR_BGR2GRAY)
gray2 = cv2.GaussianBlur(gray,(5,5),0) # 高斯平滑,高斯模糊
canny = cv2.Canny(gray2,150,200)
cv2.imshow('dog',gray)
cv2.imshow('dog2',gray2)
cv2.imshow('canny',canny)
cv2.waitKey(0)
cv2.destroyAllWindows()
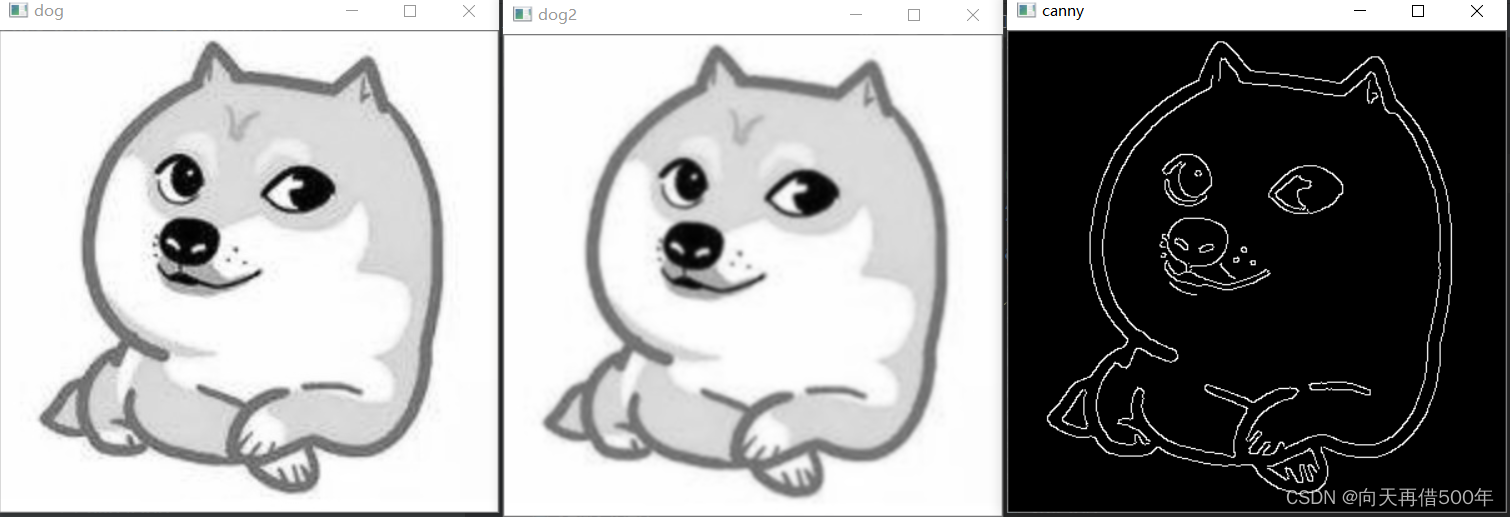
使用cv2做高斯模糊,只要一行代码调用GaussianBlur函数,给出高斯矩阵的尺寸和标准差就可以:
gray2 = cv2.GaussianBlur(gray,(5,5),0) # 高斯平滑,高斯模糊
这里(5, 5)表示高斯矩阵的长与宽都是5,标准差取0时OpenCV会根据高斯矩阵的尺寸自己计算。概括地讲,高斯矩阵的尺寸越大,标准差越大,处理过的图像模糊程度越大。也可以自己构造高斯核,相关函数:cv2.GaussianKernel().
可以来退出由照相机或其他环境产生的噪声,减少在边缘提取时的其余边缘的数目
cv2.Canny(src, thresh1, thresh2) 进行canny边缘检测
- src表示输入的图片,
- thresh1表示最小阈值,
- thresh2表示最大阈值,用于进一步删选边缘信息
人脸轮廓替换
import numpy as np
import cv2
if __name__ == '__main__':
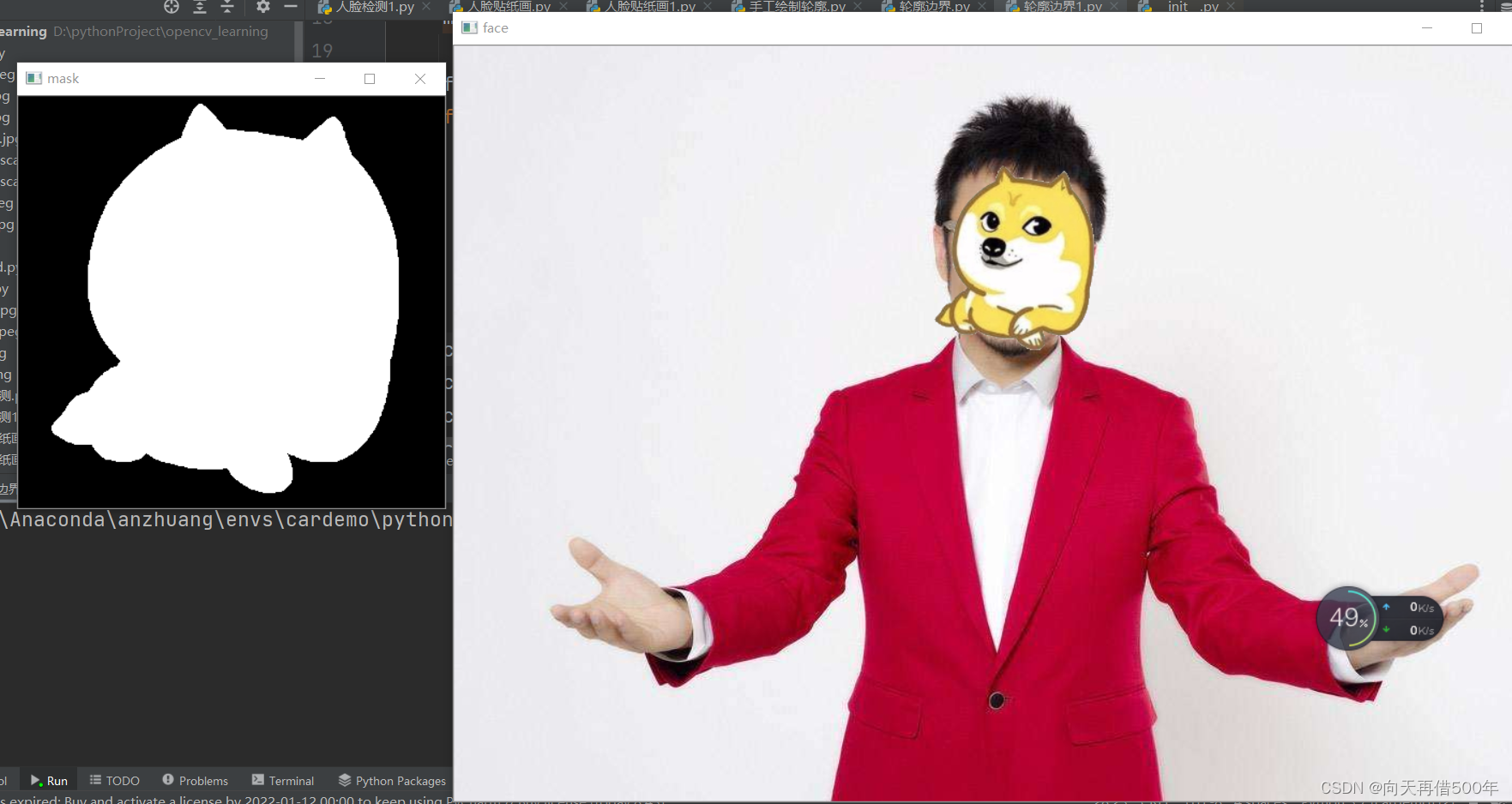
han = cv2.imread('./han.jpeg')
head = cv2.imread('./head.jpg')
face_detector = cv2.CascadeClassifier('./haarcascade_frontalface_alt.xml')
han_gray = cv2.cvtColor(han, code=cv2.COLOR_BGR2GRAY)
head_gray = cv2.cvtColor(head, code=cv2.COLOR_BGR2GRAY)
# 将狗头像二值化处理,THRESH_OTSU会自动设置阈值
threshold,head_binary = cv2.threshold(head_gray, 0, 255, cv2.THRESH_OTSU)
contours, hierarchy = cv2.findContours(head_binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
areas = []
for contour in contours:
areas.append(cv2.contourArea(contour)) #计算面积
areas = np.asarray(areas)
index = areas.argsort() # 从小到大,倒数第二个,第二大轮廓
mask = np.zeros_like(head,dtype=np.uint8) # mask面具
mask = cv2.drawContours(mask,contours,index[-2],(255,255,255),
thickness=-1)
faces = face_detector.detectMultiScale(han_gray)
for x,y,w,h in faces:
mask2 = cv2.resize(mask,(w,h))
head2 = cv2.resize(head, (w, h)) # 彩色图片
for i in range(h):
for j in range(w):
if (mask2[i,j] == 255).all():
han[i + y,j + x]=head2[i,j]
cv2.imshow('mask',mask)
cv2.imshow('face',han)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.threshold(img, threshold, maxval,type)
其中:
- threshold是设定的阈值
- maxval是当灰度值大于(或小于)阈值时将该灰度值赋成的值
- type规定的是当前二值化的方式
返回值 是阈值和目标
cv2.THRESH_BINARY 大于阈值的部分被置为255,小于部分被置为0
cv2.THRESH_BINARY_INV 大于阈值部分被置为0,小于部分被置为255
cv2.THRESH_TRUNC 大于阈值部分被置为threshold,小于部分保持原样
cv2.THRESH_TOZERO 小于阈值部分被置为0,大于部分保持不变
cv2.THRESH_TOZERO_INV 大于阈值部分被置为0,小于部分保持不变
其实还有很重要的cv2.THRESH_OTSU 作为图像自适应二值化的一个很优的算法Otsu大津算法的参数:
使用为cv2.threshold(img, 0, 255, cv2.THRESH_OTSU )
函数cv2.findContours()有三个参数。
第一个是输入图像,第二个是轮廓检索模式,第三个是轮廓近似方法。
RETR_LIST 从解释的角度来看,这中应是最简单的。它只是提取所有的轮廓,而不去创建任何父子关系。
RETR_EXTERNAL 如果你选择这种模式的话,只会返回最外边的的轮廓,所有的子轮廓都会被忽略掉。
RETR_CCOMP 在这种模式下会返回所有的轮廓并将轮廓分为两级组织结构。
RETR_TREE 这种模式下会返回所有轮廓,并且创建一个完整的组织结构列表。它甚至会告诉你谁是爷爷,爸爸,儿子,孙子等
返回值有两个,第一个是轮廓,第二个是(轮廓的)层析结构
cv2.drawContours()
cv2.drawContours(image, contours, contourIdx, color, thickness=None, lineType=None, hierarchy=None, maxLevel=None, offset=None)
InputOutputArray image,//要绘制轮廓的图像
InputArrayOfArrays contours,//所有输入的轮廓,每个轮廓被保存成一个point向量
int contourIdx,//指定要绘制轮廓的编号,如果是负数,则绘制所有的轮廓
const Scalar& color,//绘制轮廓所用的颜色
int thickness = 1, //绘制轮廓的线的粗细,如果是负数,则轮廓内部被填充
int lineType = 8, /绘制轮廓的线的连通性
InputArray hierarchy = noArray(),//关于层级的可选参数,只有绘制部分轮廓时才会用到
int maxLevel = INT_MAX,//绘制轮廓的最高级别,这个参数只有hierarchy有效的时候才有效
//maxLevel=0,绘制与输入轮廓属于同一等级的所有轮廓即输入轮廓和与其相邻的轮廓
//maxLevel=1, 绘制与输入轮廓同一等级的所有轮廓与其子节点。
//maxLevel=2,绘制与输入轮廓同一等级的所有轮廓与其子节点以及子节点的子节点
Point offset = Point()
另一种方法按位与的方式
import numpy as np
import cv2
if __name__ == '__main__':
han = cv2.imread('./han.jpeg')
head = cv2.imread('./head.jpg')
face_detector = cv2.CascadeClassifier('./haarcascade_frontalface_alt.xml')
han_gray = cv2.cvtColor(han, code=cv2.COLOR_BGR2GRAY)
head_gray = cv2.cvtColor(head, code=cv2.COLOR_BGR2GRAY)
# 旺旺二进制图片,黑白
threshold,head_binary = cv2.threshold(head_gray, 50, 255, cv2.THRESH_OTSU)
contours, hierarchy = cv2.findContours(head_binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
areas = []
for contour in contours:
areas.append(cv2.contourArea(contour))
areas = np.asarray(areas)
index = areas.argsort() # 从小到大,倒数第二个,第二大轮廓
mask = np.zeros_like(head_gray,dtype=np.uint8) # mask面具
mask = cv2.drawContours(mask,contours,index[-2],(255,255,255),
thickness=-1)
faces = face_detector.detectMultiScale(han_gray)
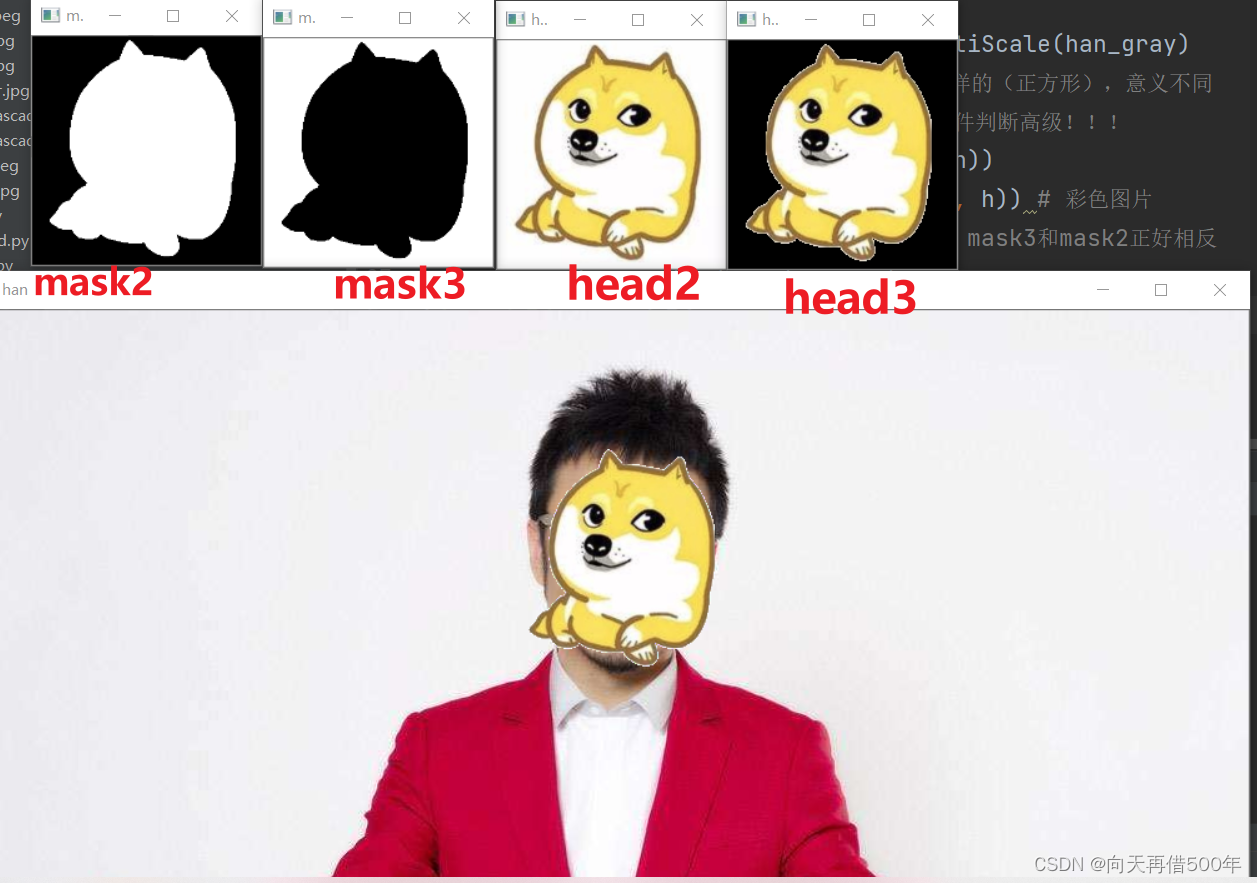
for x,y,w,h in faces: # w和h值一样的(正方形),意义不同
# 位运算比上一个代码中的for循环条件判断高级!!!
mask2 = cv2.resize(mask,(w,h))
head2 = cv2.resize(head, (w, h)) # 彩色图片
mask3 = (mask2 - 255)*255 # mask3和mask2正好相反
face = han[y:y+h,x:x+w]
# 黑色地方,没有进行计算,白色的地方进行了与运算
head3 = cv2.bitwise_and(head2,head2,mask=mask2)
cv2.imshow('head2', head2)
cv2.imshow('mask2', mask2)
cv2.imshow('mask3',mask3)
cv2.imshow('head3', head3)
face = cv2.bitwise_and(face,face,mask = mask3)
face = cv2.bitwise_or(head3,face) # 没有给mask 计算所有
han[y:y+h,x:x+w] = face
cv2.imshow('han',han)
cv2.waitKey(0)
cv2.destroyAllWindows()
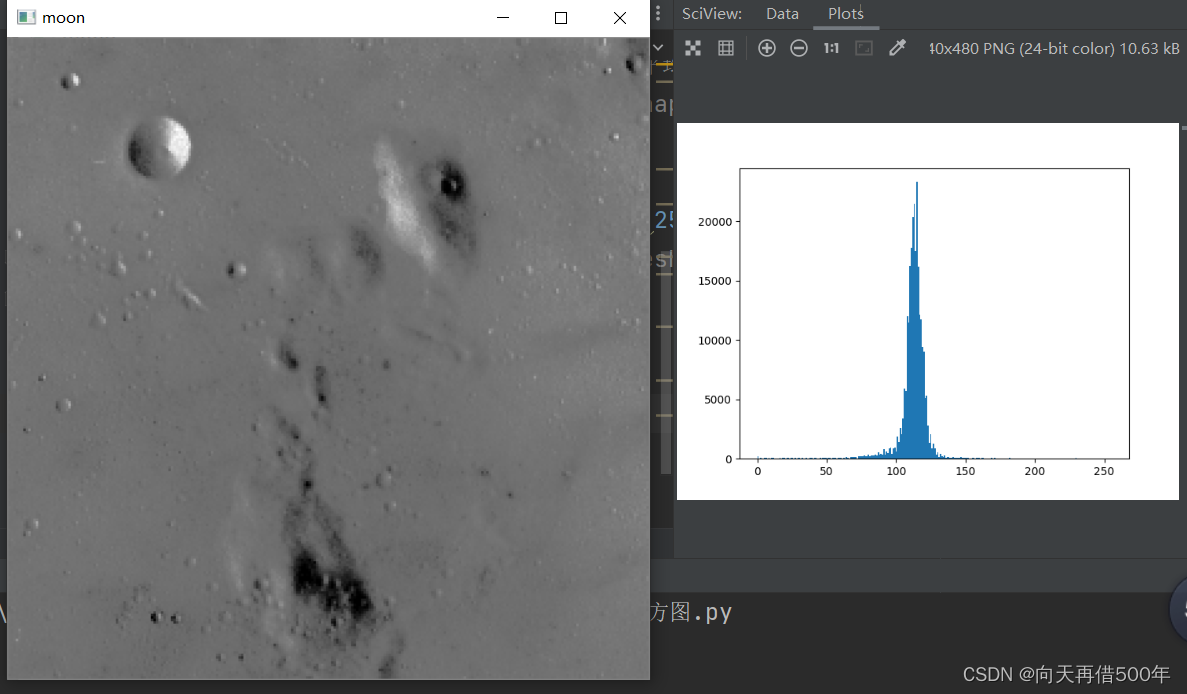
直方图均衡化处理
import numpy as np
import cv2 # opencv没有提供案例图片
import matplotlib.pyplot as plt
from skimage import data
moon = data.moon()
plt.hist(moon.ravel(),bins = 256) #ravel() 将数据变成一维 bins分成256份
plt.show()
cv2.imshow('moon',moon)
# 直方图均衡化,可以将图片的明暗对比增强
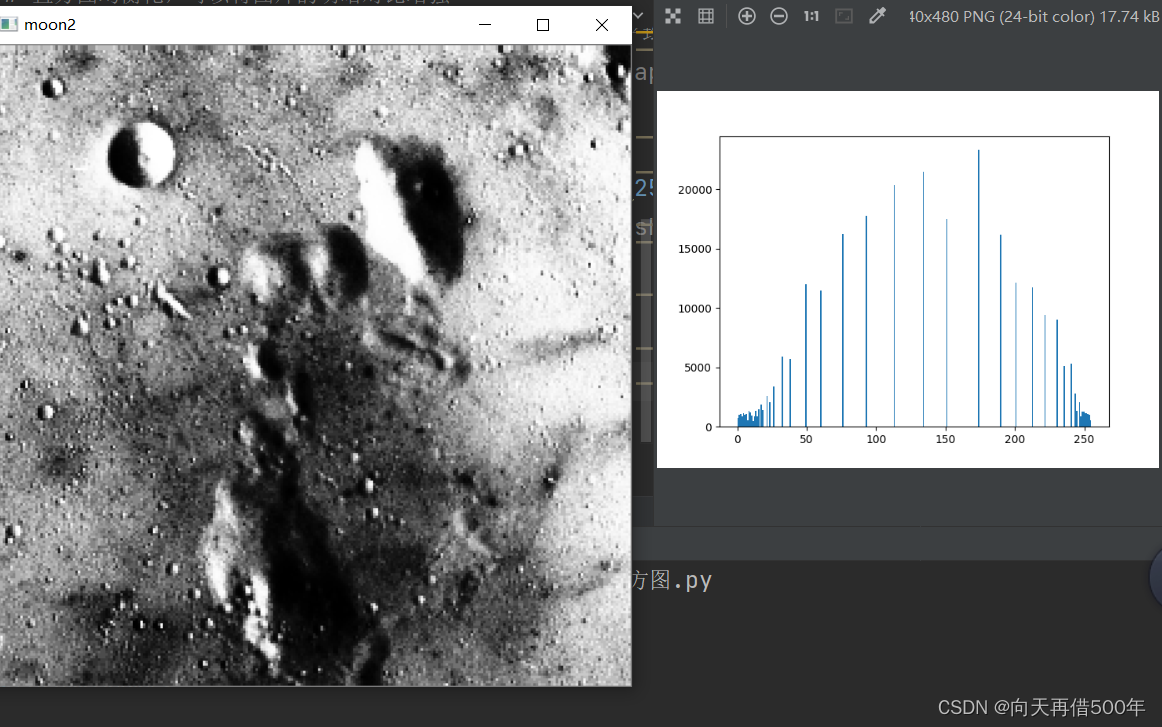
moon2 = cv2.equalizeHist(moon) # 直方图均衡化!平均一下!
plt.hist(moon2.reshape(-1),bins = 256) # reshape(-1)将数据变成一维 bins分成256份
plt.show()
hist = cv2.calcHist([moon],[0],None,[256],[0,256])
# plt.bar(x = np.arange(0,256),height=hist.reshape(-1))
# plt.show()
cv2.imshow('moon2',moon2)
cv2.waitKey(0)
cv2.destroyAllWindows()
均衡化后
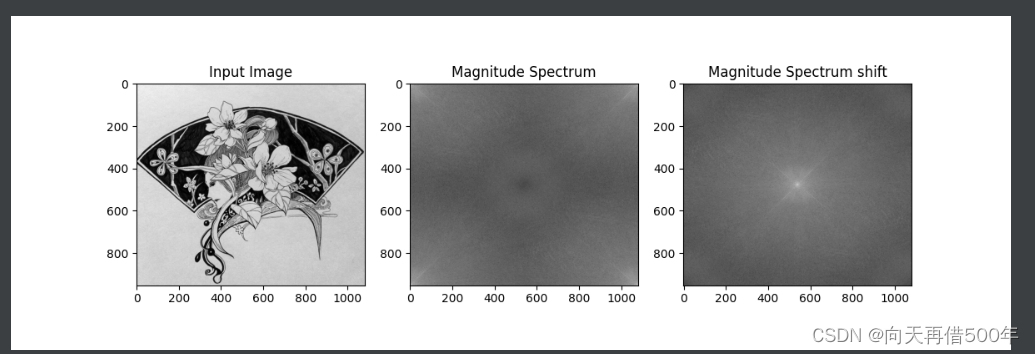
傅里叶变换
通过傅里叶变换,我们可以将图像从空间域转换到频率域,然后在频率域中对其进行滤波,主要有高通滤波和低通滤波。
概念:
高频:变化剧烈的灰度分量,例如边界
低频:变化缓慢的灰度分量
高通滤波器:只保留高频,过滤出边界
低通滤波器:只保留低频,使图像变模糊
numpy傅里叶变换
import cv2
import numpy as np
from matplotlib import pyplot as plt
if __name__ == '__main__':
img = cv2.imread('./gray.jpeg',0)
f = np.fft.fft2(img) # 时域到频域
# Shift the zero-frequency component to the center of the spectrum
# 移动0频率的数据到中心
fshift = np.fft.fftshift(f)
# print(fshift)
# # 这里构建振幅图的公式没学过
magnitude_spectrum1 = 20*np.log(np.abs(f)) # 对数运算,大幅缩小数据
magnitude_spectrum2 = 20*np.log(np.abs(fshift)) # 对数运算,大幅缩小数据
# 振幅谱图
# 131表示:1行3列第1个
plt.figure(figsize=(12,4))
plt.subplot(131),plt.imshow(img, cmap = 'gray')
plt.title('Input Image')
plt.subplot(132),plt.imshow(magnitude_spectrum1, cmap = 'gray')
plt.title('Magnitude Spectrum')
plt.subplot(133), plt.imshow(magnitude_spectrum2, cmap='gray')
plt.title('Magnitude Spectrum shift')
plt.show()
低通滤波
import numpy as np
import cv2
import matplotlib.pyplot as plt
moon = cv2.imread('./moon.png')
f = np.fft.fft2(moon) # 大部分都是0,快速傅里叶变换,时域---->频域
fshift = np.fft.fftshift(f) # 低通滤波,将低频移动到中心
# 60*60范围定义为低频波
row,col = moon.shape[0]//2,moon.shape[1]//2
fshift[row-30:row+30,col-30:col+30] = 0
f = np.fft.ifftshift(fshift)
moon2 = np.fft.ifft2(f) # 频域 ----->时域
moon2 = np.abs(moon2) # 去除虚数,保留实部
plt.subplot(121)
plt.imshow(moon,cmap='gray')
plt.subplot(122)
plt.imshow(moon2,cmap = 'gray')
plt.show()

opencv傅里叶变换
import numpy as np
import cv2
from matplotlib import pyplot as plt
# 使用灰度图像
img = cv2.imread('./moon.png',0) # 灰度化图片
# uint8转换为float32
img_float32 = np.float32(img)
# 傅里叶转换为复数
dft = cv2.dft(img_float32,flags = cv2.DFT_COMPLEX_OUTPUT)
# 将低频从左上角转换到中心
dft_shift = np.fft.fftshift(dft)
# 转换为可以显示的图片(频谱图)
magnitude_spectrum = 20*np.log(cv2.magnitude(dft_shift[:,:,0],dft_shift[:,:,1]))
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image')
plt.subplot(122),plt.imshow(magnitude_spectrum, cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()

opencv低通滤波
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 使用灰度图像
img = cv2.imread('./moon.png',0) # 灰度化图片
# uint8转换为float32
img_float32 = np.float32(img)
# 傅里叶变换,移动,将低频移动到中心
dft = cv2.dft(img_float32,flags = cv2.DFT_COMPLEX_OUTPUT) # 经过傅里叶变换的频率
# 将低频从左上角转换到中心
dft_shift = np.fft.fftshift(dft)# 移动zero-frequency component 低频波 中心
# 低通滤波:过滤高频波
h,w = img_float32.shape
h2,w2 = h//2,w//2 #中心点
mask = np.zeros((h,w,2),dtype=np.uint8)
mask[h2-50:h2+50,w2-50:w2+50] = 1
dft_shift*=mask # 中心区域15*15不变,其他(高频)变成了0,高频过滤,噪声
# 翻转
ifft_shift = np.fft.ifftshift(dft_shift)
result = cv2.idft(ifft_shift)
# 显示图片
plt.figure(figsize=(12,9))
plt.subplot(121)
plt.imshow(img_float32,cmap = 'gray')
plt.subplot(122)
plt.imshow(result[:,:,0],cmap = 'gray') # 实数
plt.show()
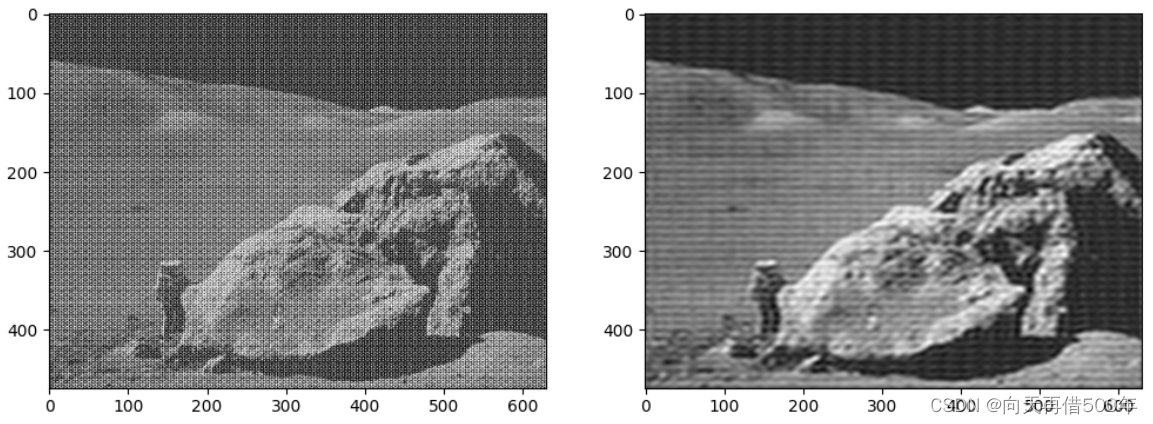
# 从频率域转换回空间域(并使用低通滤波)
def fourier_trans_back(img):
# 使用灰度图像
img = cv.cvtColor(img, cv.COLOR_RGB2GRAY)
# uint8转换为float32
img_float32 = np.float32(img)
# 傅里叶转换为复数
dft = cv.dft(img_float32, flags=cv.DFT_COMPLEX_OUTPUT)
# 将低频从左上角转换到中心
dft_shift = np.fft.fftshift(dft)
# 在这里进行低通滤波
rows, cols = img.shape
c_row, c_col = int(rows / 2), int(cols / 2)
mask_low = np.zeros_like(dft_shift, np.uint8)
mask_low[c_row - 30:c_row + 30, c_col - 50:c_col + 50] = 1
# 使用低通滤波
fshift_low = dft_shift * mask_low
# 转换为可以显示的图片(fshift_low),fshift_low中包含实部和虚部
magnitude_spectrum_low = 20 * np.log(cv.magnitude(fshift_low[:, :, 0], fshift_low[:, :, 1]))
f_ishift_low = np.fft.ifftshift(fshift_low)
img_back_low = cv.idft(f_ishift_low)
img_back_low = cv.magnitude(img_back_low[:, :, 0], img_back_low[:, :, 1])
# 使用plt低通滤波后的图像
plt.subplot(121)
plt.imshow(img_back_low, cmap='gray')
plt.title('Output Image')
plt.xticks([])
plt.yticks([])
# 展示低通滤波后的频谱图
plt.subplot(122)
plt.imshow(magnitude_spectrum_low, cmap='gray')
plt.title('magnitude_spectrum')
plt.xticks([])
plt.yticks([])
plt.show()
opencv高通滤波
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 使用灰度图像
img = cv2.imread('./moon.png',0) # 灰度化图片
# uint8转换为float32
img_float32 = np.float32(img)
# 傅里叶变换,移动,将低频移动到中心
dft = cv2.dft(img_float32,flags = cv2.DFT_COMPLEX_OUTPUT) # 经过傅里叶变换的频率
# 将低频从左上角转换到中心
dft_shift = np.fft.fftshift(dft)# 移动zero-frequency component 低频波 中心
# 高通滤波:过滤低频波(细节),保留高频波('噪声',突兀,变化明显的地方)
h,w = img_float32.shape
h2,w2 = h//2,w//2
dft_shift[h2-15:h2+15,w2-15:w2+15] = 0
# 翻转
ifft_shift = np.fft.ifftshift(dft_shift)
result = cv2.idft(ifft_shift)
# 显示图片
plt.figure(figsize=(12,9))
plt.subplot(121)
plt.imshow(img_float32,cmap = 'gray')
plt.subplot(122)
plt.imshow(result[:,:,0],cmap = 'gray') # 实数
plt.show()
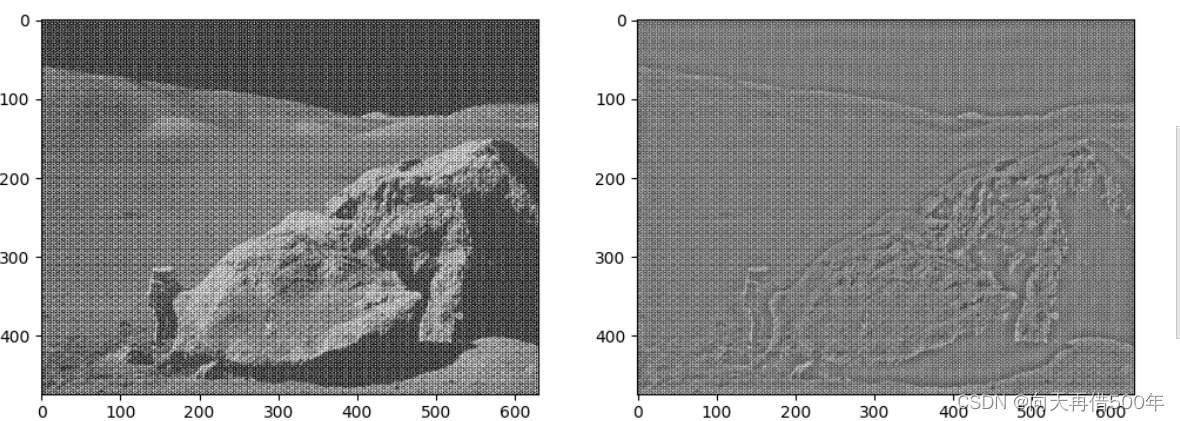
# 从频率域转换回空间域(并使用高通滤波)
def fourier_trans_back(img):
# 使用灰度图像
img = cv.cvtColor(img, cv.COLOR_RGB2GRAY)
# uint8转换为float32
img_float32 = np.float32(img)
# 傅里叶转换为复数
dft = cv.dft(img_float32, flags=cv.DFT_COMPLEX_OUTPUT)
# 将低频从左上角转换到中心
dft_shift = np.fft.fftshift(dft)
# 在这里进行高通滤波
rows, cols = img.shape
c_row, c_col = int(rows / 2), int(cols / 2)
mask_high = np.ones_like(dft_shift, np.uint8)
mask_high[c_row - 30:c_row + 30, c_col - 50:c_col + 50] = 0
# 使用高通滤波
fshift_high = dft_shift * mask_high
# 转换为可以显示的图片(fshift_high),fshift_high中包含实部和虚部
magnitude_spectrum_high = 20 * np.log(cv.magnitude(fshift_high[:, :, 0], fshift_high[:, :, 1]))
f_ishift_high = np.fft.ifftshift(fshift_high)
img_back_high = cv.idft(f_ishift_high)
img_back_high = cv.magnitude(img_back_high[:, :, 0], img_back_high[:, :, 1])
# 使用plt高通滤波后的图像
plt.subplot(121)
plt.imshow(img_back_high, cmap='gray')
plt.title('Output Image')
plt.xticks([])
plt.yticks([])
# 展示高通滤波后的频谱图
plt.subplot(122)
plt.imshow(magnitude_spectrum_high, cmap='gray')
plt.title('magnitude_spectrum')
plt.xticks([])
plt.yticks([])
plt.show()
视频中的人脸检测
import cv2
import numpy as np
if __name__ == '__main__':
video = cv2.VideoCapture('./video/v.mp4') # 读取文件,视频,视频流,占内存
face_detector = cv2.CascadeClassifier('./haarcascade_frontalface_alt.xml')
while True:
retval, image = video.read() # retval boolean表明是否获得了图片,True
if retval == False: # 取了最后一张,再读取,没有了
print('视频读取完成,没有图片!')
break
image = cv2.resize(image, (640, 360)) #因为原视频宽和高都很大,找人脸就很慢,播放出来就很卡,所有宽和高都缩小为原来一半
gray = cv2.cvtColor(image, code=cv2.COLOR_BGR2GRAY)
faces = face_detector.detectMultiScale(gray) # 耗时操作!扫描整张图片
for x,y,w,h in faces:
cv2.rectangle(image,pt1=(x,y),pt2=(x+w,y+h),color=[0,0,255],thickness=2)
cv2.imshow('ttnk',image)
key = cv2.waitKey(1) # 等待键盘ascii 1毫秒
if key == ord('q'):
print('用户键盘输入了q,死循环退出,不在显示图片')
break
# print(image.shape)
cv2.destroyAllWindows()
video.release() # 释放内存
由于视频不好上传我就上传几个图片

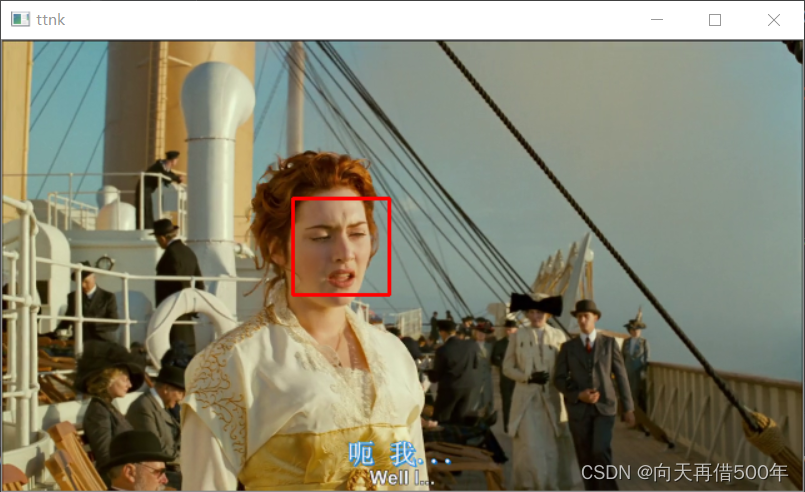
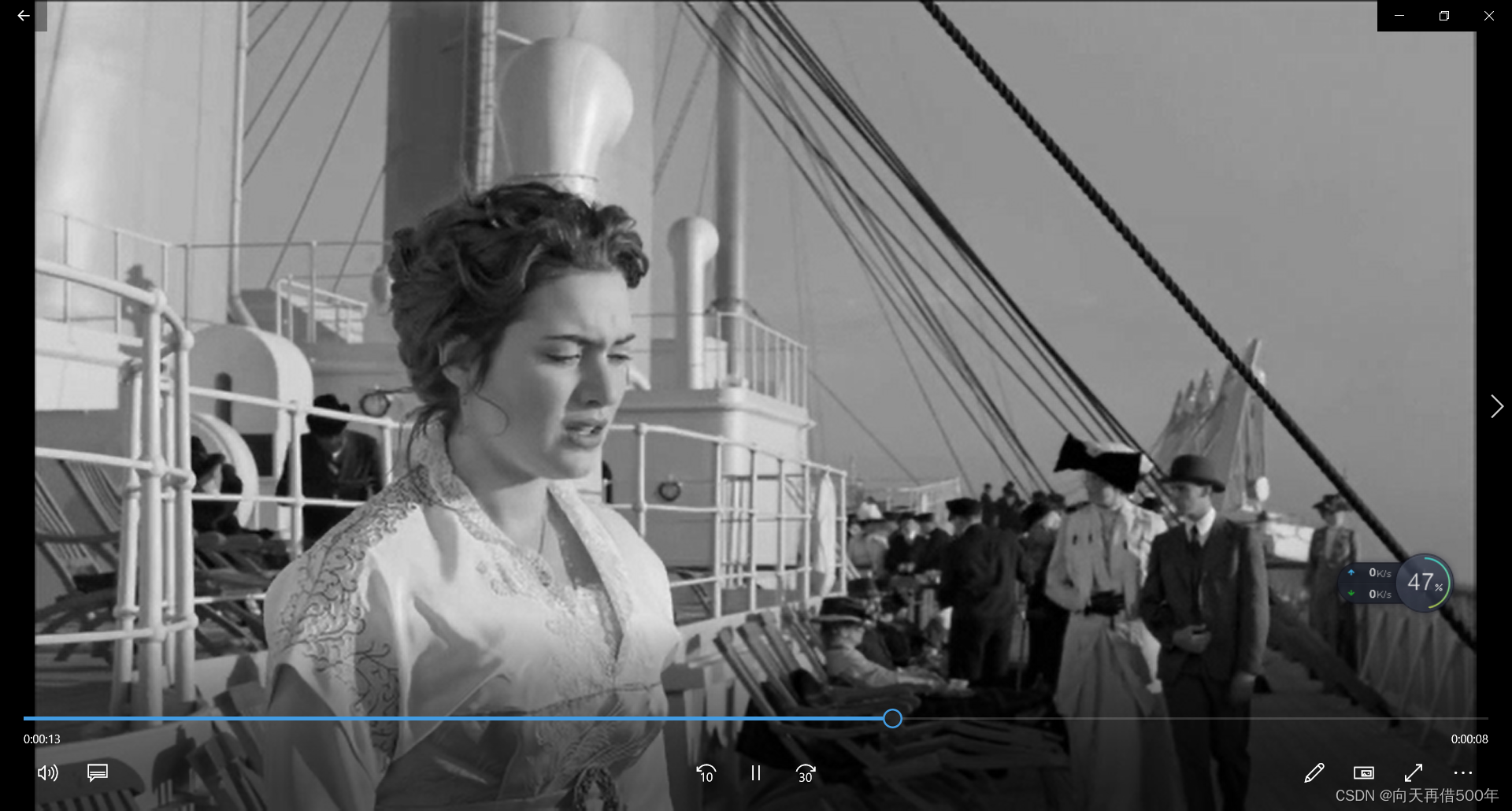
视频中人脸马赛克
import cv2
import numpy as np
if __name__ == '__main__':
video = cv2.VideoCapture('./video/v.mp4') # 读取文件,视频,视频流,占内存
# 视频 由一张图片组成的 顺序进行播放 频率 24帧
# 肉眼,反应不过来,视频(图片一张显示)
fps = video.get(propId=cv2.CAP_PROP_FPS) # 视频帧率 24
width = video.get(propId=cv2.CAP_PROP_FRAME_WIDTH)
height = video.get(propId=cv2.CAP_PROP_FRAME_HEIGHT)
count = video.get(propId=cv2.CAP_PROP_FRAME_COUNT)
print('----视频帧率:',fps)
print(width,height,count)
face_detector = cv2.CascadeClassifier('./haarcascade_frontalface_alt.xml')
while True:
retval, image = video.read() # retval boolean表明是否获得了图片,True
if retval == False: # 取了最后一张,再读取,没有了
print('视频读取完成,没有图片!')
break
image = cv2.resize(image, (640, 360))
gray = cv2.cvtColor(image, code=cv2.COLOR_BGR2GRAY)
faces = face_detector.detectMultiScale(gray) # 耗时操作!扫描整张图片
for x,y,w,h in faces:
face = image[y:y+h,x:x+w]
face = face[::10,::10]
face = np.repeat(np.repeat(face,10,axis = 0),10,axis = 1)
image[y:y+h,x:x+w] = face[:h,:w]
cv2.imshow('ttnk',image)
key = cv2.waitKey(1) # 等待键盘ascii 1毫秒
if key == ord('q'):
print('用户键盘输入了q,死循环退出,不在显示图片')
break
cv2.destroyAllWindows()
video.release() # 释放内存


将视频保存成黑白视频
import cv2
import numpy as np
if __name__ == '__main__':
video = cv2.VideoCapture('./video/v.mp4') # 读取文件,视频,视频流,占内存
writer = cv2.VideoWriter(filename = './video/gray.mp4',
# fourcc = cv2.VideoWriter.fourcc(*'MP4V') , # 视频编码
fourcc = cv2.VideoWriter.fourcc(*'MP42') , # 视频编码
fps = 24, # frame per second每秒多少帧
frameSize = (640,360)) # 图片尺寸
face_detector = cv2.CascadeClassifier('./haarcascade_frontalface_alt.xml')
while True:
retval, image = video.read() # retval boolean表明是否获得了图片,True
if retval == False: # 取了最后一张,再读取,没有了
print('视频读取完成,没有图片!')
break
image = cv2.resize(image, (640, 360))
gray = cv2.cvtColor(image, code=cv2.COLOR_BGR2GRAY) # 黑白,二维
gray2 = np.repeat(gray.reshape(360,640,1),3,axis = 2) #变成三位 蓝绿红(值一样,没有波动,黑白)
writer.write(gray2)
faces = face_detector.detectMultiScale(gray) # 耗时操作!扫描整张图片
for x,y,w,h in faces:
face = image[y:y+h,x:x+w]
face = face[::10,::10]
face = np.repeat(np.repeat(face,10,axis = 0),10,axis = 1)
image[y:y+h,x:x+w] = face[:h,:w]
# writer.write(image) # 写入马赛克的图片,彩色的图片,3维
cv2.imshow('ttnk',image)
key = cv2.waitKey(1) # 等待键盘ascii 1毫秒
if key == ord('q'):
print('用户键盘输入了q,死循环退出,不在显示图片')
break
cv2.destroyAllWindows()
video.release() # 释放内存
writer.release() # 释放内存
音频配置
安装pydub
pip install pydub
基本代码
import pydub
if __name__ == '__main__':
mp3 = pydub.AudioSegment.from_mp3('./video/style.mp3')
audio2 = mp3[:21*1000] # 切片操作,获取音乐汇总21秒
audio2 +=30 # 声音变大 增加了30分贝
audio2.export('./video/3.mp3') # 写入文件
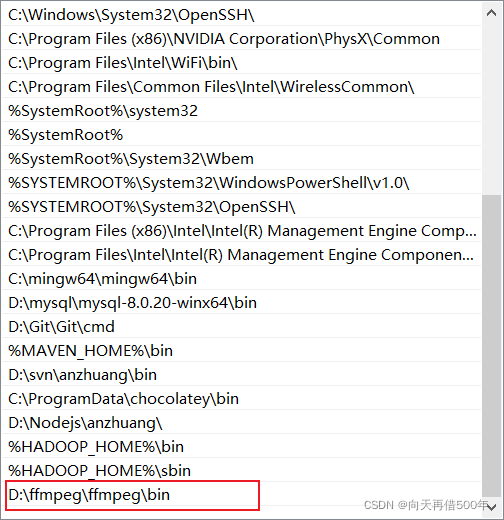
直接运行会报错

需要到网上下载ffmpeg,解压后配置环境变量
音频和视频合并
import subprocess
if __name__ == '__main__':
# 将视频和音频进行合并
# ffmpeg 音视频处理的库,c语言写的
cmd = 'ffmpeg -i ./video/gray.mp4 -i ./video/3.mp3 ./video/out.mp4'
c = subprocess.call(cmd)
print('-------------',c) #0代表成功
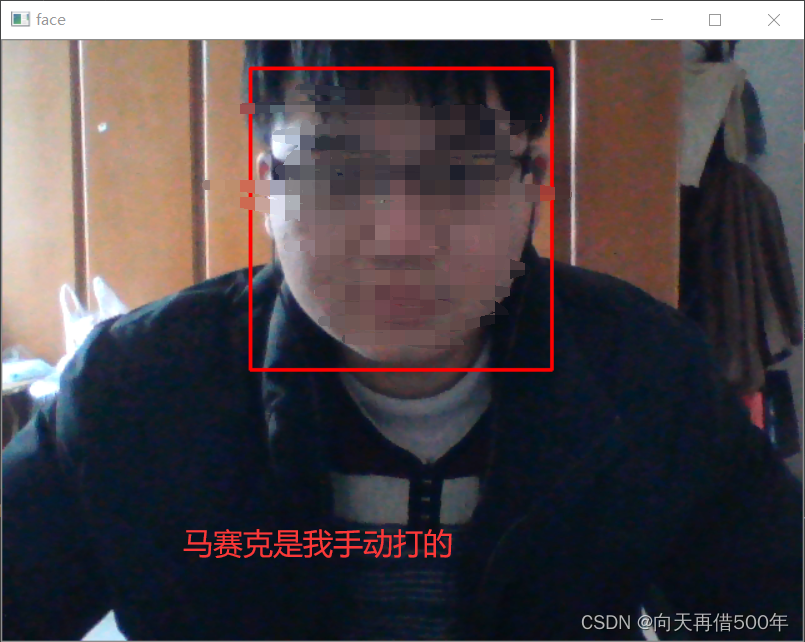
本地摄像头人脸检测
import numpy as np
import cv2
if __name__ == '__main__':
# 给视频路径,打开视频
cap = cv2.VideoCapture(0) # 打开本机的摄像头
face_detector = cv2.CascadeClassifier('./haarcascade_frontalface_alt.xml')
head = cv2.imread('./images/head.jpg')
while True:
flag,frame = cap.read() # flag是否读取了图片
if not flag:
break
gray = cv2.cvtColor(frame, code=cv2.COLOR_BGR2GRAY)
faces = face_detector.detectMultiScale(gray,scaleFactor=1.1,minNeighbors=10)
for x,y,w,h in faces:
cv2.rectangle(frame,
pt1 = (x,y),
pt2=(x+w,y+h),
color=[0,0,255],thickness=2)
cv2.imshow('face',frame)
key = cv2.waitKey(1000//24) # 注意是整除//,时间是毫秒,最小1毫秒,必须是整数
if key == ord('q'): # 键盘输入q退出
break
cv2.destroyAllWindows()
cap.release()
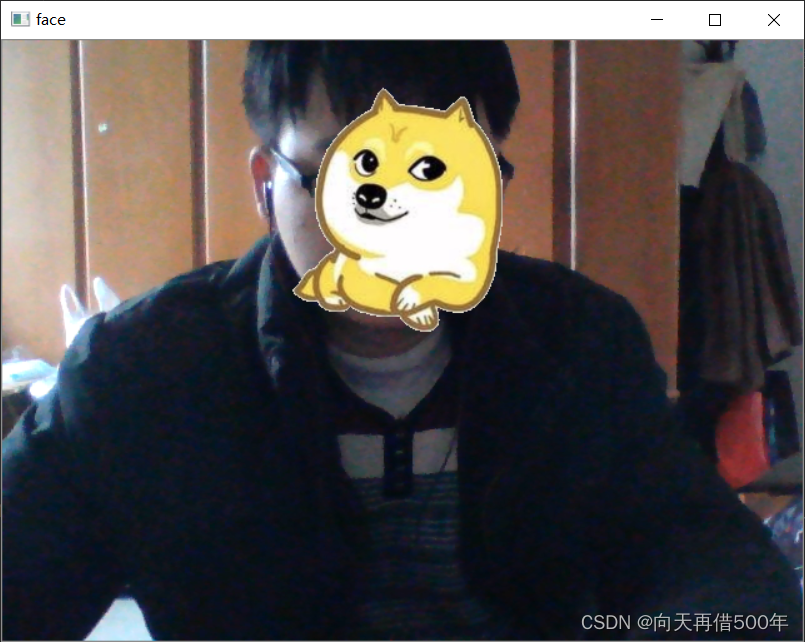
本地摄像头人脸贴纸画
import numpy as np
import cv2
if __name__ == '__main__':
# 给视频路径,打开视频
cap = cv2.VideoCapture(0) # 打开本机的摄像头
face_detector = cv2.CascadeClassifier('./haarcascade_frontalface_alt.xml')
head = cv2.imread('./images/head.jpg')
while True:
flag,frame = cap.read() # flag是否读取了图片
if not flag:
break
gray = cv2.cvtColor(frame, code=cv2.COLOR_BGR2GRAY)
faces = face_detector.detectMultiScale(gray,scaleFactor=1.1,minNeighbors=10)
for x,y,w,h in faces:
head2 = cv2.resize(head, dsize=(w, h))
frame[y:y+h,x:x+w] = head2
cv2.imshow('face',frame)
key = cv2.waitKey(1000//24) # 注意是整除//,时间是毫秒,最小1毫秒,必须是整数
if key == ord('q'): # 键盘输入q退出
break
cv2.destroyAllWindows()
cap.release()
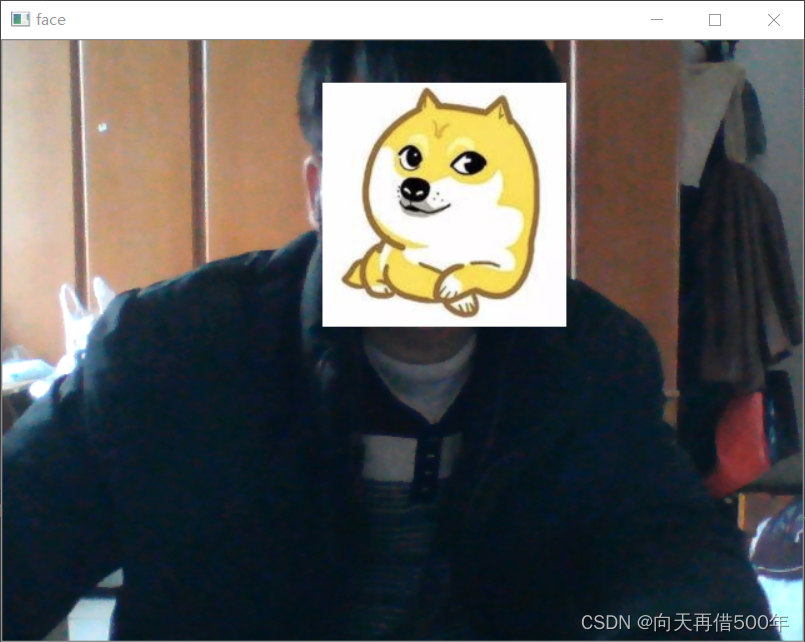
去除白边版
import numpy as np
import cv2
if __name__ == '__main__':
# 给视频路径,打开视频
cap = cv2.VideoCapture(0) # 打开本机的摄像头
face_detector = cv2.CascadeClassifier('./haarcascade_frontalface_alt.xml')
head = cv2.imread('./head.jpg')
while True:
flag,frame = cap.read() # flag是否读取了图片
if not flag:
break
gray = cv2.cvtColor(frame, code=cv2.COLOR_BGR2GRAY)
faces = face_detector.detectMultiScale(gray,scaleFactor=1.1,minNeighbors=10)
for x,y,w,h in faces:
head2 = cv2.resize(head, dsize=(w, h))
head2_gray = cv2.cvtColor(head2, code=cv2.COLOR_BGR2GRAY)
threshold ,otsu = cv2.threshold(head2_gray, 100, 255, cv2.THRESH_OTSU)
contours, hierarchy = cv2.findContours(otsu,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
areas = []
for c in contours:
areas.append(cv2.contourArea(c))
areas = np.asarray(areas)
index = areas.argsort()
mask = np.zeros(shape = [h,w],dtype=np.uint8)
cv2.drawContours(mask,contours,index[-2],(255),thickness=-1)
for i in range(h):
for j in range(w):
if mask[i,j] == 255: # !!!
frame[i+y,j+x]=head2[i,j]
cv2.imshow('face',frame)
key = cv2.waitKey(1000//24) # 注意是整除//,时间是毫秒,最小1毫秒,必须是整数
if key == ord('q'): # 键盘输入q退出
break
cv2.destroyAllWindows()
cap.release()
opencv形态学操作
opencv腐蚀膨胀
腐蚀和膨胀是针对白色部分(高亮部分)而言的。
膨胀就是对图像高亮部分进行“领域扩张”,效果图拥有比原图更大的高亮区域;腐蚀是原图中的高亮区域被蚕食,效果图拥有比原图更小的高亮区域。
膨胀就是求局部最大值的操作,从图像直观看来,就是将图像光亮部分放大,黑暗部分缩小。
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread('./images/img.jpg',flags=cv2.IMREAD_GRAYSCALE)
img = (img - 255)*255 #因为这张图是背景是白的,文字是黑的所以需要反转过来让文字变成白色背景变成黑色
kernel = np.ones(shape = [3,3],dtype=np.uint8)
# 腐蚀,由多变少,越是边界上,越容易被腐蚀,去除噪声,图像变小,变细
img2 = cv2.erode(img, kernel=kernel, iterations=1)
# 膨胀,图像变粗,变大
img3 = cv2.dilate(img2, kernel, iterations=1)
cv2.imshow('raw',img) # 原图
cv2.imshow('erode',img2) # 腐蚀
cv2.imshow('dilate',img3) # 膨胀,还原(噪声去掉还原)
cv2.waitKey(0)
cv2.destroyAllWindows()

iterations:膨胀操作的次数,默认为一次
开运算
先进性腐蚀再进行膨胀就叫做开运算。就像我们上面介绍的那样,它被用来去除噪声。这里我们用到的函数是 cv2.morphologyEx()。
import cv2
import numpy as np
if __name__ == '__main__':
# 开运算:先进行腐蚀然后进行膨胀
img = cv2.imread('./images/img2.jpg', flags=cv2.IMREAD_GRAYSCALE)
result = cv2.morphologyEx(img,
op = cv2.MORPH_OPEN,
kernel=np.ones(shape = [10,10],dtype=np.uint8),
iterations=1)
cv2.imshow('raw',img)
cv2.imshow('morpholoyEx',result)
cv2.waitKey(0)
cv2.destroyAllWindows()

闭运算
先膨胀再腐蚀。它经常被用来填充前景物体中的小洞,或者前景物体上的小黑点。
import numpy as np
import cv2
if __name__ == '__main__':
img = cv2.imread('./images/img4.jpg',flags=cv2.IMREAD_GRAYSCALE)
result = cv2.morphologyEx(img,
op =cv2.MORPH_CLOSE,
kernel = np.ones(shape = [8,8],dtype=np.uint8),
iterations=1)
cv2.imshow('raw',img)
cv2.imshow('close',result)
cv2.waitKey(0)
cv2.destroyAllWindows()

礼帽
原始图像与进行开运算之后得到的图像的差
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread('./images/img5.jpg', flags=cv2.IMREAD_GRAYSCALE)
result = cv2.morphologyEx(img,
op = cv2.MORPH_TOPHAT,
kernel=np.ones(shape = [20,20],dtype=np.uint8),
iterations=1)
cv2.imshow('raw',img)
cv2.imshow('gradient',result)
cv2.waitKey(0)
cv2.destroyAllWindows()
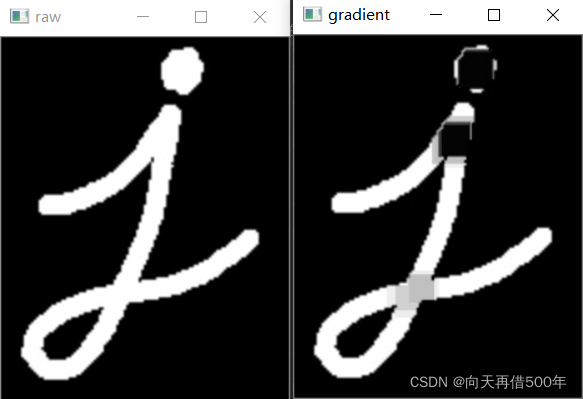
黑帽
进行闭运算之后得到的图像与原始图像的差
tophat = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)
梯度
其实就是一幅图像膨胀与腐蚀的差别
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread('./images/img5.jpg', flags=cv2.IMREAD_GRAYSCALE)
result = cv2.morphologyEx(img,
op = cv2.MORPH_GRADIENT,
kernel=np.ones(shape = [5,5],dtype=np.uint8),
iterations=1)
cv2.imshow('raw',img)
cv2.imshow('gradient',result)
cv2.waitKey(0)
cv2.destroyAllWindows()
