文章目录
前言
提示:本人不喜欢用专业术语来记录知识点,所以接下来会用例题+白话文的方式记录:
选择排序的主要思想是每一趟从待排序列中选取一个关键字值最小的记录,也即第 1 趟从 n 个记录中选取关键字值最小的记录,在第 2 趟中,从剩下的 n-1 个记录中选取关键字值最小的记录,直到整个序列中的记录都选完位置。这样,由选取记录的顺序便可得到按关键字值有序的序列。
提示:以下是本篇文章正文内容,下面案例可供参考
三、选择排序
1、直接选择排序
思想:
首先在所有记录中选出关键字值最小的记录,把它与第一个记录进行位置交换,然后在其余的记录中再选出关键字值次小的记录与第二个记录进行位置交换,依此类推,直到所有记录排好序。
- 此处引用网上一张比较经典的gif来展示直接选择排序的整个过程:
例题:
假设待排序的 8 个记录的关键字序列为 { 5,3,6,4,7,1,8,2} 排序过程如下图所示
红颜色为已排好序的数字,考试时一般用【中括号】代替
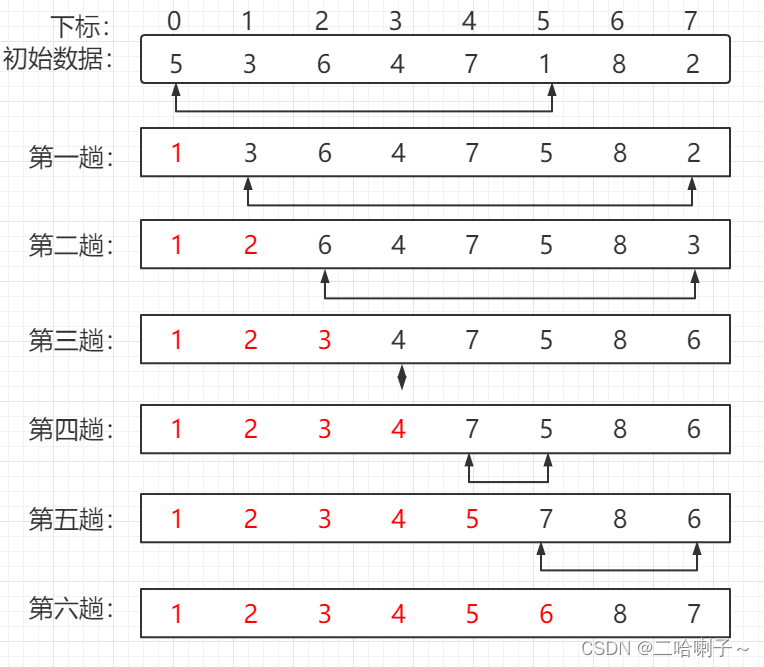
初始序列就把它看成无序序列
然后从无序序列中选择最小的跟这无序序列中第一个数交换,构成有序序列
第二趟也是从无序序列中选择最小的跟无序序列中第一个数交换
下面每一趟以此类推
每趟序列遍历完后,有序序列记录的个数 + 1,无序序列的个数 - 1,
代码部分:
public void selectSort(){
RecordNode temp; //定义一个零时变量temp
for(int i=0; i<this.curlen-1;i++) //进行i-1次遍历,this.curlen:数组的长度
{
int min=i;
for(int j=i+1;j<this.curlen; j++) //找到一个最小的
if (r[j].key.compareTo(r[min].key)<0)
min=j;
if (min!=i)
{
temp=r[i]; //以下是交换代码
r[i]=r[min];
r[min]=temp;}
}
}
性能分析
⑴、时间复杂度为:
O(n2)
⑵、所需辅助空间:
O(1)
⑶ 、算法稳定性:
是不稳定排序
2、树形选择排序
思想:
- 此处引用网上一张比较经典图来展示树形选择排序的整个过程:

先对 n 个记录进行俩俩比较,比较的结果是把关键字值较小者作为优胜者上升到父结点,得到比较的优胜者(关键字值较小者),作为第一步比较的结果保留下来;然后对这个记录再进行关键字的两两比较,如此重复,直到选出一个关键字值最小的记录为止。
这个过程可用一个含有n个叶子结点的完全二叉树来表示
例题一:
(1)
对于由8个关键字组成的序列 { 52,39,67,95,70,8,25,¯52¯ },使用树形选择排序选出最小关键字值的过程可用下图所示的完全二叉树来表示。
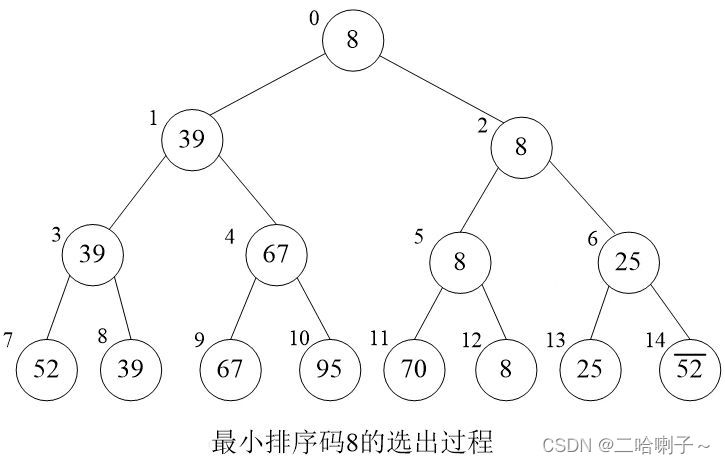
可以看到关键字都处在最后一层的叶子节点上
怎么选呢?俩俩 PK ,谁小谁上去到父亲节点,52 和 39,39 上去;67 和 95,67 上去;70 和 8,8 上去;
到上一层同样也是谁小谁上去到父亲节点,最后关键字最小的在最上面
(2)
同上图例题一(1),找次小值

在例题一(1)中,最小的找到了,然后把他当做无穷大 “∞”,然后再俩俩 PK 就可以找到次小,次小的找到了再把它替换成无穷大,每次都找到这些当中最小的弄到父亲节点,以此类推,最后就排好序了
性能分析
⑴、空间复杂度
树形选择排序虽然减少了排序时间,但使用了较多的附加存储空间。
⑵、时间复杂度
树形选择排序的时间复杂度为O(nlog2n)
⑶、算法稳定性
树形选择排序是一种稳定的排序算法。
3、堆排序
定义:
堆是满足下列性质的数列{ r0、r1…rn-1 }:
对于大顶堆: ri > = r2i+ 1 && ri > = r2i+ 2
对于小顶堆: ri < = r2i+ 1 && ri < = r2i+ 2
换一种说法就是:
所有的父亲结点都大于孩子结点的叫大顶堆
所有的父亲结点都小于孩子结点的叫小顶堆
不大不小的不叫堆
- 此处引用网上一张比较经典的图来展示大小顶堆:
大顶堆中根节点的值一定是整个序列中最大的
小顶堆中根节点的值一定是整个序列中最小的
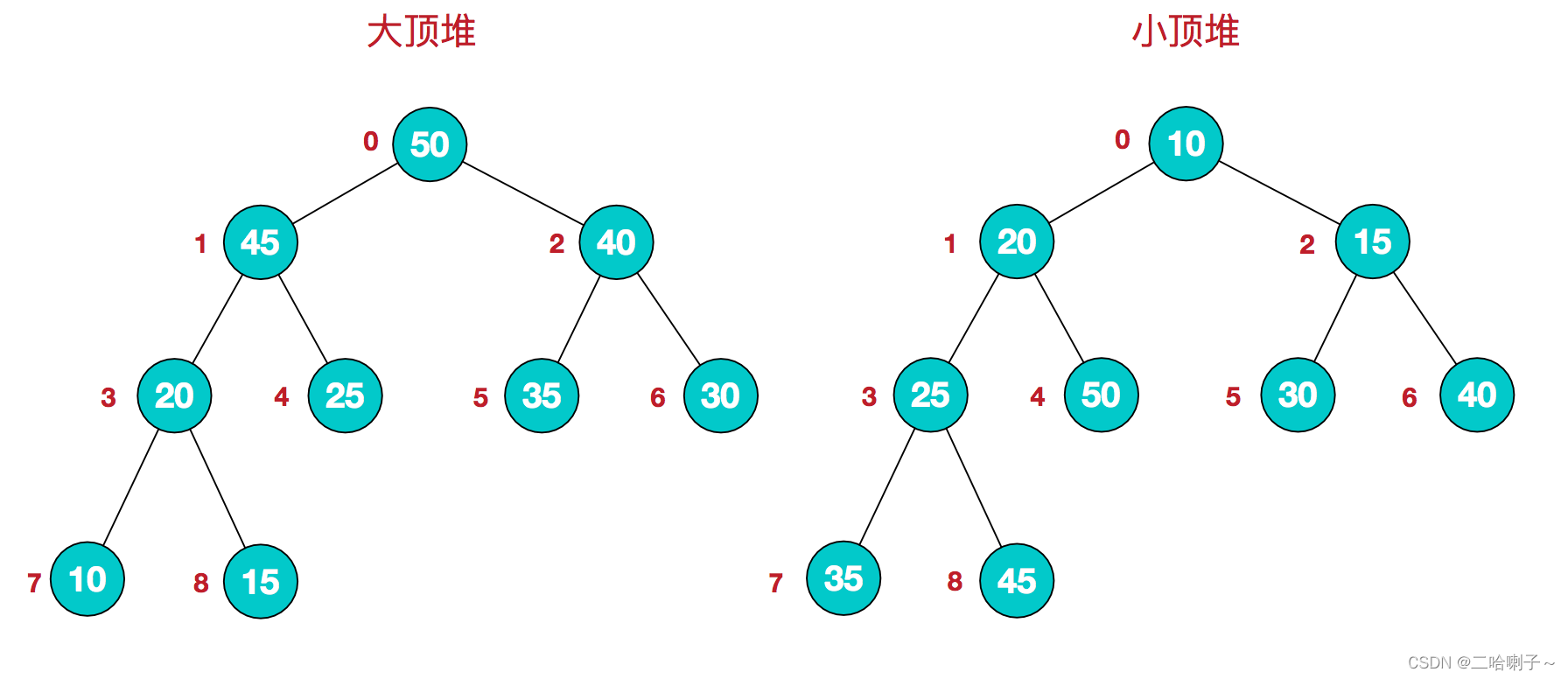
r2i+ 1 是 ri 的左孩子
r2i+ 2 是 ri 的右孩子
所以,堆的含义表明:完全二叉树中所有非终端结点(父亲结点)的值均不大于(或不小于)其左、右孩子结点的值。
- 此处引用网上一张比较经典的 gif来展示:

方法:
首先把待排序的记录序列对应成一棵完全二叉树,并把它转换成一个初始堆(即首先建初始堆)。这时,根结点具有最大(或最小)的关键字值,然后,交换根结点和最后一个结点(即第n个结点)的位置,除最后一个结点之外,前 n-1 个结点仍构成一棵完全二叉树,再把它们调整为一个堆。同样交换根结点和最后一个结点(即第 n-1 个结点)。重复进行下去,直到只剩下一个根结点为止,便得一个有序表。
如何“筛选”?
所谓 “ 筛选 ” 指的是调整的过程,对一棵左/右子树均为堆的完全二叉树,“ 调整 ” 根结点使整个二叉树也成为一个堆。
例题:
排序之前的关键字序列为
{ 40,55,49,73,12,27,98,81,64,36 }
下图中,方框内,棕色的为交换的,绿色的为不需要动的
“ 筛选 ” 是一个从上往下进行的过程。
可以看到每个父亲结点都比子节点大,所以是大顶堆
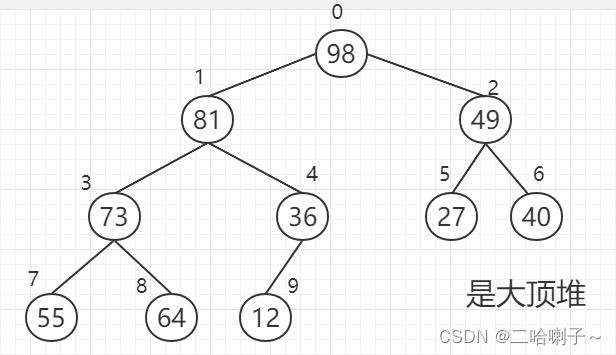
但是我们在排好序后最大值 98 应该放在最后面,下标为 9 的这个位置,但这样就需要把 12 挪上去,就是最大值需要跟最后一个结点的值进行交换
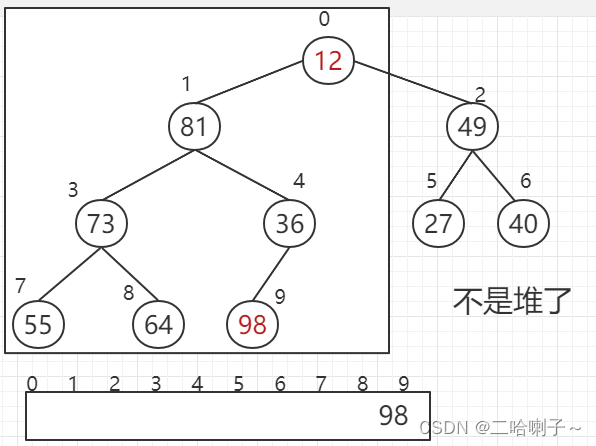
但在 98 和 12 进行互换之后,它就不是堆了,因此,需要对它进行 “ 筛选 ”,仍然把他调整成大顶堆
这时候需要从上到下筛选,但需要注意的是:因为已经找到最大值了,并且把他放在最后面,所以不需要再排最大值 98 了
先看 12、81、49,如果是大顶堆,需要把 81 放在最上面,81 和 12 交换
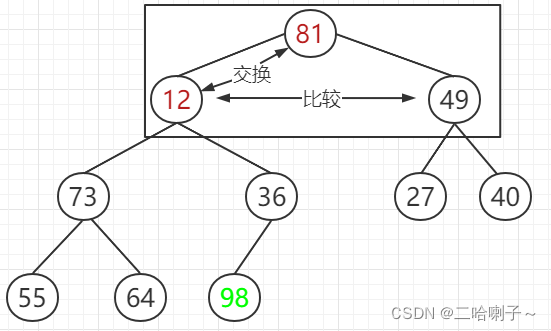
但现在还不是大顶堆,接下来 73、12、36 比较,谁大谁上去,并交换,所以 73 和 12 交换
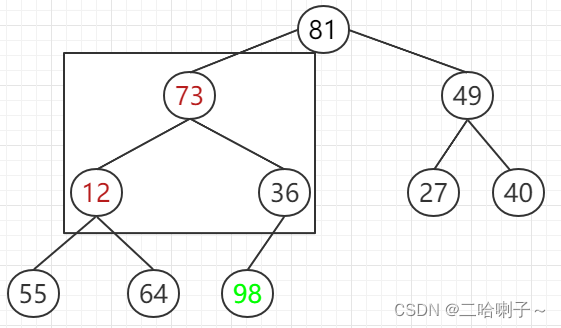
然后 55 和 64 比较,谁大谁上去
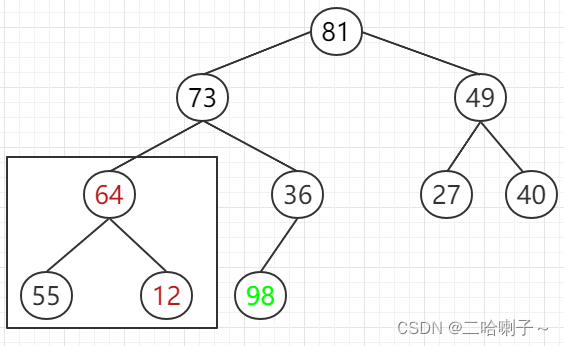
这样的话又变成大顶堆了
根结点 81 最大,和无序序列的最后一个交换,这里是 12 。。。。。以此类推,每次筛选都能找到最大的,这样就排好序了
如何“建初始堆”?
如果建一个大顶堆,最顶上的根结点一定是最大的
如果建一个小顶堆,最顶上的根结点一定是最小的
例题:
建堆是一个从下往上进行 “ 筛选 ” 的过程。
例如:排序之前的关键字序列为
{ 40,55,49,73,12,27,98,81,64,36 }

先看下标 4 和 9,36 比 12 大,36 上去,
再看左边下标 3、7、8,81 比 73、64大,81 上去,
再看右边下标 2、5、6,98 比 27、49大,98 上去,
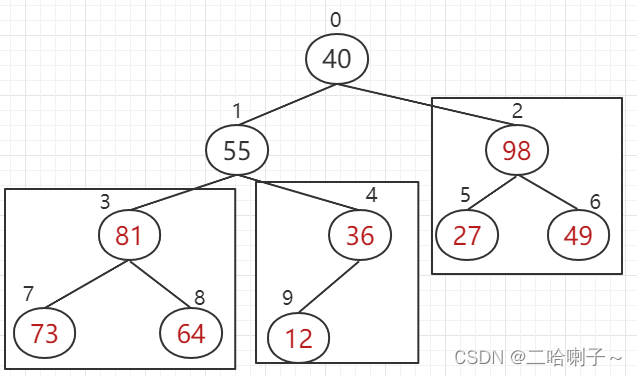
然后再来看下标 1、3、4,81 比 55、36大,81 上去,
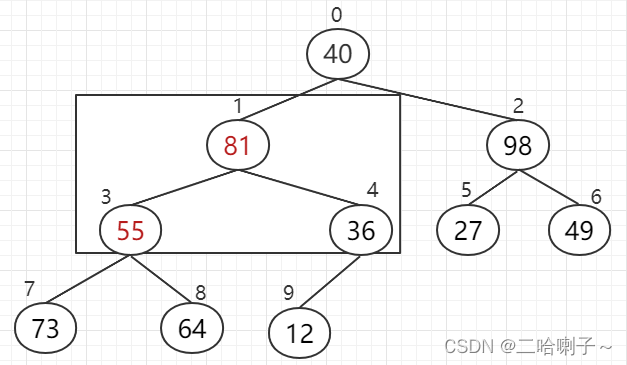
但这样我们就发现一个问题:下标 3、7、8,这三个数(55、73、64)就不能构成大顶堆了
所以三个数比较后,73上去
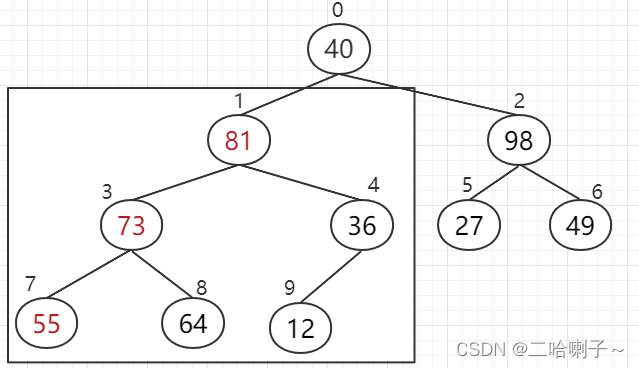
然后看下标 0、1、2,98 比 81、40大,98 上去
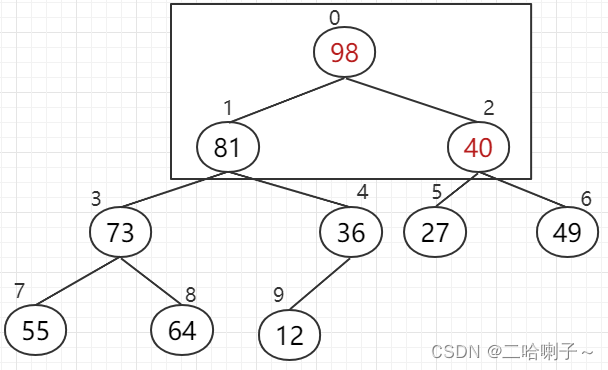
但现在下标 2、5、6,这三个数(40、27、49)就不能构成大顶堆了
所以三个数比较后,49上去
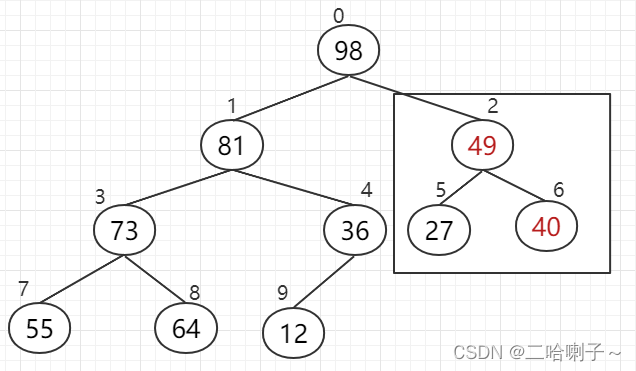
现在,左/右子树都已经调整为堆,最后只要调整根结点,使整个二叉树是个 “ 堆 ” 即可。
这个就是建堆的过程,从下往上筛选(按照编号最大,并且有孩子的,此题中从 4 开始调整,然后 3、2、1),调整的过程中注意有可能打破子树上的堆,需要继续调。
代码部分
public class HeapSort {
public static void heapSort(int[] arr) {
if (arr == null || arr.length == 0) {
return;
}
int len = arr.length;
// 构建大顶堆,这里其实就是把待排序序列,变成一个大顶堆结构的数组
buildMaxHeap(arr, len);
// 交换堆顶和当前末尾的节点,重置大顶堆
for (int i = len - 1; i > 0; i--) {
swap(arr, 0, i);
len--;
heapify(arr, 0, len);
}
}
private static void buildMaxHeap(int[] arr, int len) {
// 从最后一个非叶节点开始向前遍历,调整节点性质,使之成为大顶堆
for (int i = (int)Math.floor(len / 2) - 1; i >= 0; i--) {
heapify(arr, i, len);
}
}
private static void heapify(int[] arr, int i, int len) {
// 先根据堆性质,找出它左右节点的索引
int left = 2 * i + 1;
int right = 2 * i + 2;
// 默认当前节点(父节点)是最大值。
int largestIndex = i;
if (left < len && arr[left] > arr[largestIndex]) {
// 如果有左节点,并且左节点的值更大,更新最大值的索引
largestIndex = left;
}
if (right < len && arr[right] > arr[largestIndex]) {
// 如果有右节点,并且右节点的值更大,更新最大值的索引
largestIndex = right;
}
if (largestIndex != i) {
// 如果最大值不是当前非叶子节点的值,那么就把当前节点和最大值的子节点值互换
swap(arr, i, largestIndex);
// 因为互换之后,子节点的值变了,如果该子节点也有自己的子节点,仍需要再次调整。
heapify(arr, largestIndex, len);
}
}
private static void swap (int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
性能分析
(1)、时间复杂度:
O(nlog2n)
(2)、所需辅助空间:
O(1)
(3)、算法稳定性:
是不稳定的排序方法
总结
直接选择排序
首先在所有记录中选出关键字值最小的记录,把它与第一个记录进行位置交换,然后在其余的记录中再选出关键字值次小的记录与第二个记录进行位置交换,依此类推,直到所有记录排好序。
树形排序
先对 n 个记录进行俩俩比较,比较的结果是把关键字值较小者作为优胜者上升到父结点,得到比较的优胜者(关键字值较小者),作为第一步比较的结果保留下来;然后对这个记录再进行关键字的两两比较,如此重复,直到选出一个关键字值最小的记录为止。
堆排序
如果想要排升序,就应该建立大堆;
如果想要排降序;就应该建立小堆
筛选就是被破坏后比较、交换。谁大谁上去,从上到下的顺序
建堆是一个从下往上进行 “ 筛选 ” 的过程。