数据结构与算法之美(排序)
几种基本排序及其时间复杂度
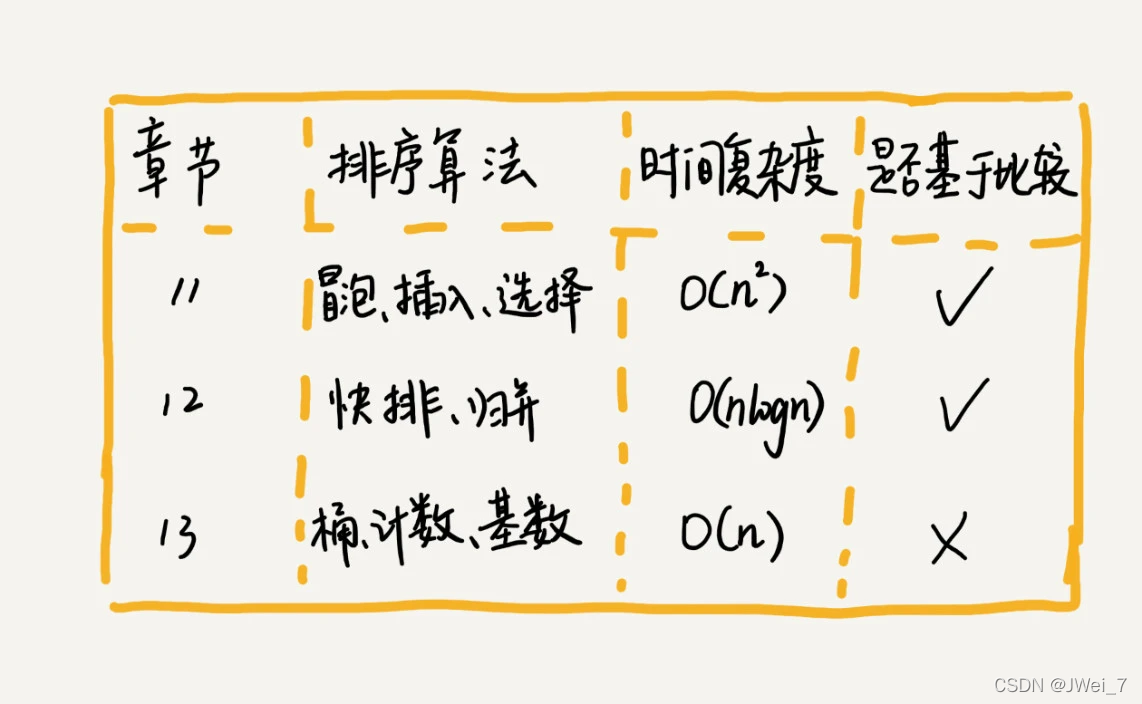
几种最经典、最常用的排序方法 :冒泡排序、插入排序、选择排序、快速排序、归并排序、计数排序、基数排序、桶排序。
二、如何分析一个排序算法?
如何分析排序算法性能?从执行效率、内存消耗以及稳定性3个方面分析排序算法的性能。
1.执行效率(从以下3个方面来衡量)
1)最好情况、最坏情况、平均情况时间复杂度
2)时间复杂度的系数、常数、低阶:排序的数据量比较小时考虑
3)比较次数和交换(或移动)次数
2.内存消耗
算法的内存消耗可以通过空间复杂度来衡量,排序算法也不例外。不过,针对排序算法的空间复杂度,我们还引入了一个新的概念,原地排序(Sorted in place)。原地排序算法,就是特指空间复杂度是O(1)的排序算法。我们今天讲的三种排序算法,都是原地排序算法。
3.稳定性
仅仅用执行效率和内存消耗来衡量排序算法的好坏是不够的。针对排序算法,我们还有一个重要的度量指标,稳定性。这个概念是说,如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。
我通过一个例子来解释一下。比如我们有一组数据2,9,3,4,8,3,按照大小排序之后就是2,3,3,4,8,9。
这组数据里有两个3。经过某种排序算法排序之后,如果两个3的前后顺序没有改变,那我们就把这种排序算法叫作稳定的排序算法; 如果前后顺序发生变化,那对应的排序算法就叫作不稳定的排序算法。
三、排序算法
1.冒泡排序
1)执行效率:最小时间复杂度、最大时间复杂度、平均时间复杂度
排序原理
1)冒泡排序只会操作相邻的两个数据。
2)对相邻两个数据进行比较,看是否满足大小关系要求,若不满足让它俩互换。
3)一次冒泡会让至少一个元素移动到它应该在的位置,重复n次,就完成了n个数据的排序工作。
4)优化:若某次冒泡不存在数据交换,则说明已经达到完全有序,所以终止冒泡。
性能分析
执行效率:最小时间复杂度、最大时间复杂度、平均时间复杂度
最小时间复杂度:数据完全有序时,只需进行一次冒泡操作即可,时间复杂度是O(n)。
最大时间复杂度:数据倒序排序时,需要n次冒泡操作,时间复杂度是O(n^2)。
平均时间复杂度:通过有序度和逆序度来分析。

有序度是数组中具有有序关系的元素对的个数
比如[2,4,3,1,5,6]这组数据的有序度就是11,分别是[2,4][2,3][2,5][2,6][4,5][4,6][3,5][3,6][1,5][1,6][5,6]。同理,对于一个倒序数组,比如[6,5,4,3,2,1],有序度是0;对于一个完全有序的数组,比如[1,2,3,4,5,6],有序度为n*(n-1)/2,也就是15,完全有序的情况称为满有序度。
什么是逆序度?逆序度的定义正好和有序度相反。核心公式:逆序度=满有序度-有序度。
排序过程,就是有序度增加,逆序度减少的过程,最后达到满有序度,就说明排序完成了。
2)空间复杂度
每次交换仅需1个临时变量,故空间复杂度为O(1),是原地排序算法。
3)算法稳定性
如果两个值相等,就不会交换位置,故是稳定排序算法。
2.插入排序
算法原理
首先,我们将数组中的数据分为2个区间,即已排序区间和未排序区间。初始已排序区间只有一个元素,就是数组的第一个元素。插入算法的核心思想就是取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间中的元素一直有序。重复这个过程,直到未排序中元素为空,算法结束。
性能分析
1)时间复杂度:最好、最坏、平均情况
如果要排序的数组已经是有序的,我们并不需要搬移任何数据。只需要遍历一遍数组即可,所以时间复杂度是O(n)。
如果数组是倒序的,每次插入都相当于在数组的第一个位置插入新的数据,所以需要移动大量的数据,因此时间复杂度是O(n^2)。
而在一个数组中插入一个元素的平均时间复杂都是O(n),插入排序需要n次插入,所以平均时间复杂度是O(n^2)。
2)空间复杂度
从上面的代码可以看出,插入排序算法的运行并不需要额外的存储空间,所以空间复杂度是O(1),是原地排序算法。
3)算法稳定性
在插入排序中,对于值相同的元素,我们可以选择将后面出现的元素,插入到前面出现的元素的后面,这样就保持原有的顺序不变,所以是稳定的。
3.归并排序
待添加 … …
推荐题目(力扣)
912. 排序数组( 补充题4. 手撕快速排序)
https://leetcode-cn.com/problems/sort-an-array/
给你一个整数数组 nums,请你将该数组升序排列。
示例 1:
输入:
nums = [5,2,3,1]
输出:
[1,2,3,5]
示例 2:
输入:
nums = [5,1,1,2,0,0]
输出:
[0,0,1,1,2,5]
提示:
1 <= nums.length <= 5 * 104
-5 * 104 <= nums[i] <= 5 * 104
/*
只能说不讲武德 这个题目要优化快排,一开始有点莽 直接冲快排 然后不出意外的超时了 不死心的还去交了一下改进的代发 一样卡在第11 12哥测试答案上,然后就看了一下题解 题解说到了基准值改为随机函数取的一个值,然后去看了快排优化的几种思路;
关于快排 O(logn) 圈重点——————》不稳定
第一种
就是最原始的 取一个固定值当基准值 然后去对比 一般就是取第一个或者最后一个了 但是如果输入序列是随机的,处理时间可以接受的。如果数组已经有序时,此时的分割就是一个非常不好的分割。因为每次划分只能使待排序序列减一,此时为最坏情况,快速排序沦为冒泡排序了,时间复杂度为Θ(n^2)。而且,输入的数据是有序或部分有序的情况是相当常见的。
第二种
就是这个这个题 用随机函数去取基准值 这样就不会造成刚刚所说的那个情况 除非整个数组的数据一模一样的 时间复杂度又会回到Θ(n^2);
其实我感觉也没有优化什么 就只是避免了第一种所说的情况而已;
(ps:亲测 我把随机函数改了 直接让中间的值来当基准值)
第三种
三数取中法 这个可以弥补第二种的缺陷 但是它也比哪俩种都难写 这个不讲(因为我也太了解 hhhh 网上还有什么三路快排让我先去琢磨一下子)
*/
class Solution {
int quicksort(vector<int>& nums, int l, int r) {
int temp = nums[r];
int i = l - 1;
for (int j = l; j <= r - 1; ++j) {
if (nums[j] <= temp) {
i = i + 1;
swap(nums[i], nums[j]);
}
}
swap(nums[i + 1], nums[r]);
return i + 1;
}
int partition(vector<int>& nums, int l, int r) {
int i = (r+l)>>1; // 取中间的值当基准值
swap(nums[r], nums[i]);
return quicksort(nums, l, r);
}
void Sort(vector<int>& nums, int l, int r) {
if (l < r) {
int pos = partition(nums, l, r);
Sort(nums, l, pos - 1);
Sort(nums, pos + 1, r);
}
}
public:
vector<int> sortArray(vector<int>& nums) {
srand((unsigned)time(NULL));
Sort(nums, 0, (int)nums.size() - 1);
return nums;
}
};
//快排必须要用随机函数 不然就会超时
82. 删除排序链表中的重复元素 II
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
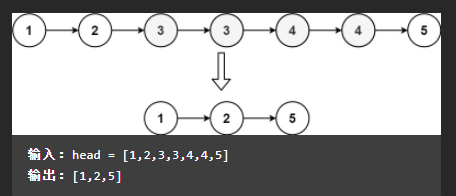
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
示例 2:
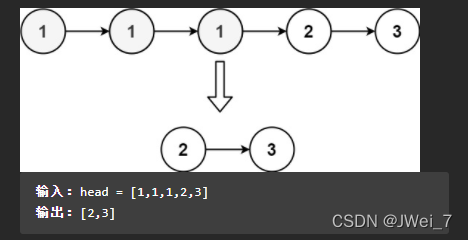
输入:head = [1,1,1,2,3]
输出:[2,3]
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (head==NULL||head->next==NULL){
//先判断是否为空
return head;
}
if (head->val!=head->next->val){
//如果当前值和下一个不一样,那么这个数据就是合法的,不需要删除,那么就将下一个递归,检查是否需要删除
head->next=deleteDuplicates(head->next);
return head;
}
else {
int value=head->val; //记录值
while (head!=NULL&&head->val==value){
//删除重复的所以值
head=head->next;
}
if (head==NULL) // 如果是空,那么直接返回
return NULL;
head=deleteDuplicates(head); //因为这个head就是下一个待检查的数据,所以不需要加next,一开始我加了,然后数据少了,有时候有多了 所以这个还是要注意一下,否则很容易出错
return head;
}
}
};