实验记录
去年的程序,洗洗还能用:【李宏毅2021机器学习深度学习——作业4 Self-Attention】Speaker classification 记录(双过strong baseline)(待改进)
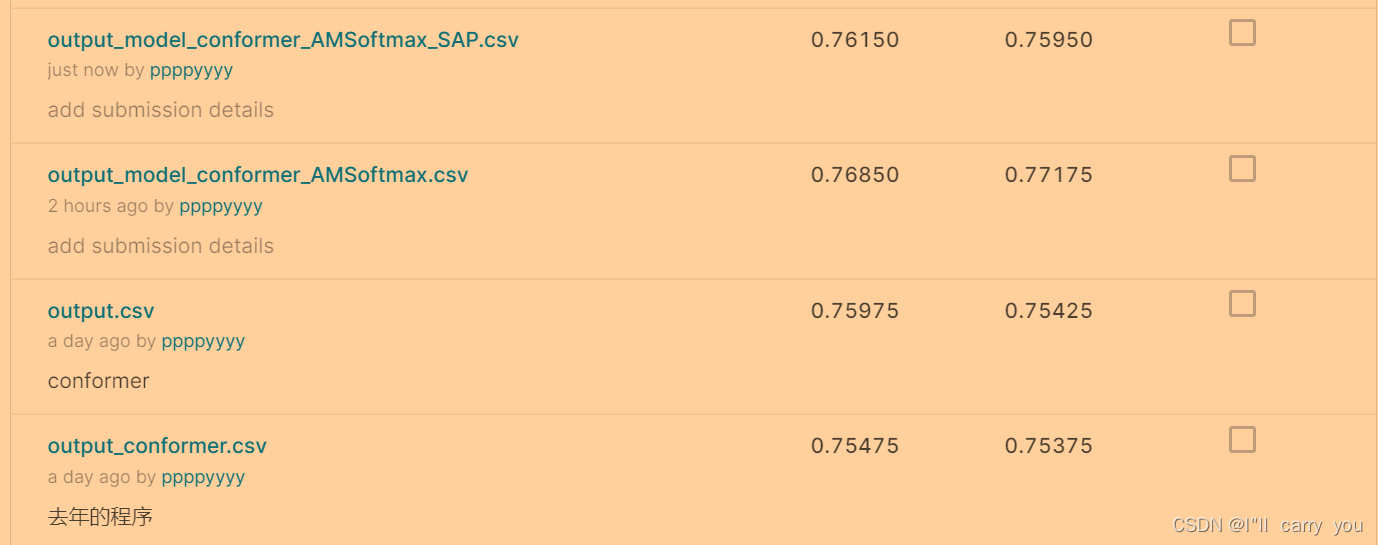
做了conformer却没达到strong baseline,参数用的默认参数(没有调参,参数也不是很理解), AMSoftmax有提升,SAP却低了(可能代码写错了?)。
等待改进中…做了一回调包侠…
评分标准
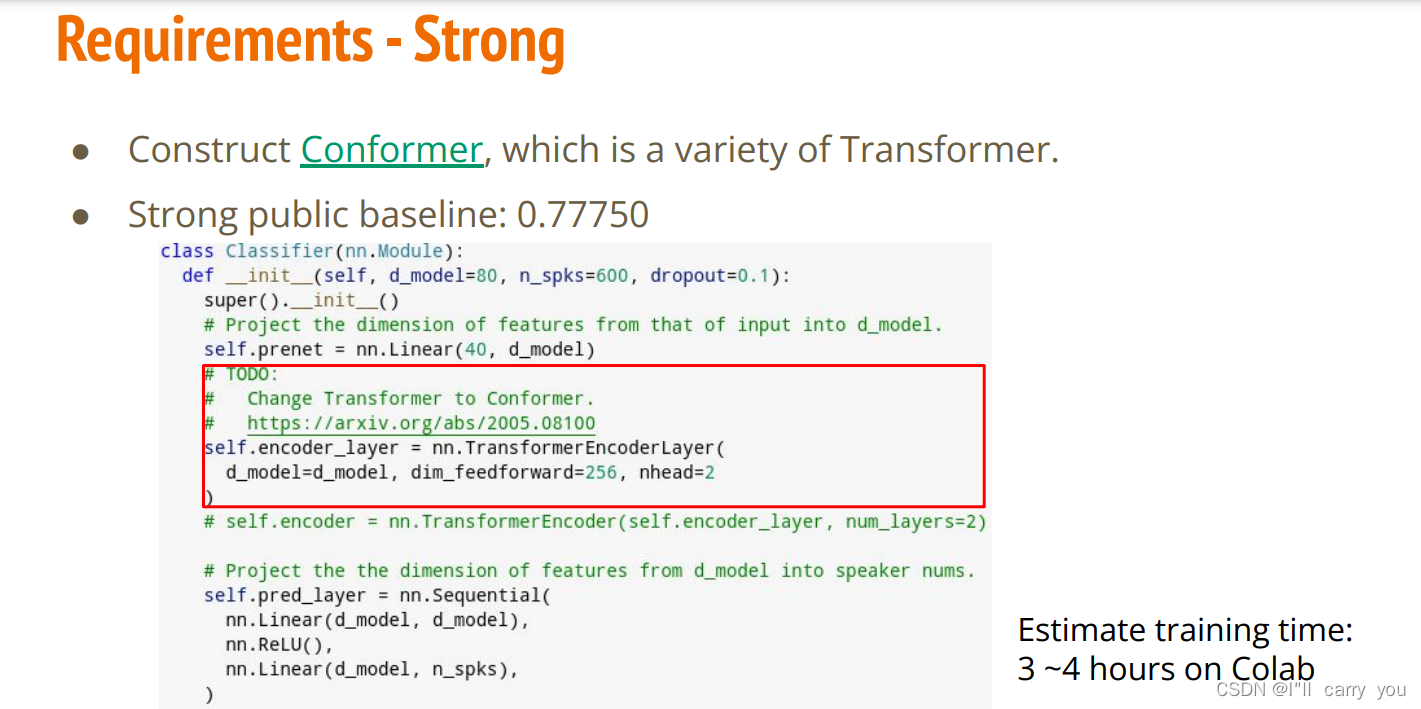

收获
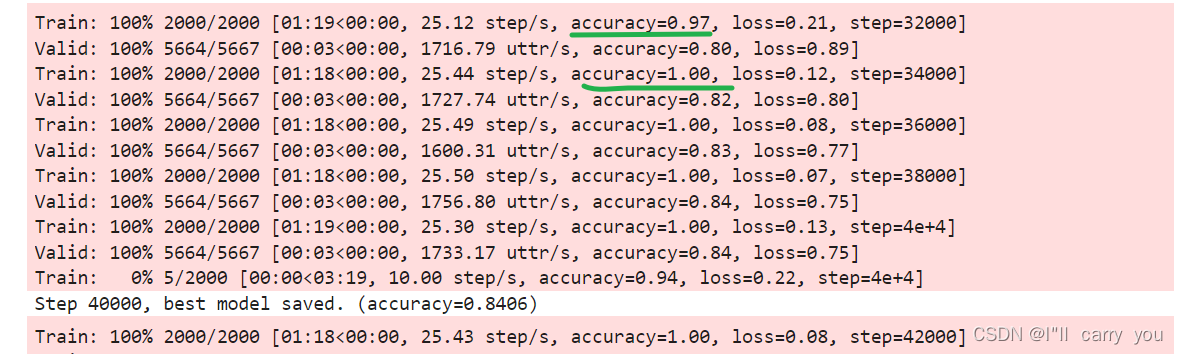
train的准确率是1,说明过拟合了把所有样本记下来了,模型并没有真正学到。必须Additive Margin Softmax 使任务更难一点。
参考资料
Conformer
https://github.com/lucidrains/conformer/blob/master/conformer/conformer.py
AM-Softmax:
我用的这个 code:https://github.com/zhilangtaosha/SpeakerVerification_AMSoftmax_pytorch
【论文阅读】AM-Softmax:Additive Margin Softmax for Face Verification. 1801.05599.【损失函数设计】
FocalSoftmax
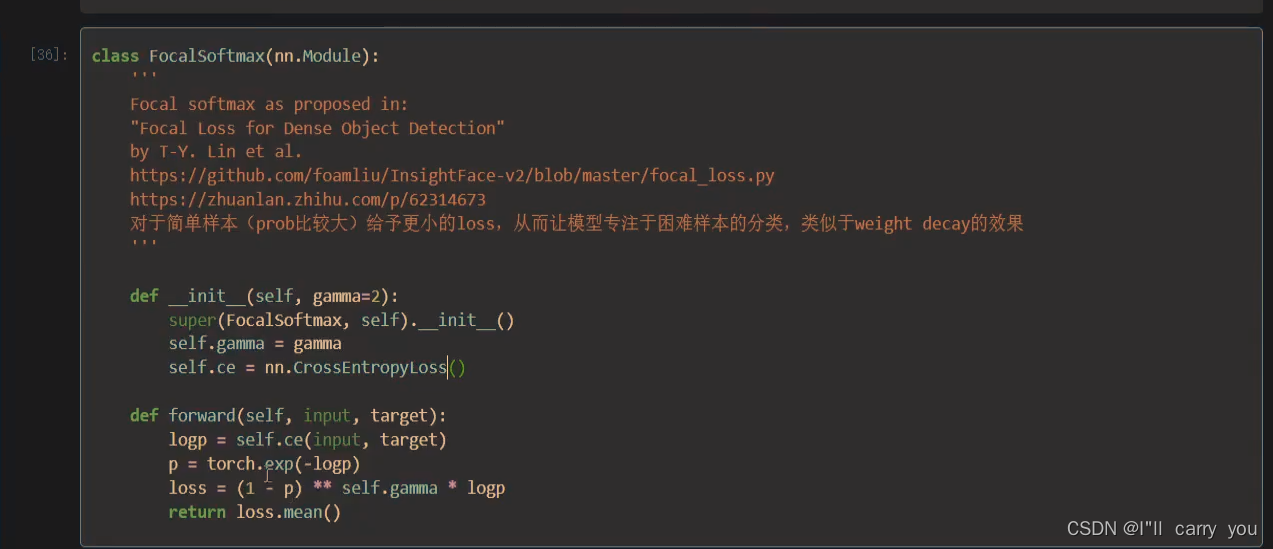
【ML2021李宏毅机器学习】作业4 Speaker Classification 思路讲解:https://www.bilibili.com/video/BV1nL4y1H7Wo
Self_Attention_Pooling
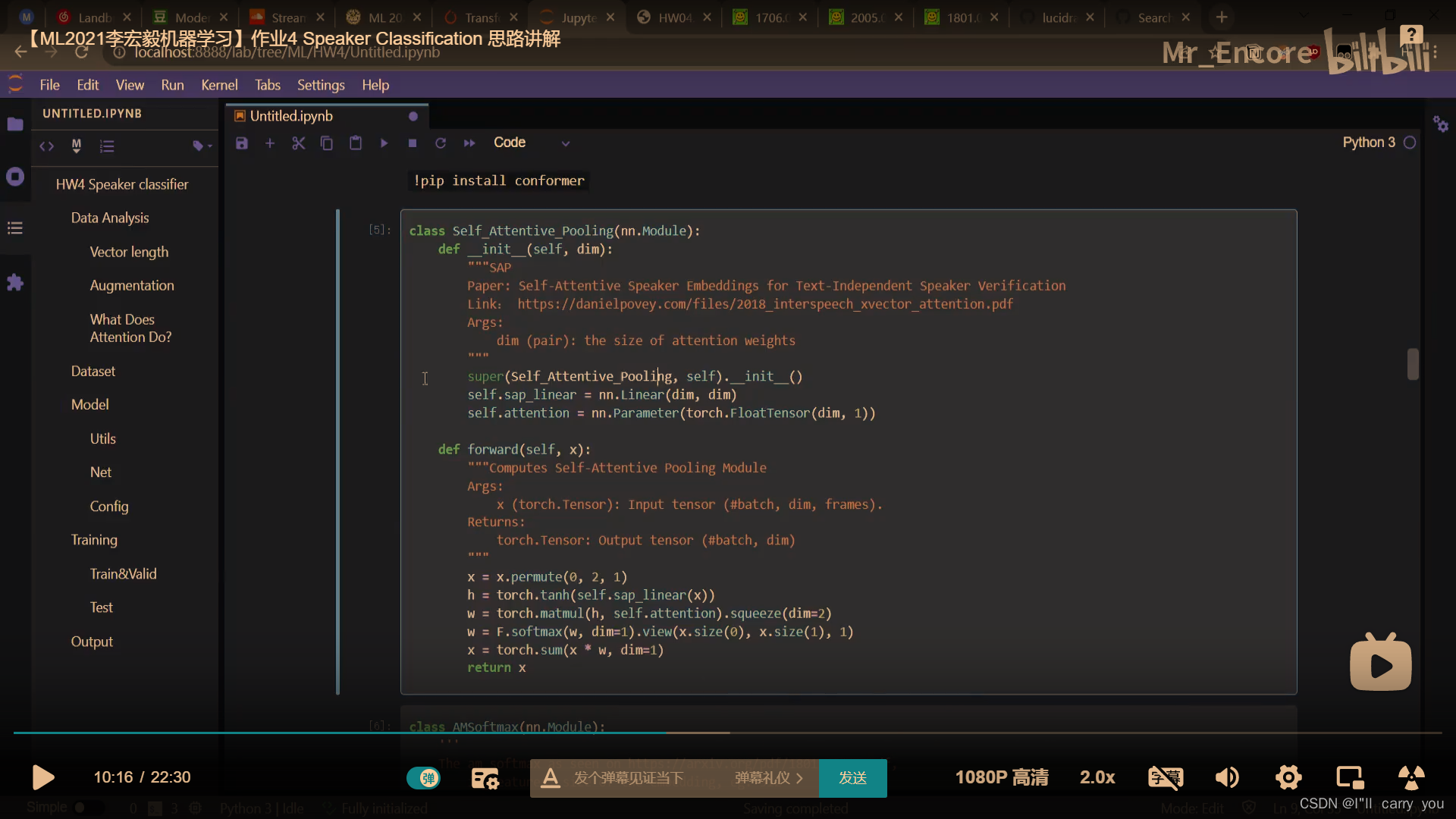
SAP另一实现:https://github.com/nii-yamagishilab/project-NN-Pytorch-scripts/commit/b0d9ac3e2602cd96e042daf5f78103df6a9bb1af
class SelfWeightedPooling(torch_nn.Module):
""" SelfWeightedPooling module
Inspired by
https://github.com/joaomonteirof/e2e_antispoofing/blob/master/model.py
To avoid confusion, I will call it self weighted pooling
"""
def __init__(self, feature_dim, mean_only=False):
super(SelfWeightedPooling, self).__init__()
self.feature_dim = feature_dim
self.mean_only = mean_only
self.noise_std = 1e-5
self.mm_weights = torch_nn.Parameter(
torch.Tensor(1, feature_dim), requires_grad=True)
torch_init.kaiming_uniform_(self.mm_weights)
def forward(self, inputs):
"""
inputs
------
tensor of shape (batchsize, length, feature_dim)
output
------
tensor of shape (batchsize, feature_dim * 2) if mean_only is False
tensor of shape (batchsize, feature_dim) if mean_only is True
"""
# batch matrix multiplication
batch_size = inputs.size(0)
# change mm_weights to (batchsize, feature_dim, 1)
# weights in shape (batchsize, length, 1)
weights = torch.bmm(
inputs,
self.mm_weights.permute(1, 0).unsqueeze(0).repeat(batch_size, 1, 1))
# attention (batchsize, length, 1)
attentions = torch_nn_func.softmax(torch.tanh(weights),dim=1)
# pooling
# weighted (batchsize, length, feature_dim)
weighted = torch.mul(inputs, attentions.expand_as(inputs))
if self.mean_only:
# only output the mean vector
return weighted.sum(1)
else:
# output the mean and std vector
noise = self.noise_std * torch.randn(
weighted.size(), dtype=weighted.dtype, device=weighted.device)
avg_repr, std_repr = weighted.sum(1), (weighted+noise).std(1)
# concatenate mean and std
representations = torch.cat((avg_repr,std_repr),1)
return representations