使用LSTM进行文本蕴含判断
最近了解了一下什么是文本蕴含,大概就是两句话,如果能从前提句(premise)能推出假设句(hypothesis)或者这两句话非常相似说的是同一个意思,那么就是蕴含关系(entailment),否则就是矛盾关系(contradiction),如果看不出就是中立的(neutral)。所以说可以看成是一个三分类问题。有很多处理方法,其中一些通过某种方式对这两句话表示成向量再进行匹配,但是一句话中并不是每个词对于匹配来说都是同样重要,比如两句话的主语完全不同那么这两句话极有可能是矛盾的。于是,另一种方法采用一种词对词(word by word)的方式,对假设句采用从前往后的方式,每个词和前提句比较。比较的时候利用注意力机制看看前提句中那些词贡献比较大,利用这种方式对假设句扫描一遍后再进行判断。
模型
模型部分参照了这里。
实现了Learning Natural Language Inference with LSTM。
记
,
分别为前提句和假设句中的词
、
在对应LSTM的输出。
为对应于假设(hypothesis)中第k个词
的attention向量,通过对前提句所有词的LSTM输出加权求和得到:
其中,
为假设句中第k个词对应于前提句中第j个词的attention权重,可由下式计算:
其中,
,
为两个向量的点乘,
为要训练的权重,
为第三个LSTM的输出:
其中,
表示拼接操作。最后使用该LSTM最后的输出状态,使用全连接层去预测3种类别。
预处理及实现效果
数据集使用SNLI,预处理部分真的很讨人厌,我用了torchtext简化代码,像论文中一样我用了与训练的Glove词向量,为了减少模型的参数,词向量不进行训练。论文中采用了一些技巧,比如对前提句后添加一个NULL关键字,对于没有见过的词采用其相邻词的词向量求平均,这些我省略了。
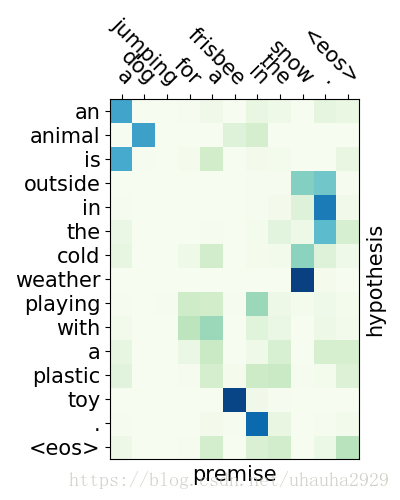
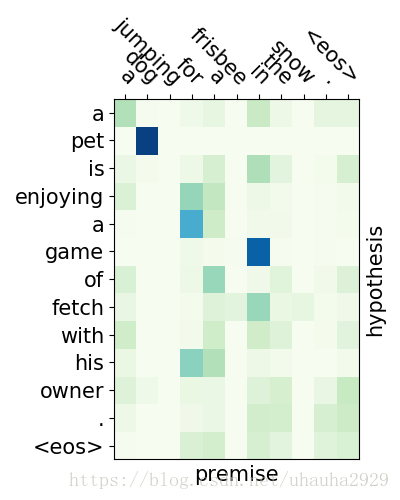
效果并没有论文中的那么好,我试了一下只有0.8383,原因很可能是模型哪边有问题或者没有进行调参等等,也可能是训练不够充分,因为我只迭代了5个epoch,运行比较慢,时间长达2个小时。不过从attention可视化可以看出模型确实进行了对齐操作。下图分别是entailment,contradiction,neutral对应的注意力分布图,图1可以看出dog和animal对应,frisbee和toy对应,snow则对应于cold weather;图二dog和cat主语不同明显是矛盾的;图3则不容易看出来。这里是我跑的代码。