利用Sentiwordnet进行文本情感分析(简)
1. 简介
利用python中的NLTK包对英文进行分词,得到词频,标注词性,得到单词得分,最后可再根据实际情况计算文本情感分。注:分词只能得到一个个单词,不能得到短语。(我的第一篇blog!!!)
2. 下载NLTK包和它内部的词典
-
使用pip下载nltk
pip install nltk
-
利用nltk下载词典
先在代码行输入:import nltk nltk.download()弹出下载框,可选all,一般下载book就够用了,不够的话在运行代码时会弹出错误提示你缺什么,再下载也可以。

3. 全过程代码详解
1. 导入所需包,函数
import pandas as pd #著名数据处理包
import nltk
from nltk import word_tokenize #分词函数
from nltk.corpus import stopwords #停止词表,如a,the等不重要的词
from nltk.corpus import sentiwordnet as swn #得到单词情感得分
import string #本文用它导入标点符号,如!"#$%&
2. 分词
-
导入文本
text = 'Nice quality, fairly quiet, nice looking and not too big. I bought two.' -
载入停止词
stop = stopwords.words("english") + list(string.punctuation) > stop[:5] ['i', 'me', 'my', 'myself', 'we'] -
根据停止词表分词
[i for i in word_tokenize(str(text).lower()) if i not in stop] > ['nice', 'quality', 'fairly', 'quiet', 'nice', 'looking', 'big', 'bought', 'two']
``
3. 计数,给予词性标签
ttt = nltk.pos_tag([i for i in word_tokenize(str(text[77]).lower()) if i not in stop])
> ttt
[('nice', 'JJ'), ('quality', 'NN'), ('fairly', 'RB'), ('quiet', 'JJ'), ('nice', 'JJ'), ('looking', 'VBG'), ('big', 'JJ'), ('bought', 'VBD'), ('two', 'CD')]
> word_tag_fq = nltk.FreqDist(ttt)
> word_tag_fq
FreqDist({('nice', 'JJ'): 2, ('quality', 'NN'): 1, ('fairly', 'RB'): 1, ('quiet', 'JJ'): 1, ('looking', 'VBG'): 1, ('big', 'JJ'): 1, ('bought', 'VBD'): 1, ('two', 'CD'): 1})
> wordlist = word_tag_fq.most_common()
> wordlist
[(('nice', 'JJ'), 2), (('quality', 'NN'), 1), (('fairly', 'RB'), 1), (('quiet', 'JJ'), 1), (('looking', 'VBG'), 1), (('big', 'JJ'), 1), (('bought', 'VBD'), 1), (('two', 'CD'), 1)]
查看’JJ’, 'NN’等所代表的的意思。如NN为noun, common,即常见名词。
扫描二维码关注公众号,回复:
9810382 查看本文章

nltk.help.upenn_tagset()
最后存入dataframe中:
key = []
part = []
frequency = []
for i in range(len(wordlist)):
key.append(wordlist[i][0][0])
part.append(wordlist[i][0][1])
frequency.append(wordlist[i][1]
textdf = pd.DataFrame({'key':key,
'part':part,
'frequency':frequency},
columns=['key','part','frequency'])
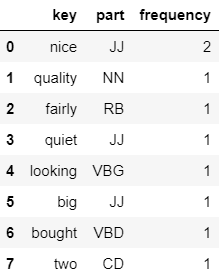
4. 计算单词得分
-
Sentiwordnet内部分函数解释
> list(swn.senti_synsets('great')) [SentiSynset('great.n.01'), SentiSynset('great.s.01'), SentiSynset('great.s.02'), SentiSynset('great.s.03'), SentiSynset('bang-up.s.01'), SentiSynset('capital.s.03'), SentiSynset('big.s.13')]其中,n为名词,v为动词,a和s为形容词,r为副词。可见,一个单词可有多种词性,每种词性也可有多种意思
> str(swn.senti_synset('good.s.06')) '<good.a.01: PosScore=0.75 NegScore=0.0>'
``
单词得分
>swn.senti_synset('good.a.01').pos_score()
0.75
这里得到的是积极得分(postive)
-
编码转换(因为前面分词和后面的词性标签不太一样)
且这里只对名词n,动词v,形容词a,副词r进行了筛选。n = ['NN','NNP','NNPS','NNS','UH'] v = ['VB','VBD','VBG','VBN','VBP','VBZ'] a = ['JJ','JJR','JJS'] r = ['RB','RBR','RBS','RP','WRB'] for i in range(len(textdf['key'])): z = textdf.iloc[i,1] if z in n: textdf.iloc[i,1]='n' elif z in v: textdf.iloc[i,1]='v' elif z in a: textdf.iloc[i,1]='a' elif z in r: textdf.iloc[i,1]='r' else: textdf.iloc[i,1]=''
``
-
计算并合并单词得分到textdf数据框中
score = [] for i in range(len(textdf['key'])): m = list(swn.senti_synsets(textdf.iloc[i,0],textdf.iloc[i,1])) s = 0 ra = 0 if len(m) > 0: for j in range(len(m)): s += (m[j].pos_score()-m[j].neg_score())/(j+1) ra += 1/(j+1) score.append(s/ra) else: score.append(0) textdf = pd.concat([textdf,pd.DataFrame({'score':score})],axis=1)因为一个单词可有多种词性,且每种词性可能有多种意思,故对该单词在该词性内所有的分数进行加权计算,得到最终该单词得分。在sentiwordnet中,一个单词一种词性内意思的顺序越靠前,该意思越能代表该单词的意思。我们赋予第一个意思1的权重,第二个1/2的权重,依此类推。其中,每个意思的分数为积极分减消极分。
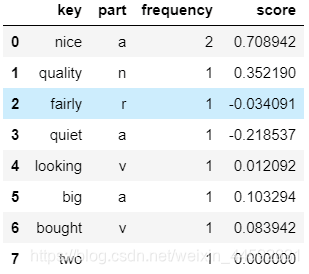
-
最后可根据实际情况计算文本情感的分。如把所有单词的得分加和记为文本得分
4. 完整代码(函数形式)
直接调用函数即可得到得分数据框。(只有上文说到的四种词性)
def text_score(text):
#create单词表
#nltk.pos_tag是打标签
ttt = nltk.pos_tag([i for i in word_tokenize(str(text).lower()) if i not in stop])
word_tag_fq = nltk.FreqDist(ttt)
wordlist = word_tag_fq.most_common()
#变为dataframe形式
key = []
part = []
frequency = []
for i in range(len(wordlist)):
key.append(wordlist[i][0][0])
part.append(wordlist[i][0][1])
frequency.append(wordlist[i][1])
textdf = pd.DataFrame({'key':key,
'part':part,
'frequency':frequency},
columns=['key','part','frequency'])
#编码
n = ['NN','NNP','NNPS','NNS','UH']
v = ['VB','VBD','VBG','VBN','VBP','VBZ']
a = ['JJ','JJR','JJS']
r = ['RB','RBR','RBS','RP','WRB']
for i in range(len(textdf['key'])):
z = textdf.iloc[i,1]
if z in n:
textdf.iloc[i,1]='n'
elif z in v:
textdf.iloc[i,1]='v'
elif z in a:
textdf.iloc[i,1]='a'
elif z in r:
textdf.iloc[i,1]='r'
else:
textdf.iloc[i,1]=''
#计算单个评论的单词分数
score = []
for i in range(len(textdf['key'])):
m = list(swn.senti_synsets(textdf.iloc[i,0],textdf.iloc[i,1]))
s = 0
ra = 0
if len(m) > 0:
for j in range(len(m)):
s += (m[j].pos_score()-m[j].neg_score())/(j+1)
ra += 1/(j+1)
score.append(s/ra)
else:
score.append(0)
return pd.concat([textdf,pd.DataFrame({'score':score})],axis=1)
