Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之 Model Confidence v2
Model Confidence v2
DIET: Lightweight Language Understanding for Dialogue Systems
论文链接:https://arxiv.org/abs/2004.09936
DIET:对话系统的轻量级语言理解
大规模预训练语言模型在 GLUE 和 SuperGLUE 等语言理解基准测试中显示出令人印象深刻的结果,与分布式表示 (GloVe) 和纯监督方法等其他预训练方法相比有了很大改进。我们介绍了双重意图和实体转换器 (DIET) 架构,并研究了不同的预训练表示对意图和实体预测这两种常见对话语言理解任务的有效性。DIET 在复杂的多域 NLU 数据集上提升了最新技术,并在其他更简单的数据集上实现了类似的高性能。令人惊讶的是,我们表明使用大型预训练模型来完成这项任务并没有明显的好处,事实上,即使在没有任何预训练嵌入的纯监督设置中,DIET 也改进了当前的技术水平。

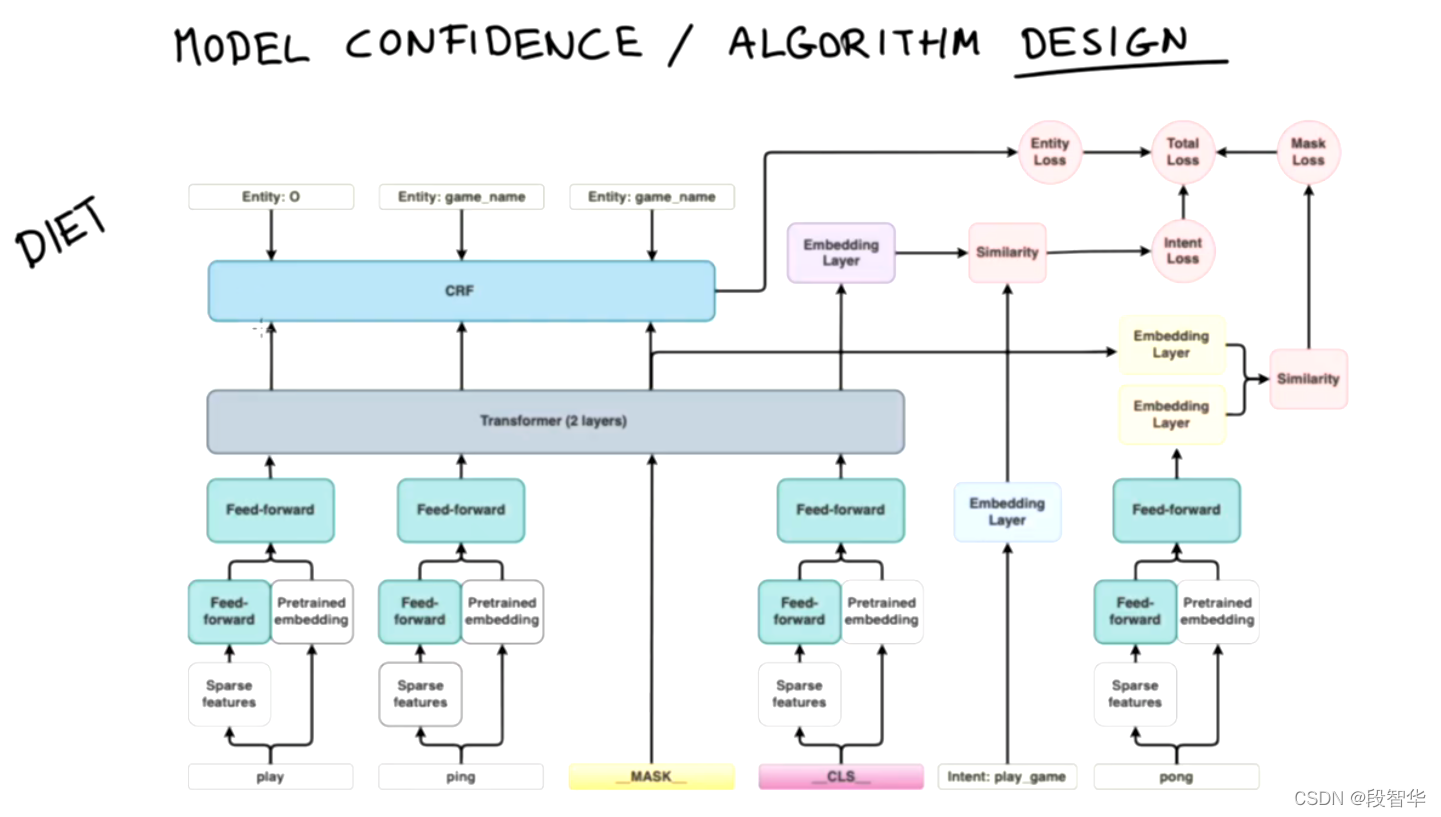
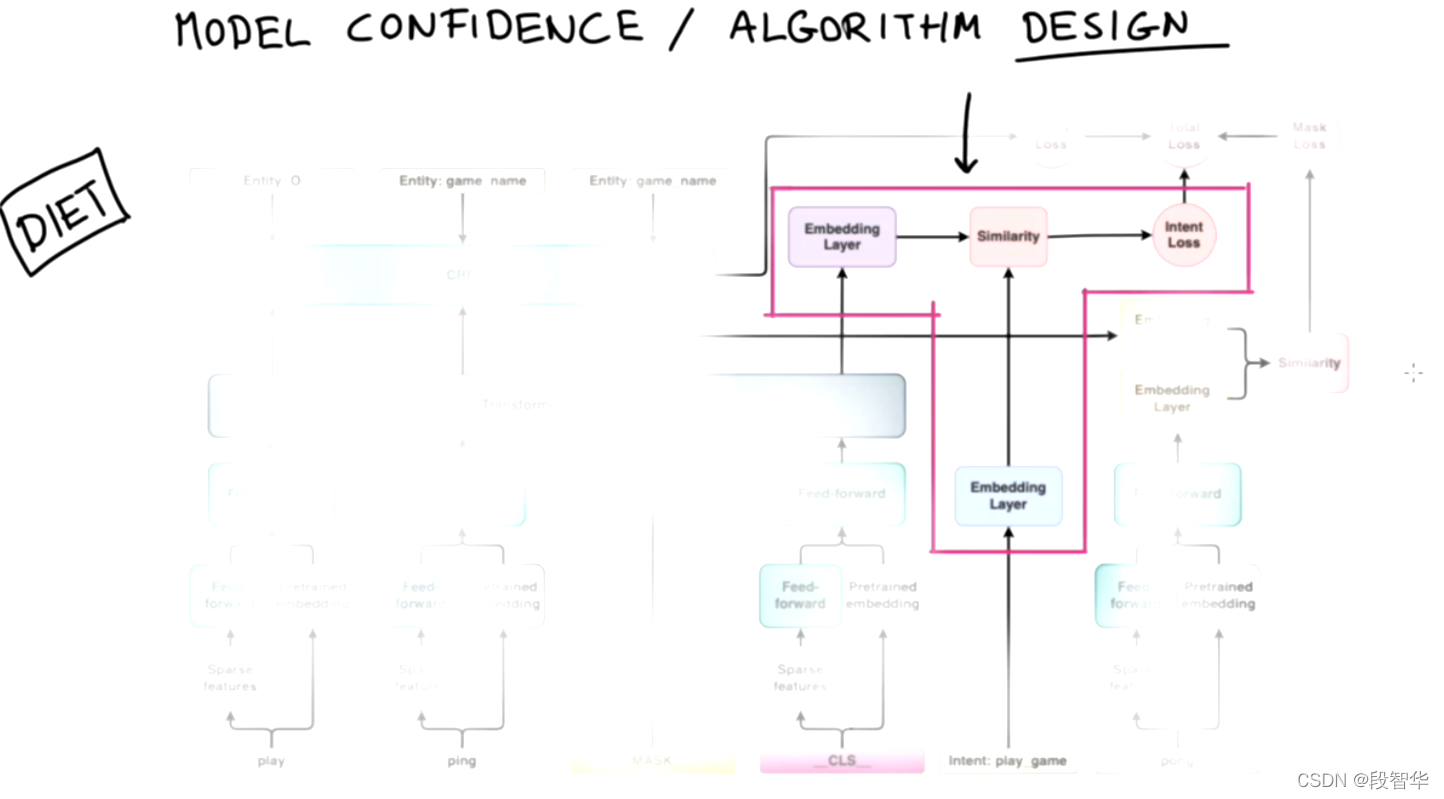
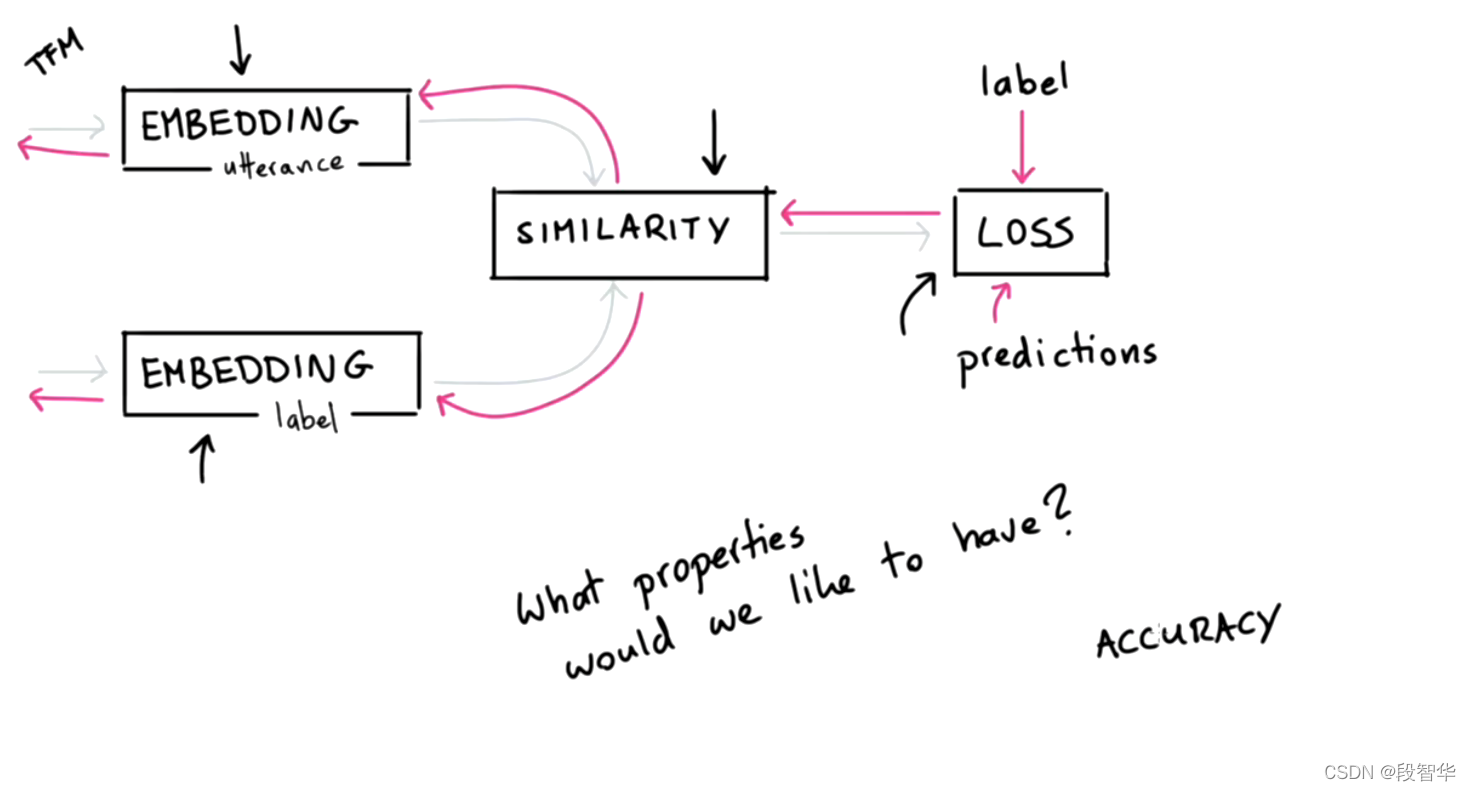
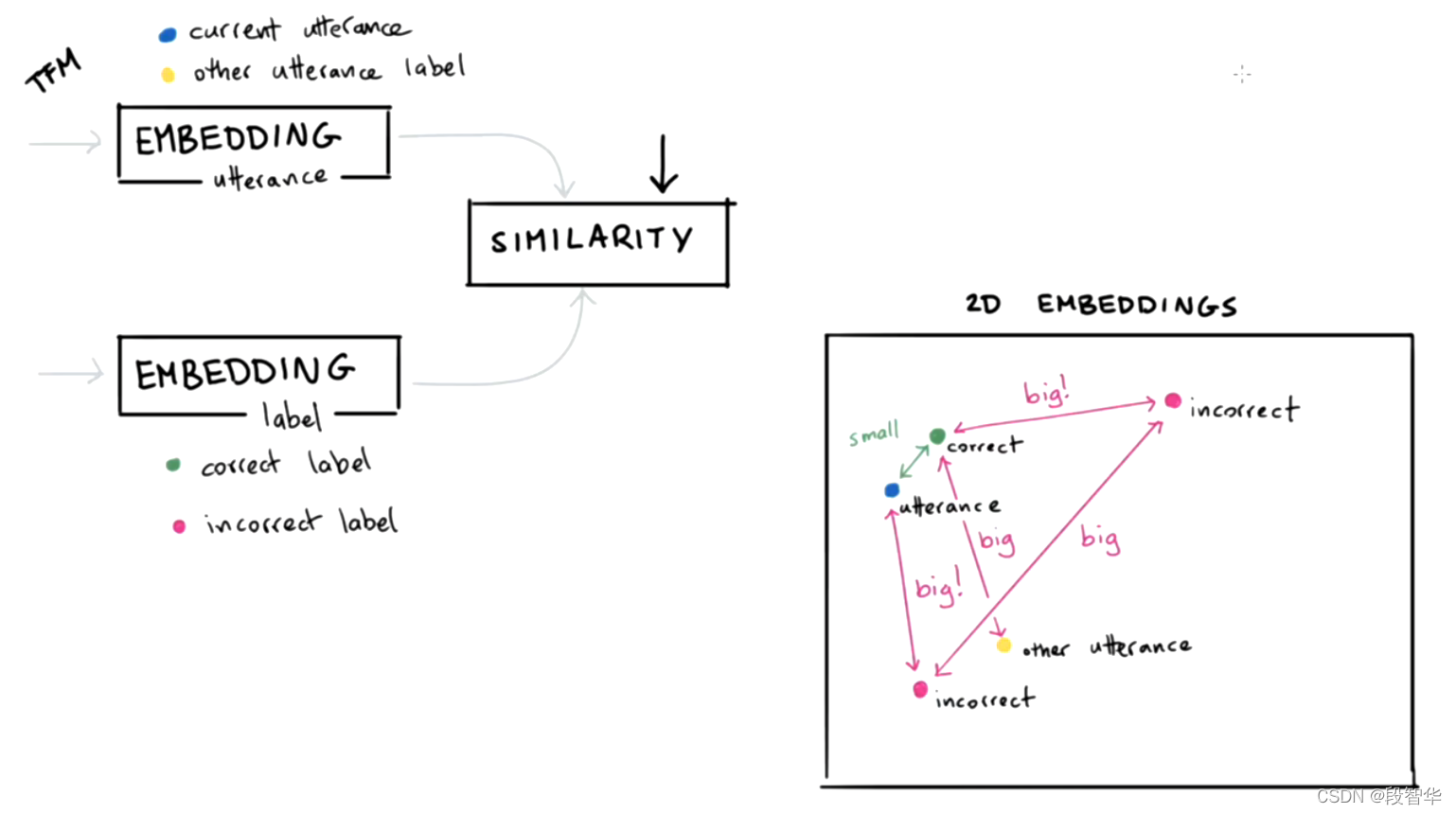
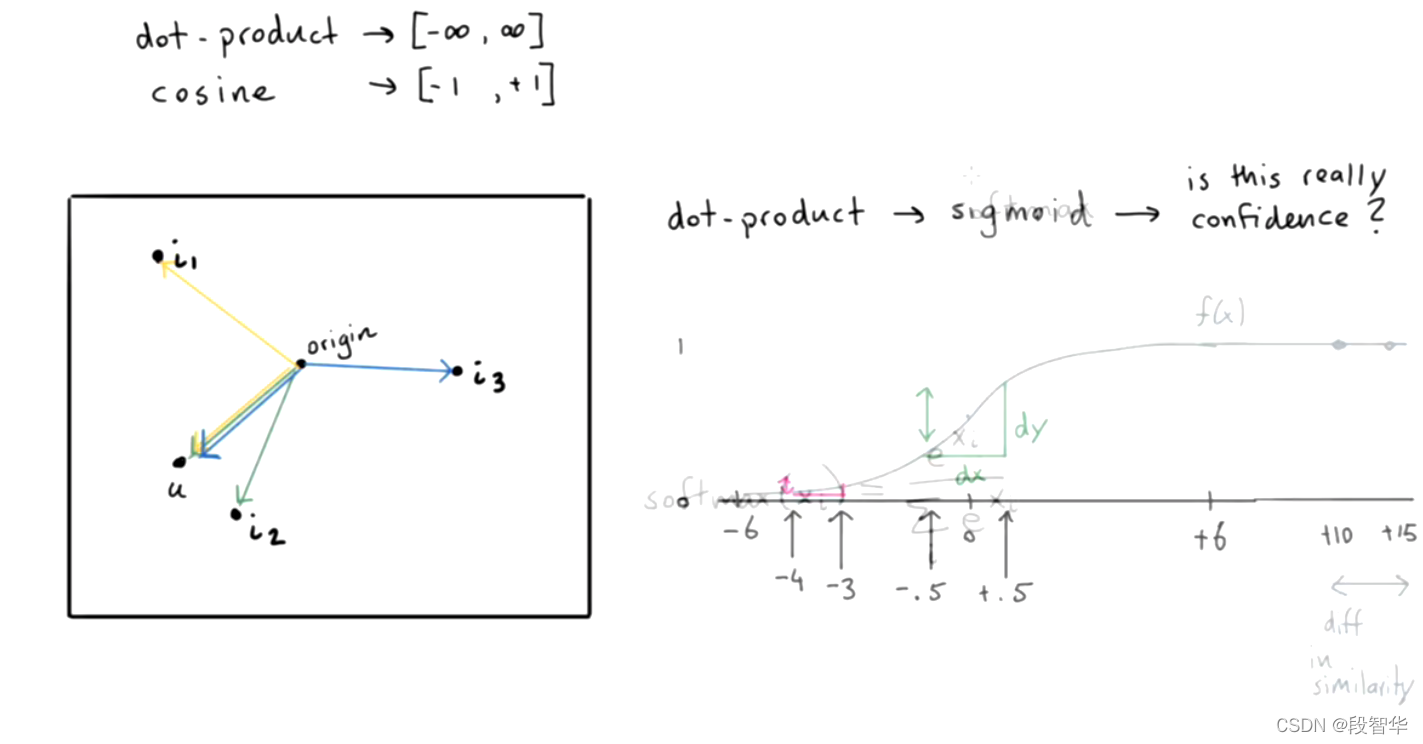
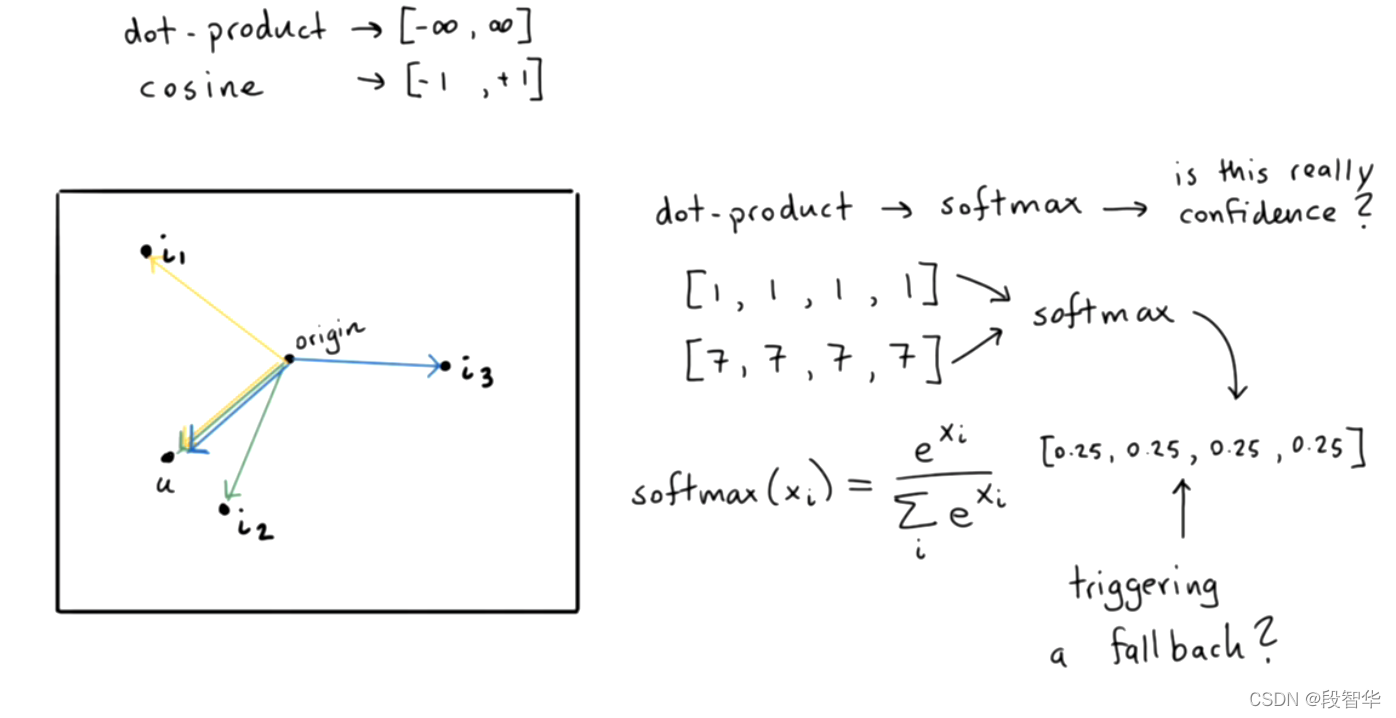
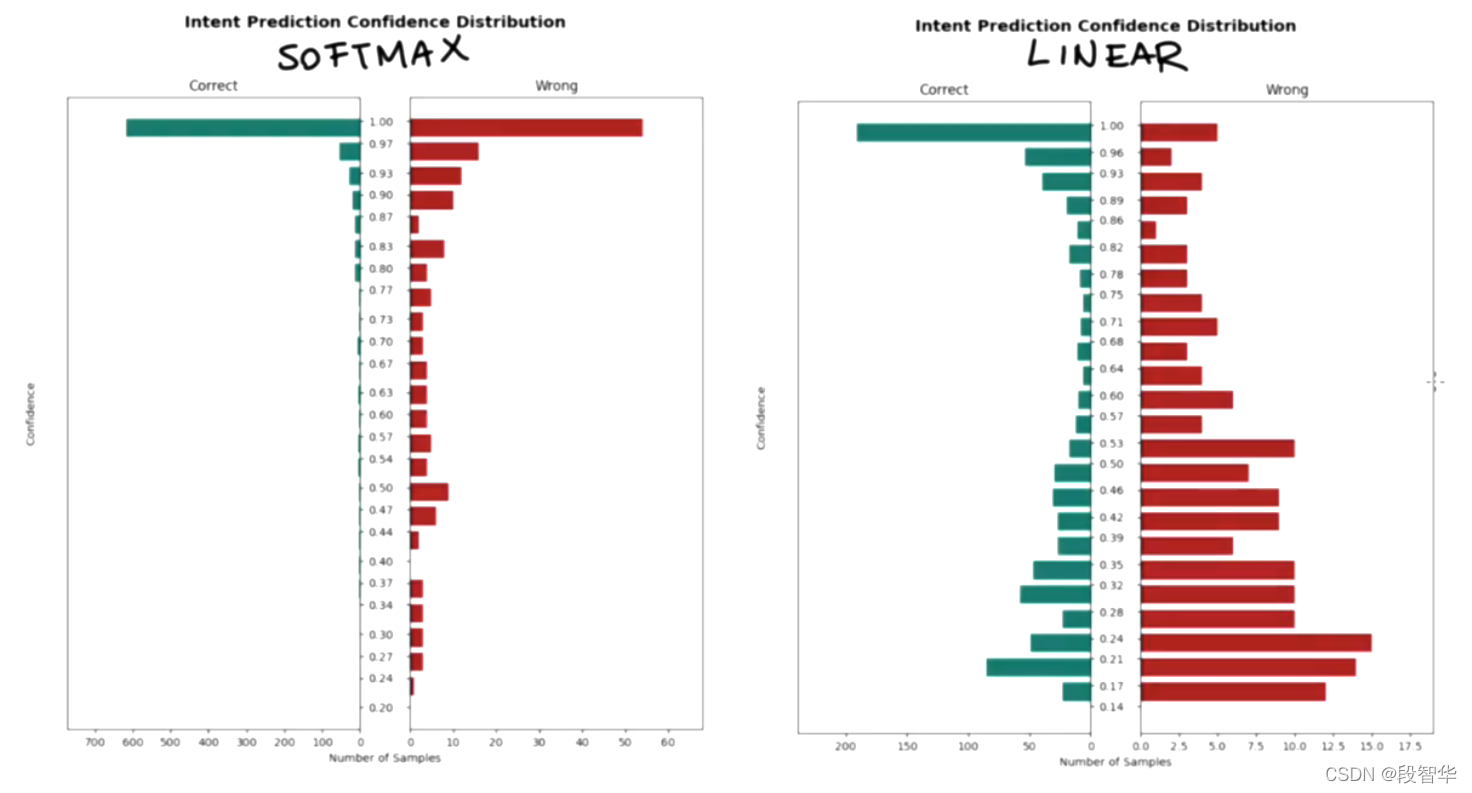

DIETClassifier
@DefaultV1Recipe.register(
[
DefaultV1Recipe.ComponentType.INTENT_CLASSIFIER,
DefaultV1Recipe.ComponentType.ENTITY_EXTRACTOR,
],
is_trainable=True,
)
class DIETClassifier(GraphComponent, IntentClassifier, EntityExtractorMixin):
"""A multi-task model for intent classification and entity extraction.
DIET is Dual Intent and Entity Transformer.
The architecture is based on a transformer which is shared for both tasks.
A sequence of entity labels is predicted through a Conditional Random Field (CRF)
tagging layer on top of the transformer output sequence corresponding to the
input sequence of tokens. The transformer output for the ``__CLS__`` token and
intent labels are embedded into a single semantic vector space. We use the
dot-product loss to maximize the similarity with the target label and minimize
similarities with negative samples.
"""
@classmethod
def required_components(cls) -> List[Type]:
"""Components that should be included in the pipeline before this component."""
return [Featurizer]
@staticmethod
def get_default_config() -> Dict[Text, Any]:
"""The component's default config (see parent class for full docstring)."""
# please make sure to update the docs when changing a default parameter
return {
# ## Architecture of the used neural network
# Hidden layer sizes for layers before the embedding layers for user message
# and labels.
# The number of hidden layers is equal to the length of the corresponding
# list.
HIDDEN_LAYERS_SIZES: {
TEXT: [], LABEL: []},
# Whether to share the hidden layer weights between user message and labels.
SHARE_HIDDEN_LAYERS: False,
# Number of units in transformer
TRANSFORMER_SIZE: DEFAULT_TRANSFORMER_SIZE,
# Number of transformer layers
NUM_TRANSFORMER_LAYERS: 2,
# Number of attention heads in transformer
NUM_HEADS: 4,
# If 'True' use key relative embeddings in attention
KEY_RELATIVE_ATTENTION: False,
# If 'True' use value relative embeddings in attention
VALUE_RELATIVE_ATTENTION: False,
# Max position for relative embeddings. Only in effect if key- or value
# relative attention are turned on
MAX_RELATIVE_POSITION: 5,
# Use a unidirectional or bidirectional encoder.
UNIDIRECTIONAL_ENCODER: False,
# ## Training parameters
# Initial and final batch sizes:
# Batch size will be linearly increased for each epoch.
BATCH_SIZES: [64, 256],
# Strategy used when creating batches.
# Can be either 'sequence' or 'balanced'.
BATCH_STRATEGY: BALANCED,
# Number of epochs to train
EPOCHS: 300,
# Set random seed to any 'int' to get reproducible results
RANDOM_SEED: None,
# Initial learning rate for the optimizer
LEARNING_RATE: 0.001,
# ## Parameters for embeddings
# Dimension size of embedding vectors
EMBEDDING_DIMENSION: 20,
# Dense dimension to use for sparse features.
DENSE_DIMENSION: {
TEXT: 128, LABEL: 20},
# Default dimension to use for concatenating sequence and sentence features.
CONCAT_DIMENSION: {
TEXT: 128, LABEL: 20},
# The number of incorrect labels. The algorithm will minimize
# their similarity to the user input during training.
NUM_NEG: 20,
# Type of similarity measure to use, either 'auto' or 'cosine' or 'inner'.
SIMILARITY_TYPE: AUTO,
# The type of the loss function, either 'cross_entropy' or 'margin'.
LOSS_TYPE: CROSS_ENTROPY,
# Number of top intents for which confidences should be reported.
# Set to 0 if confidences for all intents should be reported.
RANKING_LENGTH: LABEL_RANKING_LENGTH,
# Indicates how similar the algorithm should try to make embedding vectors
# for correct labels.
# Should be 0.0 < ... < 1.0 for 'cosine' similarity type.
MAX_POS_SIM: 0.8,
# Maximum negative similarity for incorrect labels.
# Should be -1.0 < ... < 1.0 for 'cosine' similarity type.
MAX_NEG_SIM: -0.4,
# If 'True' the algorithm only minimizes maximum similarity over
# incorrect intent labels, used only if 'loss_type' is set to 'margin'.
USE_MAX_NEG_SIM: True,
# If 'True' scale loss inverse proportionally to the confidence
# of the correct prediction
SCALE_LOSS: False,
# ## Regularization parameters
# The scale of regularization
REGULARIZATION_CONSTANT: 0.002,
# The scale of how important is to minimize the maximum similarity
# between embeddings of different labels,
# used only if 'loss_type' is set to 'margin'.
NEGATIVE_MARGIN_SCALE: 0.8,
# Dropout rate for encoder
DROP_RATE: 0.2,
# Dropout rate for attention
DROP_RATE_ATTENTION: 0,
# Fraction of trainable weights in internal layers.
CONNECTION_DENSITY: 0.2,
# If 'True' apply dropout to sparse input tensors
SPARSE_INPUT_DROPOUT: True,
# If 'True' apply dropout to dense input tensors
DENSE_INPUT_DROPOUT: True,
# ## Evaluation parameters
# How often calculate validation accuracy.
# Small values may hurt performance.
EVAL_NUM_EPOCHS: 20,
# How many examples to use for hold out validation set
# Large values may hurt performance, e.g. model accuracy.
# Set to 0 for no validation.
EVAL_NUM_EXAMPLES: 0,
# ## Model config
# If 'True' intent classification is trained and intent predicted.
INTENT_CLASSIFICATION: True,
# If 'True' named entity recognition is trained and entities predicted.
ENTITY_RECOGNITION: True,
# If 'True' random tokens of the input message will be masked and the model
# should predict those tokens.
MASKED_LM: False,
# 'BILOU_flag' determines whether to use BILOU tagging or not.
# If set to 'True' labelling is more rigorous, however more
# examples per entity are required.
# Rule of thumb: you should have more than 100 examples per entity.
BILOU_FLAG: True,
# If you want to use tensorboard to visualize training and validation
# metrics, set this option to a valid output directory.
TENSORBOARD_LOG_DIR: None,
# Define when training metrics for tensorboard should be logged.
# Either after every epoch or for every training step.
# Valid values: 'epoch' and 'batch'
TENSORBOARD_LOG_LEVEL: "epoch",
# Perform model checkpointing
CHECKPOINT_MODEL: False,
# Specify what features to use as sequence and sentence features
# By default all features in the pipeline are used.
FEATURIZERS: [],
# Split entities by comma, this makes sense e.g. for a list of ingredients
# in a recipie, but it doesn't make sense for the parts of an address
SPLIT_ENTITIES_BY_COMMA: True,
# If 'True' applies sigmoid on all similarity terms and adds
# it to the loss function to ensure that similarity values are
# approximately bounded. Used inside cross-entropy loss only.
CONSTRAIN_SIMILARITIES: False,
# Model confidence to be returned during inference. Currently, the only
# possible value is `softmax`.
MODEL_CONFIDENCE: SOFTMAX,
# Determines whether the confidences of the chosen top intents should be
# renormalized so that they sum up to 1. By default, we do not renormalize
# and return the confidences for the top intents as is.
# Note that renormalization only makes sense if confidences are generated
# via `softmax`.
RENORMALIZE_CONFIDENCES: False,
}
def __init__(
self,
config: Dict[Text, Any],
model_storage: ModelStorage,
resource: Resource,
execution_context: ExecutionContext,
index_label_id_mapping: Optional[Dict[int, Text]] = None,
entity_tag_specs: Optional[List[EntityTagSpec]] = None,
model: Optional[RasaModel] = None,
sparse_feature_sizes: Optional[Dict[Text, Dict[Text, List[int]]]] = None,
) -> None:
"""Declare instance variables with default values."""
if EPOCHS not in config:
rasa.shared.utils.io.raise_warning(
f"Please configure the number of '{
EPOCHS}' in your configuration file."
f" We will change the default value of '{
EPOCHS}' in the future to 1. "
)
self.component_config = config
self._model_storage = model_storage
self._resource = resource
self._execution_context = execution_context
self._check_config_parameters()
# transform numbers to labels
self.index_label_id_mapping = index_label_id_mapping or {
}
self._entity_tag_specs = entity_tag_specs
self.model = model
self.tmp_checkpoint_dir = None
if self.component_config[CHECKPOINT_MODEL]:
self.tmp_checkpoint_dir = Path(rasa.utils.io.create_temporary_directory())
self._label_data: Optional[RasaModelData] = None
self._data_example: Optional[Dict[Text, Dict[Text, List[FeatureArray]]]] = None
self.split_entities_config = rasa.utils.train_utils.init_split_entities(
self.component_config[SPLIT_ENTITIES_BY_COMMA],
SPLIT_ENTITIES_BY_COMMA_DEFAULT_VALUE,
)
self.finetune_mode = self._execution_context.is_finetuning
self._sparse_feature_sizes = sparse_feature_sizes
# init helpers
def _check_masked_lm(self) -> None:
if (
self.component_config[MASKED_LM]
and self.component_config[NUM_TRANSFORMER_LAYERS] == 0
):
raise ValueError(
f"If number of transformer layers is 0, "
f"'{
MASKED_LM}' option should be 'False'."
)
def _check_share_hidden_layers_sizes(self) -> None:
if self.component_config.get(SHARE_HIDDEN_LAYERS):
first_hidden_layer_sizes = next(
iter(self.component_config[HIDDEN_LAYERS_SIZES].values())
)
# check that all hidden layer sizes are the same
identical_hidden_layer_sizes = all(
current_hidden_layer_sizes == first_hidden_layer_sizes
for current_hidden_layer_sizes in self.component_config[
HIDDEN_LAYERS_SIZES
].values()
)
if not identical_hidden_layer_sizes:
raise ValueError(
f"If hidden layer weights are shared, "
f"{
HIDDEN_LAYERS_SIZES} must coincide."
)
def _check_config_parameters(self) -> None:
self.component_config = train_utils.check_deprecated_options(
self.component_config
)
self._check_masked_lm()
self._check_share_hidden_layers_sizes()
self.component_config = train_utils.update_confidence_type(
self.component_config
)
train_utils.validate_configuration_settings(self.component_config)
self.component_config = train_utils.update_similarity_type(
self.component_config
)
self.component_config = train_utils.update_evaluation_parameters(
self.component_config
)
@classmethod
def create(
cls,
config: Dict[Text, Any],
model_storage: ModelStorage,
resource: Resource,
execution_context: ExecutionContext,
) -> DIETClassifier:
"""Creates a new untrained component (see parent class for full docstring)."""
return cls(config, model_storage, resource, execution_context)
Rasa 3.x系列博客分享
-
Rasa课程、Rasa培训、Rasa面试系列 Rasa 3.X 项目实战之银行金融Financial Bot智能业务对话机器人
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Diet Architecture How it Works
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Diet Architecture Why it Works(Design Decisions)
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Diet Architecture Benchmarking
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Understanding Word Embeddings Just Letters
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Understanding Word Embeddings CBOW and Skip Gram
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Understanding Word Embeddings GloVe
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Understanding Word Embeddings Whatlies
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Transformers & Attention Self Attention
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之 Countvectors and Spelling Errors
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Subword Embeddings and Spelling
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之免费录播课Rasa 3.X 智能对话机器人案例开发硬核实战高手之路 (7大项目Expert版本)之 Debugging项目实战系列
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Implementation of Subword Embeddings
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之星空NLP对话机器人论文班:NLP领域10篇最高质量的对话机器人经典论文解密
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Measuring Bias in Word Embeddings
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Gavin大咖免费公益课程 Rasa Paper对话机器人经典论文解读班
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Using Projections to Remove Bias from Word Embeddings
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之 Debiasing via Projections Doesnot Always Work
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Hugging Face bert-base-chinese 使用
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Gavin大咖免费公益课程Rasa Paper论文解析核心版
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之The Maths Behind De-Biasing in Word Embeddings
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Word Analogies don‘t Hold in General
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之General Embeddings vs. Specific Problems
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之 UnexpecTEDIntentPolicy Details
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之NER for Personal Indentifiable Information is Hard
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Translation Issues及Bulk Labelling
-
Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之MessageContainerForCoreFeaturization