Rasa课程、Rasa培训、Rasa面试、Rasa实战系列之Understanding Word Embeddings GloVe
one hot encoding VS word2vec
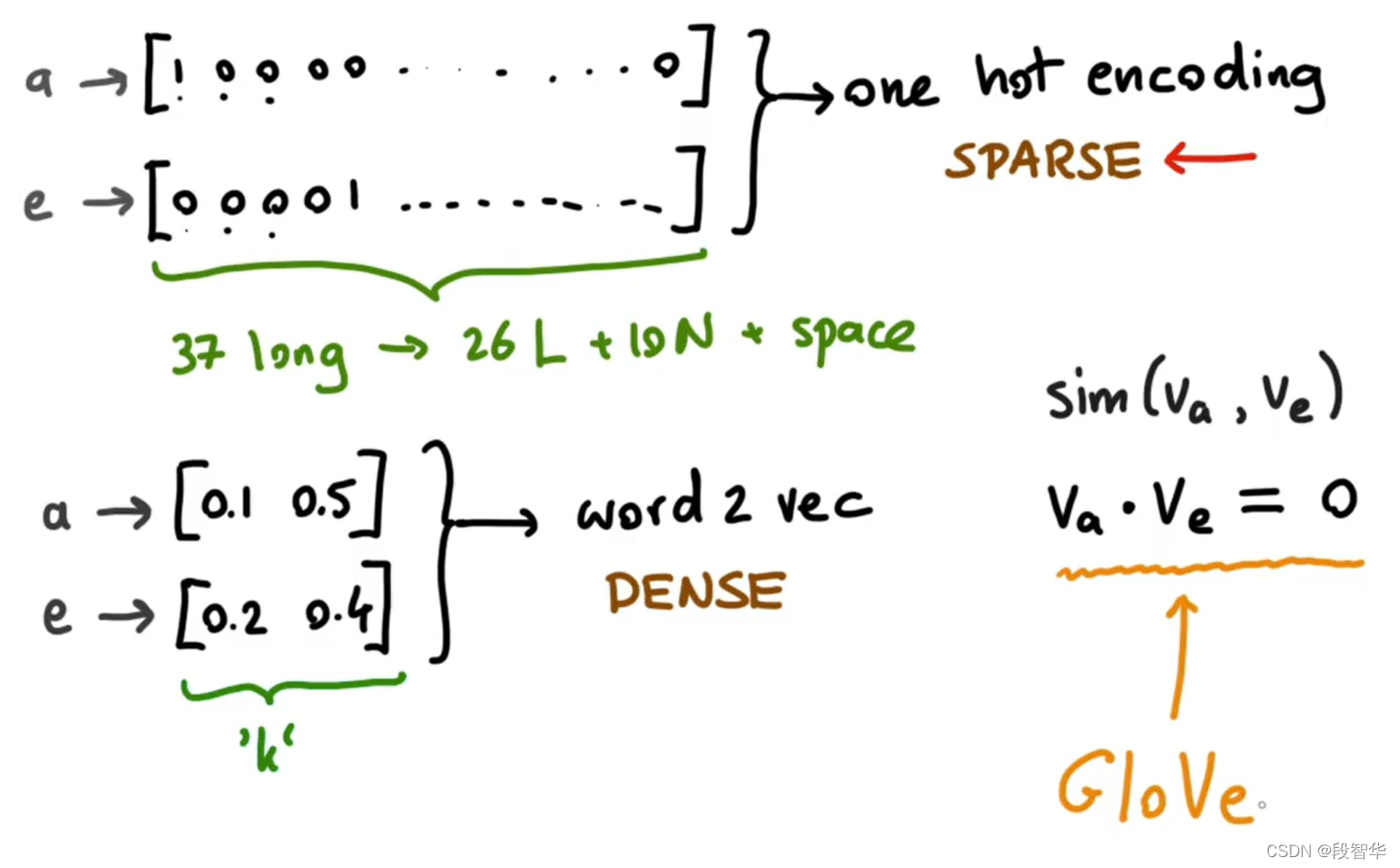
- one-hot编码示例
每个单词在向量中都有自己的值,但它失去了句子中单词的内在含义,失去了句子的上下文。两个单词的稀疏向量相似度计算为0

- word2vec示例
不同的词在不同的特征上具有几乎相似的值(这里的性别、皇家、年龄和食物是特征)。正因为如此,词嵌入可以从词中保存句子的上下文信息,并且在对大型数据集进行训练之后,甚至可以识别句子中向量表示中不可获取的词。这样,我们可以在相对较小的未标记数据集上使用在大量数据集上训练的模型。因此,词嵌入可用于迁移学习。由于这个属性,词嵌入在命名实体识别、文本摘要、共同引用解析和解析等广泛的应用中非常有用。