Hadoop的安装方式
单机:所有的服务运行在一个进程里面,开发阶段才会使用
分布式:将多个服务(JVM),分别运行在多台机器上。
伪分布式:将多个服务(JVM)运行在一台机器上
Hadoop伪分布式安装
文档:http://hadoop.apache.org/docs/r2.7.6/hadoop-project-dist/hadoop-common/SingleCluster.html
安装过程:
(1)上传解压
tar -zxvf hadoop-2.7.3.tar.gz -C /opt/modules/
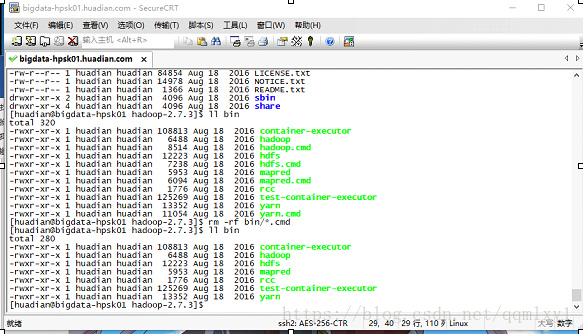
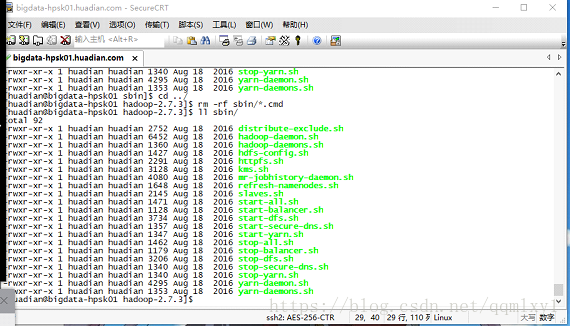
rm -rf sbin/*.cmd
(3)修改配置文件(安装模块来配置)
-》*-env.sh 环境变量文件
hadoop-env.sh
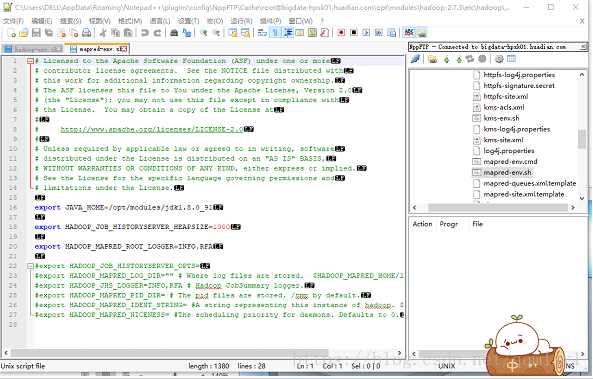
yarn-env.sh

修改JAVA_HOME=/opt/modules/jdk1.8.0_91
-》common
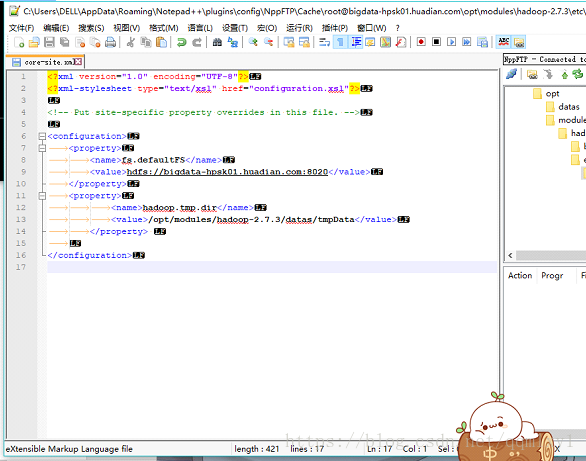
core-site.xml
<!--指定文件系统HDFS的主节点NameNode运行的 主机名 和 端口 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata-hpsk01.huadian.com:8020</value>
</property>
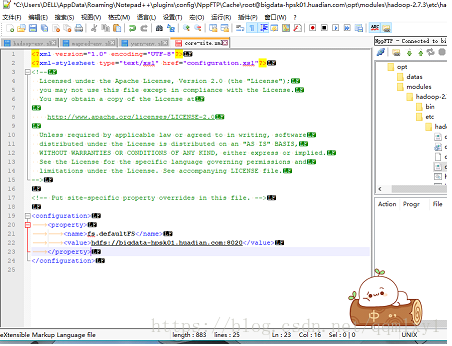
<!--指定HDFS文件系统在本地临时存储的目录(需要手动创建),默认是/tmp, -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.7.3/datas/tmpData</value>
</property>
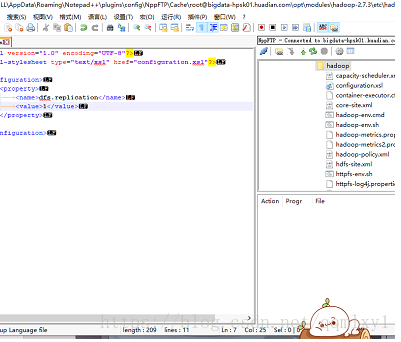
-》HDFS
hdfs-site.xml
<!--由于伪分布式,只有一台机器,所有数据块 没有必要设置3份-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
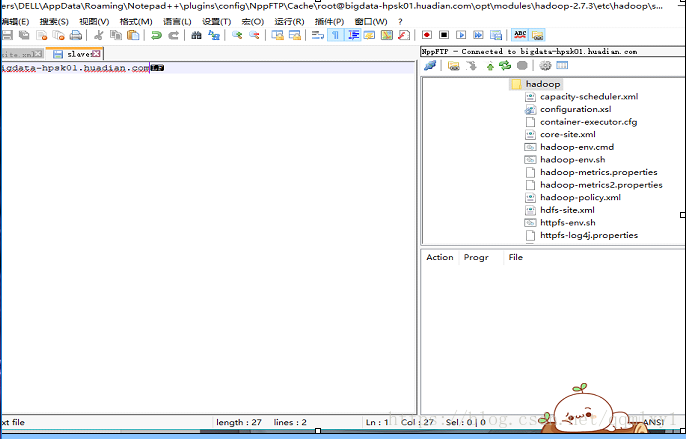
slaves
指定DataNode运行在那些机器上
一行一个主机名,DataNode将会运行在此主机上
-》启动HDFS
-》格式化文件系统
bin/hdfs namenode -format
成功的标准:
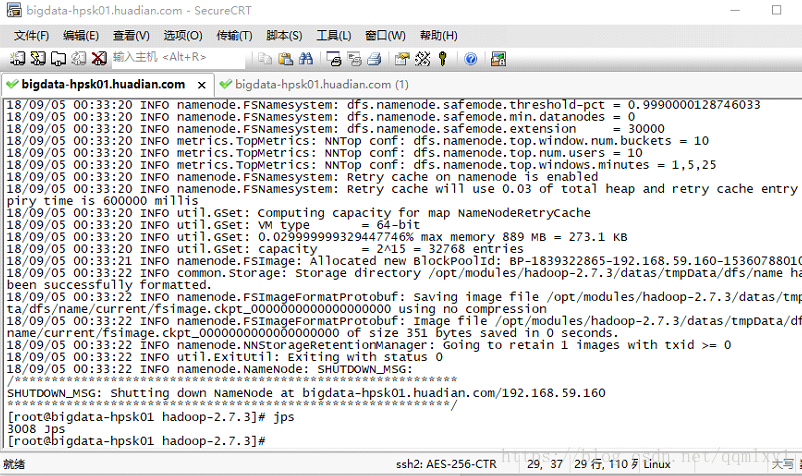
18/09/04 00:15:05 INFO util.ExitUtil: Exiting with status 0
-》启动
主节点:NameNode
sbin/hadoop-daemon.sh start namenode

-》验证是否启动
方式一:
Jps

方式二:
通过Web UI查看
bigdata-hpsk01.huadian.com:50070

访问失败的原因:
(1)确定进程是否启动
(2)映射是否配置成功
(3)防火墙是否关闭,selinux是否设置为disable
-》HDFS的基本使用
帮助文档
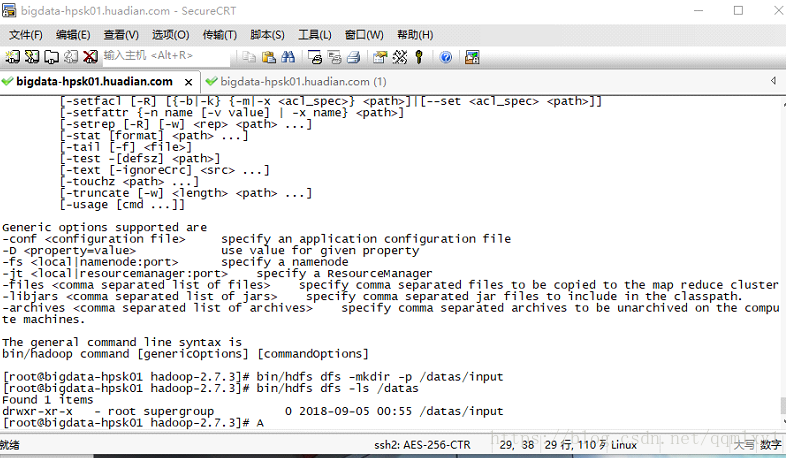
bin/hdfs dfs
- 创建目录
bin/hdfs dfs -mkdir -p /datas/input
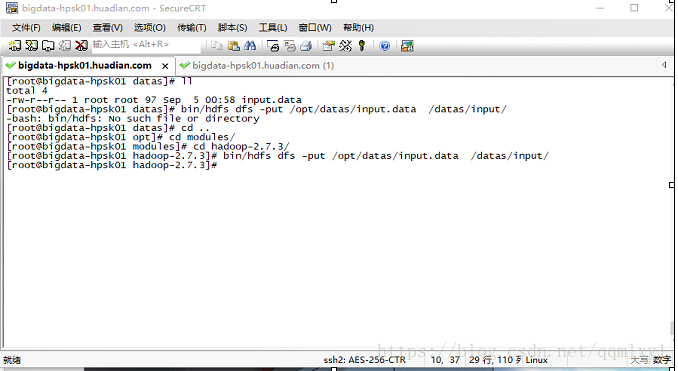
- 上传文件
bin/hdfs dfs -put /opt/datas/input.data /datas/input/
- 列举目录文件
bin/hdfs dfs -ls /datas
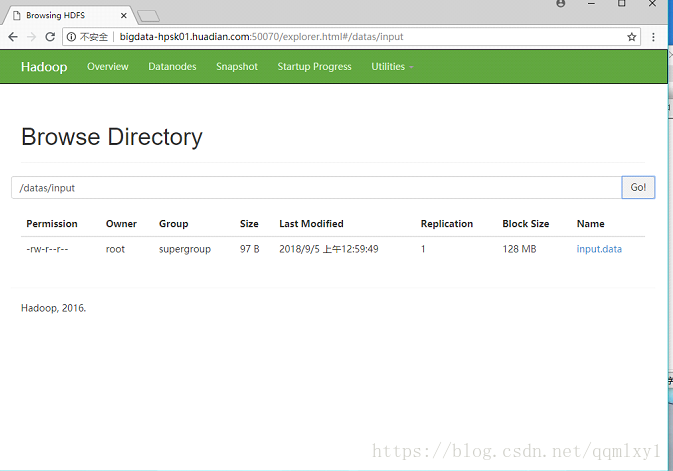
webUI
- 查看文件内容
bin/hdfs dfs -text /datas/input/input.data

- 删除文件
bin/hdfs dfs -rm -f -r /datas/input/input.data

-》YARN
yarn-site.xml
<!--YARN的主节点ResourceManager 运行的主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata-hpsk01.huadian.com</value>
</property>
<!--告知YARN,MapReduce程序将运行在其上-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>

slaves --我们不需要配置,刚刚已经配置过一次了
指定NodeManager运行在那些机器上
一行一个主机名,DataNode将会运行在此主机上
-》启动YARN
启动
主节点
sbin/yarn-daemon.sh start resourcemanager
从节点
sbin/yarn-daemon.sh start nodemanager
验证:
方式一:JPS
方式二:WebUI,8088端口
bigdata-hpsk01.huadian.com:8088
-》MapReduce
mv mapred-site.xml.template mapred-site.xml
<!--指定MapReduce程序运行在YARN上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
-》将MapReduce程序运行在YARN上
准备测试:需要分享的数据
/datas/input/input.data
MapReduce程序
/opt/modules/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
提交
将mapreduce程序提交到YARN上运行
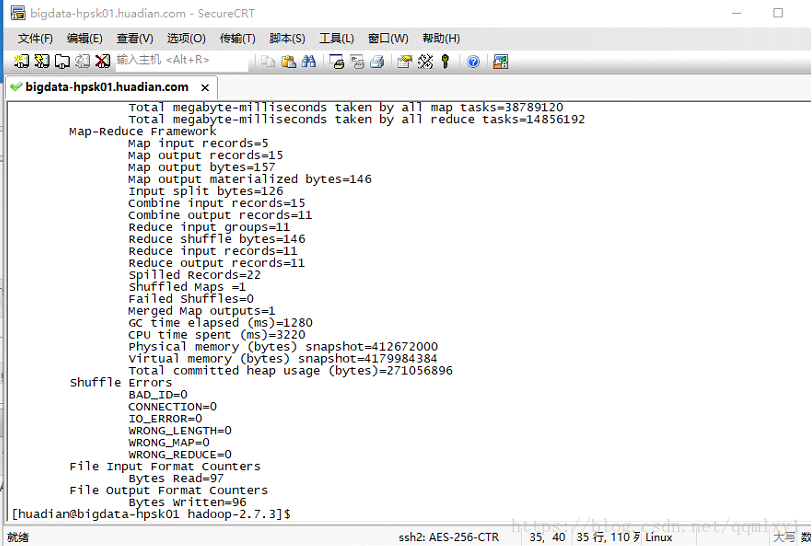
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /datas/input/input.data /datas/output/output1