过去几年对深度学习的广泛而强烈的兴趣激发了公司、学者和业余爱好者开发各种成熟的开源框架,以自动执行基于梯度的学习算法的重复工作。在 第 3.2 节中,我们仅依靠
- (i) 张量进行数据存储和线性代数;
- (ii) 用于计算梯度的自动微分。
在实践中,由于数据迭代器、损失函数、优化器和神经网络层如此普遍,现代库也为我们实现了这些组件。
在本节中,我们将向您展示如何使用深度学习框架的高级 API 简洁地实现第 3.2 节中的线性回归模型。
3.3.1 生成数据集
首先,我们将生成与第 3.2 节中相同的数据集 。
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
3.3.2. 读取数据集
我们可以调用框架中现有的 API 来读取数据,而不是滚动我们自己的迭代器。我们传入features和labels作为参数,并batch_size在实例化数据迭代器对象时指定。此外,布尔值is_train指示我们是否希望数据迭代器对象在每个 epoch 上打乱数据(通过数据集)。
def load_array(data_arrays, batch_size, is_train=True): #@save
"""Construct a PyTorch data iterator."""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
现在我们可以使用与我们在第 3.2 节中调用该函数的data_iter方式大致相同的方式 。为了验证它是否正常工作,我们可以读取并打印第一批示例。与3.2 节相比,这里我们使用构造 Python 迭代器并使用从迭代器中获取第一项。
next(iter(data_iter))
[tensor([[-0.4517, -0.3277],
[-0.5566, 0.3060],
[-0.6281, -0.2933],
[ 0.4836, -0.8837],
[ 0.3179, -0.4385],
[ 0.9690, 0.4170],
[ 0.6503, -2.3574],
[-0.1246, 2.4129],
[ 1.6695, 0.8556],
[ 0.1999, -0.3050]]),
tensor([[ 4.4221],
[ 2.0469],
[ 3.9289],
[ 8.1781],
[ 6.3392],
[ 4.7124],
[13.5202],
[-4.2467],
[ 4.6434],
[ 5.6319]])]
3.3.3. 定义模型
当我们在第 3.2 节从头开始实现线性回归时 ,我们明确定义了模型参数并使用基本线性代数运算对计算进行编码以产生输出。你应该知道如何做到这一点。但是一旦你的模型变得更复杂,并且你几乎每天都必须这样做,你会很高兴得到帮助。这种情况类似于从头开始编写自己的博客。做一两次是有益的和有启发性的,但如果每次你需要一个博客,你都花一个月的时间重新发明轮子,那么你将成为一个糟糕的 Web 开发人员。
对于标准操作,我们可以使用框架的预定义层,这使我们能够特别关注用于构建模型的层,而不必专注于实现。我们将首先定义一个模型变量net,它将引用 Sequential该类的一个实例。该类Sequential为将链接在一起的多个层定义了一个容器。给定输入数据, Sequential实例将其通过第一层,然后将输出作为第二层的输入传递,依此类推。在下面的示例中,我们的模型仅包含一层,因此我们并不真正需要Sequential. 但由于我们未来的几乎所有模型都将涉及多个层,我们无论如何都会使用它来让您熟悉最标准的工作流程。
回忆一下单层网络的架构, 如图 3.1.2 所示。该层被称为全连接层, 因为它的每个输入都通过矩阵向量乘法连接到它的每个输出。
在 PyTorch 中,全连接层是在Linear 类中定义的。请注意,我们将两个参数传递给nn.Linear. 第一个指定输入特征维度,即 2,第二个是输出特征维度,它是单个标量,因此为 1。
# `nn` is an abbreviation for neural networks
from torch import nn
net = nn.Sequential(nn.Linear(2, 1))
3.3.4。初始化模型参数
在使用 之前net,我们需要初始化模型参数,例如线性回归模型中的权重和偏差。深度学习框架通常有一个预定义的方法来初始化参数。在这里,我们指定每个权重参数应从均值为 0,标准差为 0.01 的正态分布中随机抽样。偏置参数将被初始化为零。
由于我们在构造时已经指定了输入和输出维度 nn.Linear,现在我们可以直接访问参数来指定它们的初始值。我们首先通过 定位层net[0],即网络中的第一层,然后使用weight.data和 bias.data方法访问参数。接下来我们使用替换方法normal_并fill_覆盖参数值。
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
tensor([0.])
3.3.5 定义损失函数
该类MSELoss计算均方误差。默认情况下,它返回示例的平均损失。
loss = nn.MSELoss()
3.3.6 定义优化算法
Minibatch 随机梯度下降是优化神经网络的标准工具,因此 PyTorch 支持它以及optim模块中该算法的许多变体。当我们实例化一个SGD实例时,我们将指定要优化的参数(可通过我们的网络获得net.parameters()),并使用我们的优化算法所需的超参数字典。小批量随机梯度下降只需要我们设置值lr,这里设置为 0.03。
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
3.3.7。训练
您可能已经注意到,通过深度学习框架的高级 API 来表达我们的模型只需要相对较少的代码行。我们不必单独分配参数、定义损失函数或实现小批量随机梯度下降。一旦我们开始使用更复杂的模型,高级 API 的优势将大大增加。但是,一旦我们准备好所有基本部分,训练循环本身就与我们从头开始实施所有内容时所做的非常相似。
train_data.zero_grad()刷新你的内存,pytorch会记录梯度的数据,所以需要清除:对于一些epoch ,我们将对数据集 ( 对于每个 minibatch,我们都会经历以下步骤:
- 通过调用生成预测
net(X)并计算损失l(前向传播)。 - 通过运行反向传播计算梯度。
- 通过调用我们的优化器来更新模型参数。
为了更好地衡量,我们在每个 epoch 后计算损失并打印它以监控进度。
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f'epoch {
epoch + 1}, loss {
l:f}')
epoch 1, loss 0.000325
epoch 2, loss 0.000103
epoch 3, loss 0.000101
下面,我们比较通过在有限数据上训练学习到的模型参数和生成数据集的实际参数。要访问参数,我们首先访问我们需要的层,net然后访问该层的权重和偏差。与我们从头开始的实现一样,请注意我们的估计参数接近于它们的真实对应物。
w = net[0].weight.data
print('error in estimating w:', true_w - w.reshape(true_w.shape))
b = net[0].bias.data
print('error in estimating b:', true_b - b)
error in estimating w: tensor([ 0.0004, -0.0006])
error in estimating b: tensor([-0.0010])
3.3.8. 概括
-
使用 PyTorch 的高级 API,我们可以更简洁地实现模型。
-
在 PyTorch 中,该data模块提供了数据处理的工具,该nn模块定义了大量的神经网络层和常见的损失函数。
-
我们可以通过用以 . 结尾的方法替换它们的值来初始化参数_。
3.3.9。练习
- 如果我们用 替换
nn.MSELoss(reduction='sum'),nn.MSELoss()我们如何改变代码的学习率以使其表现相同。为什么?
reduction ( string , optional ) – Specifies the reduction to apply to the output: 'none' | 'mean' | 'sum' . 'none' : no reduction will be applied, 'mean' : the sum of the output will be divided by the number of elements in the output, 'sum' : the output will be summed. Note: size_average and reduce are in the process of being deprecated, and in the meantime, specifying either of those two args will override reduction . Default: 'mean'
-
查看 PyTorch 文档以了解提供了哪些损失函数和初始化方法。用 Huber 的损失代替损失。
CLASStorch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction='mean')
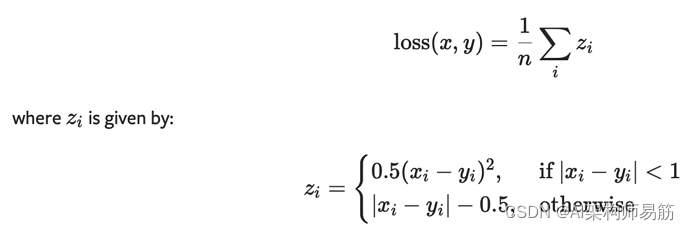
-
你如何访问梯度
net[0].weight?
print(net[0].weight.grad())
For more:
Search for accessing the gradient:https://d2l.ai/chapter_deep-learning-computation/parameters.html
参考
https://d2l.ai/chapter_linear-networks/linear-regression-concise.html