用 AI 托管量产原创韩国女团现场打歌混剪视频?没错可以的。
当下自媒体账号有很多都是发布韩国女团混剪的视频,一方面的受众人群是爱美的女生,看到美美的就很享受。另一方面手中就是宅男和LSP们看韩国女团跟看岛国爱情片差不多一个感觉的。
本身看了那么多混剪的视频发现可以用算法直接融合,再配合上 Python 的 Moviepy 模块直接可以自动生成混剪视频,而且这种生成的混剪视频随机性比较高(当然了绝对是原创),效率也很高(10分钟出一个)。

我用 T-ara 的《Day By Day》现场打歌视频进行试验,已经成功。虽然还有些契合不是很完美的地方,在后续的版本中会更新相应的算法力求达到完美。
目前版本是1.0版本功能有限,未来会继续在更新算法的基础上更新脚本。这里介绍大体的制作思路和方法和原创你们想要问的问题。
既然正儿八经的讲技术没人看那么就做这么一个号试试吧。
软硬件、技能需求
- CPU最好是I7-8750以上,要不整体制作会非常慢
- Python版本3.6以上
- Moviepy模块暂时不支持GPU,因此显卡好坏无视
- 需要会写爬虫,抓视频素材。
- 需要掌握常规的文章洗稿方法,不然视频内容没法做
- 需要掌握常规的window系统操作,否则剪映某些操作无法完成
- 需要会操作Moviepy模块,不会的看我专栏里的对应介绍和操作方法
- 需要1-N个手机号,用于申请百度AI的免费API使用
- 需要有耐心
数据获取
数据获取的话去某管直接下载吧,省去去水印的环节,而且很多片子的质量都很高 1080P 和 2、3、4K 的都很常见。
基础素材准备
这个对于之前《月产10000个中药科普短视频方法,Python编程AI教程》制作的需求素材相对于简单一些。
一个水印就行了,毕竟人家是来听歌看妹子的,乱七八糟的东西加多了反而影响效果。
流程与代码
了解业务处理制作流程有助于理解代码,或者流程了解了代码就很容易。

先看一下整体的工程目录,然后一步一步说。
基础数据应用部分
import os
from moviepy.editor import *
import time
import re
import pandas as pd
import json
import random
import glob
# 字符串时、分、秒转换成秒函数
def str2sec(x):
h, m, s = x.strip().split(':')
return int(h)*3600 + int(m)*60 + int(s)
# 字符串时、分、秒、毫秒转换成秒函数
def str2sec_(x):
if x != "-":
h, m, s = x.strip().split(':')
return str(int(h)*3600 + int(m)*60 + int(s))
else:
return x
# 避免出错生成新的拼接素材清空前面的内容
path = "temp_video/"
for infile in glob.glob(os.path.join(path, '*.mp4')):
os.remove(infile)
# 将所有需要剪辑放到 source_video 文件夹下
video_list = os.listdir("source_video/")
video_list = [i for i in video_list if 'txt' not in i]
video_list = [i for i in video_list if 'xlsx' not in i]
算法自动化整合算法
此处省略一下,用声音的波形算法同步全部视频匹配到一个时间轴上,找到一个基础 base_video(后面会看到,就是主线视频),其他素材视频将时间线根据音频的波形算法匹配到时间线上,自动的加速(素材整体视频时间 < base_video 视频时间) 或者 自动减速(素材整体视频时间 > base_video 视频时间) 操作。
# video_base 基础时间线视频
video_base = random.choice(video_list)
# 在原有的 video_list 剔除 video_base
video_list.remove(video_base)
# 按照 video_base 的时间统一处理其他视频,将时间进行对等
base_duration = locals()[video_base].duration
for each in video_list:
# 计算每个视频的时长
each_duration = locals()[each].duration
# 倍速播放倍数,视频时间/音频时间就是视频加速的时间
factor = each_duration/base_duration
# 倍速播放持续时间 ,可以为空表使全部
final_duration = None
locals()[each] = locals()[each].fx(vfx.speedx,factor,final_duration)
循环创建变量、裁剪、重置分辨率
num_list = list(range(len(data_list)))
video_dict = data_list.to_dict('records')
# 构建变量名称,调用使用 locals()[xxxx]方法
video_list = []
for num,data in zip(num_list,video_dict):
locals()["video_temp_"+str(num)] = VideoFileClip("source_video/"+ data["file_name"])
# 对裁剪视频进行简介操作
# 统一分辨率
locals()["video_temp_"+str(num)] = locals()["video_temp_"+str(num)].resize((1920, 1080))
# 按照字典的起止时间裁剪
start_time = 0 if data["start"] == "-" else data["start"]
end_time = locals()["video_temp_"+str(num)].duration if data["end"] == "-" else data["end"]
# 视频按照裁剪时间重新定义变量
locals()["video_temp_"+str(num)] = locals()["video_temp_"+str(num)].subclip(start_time,end_time)
video_list.append("video_temp_"+str(num))
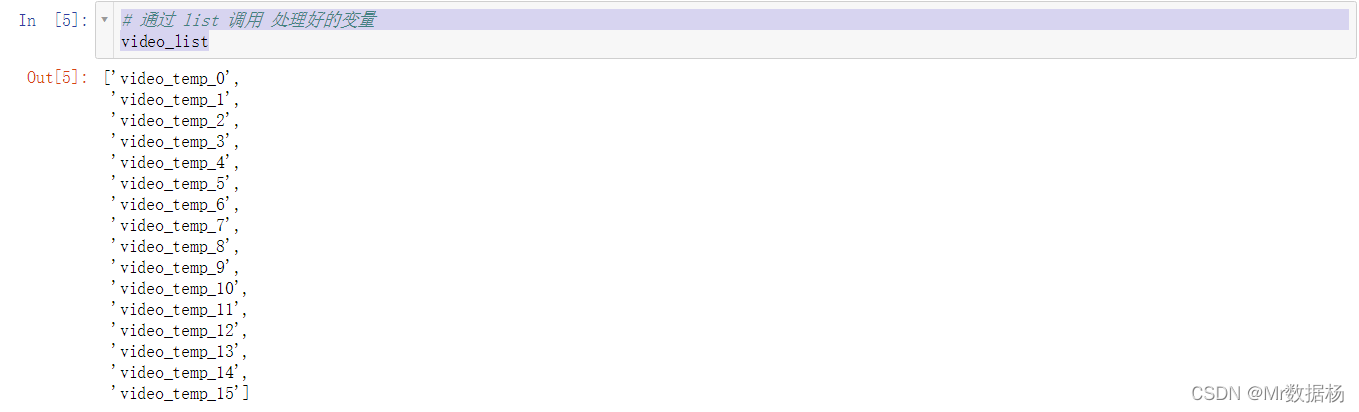
# 通过 list 调用 处理好的变量
video_list
随机开始进行裁剪
time_ = 0
start_time = 0
time_list = [0]
# 判断时间永远小于要做的视频
while time_ <= stop_time:
# 视频随机切割点
cut_time = random.randint(5,15)
start_time = start_time + cut_time
time_list.append(start_time)
# 最终计算变量
time_ = time_ + cut_time
# 剔除超出的部分时间
time_list = time_list[:-2]
# 时间两两组合成需要拆的部分视频
time_list = [time_list[i:i+2] for i in range(0, len(time_list), 1)]
# 为最后一个元素添加 结束时间 stop_time
time_list[-1] = [time_list[-1][0],stop_time]
# 将之前剔除的视频重新添加回来
video_list.append(video_base)
# 将所有片段进行拆分
n = 1
for time_ in time_list:
# cut_video 是视频名称 使用 locals()[cut_video] 调用
cut_video = locals()[random.choice(video_list)]
cut_video = cut_video.subclip(time_[0],time_[1])
# 静音操作
cut_video = cut_video.fx(afx.volumex, 0)
cut_video = cut_video.write_videofile("temp_video/{}.mp4".format(n))
n = n + 1

视频合成
# 对文件进行数字排序避免 1 10 23456789的情况发生顺序错误
each_dir = "temp_video/"
cut_list = sorted(os.listdir(each_dir),key = lambda i:int(re.match(r'(\d+)',i).group()))
# 视频合成 cvc_video
L = []
for i in cut_list:
cut_video = VideoFileClip("temp_video/" + i)
L.append(cut_video)
cvc_video = concatenate_videoclips(L)
# 视频中添加水印
logo = (
ImageClip("./base_data/水印1.png")
.set_duration(cut_video.duration) # 水印持续时间
.resize(height=200) # 水印的高度,会等比缩放
.set_pos(("left", "top")) # 水印的位置
)
# 文件进行保存到结果文件中
cvc = CompositeVideoClip([cvc_video,logo])
# 视频和音频合成在一起
audio = AudioFileClip('temp_data/audio.mp3')
video_result = cvc.set_audio(audio)
video_result.write_videofile("{}.mp4".format(str(int(time.time()))))

按照时间戳生成的不同版本的成品