前言
行人重识别是计算机视觉的基本任务之一,首先要有一个detector(检测器来检测到目标),然后将检测到的目标送入到tracker(追踪器)中,完成对相同目标的判别和追踪。
基于此我们可以将这个技术用于:
1.单摄像头车流量、人流量的计算
2.但摄像头的追踪(徘徊检测)
3.跨摄像头的追踪。
很明显,任务3 要难于任务1, 任务2 是任务1的延续,需要引入一点其它技术。
1、知识体系
1.1 前置说明
DeepSort的前身是sort算法,Sort算法的核心是卡尔曼滤波算法和匈牙利算法。
卡尔曼滤波算法作用:是当前的一系列运动变量去预测下一时刻的运动变量,但是第一次的检测结果用来初始化卡尔曼滤波的运动变量。
匈牙利算法:解决分配问题,就是把一群检测框和卡尔曼预测的框做分配,让卡尔曼预测的框找到和自己最匹配的检测框,达到追踪的效果。本质是维护一个状态矩阵,解决预测框的匹配问题。
1.2 Sort的工作流程
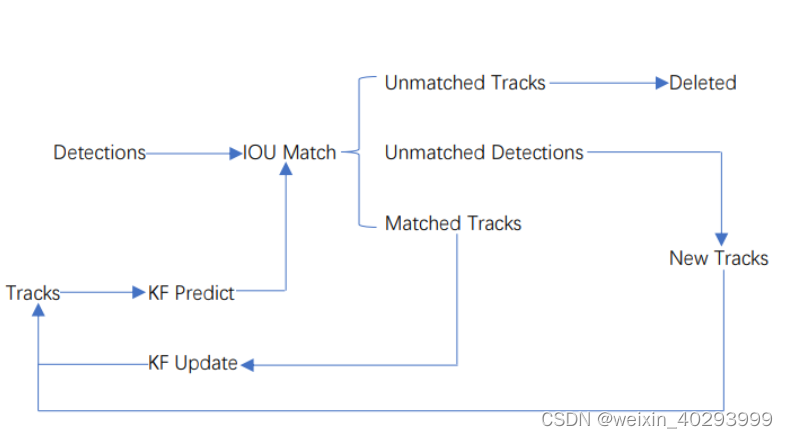
Detections是通过目标检测到的框。Tracks是轨迹信息。
整个算法的工作流程如下:
(1)将第一帧检测到的结果创建其对应的Tracks。将卡尔曼滤波的运动变量初始化,通过卡尔曼滤波预测其对应的框框。
(2)将该帧目标检测的框框和上一帧通过Tracks预测的框框一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(3)将(2)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(4)反复循环(2)-(3)步骤,直到视频帧结束。
印象里这里的预测是线性预测,因为预测器很弱容易产生id switch问题,而且只考虑了运动的关联性特征,没考虑外观特征。这些问题会在deepsort中优化。
1.3 deepsort
。而Deepsort算法在sort算法的基础上增加了级联匹配(Matching Cascade)和新轨迹的确认(confirmed)。Tracks分为确认态(confirmed),和不确认态(unconfirmed),新产生的Tracks是不确认态的;不确认态的Tracks必须要和Detections连续匹配一定的次数(默认是3)才可以转化成确认态。确认态的Tracks必须和Detections连续失配一定次数(默认30次),才会被删除。
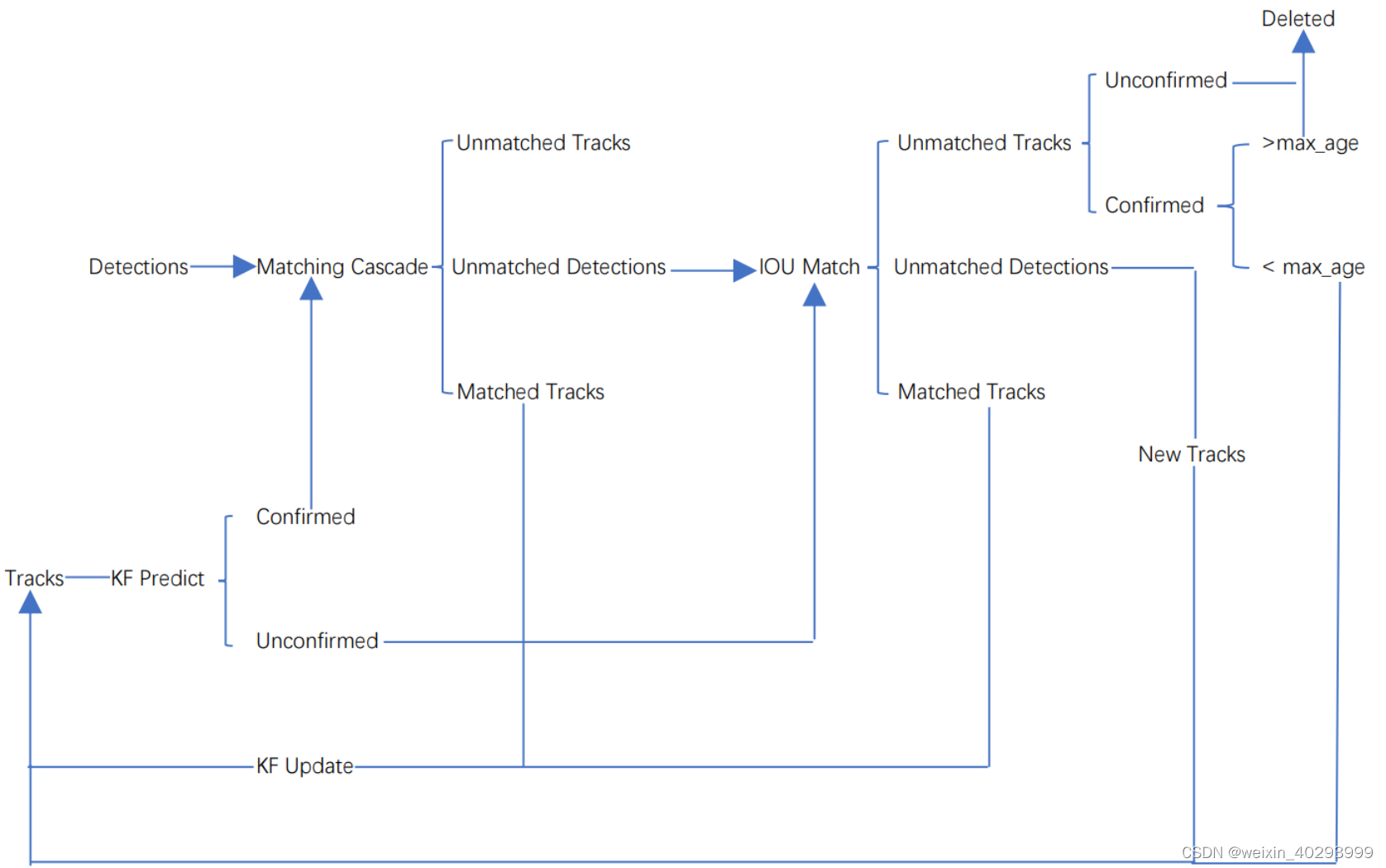
整个算法的工作流程如下:
(1)将第一帧次检测到的结果创建其对应的Tracks。将卡尔曼滤波的运动变量初始化,通过卡尔曼滤波预测其对应的框框。这时候的Tracks一定是unconfirmed的。
(2)将该帧目标检测的框框和第上一帧通过Tracks预测的框框一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(3)将(2)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks(因为这个Tracks是不确定态了,如果是确定态的话则要连续达到一定的次数(默认30次)才可以删除)删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(4)反复循环(2)-(3)步骤,直到出现确认态(confirmed)的Tracks或者视频帧结束。
(5)通过卡尔曼滤波预测其确认态的Tracks和不确认态的Tracks对应的框框。将确认态的Tracks的框框和是Detections进行级联匹配(之前每次只要Tracks匹配上都会保存Detections其的外观特征和运动信息,默认保存前100帧,利用外观特征和运动信息和Detections进行级联匹配,这么做是因为确认态(confirmed)的Tracks和Detections匹配的可能性更大)。
(6)进行级联匹配后有三种可能的结果。第一种,Tracks匹配,这样的Tracks通过卡尔曼滤波更新其对应的Tracks变量。第二第三种是Detections和Tracks失配,这时将之前的不确认状态的Tracks和失配的Tracks一起和Unmatched Detections一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(7)将(6)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks(因为这个Tracks是不确定态了,如果是确定态的话则要连续达到一定的次数(默认30次)才可以删除)删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(8)反复循环(5)-(7)步骤,直到视频帧结束。
2. 实践应用
代码在我的git仓库:https://github.com/justinge/yolov5-deepsort
里面的readyme要看一下,都可以跑的通。 单摄像头的计数很容易的。
还可以配合我之前的文章:https://blog.csdn.net/weixin_40293999/article/details/127811380
总结
关于跨摄像头的追踪,我还没有想出好办法来,先留个坑。