前言
本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见1000个问题搞定大数据技术体系
目录
Spark RDD 论文详解(五)实现
Spark RDD 论文详解(六)评估
Spark RDD 论文详解(七)讨论
Spark RDD 论文详解(八)相关工作和结尾
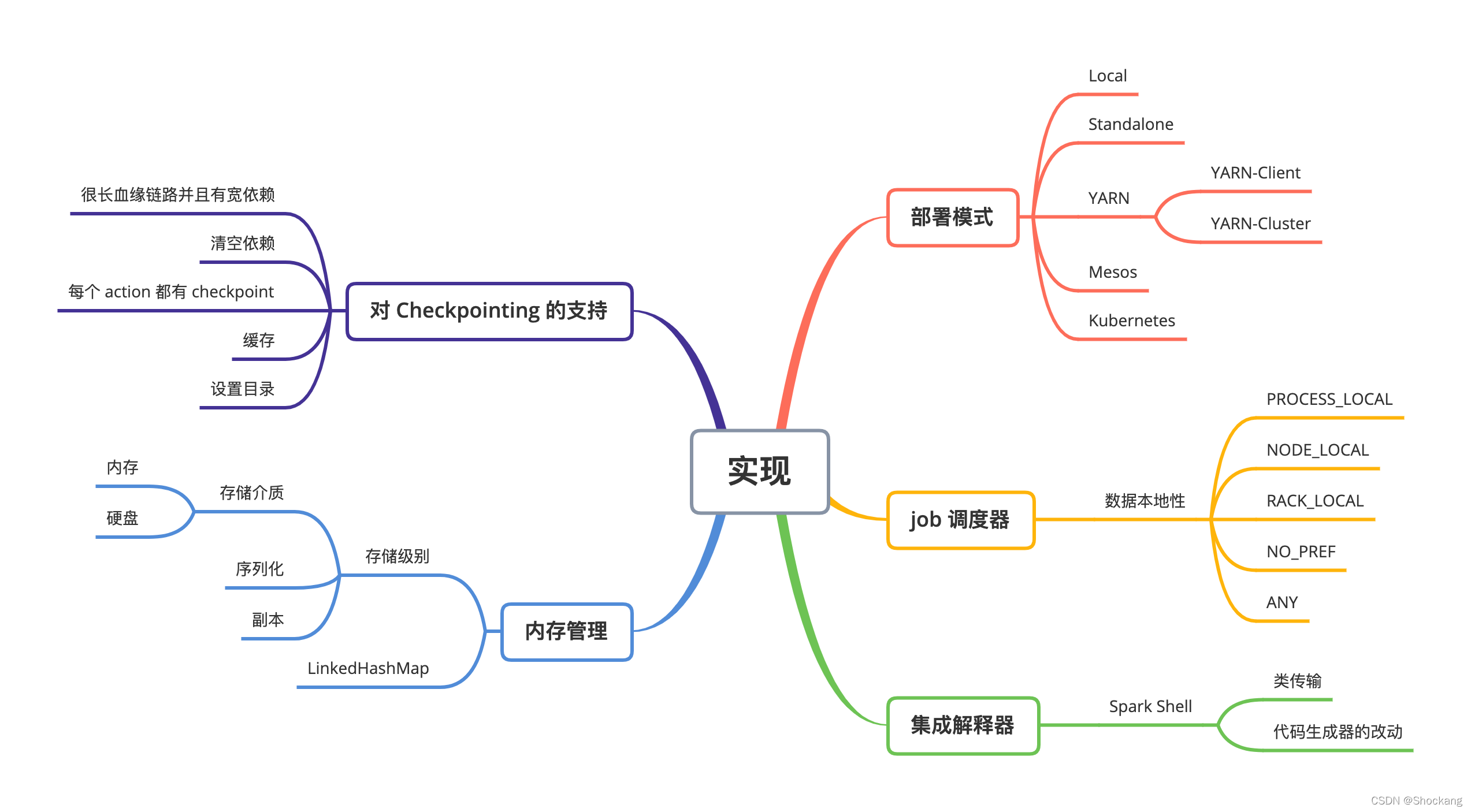
思维导图
正文
5、实现
原文翻译
我们用了 14000 行 scala 代码实现了 spark。
Spark 系统跑在集群管理者 mesos 上,这样可以使的它和其他的应用比如 hadoop 、 MPI 等共享资源,每一个 spark 程序都是由它的 driver 和 workers 组成,这些 driver 和 workers 都是以一个 mesos 应用运行在 mesos 上的,mesos 可以管理这些应用之间的资源共享问题。
Spark 可以利用已经存在的 hadoop 的 api 组件读取任何的 hadoop 的输入数据源(比如:HDFS 和 Hbase 等),这个程序 api 是运行在没有更改的 scala 版本上。
我们会简要的概括下几个比较有意思的技术点:我们的 job 调度器(5.1 节),可以用于交互的 Spark 解释器(5.2 节),内存管理(5.3 节)以及对 checkpointing 的支持(5.4 节)。
解析
Spark 支持多种部署模式,包括:
- Local
- Standalone
- YARN-Client
- YARN-Cluster
- Mesos
- Kubernetes
其中 Local 模式主要用于本地开发测试。
Standalone 模式和 YARN 模式都可以用于生产环境,一般情况下,如果不是同一个集群中同时存在多种类型的计算任务(比如你既想要 Spark 来进行批处理,又想要 Flink 来流处理),单纯的 Standalone 模式已经能够满足生产环境的需求。
YARN 模式分为两种,即 YARN-Client 和 YARN-Cluster ,区别在于 Driver 的位置。
YARN-Client 模式,Driver 在客户端机器上面,就是不在 YARN 集群里面,应用运行结果在客户端会有显示,也就是说你可以用 Spark UI 来观测。
YARN-Cluster 模式,Driver 在 YARN 集群里面,受到 ResourceManager 的统一管理。
Mesos 用的比较少,相比 YARN 突出的特点是可以进行细粒度的管理。
Kubernetes 模式是云计算背景下诞生的,也是未来的主流方向之一。
可以通过我的这篇博客了解 Kubernetes 《Kubernetes 是什么?》
5.1 job 调度器
原文翻译
Spark 的调度器依赖我们在第 4 章中讨论的 RDDs 的表达。
从总体上看,我们的调度系统有点和 Dryad 相似,但是它还考虑了被存储的 RDDs 的哪些分区还在内存中。
当一个用户对某个 RDD 调用了 action 操作(比如 count 或者 save)的时候调度器会检查这个 RDD 的血缘关系图,然后根据这个血缘关系图构建一个含有 stages 的有向无环图(DAG),最后按照步骤执行这个 DAG 中的 stages,如图 5 的说明。
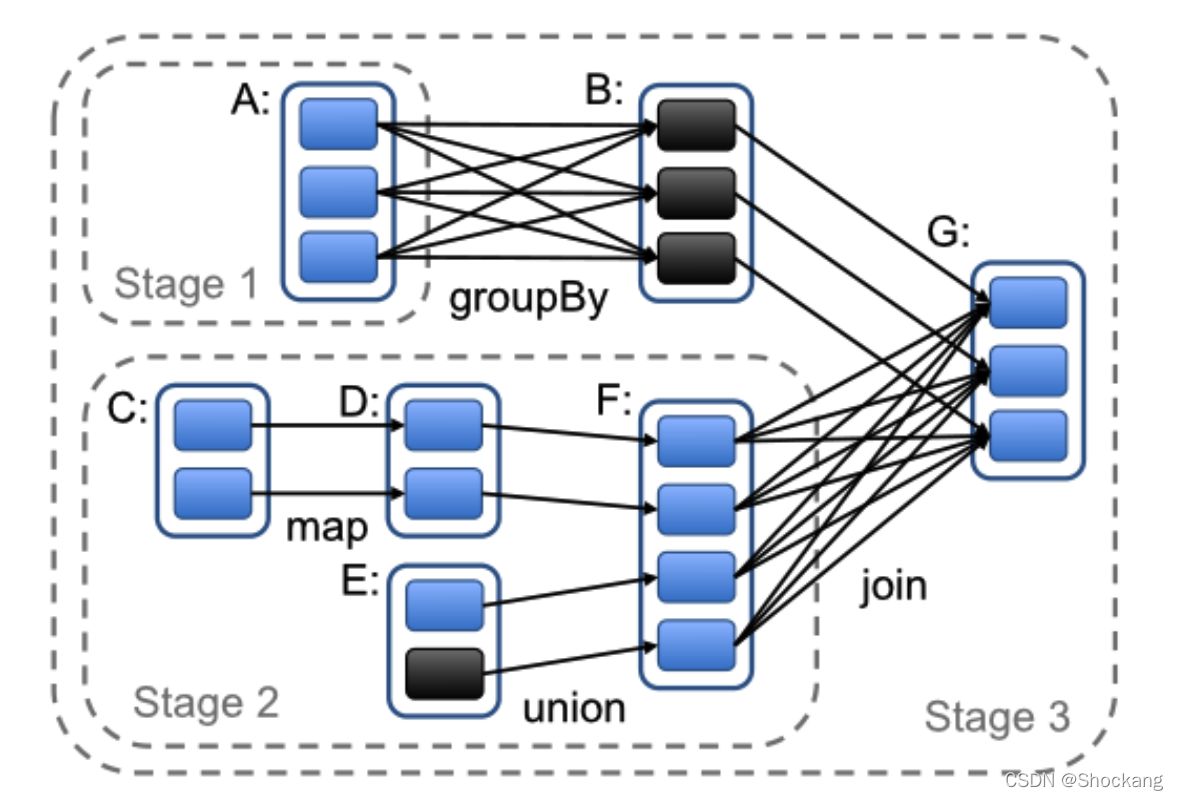
图五:怎么计算 spark job stage 的例子。实现的方框表示 RDDs ,带有颜色的方形表示分区,黑色的是表示这个分区的数据存储在内存中,对 RDD G 调用 action 操作,我们根据宽依赖生成很多 stages,且将窄依赖的 transformations 操作放在 stage 中。在这个场景中,stage 1 的输出结果已经在内存中,所以我们开始运行 stage 2,然后是 stage 3。
每一个 stage 包含了尽可能多的带有窄依赖的 transformations 操作。
这个 stage 的划分是根据需要 shuffle 操作的宽依赖或者任何可以切断对父亲 RDD 计算的某个操作(因为这些父亲 RDD 的分区已经计算过了)。
然后调度器可以调度启动 tasks 来执行没有父亲 stage 的 stage(或者父亲 stage 已经计算好了的 stage),一直到计算完我们的最后的目标 RDD 。
我们调度器在分配 tasks 的时候是采用延迟调度来达到数据本地性的目的(说白了,就是数据在哪里,计算就在哪里)。
可以参考我的这篇博客来理解——为什么说数据不动代码动?移动计算比移动数据更划算?
如果某个分区的数据在某个节点上的内存中,那么将这个分区的计算发送到这个机器节点中。
如果某个 RDD 为它的某个分区提供了这个数据存储的位置节点,则将这个分区的计算发送到这个节点上。
对于宽依赖(比如 shuffle 依赖),我们将中间数据写入到节点的磁盘中以利于从错误中恢复,这个和 MapReduce 将 map 后的结果写入到磁盘中是很相似的。
只要一个任务所在的 stage 的父亲 stage 还是有效的话,那么当这个 task 失败的时候,我们就可以在其他的机器节点中重新跑这个任务。
如果一些 stages 变的无效的话(比如因为一个 shuffle 过程中 map 端的一个输出结果丢失了),我们需要重新并行提交没有父亲 stage 的 stage(或者父亲 stage 已经计算好了的 stage)的计算任务。
虽然备份 RDD 的血缘关系图比较容易,但是我们不能容忍调度器调度失败的场景。
虽然目前 Spark 中所有的计算都是响应 driver 程序中调用的 action 操作,但是我们也是需要尝试在集群中调用 lookup 操作,这种操作是根据 key 来随机访问已经 hash 分区过的 RDD 所有元素以获取相应的 value。
在这种场景中,如果一个分区没有计算的话,那么 task 需要将这个信息告诉调度器。
解析
Spark 中调度任务的优先级是这样的:
PROCESS_LOCAL > NODE_LOCAL > RACK_LOCAL > NO_PREF > ANY
- PROCESS_LOCAL 代表数据和计算在同一个进程中,不需要跨进程的。但是要注意一点,很多资料书上面都没有提及到,要想达到 PROCESS_LOCAL ,你得先
缓存,试想一下,你不缓存,怎么去利用这份数据来进行计算呢?
常见的缓存手段有:DataFrame的 API : df.cache() 和 df.persist(),Spark SQL 的 cache table 等。另外要注意,针对 RDD 的 API: rdd.cache() 和 rdd.persist() ,Spark SQL 的缓存管理器:
CacheManager是不认的。
缓存可以触发 PROCESS_LOCAL,但是 PROCESS_LOCAL 不一定必须要缓存,比如广播就是 PROCESS_LOCAL。
还要注意一点,你缓存得触发物化操作才能生效,不然直接就 pipeline 了,不会驻留在 内存/硬盘 里面的。常见的物化操作就是 count。
- NODE_LOCAL 代表数据和计算在同一个节点上面,这时虽然会跨进程,但是不会产生网络传输,最多就从一个端口传递到另一个端口,此时的用户态和系统态内存的切换也是不小的开销。
- RACK_LOCAL 代表数据和计算在同一个机架上面,你可以查看我的这篇博客了解详情——《提到HDFS就会想到机架感知,那么机架感知你真的知道是什么吗?》
- NO_PREF 实际上是 no preference 的缩写,就是没有偏好的意思。这通常出现在数据存放在外部数据源的场景。
- ANY 这种情况就很糟糕了,代表着跨机架的数据传输,交换机的开销可不小。
最后再提醒一点,调度任务在任何情况下第一优先级肯定考虑的是 PROCESS_LOCAL。但是资源是有限的,假设你要计算的数据存放的那台节点上面 CPU 都挂满了,你把计算再发给它有用吗?所以,此时一个比较适当的操作就是等一等!
有人可能会问:要是内存也满了咋办?内存要满了就放到硬盘上面啊,当然要视你的存储策略而定,你要是 MEMORY_AND_DISK 那就放硬盘吧,要是 MEMORY 那就不妙了,意味着此时部分数据可能会抛弃,根据LRU算法来腾出内存来,具体的细节后面有时间写篇博客再详解。
这时候就和几个 Spark 配置参数有关系了:
| Spark配置参数 | 默认值 | 说明 |
|---|---|---|
| spark.locality.wait | 3s | 在放弃并在非本地节点上启动数据本地任务之前,需要等待多长时间才能启动该任务。相同的等待将用于逐步通过多个本地级别(PROCESS_LOCAL、NODE_LOCAL、RACK_LOCAL,然后是 ANY)。还可以通过设置spark.locality.wait.node 来自定义每个级别的等待时间等。如果任务很长且局部性较差,则应增加此设置,但默认设置通常效果良好。 |
| spark.locality.wait.node | spark.locality.wait | 自定义设置 NODE_LOCAL 的本地等待事件。例如,您可以将其设置为0,以跳过节点位置并立即搜索机架位置(如果您的集群具有机架信息)。 |
| spark.locality.wait.process | spark.locality.wait | 自定义设置 PROCESS_LOCAL 的本地等待时间。这会影响在特定 Executor 进程中尝试访问缓存数据的任务。 |
| spark.locality.wait.rack | spark.locality.wait | 自定义设置 RACK_LOCAL 的本地等待时间。 |
5.2 集成解释器
原文翻译
scala 和 Ruby 以及 Python 一样包含了一个交互型的 shell 脚本工具。
考虑到利用内存数据可以获得低延迟的特性,我们想让用户通过解释器来交互性的运行 Spark,从而达到查询大数据集的目的。
Scala 解释器通常是将用户输入的每一行代码编译成一个类,然后将这个类加载到 JVM 中,然后调用这个类的方法。
这个类中包含了一个单例对象,这个单例对象包含了用户输入一行代码中的变量或者函数,还包含了一个运行用户输入那行代码的初始化方法。
比如,用户输入 var x = 5,然后再输入 println(x),scala 解释器定义个包含了 x 的叫做 Line 1 的类,然后将第二行代码编译成 println(Line 1.getInstance(). x )。
我们对 Spark 中的解释器做了如下两个改变:
类传输
为了让 worker 节点能拿到用户输入的每一行代码编译成的 class 的二进制代码,我们使的解释器为这些 classes 的二进制代码提供 HTTP 服务。
代码生成器的改动
正常情况下,我们通过访问对应的类的静态方法来达到访问将用户输入每一行代码编译成的单例对象。
这个意味着,当我们将一个含有在前面行中定义的变量(比如上面例子中的 Line 1.x)的闭包序列化发送到 worker 节点的时候,java 是不会通过对象图来跟踪含有 x 的 Line 1 实例的,这样的话 worker 节点将收不到变量 x。
我们修改了代码生成逻辑实现了直接引用每一行代码生成的实例。
图六显示了经过我们的改变后,解释器是如何将用户输入的一系列的代码转换成 java 对象。
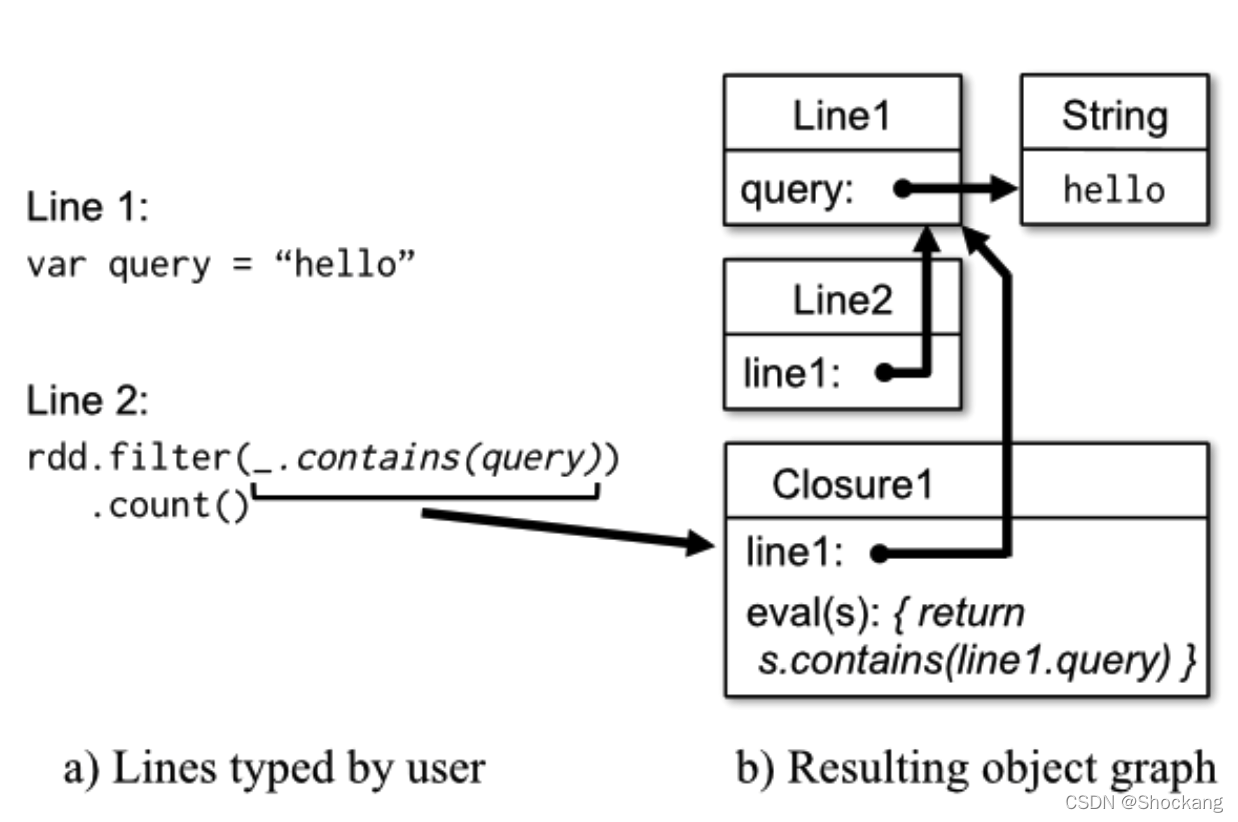
图六:显示 spark 解释器是如何将用户输入的代码转换成 java 对象的例子
我们发现 Spark 解释器在处理我们研究中获取到的大量痕迹数据以及探索存储在 HDFS 中的数据集时是非常有用的。
我们正在打算用这个来实现更高层面的交互查询语言,比如 SQL。
解析
关于 Spark SQL 的发展请参考我的这篇博客——《Spark SQL是怎么发展起来的?》
5.3 内存管理
原文翻译
Spark 在持久化 RDDs 的时候提供了 3 种存储选择:
- 存在内存中的非序列化的 java 对象
- 存在内存中的序列化的数据
- 存储在磁盘中
第一种选择的性能是最好的,因为 java VM 可以很快的访问 RDD 的每一个元素。
第二种选择是在内存有限的情况下,使的用户可以以很低的性能代价而选择的比 java 对象图更加高效的内存存储的方式。
如果内存完全不够存储的下很大的 RDDs,而且计算这个 RDD 又很费时的,那么选择第三种方式。
为了管理有限的内存资源,我们在 RDDs 的层面上采用 LRU(最近最少使用)回收策略。
当一个新的 RDD 分区被计算但是没有足够的内存空间来存储这个分区的数据的时候,我们回收掉最近很少使用的 RDD 的分区数据的占用内存,如果这个 RDD 和这个新的计算分区的 RDD 是同一个 RDD 的时候,我们则不对这个分区数据占用的内存做回收。
在这种情况下,我们将相同的 RDD 的老分区的数据保存在内存中,这样可以避免重新计算这些分区的数据,这是非常重要的,因为很多操作都是对整个 RDD 的所有的 tasks 进行计算的,所以非常有必要将后续要用到的数据保存在内存中。
到目前为止,我们发现这种默认的机制在所有的应用中工作的很好,但是我们还是将持久每一个 RDD 数据的策略的控制权交给用户。
最后,在一个集群中的每一个 Spark 实例的内存空间都是分开的,我们以后打算通过统一内存管理达到在 Spark 实例之间共享 RDDs。
解析
存储级别
Spark 中的存储级别有以下几个:
| 存储级别 | 含义解释 |
|---|---|
| MEMORY_ONLY | 使用未序列化的Java对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。那么下次对这个RDD执行算子操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用cache()方法时,实际就是使用的这种持久化策略。 |
| MEMORY_AND_DISK | 使用未序列化的Java对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个RDD执行算子时,持久化在磁盘文件中的数据会被读取出来使用。 |
| MEMORY_ONLY_SER | 基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| MEMORY_AND_DISK_SER | 基本含义同MEMORY_AND_DISK。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| DISK_ONLY | 使用未序列化的Java对象格式,将数据全部写入磁盘文件中。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2 | 对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。如果没有副本的话,就只能将这些数据从源头处重新计算一遍了。 |
记起来也很简单,主要从 3 个方面来记忆就行了:
- 存储介质(内存还是硬盘)
- 序列化
- 副本
LinkedHashMap
Spark 使用了一个巧妙的数据结构:LinkedHashMap 来实现内存的回收,这种数据结构天然地支持 LRU 算法。
LinkedHashMap 使用两个数据结构来维护数据,一个是传统的 HashMap,另一个是双向链表。
HashMap 的用途在于快速访问,根据指定的 BlockId,HashMap 以 O(1) 的效率返回内存数据 MemoryEntry。
双向链表则不同,它主要用于维护元素(也就是 BlockId 和 MemoryEntry 键值对)的访问顺序。
凡是被访问过的元素,无论是插入、读取还是更新都会被放置到链表的尾部。
因此,链表头部保存的刚好都是“最近最少访问”的元素。
5.4 对 Checkpointing 的支持
原文翻译
虽然我们总是可以使用 RDDs 的血缘关系来恢复失败的 RDDs 的计算,但是如果这个血缘关系链很长的话,则恢复是需要耗费不少时间的。
因此,将一些 RDDs 的数据持久化到稳定存储系统中是有必要的。
一般来说,checkpointing 对具有很长的血缘关系链且包含了宽依赖的 RDDs 是非常有用的,比如我们在 3.2.2 小节中提到的 PageRank 的例子。
在这些场景下,集群中的某个节点的失败会导致每一个父亲 RDD 的一些数据的丢失,进而需要重新所有的计算。
与此相反的,对于存储在稳定存储系统中且是窄依赖的 RDDs(比如 3.2.1 小节中线性回归例子中的 points 和 PageRank 中的 link 列表数据),checkpointing 可能一点用都没有。
如果一个节点失败了,我们可以在其他的节点中并行的重新计算出丢失了数据的分区,这个成本只是备份整个 RDD 的成本的一点点而已。
Spark 目前提供了一个 checkpointing 的 api(persist 中的标识为 REPLICATE,还有 checkpoint()),但是需要将哪些数据需要 checkpointing 的决定权留给了用户。
然而,我们也在调查怎么样自动的 checkpoing,因为我们的调度系统知道数据集的大小以及第一次计算这个数据集花的时间,所以有必要选择一些最佳的 RDDs 来进行 checkpointing,来达到最小化恢复时间。
最后,需要知道的是 RDDs 天生的只读的特性使的他们比一般的共享内存系统做 checkpointing 更简单了。
因为不用考虑数据的一致性,我们可以不终止程序或者拍摄快照,只需要在后台将 RDDs 的数据写入到存储系统中。
解析
- checkpoint 适合那些很长血缘链路并且有宽依赖的 RDDs,并且 checkpoint 会清空这个 RDD 所有的父依赖,想想也是,依赖本来就是用于容错恢复的,在怎么容错恢复哪比得上 checkpoint 的稳定存储啊。
- Spark 自动在每一个 job 之后添加了 checkpoint 操作,因为一个 action 操作会触发一个 job,也就代表每一个 action 操作之后就会有 checkpoint 的产生。
- 如果对某一个 RDD 或者 Dataset 进行 checkpoint 的话,最好要对它进行
缓存,因为 pipeline 机制的存在,数据不会主动驻留在内存里面,这也就代表,你还得重新从数据源再计算一遍,造成很大的额外开销。 - 关于 checkpoint 还有一个注意事项,你必须事先设置 checkpoint 的目录,不然程序会报错。