转载自:https://blog.csdn.net/zhaojw_420/article/details/53261965
一、基本RDD
1、针对各个元素的转化操作最常用的转化操作是map()和filter()。转化操作map()J接收一个函数,把这个函数用于RDD中的每一个元素,将函数的返回结果作为结果RDD中对应元素。而转化操作filter()则接收一个函数,将RDD满足该函数的元素放入新的RDD中返回。map()的返回值类型不需要和输入类型一样。
从一个RDD变成另外一个RDD。lazy,懒执行 。比如根据谓词匹配筛选数据就是一个转换操作。
例:求平均值
Scala:
val input=sc.parallelize(List(1,2,3,4))
val result=input.map(x=>x*x)
println(result.collect().mkString(","))java:
@Test
public void rddSquare(){
SparkConf sparkConf = new SparkConf().setAppName( "JavaWordCount");
JavaSparkContext sc = new JavaSparkContext( sparkConf);
JavaRDD<Integer> rdd= sc.parallelize(Arrays. asList(1,2,3,4));
JavaRDD<Integer> result= rdd.map( new Function<Integer, Integer>() {
@Override
public Integer call(Integer x ) throws Exception {
return x *x ;
}
});
System. err.println(StringUtils.join( result.collect(), ""));
}flatMap()方法可以实现对每个输入元素生成多个输出元素,返回一个返回值序列的迭代器。其一个简单用途就是把输入的字符串切分为单词。
Scala:
val lines=sc.parallelize(List("hello word","hi","I'm back"))
val words=lines.flatMap(line=>line.split(" "))
words..first()Java:
@Test
public void rddFlatMap(){
JavaRDD<String> lines= sc.parallelize(Arrays.asList( "hello word","hi" ,"i am back"));
JavaRDD<String> words= lines.flatMap( new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line ) throws Exception {
return Arrays.asList( line.split( " ")).iterator();
}
});
System. err.println(words .first());
}flatMap()和map()方法的区别:flatMap()相当于看作返回来的迭代器的“压扁”,这样就得到一个由各个列表中的元素组成的RDD。
例如:
map()的结果:{[“coffe”,”panda”],[“happy”,”panda”],[“happies”,”panda”,”party”]}
flatMap()的结果:{“coffe”,”panda” ,”happy”,”panda” ,”happies”,”panda”,”party” }
filter()操作不会改变已有的inputRDD中的数据。
通过转化操作,从已有的RDD中派生出新的RDD,spark会使用谱系图来记录这些不同RDD之间的依赖关系。spark需要用这些信息来按需计算每个RDD,也可以依靠谱系图在持久化的RDD丢失部分数据时恢复所丢失的数据。
Scala:
val inputRDD=sc.textFile("log.txt")
val errorRDD=inputRDD.filter(line=>line.contains("error"))Java:
JavaRDD<String> inputRDD=sc.textFile("log.txt");
JavaRDD<String> errorRDD=inputRDD.filter(
new Function<String,Boolean>(){
public Boolean call(String x){
return x.contains("error");
}
}
);filter()操作不会改变已有的inputRDD中的数据。
通过转化操作,从已有的RDD中派生出新的RDD,spark会使用谱系图来记录这些不同RDD之间的依赖关系。spark需要用这些信息来按需计算每个RDD,也可以依靠谱系图在持久化的RDD丢失部分数据时恢复所丢失的数据。
2、伪集合操作
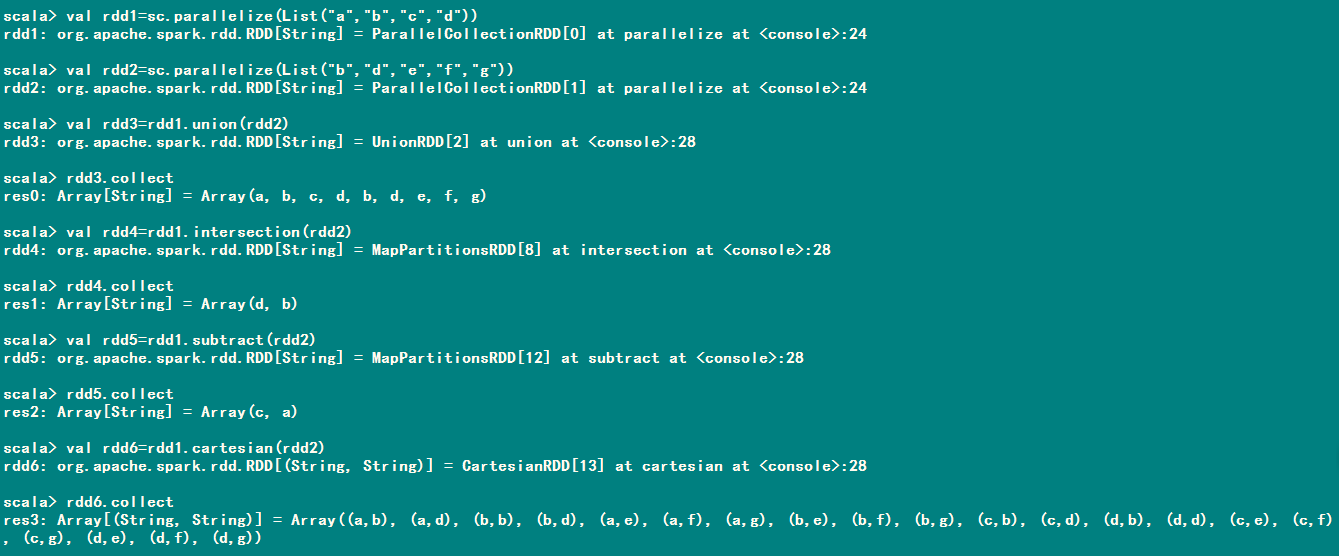
RDD.distinct()方法转换操作生成一个只包含不同元素的一个新的RDD。开销很大。
RDD.union(otherRDD),会返回一个包含两个RDD中所有元素的RDD,包含重复数据。
RDD.intersection(otherRDD),只返回两个RDD中都有的元素。可能会去掉所有的重复元素。通过网络混洗来发现共有元素。
RDD.subtract(otherRDD)返回只存在第一个RDD中而不存在第二个RDD中的所有的元素组成的RDD。也需要网络混洗。
RDD.cartesian(otherRDD),计算两个RDD的笛卡尔积,转化操作会返回所有可能的(a,b)对,其中a是源RDD中的元素,而b则来自于另一个RDD。
对一个数据为{1,2,3,3}的RDD进行操作进行基本的RDD转化操作
3、行动操作
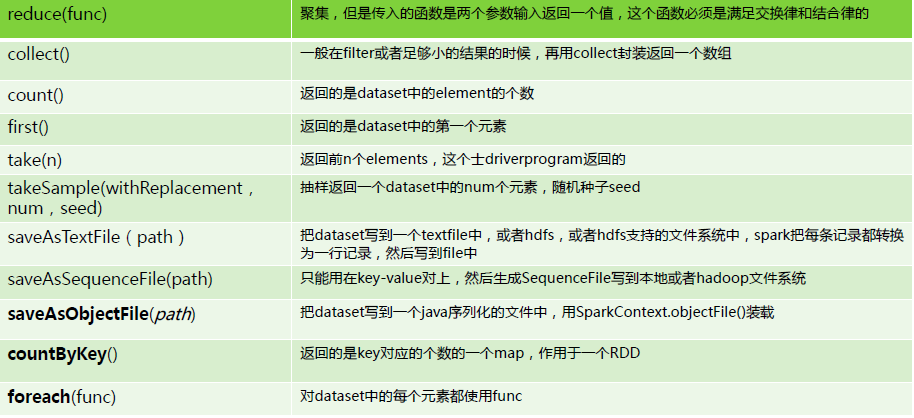
RDD最常见的行动操作:reduce()操作,它接受一个函数作为参数,这个函数要操作两个相同类型的RDD数据并返回一个同样类型的新元素。
reduce将RDD中元素两两传递给输入函数,同时产生一个新的值,新产生的值与RDD中下一个元素再被传递给输入函数直到最后只有一个值为止。
行动操作会对RDD计算一个结果,并把结果返回到驱动程序中,或把结果存储到外部存储系统中(如HDFS)中。
Scala:

val rdd=sc.parallelize(List(1,2,3,3))
val sum=rdd.reduce((x,y)=>x+y)Java:

/**
* java中的reduce()方法
*/
public void testReduce(){
JavaRDD<Integer> rdd= sc.parallelize(Arrays.asList(1,2,3,3));
Integer sum= rdd.reduce( new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer x , Integer y ) throws Exception {
return x +y ;
}
});
System. err.println(sum );
}flod()方法与reduce()方法类似,接受一个与redce()接受的函数相同的函数,再加上一个“初始值”来作为分区第一次调用时的结果。
两者都要求函数的返回值类型需要和我们所操作的RDD中的元素类型相同。
aggregate()函数则把我们从返回值类型必须与所操作的RDD类型相同的限制中解放出来。可以计算两个RDD的平均值。
Scala:
val rdd=sc.parallelize(List(1,2,3,4,5,6))
val result=rdd.aggregate((0,0))((acc,value)=>(acc._1+value,acc._2+1),(acc1,acc2)=>(acc1._1+acc2._1,acc1._2+acc2._2))
val avg=result._1/result._2.toDoubleJava:
public class AvgCount implements Serializable {
private static final long serialVersionUID = 1L;
private final static SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount" );
private final static JavaSparkContext sc = new JavaSparkContext( sparkConf);
public int total ;
public int num ;
public AvgCount(int total , int num) {
this. total = total;
this. num = num;
}
public double avg(){
return total /(double)num;
}
static Function2<AvgCount,Integer,AvgCount> addAndCount=
new Function2<AvgCount, Integer, AvgCount>() {
@Override
public AvgCount call(AvgCount a , Integer x ) throws Exception {
a. total+= x;
a. num+=1;
return a ;
}
};
static Function2<AvgCount, AvgCount, AvgCount> combine=
new Function2<AvgCount, AvgCount, AvgCount>() {
@Override
public AvgCount call(AvgCount a , AvgCount b ) throws Exception {
a. total+= b. total;
a. num+= b. num;
return a ;
}
};
public static void main(String[] args) {
AvgCount initial= new AvgCount(0, 0);
JavaRDD<Integer> rdd= sc.parallelize(Arrays.asList(1,2,3,4,5,6));
AvgCount result= rdd.aggregate( initial, addAndCount, combine );
System. err.println(result .avg());
}
}collect()方法会返回整个RDD的内容。测试中使用。RDD内容不多。
take(n)返回RDD的第n个元素。并且尝试只访问尽量少的分区,因此该操作会得到一个不均衡的集合。可能返回的元素会跟预期的不太一样。
top()按照RDD元素的顺序,返回RDD的前几个元素。
first()就是一个行动操作,他会返回RDD的第一个元素。
触发计算,进行实际的数据处理
Scala:
print "input had "+badLinesRDD.count()+" concering lines"
print "Here are 10 examples:"
for line in badLinesRDD.take(10).foreach(println)Java:
System.out.println("input had "+badLinesRDD.count()+" concering lines" );
System.out.print("Here are 10 examples:" );
for(Sring line:badLinesRDD.take(10)){
System.out.println(line);
}对一个数据为{1,2,3,3}的RDD进行基本的RDD行动操作如表:。
两者的区别在于Spark计算RDD的方式不同。虽然你可以在任何时候去定义新的RDD,但Spark只会惰性计算这些RDD,他们只有在第一次在一个行动操作中用到时,才会真正计算。
二、在不同RDD类型间转换
在Scala中将RDD转为特定函数的RDD是由隐式转换自动处理的。需要加上import org.apache.spark.SparkContext._来使用在这些隐式转换。这些隐式转换可以隐式的将一个RDD转换为各种封装,比如DoubleRDDFunctions(数值数据的RDD)和PairRDDFunction(键值对RDD)。
在Java中有两个专门的类JavaDoubleRDD和JavaPairRDD,来处理特殊类型的RDD。
Java中针对专门类型的函数接口:

/**
* java创建DoubleRDD
* @author Administrator
*
*/
public class DoubleRDD implements Serializable {
private static final long serialVersionUID = 1L;
private final static SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount" );
private final static JavaSparkContext sc = new JavaSparkContext( sparkConf);
public void testDoubleRDD(){
JavaRDD<Integer> rdd= sc.parallelize(Arrays.asList(1,2,3,4,5));
JavaDoubleRDD result= rdd.mapToDouble( new DoubleFunction<Integer>() {
private static final long serialVersionUID = 1L;
@Override
public double call(Integer x) throws Exception {
return (double )x *x ;
}
});
System. err.println(result );
}
}三、持久化(缓存)
当我们让Spark持久化存储一个RDD时,计算出RDD的节点会分别保存他们所有求出的分区数据。如果一个有持久化数据的节点发生故障,spark会在需要用到的缓存数据时重算丢失的数据分区。可以把数据备份到多个节点上。
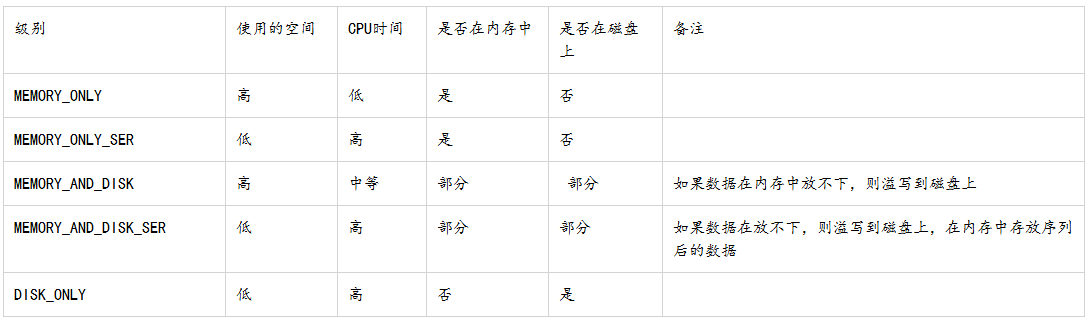
在scala和java中,默认情况下persist()会把数据以序列化的形式缓存到JVM的堆空间中。
org.apache.spark.storage.StorageLevel和py.StorageLevel中的持久化级别;如有必要可以通过在存储级别的末尾加上”_2”来把持久化数据存为两份:
在Scala中使用persist();
import org.apache.spark.storage.StorageLevel
val result=input.map(x=>x*x)
result.persist(StorageLevel.DISK_ONLY)
println(result.count())
println(result.collect().mkString(","))在第一次对这个RDD调用行动操作前就调用了persist()方法,persist()调用本身不会触发强制求值。
如果缓存的数据太多,内存中放不下,Spark会自动利用最近最少使用(LRU)的缓存策略把最老的分区从内存中移除。当然对于使用内存和磁盘缓存级别的分区来说,移除的数据会写如磁盘。
最后,还可以使用unpersist()方法手动把持久化的RDD从缓存中移除。
cache()方法,是延迟执行,需要在一个action执行之后,进行缓存RDD。是persist特殊缓存方式。将RDD放入内存中,缓存级别是MEMORY_ONLY