内容:
- 什么是图像,数字图像
- 图像处理方式分类
- 数字图像处理核心技术

- x,y:空间域坐标
z:表达立体
λ:表达颜色
t:表达活动
数字图像:空间域离散、幅度上量化的图像、将模拟图像经过空间域采样,幅度上量化,即可得到数字图像
图像类型:
- 1.二值图像:整个图像里只有两个亮度值
2. 黑白图像:二值图像的特例,两个亮度值分别为0和255
3. 灰度图像:亮度值0-255(没有颜色)
4. 彩色图像:每个图像除了亮度还有色彩
5. 点云图像:主要表达三维图像
6. 彩色图像+深度图像:表达三维图像
7. 多光谱图像:常见于遥感图像
图像处理方法分类:
- 光学图像处理
- 模拟电信号图像处理
- 数字图像处理
数字图像处理
定义:依托数值计算设备如计算机,以数值计算方式对数字化的图像进行处理。
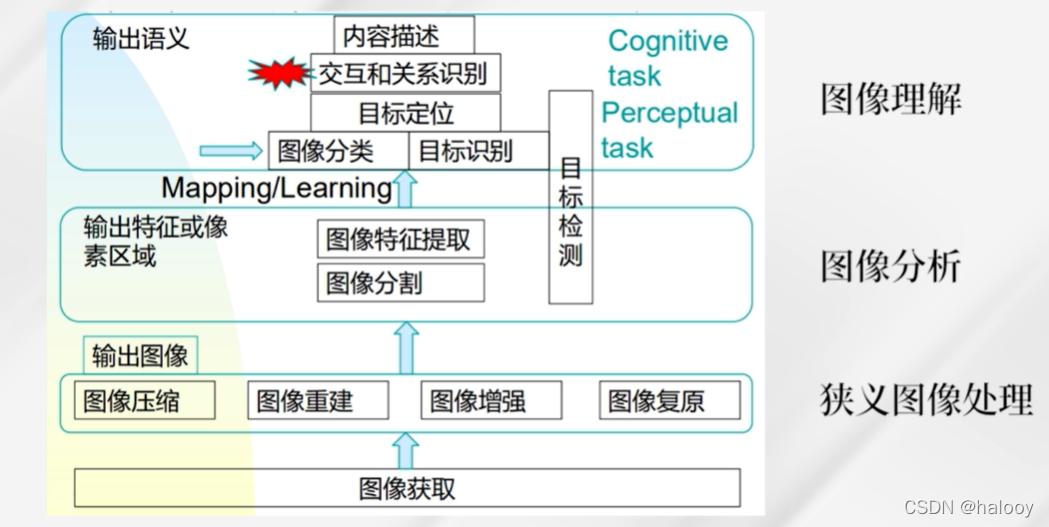
图像处理的三个层面:
- 狭义图像处理:输入图像,输出图像。(像素级的处理)
- 图像分析:输入图像,输出特征参数。(不同区域的颜色特征、形状特征、位置特征、纹理特征等)把不同区域表达为不同的特征向量。
- 图像理解:输入图像,输出语义、语言
数字图像技术的发展
-
图像获取(Image Acquisition)
利用图像采集设备获取一幅图像 。
模拟图像:视觉传感器–CCD、CMOS;
数字图像:视觉传感器+数字化器。数字化器包括采样和量化两部分 -
图像增强(Image enhancement)
面向某一目标对图像感兴趣的部分进行处理,以改善图像的视觉质量。
面向目标,不考录降质原因(基于人类主观偏好)设计方法;
方法设计更主观
处理结果图像存在局部优化的特点 -
图像复原(Image restoration)
对于降质图像去除其降质因素,尽可能恢复图像的本来面目。
面向原因,对图像降质过程求逆。
方法设计更客观
处理结果图像存在全局优化的特点
两大难点:降质过程建模(由结果估计过程),求逆运算。 -
图像重建(Image reconstruction)
图像重建即由投影数据重建图像的技术。对于一些三维(二维)物体其内部内容未知,通过其他手段获取其投影数据,由投影数据重建出三维数据(二维图像)。

-
图像压缩(Image compression)
图像压缩又称图像编码,即去除图像冗余,减少图像表示的数据量,一边节省图像传输、处理时间及存储容量。- 图像压缩包括有损压缩编码(Lossy)和无损压缩编码(Lossless)两大类。
无损压缩:可以无失真的重构原始图像,但压缩比较地,一般为2-3;通常具有重要的保存价值的图像如医学图像、遥感图像等采用无损压缩。
有损压缩:重构图像与原始图像存在误差,但很多时候视觉感知上与原始图像差别不大。有损压缩的图像压缩比较高,日常生活图像多为有损压缩图像。
图像压缩标准:
JPEG,JPEG LS,JPEG2000
- 图像压缩包括有损压缩编码(Lossy)和无损压缩编码(Lossless)两大类。
-
图像分割(Image Segmentation)
把图像分成若干个特定的、具有独特性质的区域的技术。图像分割是由狭义图像处理到图像分析理解的关键步骤。是像素级处理到高层语义理解的关键环节。 -
图像特征提取(Image(Object)Feature Extraction)
对图像分割得到的每个区域提取其特征并形成特征表示向量。
常见特征:
1.形状特征:获取描述物体形状的特征空间并进行映射,常见由几何参数、圆度、傅里叶形状描述子、形状不变等;
2.纹理特征:获取描述物体内部纹理的特征空间并进行映射,常见有灰度共生矩阵、LBP等
3.颜色特征:获取描述物体颜色统计特性或颜色分布的特征空间并进行映射,常见有颜色直方图、主颜色、主颜色分布等;
4.深度特征:通过深度学习获取描述物体的特征并进行映射 -
图像(对象)识别、分类(Image(Object)Recognition)
- 根据区域的特征通过学习将其映射为区域所对应的语义概念,是由图像底层特征到语义概念映射的过程,这是一个典型的模式识别问题;
- 通常的学习是基于有限种类的目标进行学习,因此目前的目标识别任务的本质等价于目标分类;
- 传统层次化方法:分割/检测–》特征提取–》识别;
- 深度学习:端到端
-
目标(对象)检测(Object Detection)
- 自动判断图像中是否存在指定一个或多个类别对象,并在图片中标记其位置,目标检测是一个从像素到语义对象的过程,
- 目标检测需要从像素级特征到语义对象并给出其位置,因此存在一个由底层特征到高层语义的映射过程,某种程度上一次性完成了分割–》特征提取–》对象识别系列任务。
-
视觉关系表达(Visual Relation representation)
表示一对对象之间的空间位置关系、交互关系等。
位置关系挑战在于由二维图像估计三维空间位置关系存在一定的歧义;
交互关系本质上是将两个对象用动词连接起来;
同样的两个对象可能由不同的交互关系; -
行为识别(Action Recognition)
即基于对象之间的交互关系对对象的行为进行识别(分类)
有些行为有时域动态特征,因此基于视频才能完成;有些行为可以从一幅关键帧图像直接得到;
行为包括个体行为和群体行为,个提醒各位和群体行为有关系也有区别; -
图像内容描述(Image Caption)
对一幅输入图像自动生成一段语言文字来描述图像内容,类似于看图说话。
图像内容描述是图像理解的最高境界,其包含了对象空间位置关系描述,对象交互关系描述,而且还要主义描述语言的流畅性,语句之间的转折连贯关系等,因此是图像理解和自然语言处理的交叉与综合。