本文主要介绍如何利用Xgboost+LR构建分类模型,基于真实案例用R语言来实现该算法。
一、算法原理
Xgboost可以用来构造新特征变量,而LR则可以把原始特征和新特征集合起来构造模型,并计算各特征的显著性和权重系数。
二、利用R构造Xgboost模型
原始数据,数据框格式,8个自变量,1个因变量,训练集共200万+数据,测试集90万+数据。
# 利用xgboost包的xgb.create.features构造新特征变量
library(xgboost)
traindata1 <- data.matrix(traindata[,c(1:8)]) # 将自变量转化为矩阵
library(Matrix)
traindata2 <- Matrix(traindata1,sparse=T) # 利用Matrix函数,将sparse参数设置为TRUE,转化为稀疏矩阵
traindata3 <- as.numeric(as.character(traindata[,9])) # 将因变量转化为numeric
traindata4 <- list(data=traindata2,label=traindata3) # 将自变量和因变量拼接为list
dtrain <- xgb.DMatrix(data = traindata4$data, label = traindata4$label) # 构造模型需要的xgb.DMatrix对象,处理对象为稀疏矩阵
testset1 <- data.matrix(testset[,c(1:8)]) # 将自变量转化为矩阵
testset2 <- Matrix(testset1,sparse=T) # 利用Matrix函数,将sparse参数设置为TRUE,转化为稀疏矩阵
testset3 <- as.numeric(as.character(testset[,9])) # 将因变量转化为numeric
testset4 <- list(data=testset2,label=testset3) # 将自变量和因变量拼接为list
dtest <- xgb.DMatrix(data = testset4$data, label = testset4$label) # 构造模型需要的xgb.DMatrix对象,处理对象为稀疏矩阵
param <- list(max_depth=2, eta=1, silent=1, objective='binary:logistic') # 定义模型参数
nround = 4
bst = xgb.train(params = param, data = dtrain, nrounds = nround, nthread = 2) # 构造xgboost模型
new.features.train <- xgb.create.features(model = bst, traindata4$data) # 生成xgboost构造的新特征组合,训练集
new.features.test <- xgb.create.features(model = bst, testset4$data) # 生成xgboost构造的新特征组合,测试集
newdtrain <- as.data.frame(as.matrix(new.features.train)) # 将训练集的特征组合转化为dataframe格式
newdtest <- as.data.frame(as.matrix(new.features.test)) # 将测试集的特征组合转化为dataframe格式
newtraindata <- cbind(newdtrain,backflag1=traindata$backflag) # 将训练集的自变量和因变量合并
newtestdata <- cbind(newdtest,backflag1=testset$backflag) # 将测试集的自变量和因变量合并
model <- xgb.dump(bst,with_stats = T) # 显示计算过程,查看树结构
model
names <- dimnames(data.matrix(traindata[,c(1:8)]))[[2]] # 获取特征的真实名称
importance_matrix <- xgb.importance(names,model=bst) # 计算变量重要性
xgb.plot.importance(importance_matrix[,])模型共构造了4颗树,其中一棵树的树结构如下图所示。

Xgboost模型构造了13个新特征变量,第一个数字代表第几棵树,第二个数字代表叶子节点。

# 第一次构造LR模型
fit <- glm(y ~ .,newtraindata, family=binomial())
summary(fit)
# 第二次构造LR模型,剔除P值大于0.05的变量
fit <- glm(y ~ x1 + x3 + x4 + x5 + x6 + x7 + x8 + V13 + V15 + V24 + V25 + V26 + V34 + V35 + V36 + V44 + V46, newtraindata, family=binomial())
summary(fit)
最终入选变量如下所示:
# 对训练集进行预测
pred <- predict(fit,newtraindata,type='response') # 选定type为response则返回响应变量的预测概率,值在0-1之间
pred <- data.frame(predict(fit,newtraindata,type='response'))
# 计算ROC,方法一
library(pROC)
xgb_lr.train.modelroc <- roc(newtraindata$backflag1, pred)
plot(xgb_lr.train.modelroc,print.auc=TRUE,auc.polygon=TRUE,grid=c(0.1,0.2),
grid.col=c("green","red"),max.auc.polygon=TRUE,auc.polygon.col="skyblue",print.thres=TRUE)
# 计算ROC,方法二
library(ROCR)
predict <- prediction(pred$predict.fit..newtraindata.,newtraindata$backflag1)
pref <- performance(predict,"tpr","fpr")
plot(pref,colorize=T)
# 计算AUC
auc <- performance(predict, measure = "auc")
auc <- [email protected][[1]]
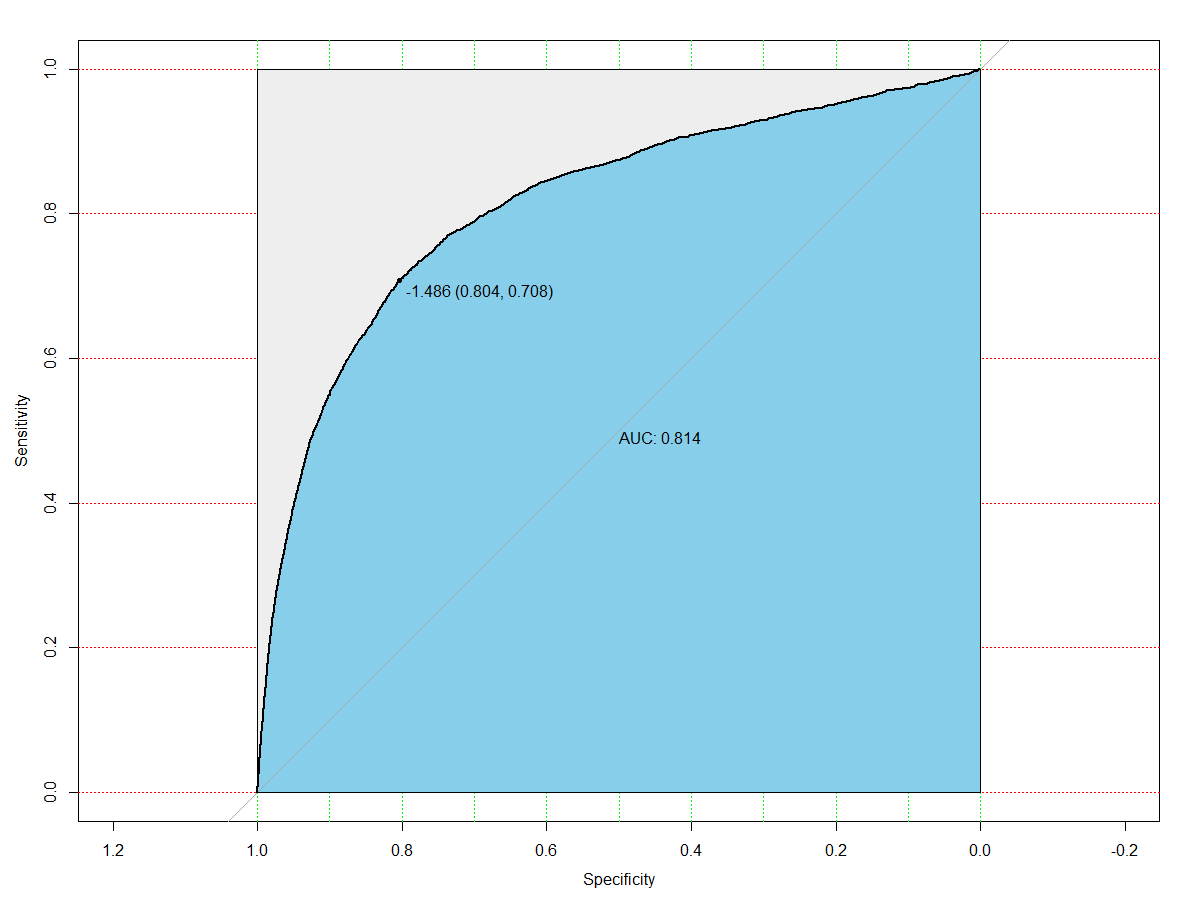
auc计算出来测试集的ROC图如下所示,AUC值为0.814。训练集的ROC和AUC同理可得。
# 计算混淆矩阵
confusion <- data.frame(pred)
confusion$pred <- ifelse(confusion$pred>0.5,1,0)
xgb_lr.train.result <- table(newtraindata$backflag1, confusion$pred)
xgb_lr.train.result
# 计算准确率
(xgb_lr.train.result[1,1]+xgb_lr.train.result[2,2])/nrow(newtraindata)
# 训练集精确度、召回率
xgb_lr.train.result[2,2]/(xgb_lr.train.result[1,2]+xgb_lr.train.result[2,2]) # 精确度
xgb_lr.train.result[2,2]/(xgb_lr.train.result[2,1]+xgb_lr.train.result[2,2]) # 召回率
# 测试集精确度、召回率
xgb_lr.test.result[2,2]/(xgb_lr.test.result[1,2]+xgb_lr.test.result[2,2]) # 精确度
xgb_lr.test.result[2,2]/(xgb_lr.test.result[2,1]+xgb_lr.test.result[2,2]) # 召回率根据混淆矩阵,计算模型训练集的准确率为77.68%,精确度为80.17%,召回率为78.96%。