本文提供作者:小鱼很想写代码(掘金)
觉得文章写的好,请给戳↑链接关注作者,给文章点个赞嗷~
摸鱼学习交流请戳:https://shimo.im/sheets/CtcH8VR9rV8vGVdv/MODOChttps://shimo.im/sheets/CtcH8VR9rV8vGVdv/MODOC![]() https://shimo.im/sheets/CtcH8VR9rV8vGVdv/MODOC
https://shimo.im/sheets/CtcH8VR9rV8vGVdv/MODOC
【前言】
在以前的java学习过程中,我们知道java 把内存划分成两种:一种是栈内存,另一种是堆内存。在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配。恰好在最近的学习过程中,了解了一些关于JavaScript中的内存机制,故在这里做一做分享,欢迎各位大佬在评论区交流指正。
本文主要讲诉以下内容:
- 关于JavaScript的语言类型
- 什么是执行上下文
- JavaScript的内存机制
- 为什么要分栈和堆?
- 堆栈与闭包之间的关系
【正文】
关于JavaScript的语言类型
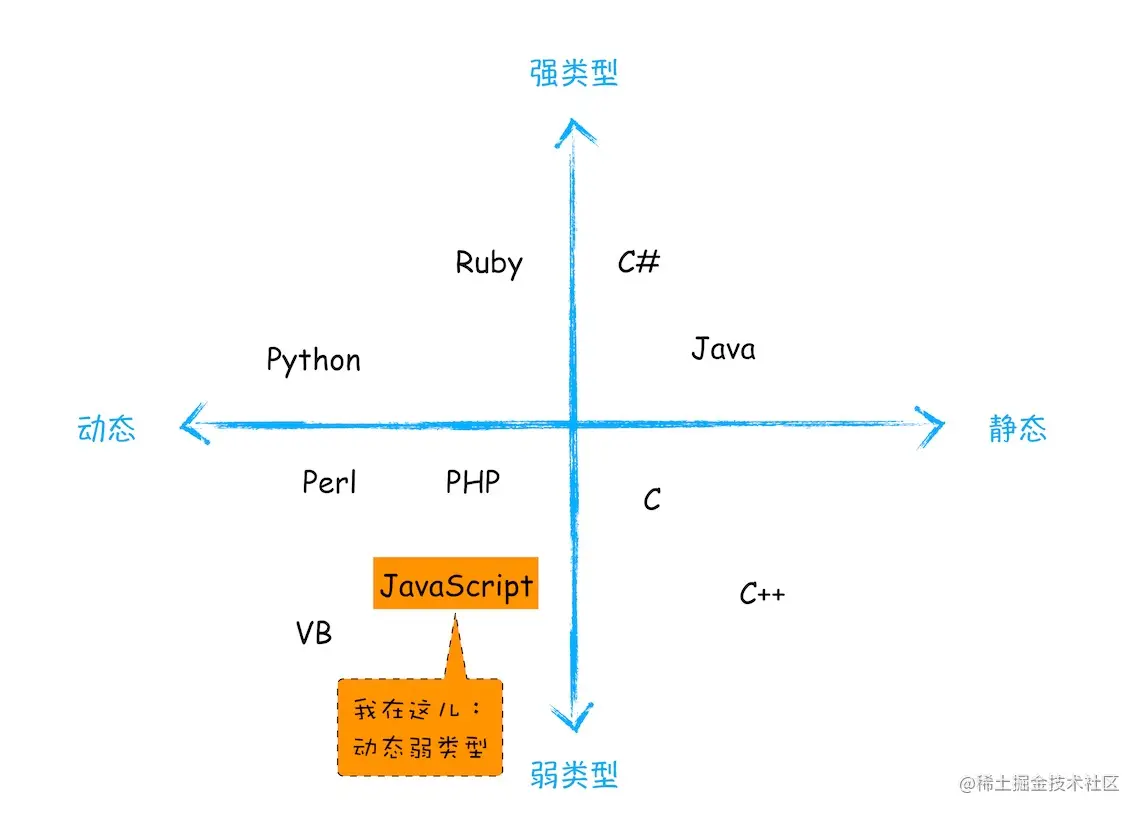
在讲述JavaScript的内存机制之前,我们先聊一下JavaScript这门语言类型。我们都知道语言分为强语言、弱语言、动态语言、静态语言,它们分别有着各自的特色。在使用之前需要确认其变量类型的语言是静态语言,而在动态语言中,运行过程当中需要检查数据类型,我们可以用一个变量来保存不同类型的数据。而支持隐式类型转换的语言称为弱类型语言,什么是隐式类型转换呢?例如C语言中可以将int类型转换为布尔类型,这就是隐式类型转换,而JavaScript和C语言一样都是属于弱语言,在JavaScript中我们并不需要对声明变量的类型,因为引擎(v8)在运行时会自动检查其数据类型并识别出来。这里我们引用一张图方便理解
什么是执行上下文
执行上下文是对JavaScript中的代码被解析和执行时所在环境的抽象概念,任何代码都是在执行上下文中运行的。 JavaScript中的执行上下文主要分为三种类型:

- 全局执行上下文:基础的上下文,所有不在函数内部的代码都在全局上下文中,一个程序只有一个全局上下文
- 函数上下文:函数被调用时, 都会为该函数创建一个新的上下文。每个函数都有它自己的执行上下文,一个程序可以有多个函数上下文
- Eval 函数执行上下文 : 执行在 eval 函数内部的代码也会有它属于自己的执行上下文,与本文无关 不多阐述
在下面的内容中,我们会大量用到执行上下文这个概念
JavaScript的内存机制
在本文的前言中,我们提到了Java这门语言的内存机制分为了堆和栈,JavaScript的内存机制也一样分为了堆和栈,但它和Java还是存在区别的。JavaScript中的栈只会存放一些原始类型的小数据,例如 Undefined、Null、Boolean、Number 和 String、Symbol等等,而在JavaScript中的堆中,则是用来存放引用类型,例如Object, Array, Function等,其数据存储在堆空间中,只在栈空间内存储了相对应的引用地址。
下面我们通过代码和图片来分析JavaScript中的调用栈过程:
function foo(){
var a =1 //原始类型
var b =a
a = 2
console.log(a);//2
console.log(b);//1
}
foo()
function bar(){
var c = {name:'张三'} //对象类型
var d = c
c.name ="李四"
console.log(c);//李四
console.log(d);//李四
}
bar()我们可以看到第一段代码中,我们对b赋值为a,然后改变了a的值,但是输出的结果中,b的值却仍是a原来的值1。在第二段代码中,同样是对c赋值更改为李四,但是输出的c、d却都是同样的值,这是为何呢?下面我们通过图片来进行分析:

首先当JavaScript引擎第一次遇到你的代码时时,它会创建一个全局的执行上下文并且压入当前执行栈。每当引擎遇到一个函数调用,它会为该函数创建一个新的执行上下文并压入栈的顶部。也就是图中的foo函数执行上下文,一个程序只有一个全局执行上下文,但可以有多个函数执行上下文,它们在栈中都遵循“后进先出”的规则。
由图我们可以看到,此时引擎遇到了我们的代码,它创建了一个全局执行上下文并按照规则压入了栈的底端,之后继续向下走,分别遇到了foo函数和bar函数,生成了两个函数执行上下文,在图中我们写在一起(懒得重新画图了,这里其实应该是两个分开的函数执行上下文,bar在foo上方),由于a赋值为1,它是原始类型,所以a的数据储存在栈当中,我们将b赋值为a其实是深拷贝,所有原始值的赋值都是深拷贝,此时b拿到了a的值1,拿到值1的b与a此时已经没有关系了,它们是独立的个体,只是此时指向同一个地址所以拿到的值都是1,所以后面我们将a的值改为2,此时a指向了一个新的地址,拿到了2的值,而b还指向原来的地址,也就是1所存放的地方,这里放张图便于理解。
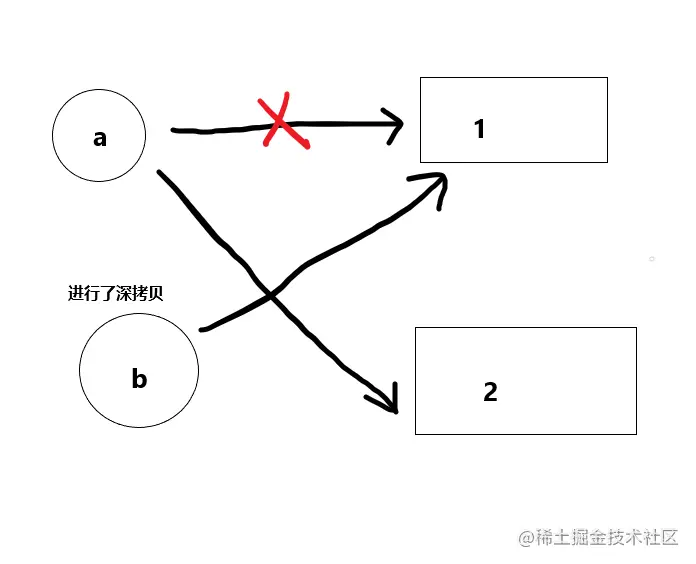
接着我们看到bar函数的执行上下文,可知c是对象类型,它的值存在堆当中,在栈中仅保留了引用地址1002,而此时对d赋值一个对象类型的值,这个叫做浅拷贝。浅拷贝复制了其引用地址1002。但后文对其修改name的值,是修改堆中的数据,c和d的引用地址1002都未发生改变,所以最后c和d都输出了李四。
这便是JavaScript中的内存机制,将不同类型的数据放于不同的位置,那么,这么做的意义是什么呢?
为什么要分栈和堆?
我们不由得发问,虽然我们搞懂了JavaScript的内存机制,但这样做的意义是什么呢?所有的数据直接存放在栈当中可不可以呢?
答案显然是不可以的。JavaScript引擎需要用栈来维护程序执行期间的上下文状态(环境),如果栈过大,所有数据都放在栈里面,栈里面的数据取用特别不方便,会影响上下文的切换效率,由于是数据是存放在栈当中的,先编译先入栈,后编译后入栈,执行完要进行销毁操作,但这样的话先进栈的函数执行上下文要等后进栈的函数执行上下文销毁完才能销毁,如果栈过大,就影响了上下文的切换效率,进而影响整个程序的执行效率。
堆栈与闭包之间的关系
我们直接看到下面这串代码:
function foo() {
var myName = '钉钉' //在堆里面
let test1 = 1 //在堆里面
const test2 = 2 //在栈里面
var innerBar = {
setName: function(newName) {
myName = newName //引用了外部变量
},
getName: function() {
console.log(test1); //引用了外部变量
return myName
}
}
return innerBar
}
var bar = foo()
bar.setName('涛')
console.log(bar.getName());在这我们可以很清晰的知道,这段代码中,形成了一个闭包。那么,在这闭包情况下,其代码内的值得空间分配和普通情况下有什么不同呢?我们可以看到,代码中得myName、test1、test2都是原始类型得变量,按我们前面所说得JavaScript分配机制来看,它们应该都储存在栈当中,但是结果并不这样得。这三个变量中只有test2在栈里面储存。 因为被闭包引用的变量会去到堆里的一个叫做closure的闭包对象里面去,并且将数据存在里面,而在栈中只留下一个引用地址指向这个堆里的闭包对象。由于闭包的原因,这个foo的执行上下文不能被销毁,所以栈内的test2仍在栈中,但是我们并不能在外面调用到它了,但它确实是存在的。