一、大数据的特征
4V特征
Volume(大数据量):90% 的数据是过去两年产生
Velocity(速度快):数据增长速度快,时效性高
Variety(多样化):数据种类和来源多样化
结构化数据、半结构化数据、非结构化数据
Value(价值密度低):需挖掘获取数据价值
固有特征
时效性
不可变性
二、关于hadoop
hadoop是如何进行分布式处理呢?
1.数据存储:分布式存储,分成多块存储
2.存储结束后,进行分布式数据的处理
说了这么多,什么是hadoop?
Hadoop是一个开源分布式系统架构
分布式文件系统HDFS——解决大数据存储
分布式计算框架MapReduce——解决大数据计算
分布式资源管理系统YARN
处理海量数据的架构首选
非常快得完成大数据计算任务
已发展成为一个Hadoop生态圈
hadoop又有哪些优点是我们使用它的理由呢?
高扩展性,可伸缩
高可靠性
多副本机制,容错高
低成本
无共享架构
灵活,可存储任意类型数据
开源,社区活跃
看一下hadoop的生态圈吧,百度这些知识点,可以更加有效的有针对性的去学习!
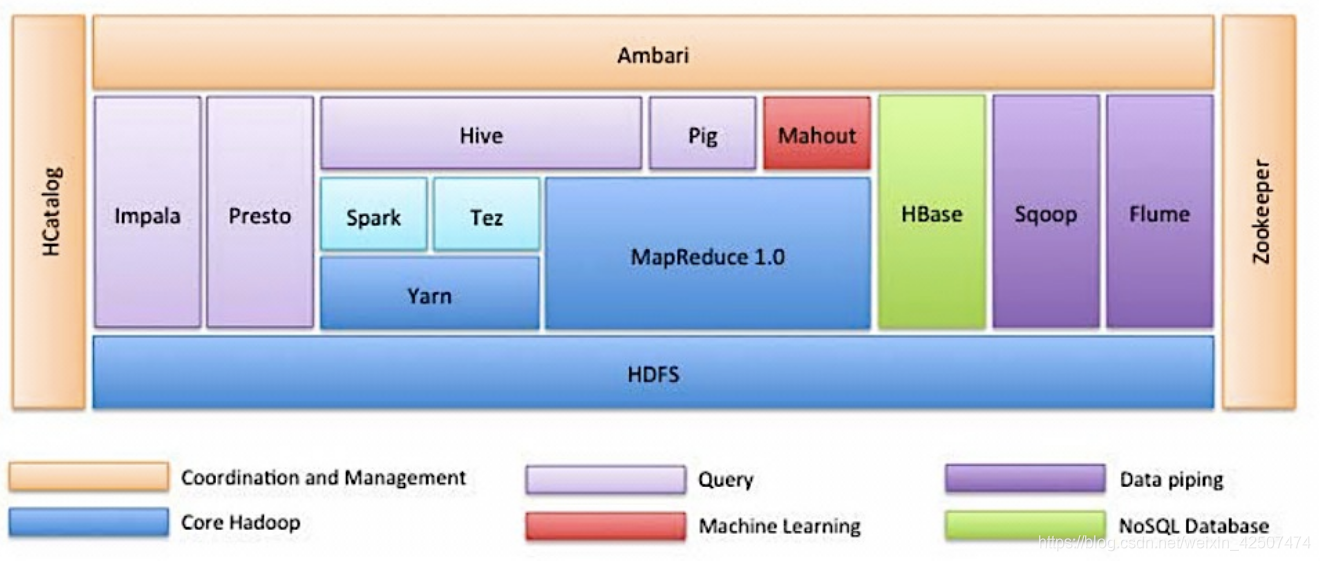
稍作分类:
Hadoop核心
HDFS、MapReduce、YARN
数据查询分析
Hive、Pig、Impala、Presto
协调管理
HCatalog、Zookeeper、Ambari
数据迁移
Sqoop、Flume
Spark、NoSQL、机器学习、任务调度等
由这些介绍可以更加有针对性的对自己想要工作的地方学习!
三、hadoop的结构
HDFS(Hadoop Distributed File System)
分布式文件系统,解决分布式存储
MapReduce
分布式计算框架
YARN
分布式资源管理系统
在Hadoop 2.x中引入
Common
支持所有其他模块的公共工具程序
了解完这些基本知识后,我们就要开始进一步的有针对性的学习!下一篇会进行关于hadoop的单机搭建和集群构造!