1.Java主流锁的整体认知
话不多说,直接上图,先对Java主流锁有一个整体的认知

2.乐观锁悲观锁概念
悲观锁与乐观锁是一种广义概念,体现的是看待线程同步的不同角度
2.1乐观锁
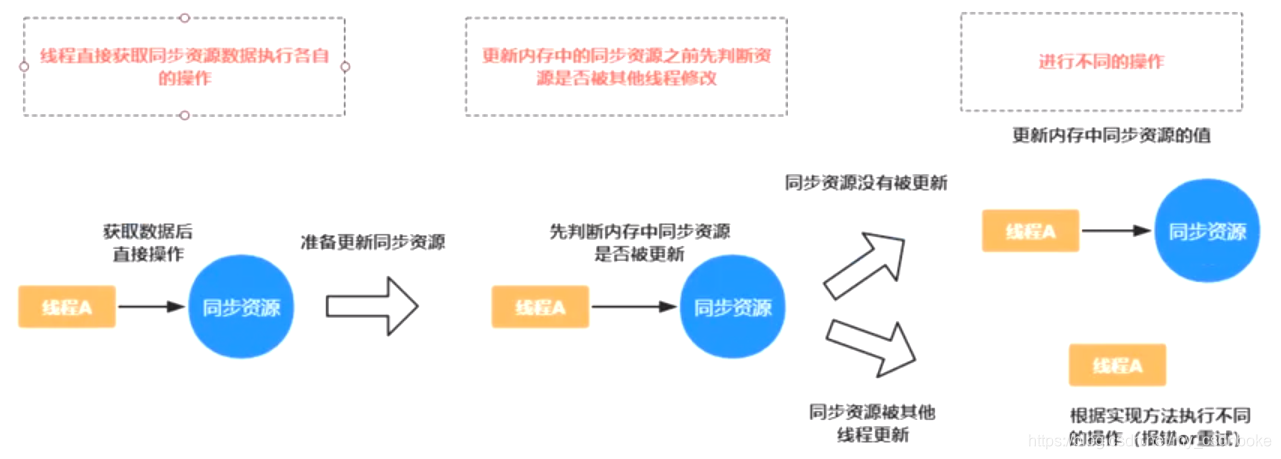
定义:乐观锁认为自己在使用数据时不会有别的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前有没有别的线程更新了这个数据
锁实现:CAS算法,例如AtomicInteger类的原子自增是通过CAS自旋实现
适用场景:读操作较多,不加锁的特点能够使其读操作的性能大幅提升
为了更好地理解乐观锁,请看乐观锁的执行过程,如下图:
2.2悲观锁
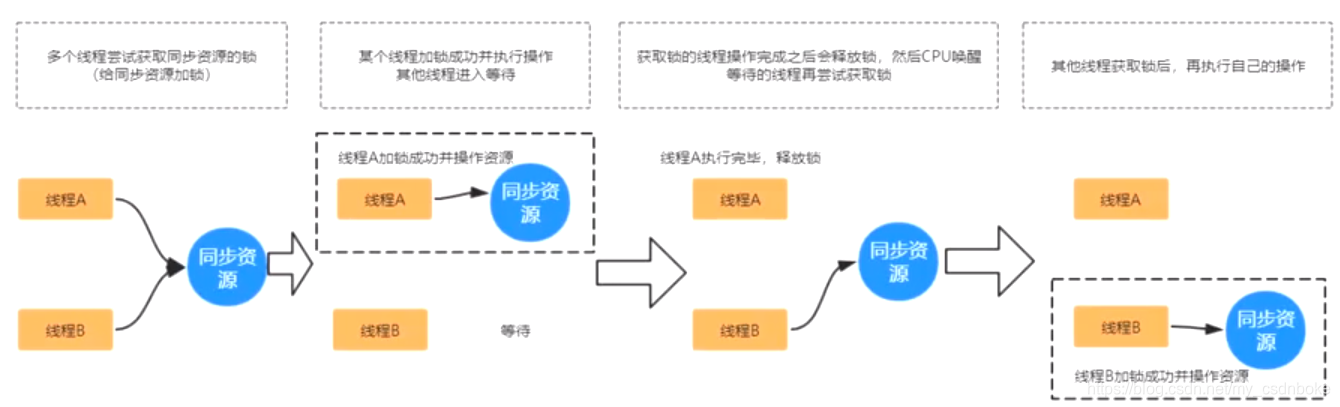
概念:悲观锁认为自己在使用数据的时候一定有别的线程来修改数据,在获取数据的时候会先加锁,确保数据不会被别的线程修改
锁实现:关键字synchronized、接口Lock的实现类。
适用场景:适用场景:写操作较多,先加锁可以保证写操作是数据正确
为了更好地理解乐观锁,请看悲观锁的执行过程,如下图:
3.CAS算法,CAS存在的问题
3.1CAS的基本介绍
全名:Compare And Swap(比较与交换)
无锁算法:基于硬件原语实现,在不使用锁(没有线程被阻塞)的情况下实现多线程之间的变量同步,需要注意的是比较发生的时间点是要将工作内存值同步到主内存的时候,要先将主内存变量在与其在工作内存的副本进行比较,如果相等才可以更新变量值然后同步/写入主内存,否则就不能哦。
jdk中实现:java.util.concurrent包中的原子类(AutomicInteger)
涉及三个操作数
-
需要读写的值,即主内存(对应线程的堆区)的变量的值V
-
进行比较的值,即主内存变量在工作内存(对应线程的栈区)的副本
-
要写入的新值B(即在工作内存改变变量值后需要同步到主内存的值)
3.2实现原理如下图:

在主内存中有一个变量V,它的值为0,现在多线程并发访问,都需要更改它的值,比如线程1首先会通过read、load等流程将它拷贝到线程1的工作内存,比较主内存的变量V和工作内存的副本A=0,相等然后更新它的值为1,同步到主内存,此时主内存的变量V值为1;现在线程2进行这个操作的时候,同样通过read、load拷贝一份副本到工作内存,更改变量的值时,需要进行比较,此时工作内存的副本值为0,但是主内存的变量值已经为1了,操作失败,不能将更新的值同步回主内存。然后就是自旋了,会重新通过read、load拷贝一份主内存的副本到工作内存,再次进行比较,相等才能将更新的值同步回主内存。当然自旋的循环次数是可以设定的。
3.3CAS存在的问题
主要是ABA问题:还是上面的例子,假如有线程3在线程1更新值后,也进行了更新值的操作,又将v改回为0了,而线程2在这之后进行更新值的操作,也能成功,但是很显然线程2是感知不到主内存v的值发生过变化。这就好比,你存在银行的钱,银行职员挪用了,在上级领导发现之前,将钱还回来了,这是多么恐怖的事情啊。
解决:JDK中的并发包为了解决这个问题,提供了一个带有标记的原子引用类“AtomicStampedReference”,它可以通过控制变量值的版本来保证CAS的正确性。每次在执行数据的修改操作时,都会带上一个版本号,一旦工作内存数据的版本号和主内存数据的版本号一致就可以执行修改操作并对版本号执行+1操作,否则就执行失败。
4.自旋锁,synchronized分析
4.1自旋锁
4.1.1 定义
是指当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁时否能够被成功获取,自旋直到获取到锁才会退出循环。
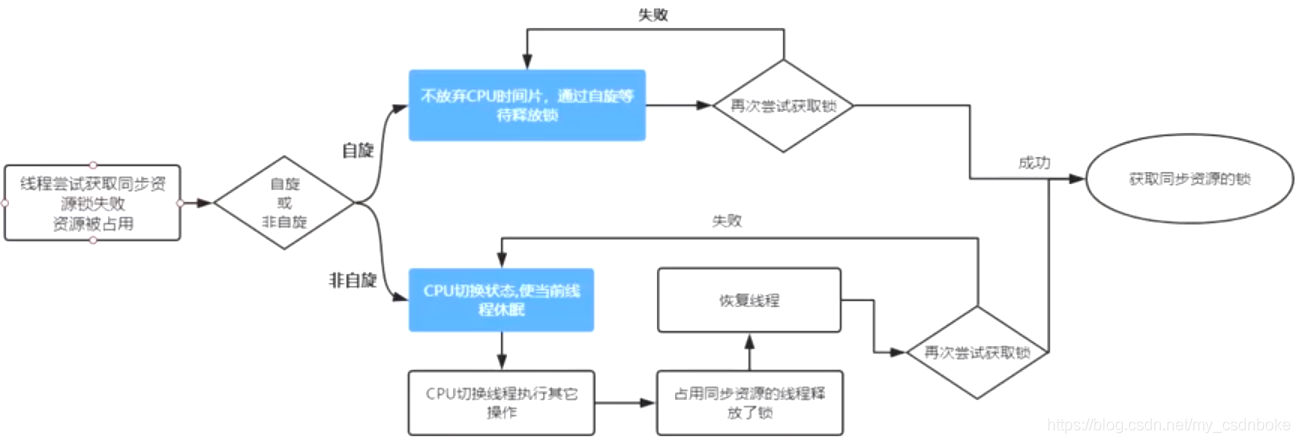
4.1.2自旋锁存在的意义与使用场景
- 阻塞与唤醒线程需要操作系统切换CPU状态,需要消耗一定的时间
- 同步代码块逻辑简单,执行时间很短
假如阻塞与唤醒线程需要消耗时间为100ms, 但是通过自旋10ms, 就可以试很多次,很有可能在10ms内就可以获取到锁,执行后续操作,大大节约了时间。所以自旋的意义就是为了尽量避免线程的阻塞与唤醒,切换上下文所造成的性能消耗。
自适应自旋锁假定不同线程持有同一个锁对象的时间基本相当,竞争程度趋于稳定。因此,可以根据上一次自旋的时间、次数的结果调整下一次自旋的时间与次数。比如上一次自旋30次成功,不考虑其他条件变化的前提下,自适应设定下一次自旋的次数为30+10=40次。
JDK1.6 通过-XX:-UseSpinning参数关闭自旋锁优化
-XX:PreBlockSpin参数修改默认的自旋次数
JDK>=1.7 自旋锁的参数被取消,虚拟机不再支持由用户配置自旋锁,自旋锁总是会执行,执行的次数也由虚拟机自动调整。
4.2 synchronized分析
4.2.1使用方式
- 普通同步方法(实例方法),锁是当前实例对象 ,进入同步代码前要获得当前实例的锁
- 静态同步方法,锁是当前类的class对象 ,进入同步代码前要获得当前类对象的锁
- 同步方法块,锁是括号里面的对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
4.2.2 实现方式
synchronized是JVM内置锁,通过内部对象Monitor(监视器锁)实现,基于进入与退出代码块同步,监视器锁的实现依赖底层操作系统的Multex lock (互斥锁)实现,如果将含有synchronized关键字代码块的类,通过安装jclasslib Bytecode viewer 插件后,可查看byte code 字节码指令,我们会发现有monitorenter和monitorexit两个字节指令,识别加锁的话,这两个字节指令对应进入拿到锁进入同步代码块,释放锁,退出同步代码块。
4.2.3 Monitor
每个同步对象都有一个自己的Monitor(监视器锁)

如果要进入同步代码块,首先需要判断当前线程是否拿到了对象的监视器锁,如果拿到了才会进入同步代码块,如果没有拿到对象的监视器锁,那就不好意思了,jvm会让该线程到同步队列(其它需要拿到对象的监视器锁,但是还没有拿到的线程组成的队列)去排队,等拿到对象监视器锁的线程释放锁,才会唤醒同步队列里面的某个幸运儿,这个幸运儿线程就进入同步代码块执行任务。
其实加锁,并不是一开始就加这样重量级的锁,比如前面提到的,如果通过适应性自旋锁,就能解决的问题,刚开始就加重量级锁显然有种杀鸡焉用牛刀的感觉。
5.JVM内置锁膨胀升级,对象加锁原理
5.1 JVM内置锁膨胀升级
JDK>1.6中synchronized的实现进行了各种优化,如适应性自旋、锁消除、锁粗化、轻量级锁和偏向锁
JDK>1.6默认开启偏向锁
开启偏向锁:-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
关闭偏向锁:-XX:-UseBiasedLocking

每次释放锁的时候又会回到无锁的状态,拿到锁,进入同步代码块,又重新进入升级过程。
5.2 JVM对象加锁原理
既然同步对象(即上了锁的对象)会和Monitor进行关联,那么同步对象的实例就要存储锁的信息(锁的状态和指向),那么在内存的角度,如何判断一个对象是否加了锁呢?或者说同步对象的实例在内存中的存储结构是怎样的呢?实例对象主要分为两个部分存储,对象头和实际数据,对象头是对实例对象的描述,也就是说,对象上锁,会改变对象头(存储的信息)。
认识对象的内存结构
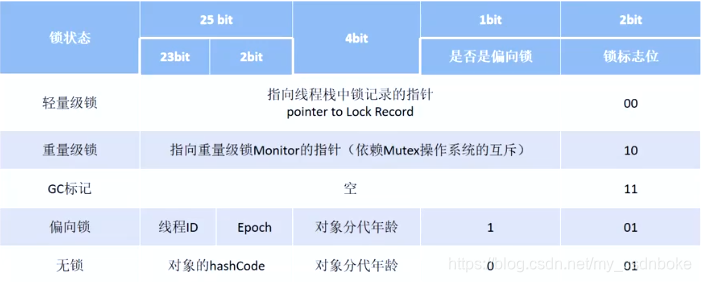
对象头:比如hash码,对象所属的年代,对象锁,锁状态标志,偏向锁(线程)ID,偏向时间,数组长度(数组对象)等。
对象实际数据:即创建对象时,对象中成员变量,方法等。
锁有膨胀升级的过程,那么显然对象头的信息就随着升级过程而动态改变的。
Mark Work在32位JVM中存储内容为例
实例对象是怎样存储的?
对象的实例存储在堆空间,对象的元数据存在方法区(元空间区),对象的引用存在栈空间。
6.深入理解AQS
6.1Java的显示锁与隐式锁
隐式锁:(synchronized,它是基于JVM内置锁),加锁与解锁的过程不需要我们在代码当中人为的控制,jvm会自动去加锁和解锁
显示锁:(以ReentrantLock为例,一个可重入的锁)整个加锁和解锁的过程需要我们手动编写代码去控制
其实synchronized和ReentrantLock都是可重入锁,可重入锁,就是说线程已经获得了某个锁,可以再次获取锁而不会出现死锁。由于ReentrantLock是显示锁,使用时要手动释放锁,并且加锁和释放锁的次数要相等。如果不相等,那么其它线程将无法获取到锁,导致一直等待。
public class ReentrantLockTest {
/**
* 需要多个保证多个线程使用的是同一个锁
*/
private ReentrantLock lock = new ReentrantLock(true);
private int counter;
public static void main(String[] args) {
final ReentrantLockTest reentrantLockTest = new ReentrantLockTest();
new Thread(new Runnable() {
@Override
public void run() {
String threadName = Thread.currentThread().getName();
reentrantLockTest.modifyResources(threadName);
}
}, "xpf").start();
}
private void modifyResources(String threadName) {
System.out.println("通知《管理员》线程---> " +threadName + "准备打水");
lock.lock();//加锁
System.out.println("线程--->" + threadName+ "第一次加锁");
counter++;
System.out.println("线程:" + threadName+ "打第"+ counter+ "次水");
// 重入该锁,还有一件事情要做,没做完之前不能把锁资源让出去
lock.lock();
System.out.println("线程--->"+threadName+"第二次加锁");
counter++;
System.out.println("线程:"+ threadName+ "打第"+counter+"次水");
lock.unlock();//释放锁
System.out.println("线程:"+threadName+"释放一个锁");
lock.unlock();//释放锁的次数要与加锁的次数一致,否则,其它线程无法获取到锁
System.out.println("线程:"+threadName+"释放一个锁");
}
}
6.2 AQS原理分析
ReentrantLock就是基于AQS(AbstractQueuedSynchronizer抽象队列同步器)来实现的,它的内部类Sync继承AbstractQueuedSynchronizer。创建实例对象的传入的参数true,表示创建公平锁,开篇图中提到过,表示要排队,排在前面的有获取锁的优先权。
结合代码案例,进行分析。首先debug一下,我们看到如下信息
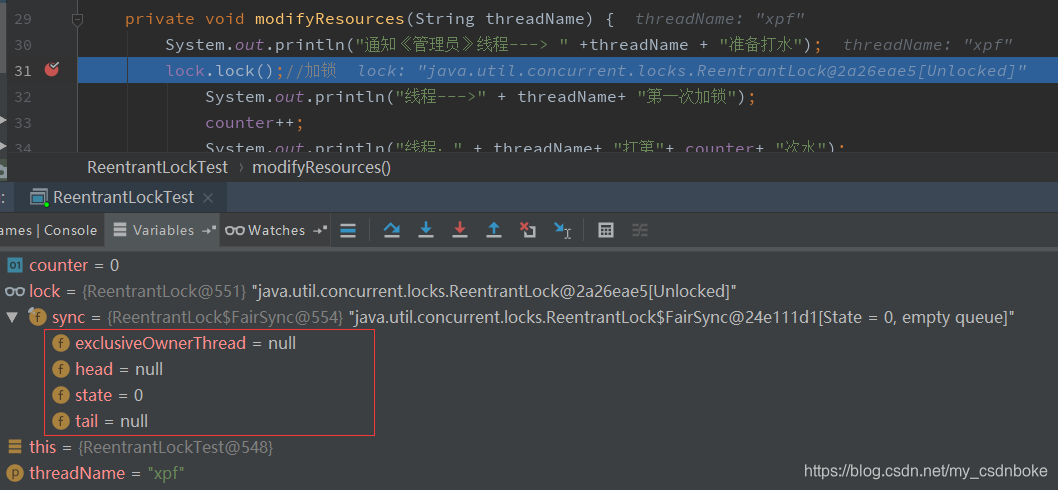
再往下执行一步,得到信息如下:
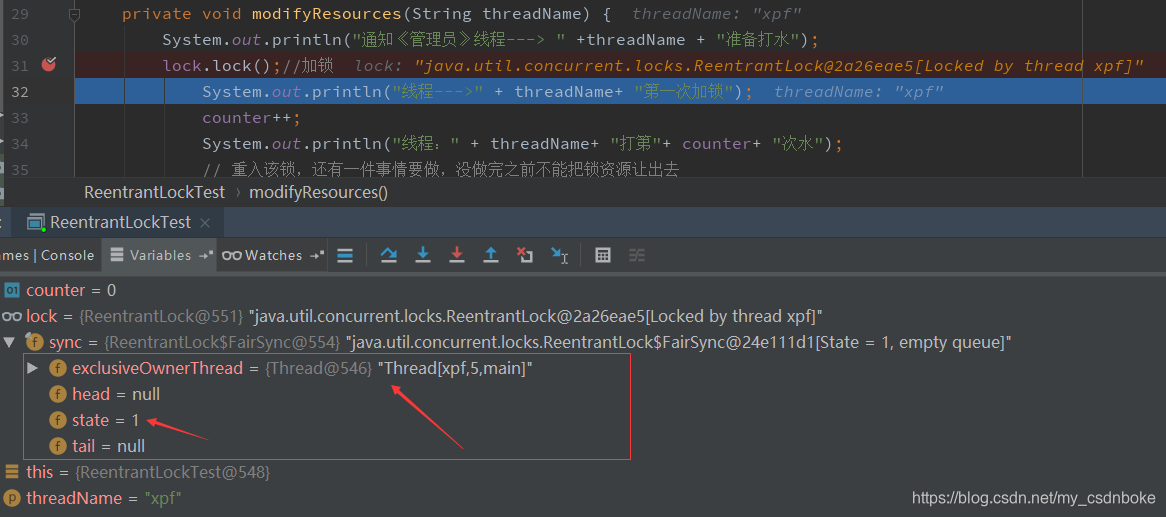
加锁后,state=1,exclusiveOwnerThread也有值了,就是我们new 的线程(名为xpf),表示占有锁的线程。如果继续执行,也就是再加一次锁,会发现state变为2,受限于篇幅,就不截图了。我们发现还有两个参数head,tail为null,不是加锁成功了吗?这是为什么呢?当有多个线程并发获取锁的时候,此时线程1获取锁,还没有释放锁,所以线程2、3、4无法获取锁,怎么办呢?那就会添加到一个叫CLH的队列中,排队等候(传入参数true,公平锁)。而示例代码中,只有单个线程,并没有多个线程并发获取锁,队列自然为空,所以队列的头尾结点head、tail也就为空了。
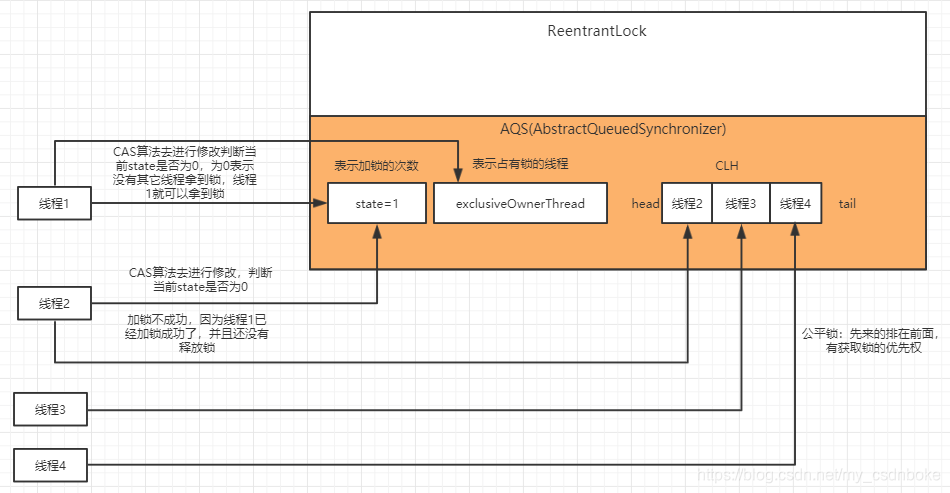
7.CLH队列
CLH队列是Craig、Landing、Hagersten三人发明的一种基于双向链表数据结构的队列,Java中CLH队列是原CLH队列的一个变种,线程由原自旋机制改为阻塞机制。
为什么是阻塞呢?到代码中找答案,由于能力所限,对于源码的分析方面,目前只能浅尝辄止,首先我们看这个链表的结点特性。
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
...
static final class Node {
/** Marker to indicate a node is waiting in shared mode */
static final Node SHARED = new Node();
/** Marker to indicate a node is waiting in exclusive mode */
static final Node EXCLUSIVE = null;
...
volatile Node next;
volatile Node prev;
/**
* The thread that enqueued this node. Initialized on
* construction and nulled out after use.
*/
volatile Thread thread;
}
...
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
...
}
有两种模式,SHARED表示结点是共享模式(用于读锁,是可以共享的锁),EXCLUSIVE表示结点是独占模式。我们看AbstractQueuedSynchronizer的acquire方法,加入的结点就是独占模式的。如果对聊表有基本的了解,就知道结点存储的数据分为两部分,一部分是指针地址,另一部分就是数据内容。而这里存的具体数据就是要排队获取锁的线程。这就是大概的线程在同步器中同步排队的方式。
另附上死锁的博文连接,看了一下,总结的不错
死锁的四个必要条件和解决办法:https://blog.csdn.net/guaiguaihenguai/article/details/80303835
