1.决策树原理
决策树(decision tree)是一类常见的机器学子方法。具体的原理这里不做介绍,读者可以简单理解为:要用决策树做未知样本的分类(预测),一定要现根据已有样本,训练、产生一颗泛化能力强,即能处理未知样本的决策树。
2.用决策树做分类的例子
a.数据集,名为getbed.csv
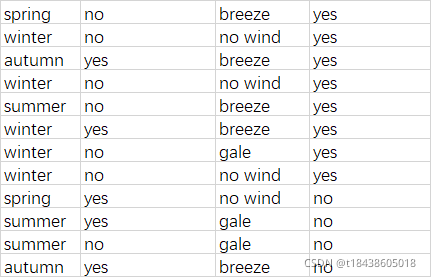
季节 时间已过八点 风力情况 要不要赖床
spring no breeze yes
winter no no wind yes
autumn yes breeze yes
winter no no wind yes
summer no breeze yes
winter yes breeze yes
winter no gale yes
winter no no wind yes
spring yes no wind no
summer yes gale no
summer no gale no
autumn yes breeze no
注意,读者制作getbed.csv时,不要带列名。
关于训练集、验证集和测试集的补充知识:参考训练集、验证集和测试集这三个名词的区别
b.环境准备
需要用到panda 和 scikit-learn,读者环境中没有的,自行安装
c.代码
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn import tree
from sklearn.model_selection import train_test_split
'''
获取数据内容。pandas.read_csv(“data.csv”)默认情况下,会把数据内容的第一行默认为字段名标题。
为了解决这个问题,我们添加“header=None”,告诉函数,我们读取的原始文件数据没有列索引
'''
#pandas 读取 csv 文件,header = None 表示不将首行作为列
data = pd.read_csv('getbed.csv',header =None)
#为读入的数据,指定列名
data.columns = ['season','after 8','wind','lay bed']
#data.columns = ['season','after 8','wind']
#sparse=False意思是不产生稀疏矩阵
vec=DictVectorizer(sparse=False)
#先用 pandas 对每行生成字典,然后进行向量化
feature = data[['season','after 8','wind']]
target = data[['lay bed']]
X_train = vec.fit_transform(feature.to_dict(orient='record'))
#使用feature_names_all接收特征列名,便于后面使用
feature_names_all = vec.get_feature_names()
#打印各个变量
print('show feature\n',feature)
print('show vector\n',X_train)
print('show vector name\n',vec.get_feature_names())
Y_train = vec.fit_transform(target.to_dict(orient='record'))
print('show vector name\n',vec.get_feature_names())
#print('show target\n',target)
#划分成训练集,验证集,验证集,不过这里我们数据量不够大,没必要
#此段代码中,test_size = 0.25,表示把数据集划分为两份,训练集和测试集之比为4:1(二八原则)
#关于train_test_split(),随机划分训练集和测试集的函数,可参考博客:https://blog.csdn.net/qq_38410428/article/details/94054920
#train_x, test_x, train_y, test_y = train_test_split(X_train, Y_train, test_size = 0.25)
#训练决策树
clf = tree.DecisionTreeClassifier(criterion='gini')
model = clf.fit(X_train,Y_train)
'''
#如果划分了,训练集、验证集和测试集,加上此步骤,看训练好的决策树在测试集上的准确率
res = model.predict(test_x)
print(res) #模型结果输出
print(test_y) #实际值
print(sum(res==test_y)/len(res)) #准确率
'''
A = ([[0,1,0,0,0,1,0,1,0]]) #时间已过8点,冬天,风力gale的情况下,是否起床
predict_result = clf.predict(A)
print('预测结果:'+str(predict_result))
#可选步骤
#保存成 dot 文件,后面可以用 dot out.dot -T pdf -o out.pdf 转换成图片,查看生成的决策树
with open("out.dot", 'w') as f :
f = tree.export_graphviz(clf, out_file = f,
feature_names = feature_names_all)
提取码:tian
–来自百度网盘超级会员V7的分享
参考: