一.spark单节点部署
# 1.安装java环境
# 略
# 2.安装scala环境
wget https://downloads.lightbend.com/scala/2.13.6/scala-2.13.6.tgz
tar -zxvvf scala-2.13.6.tgz
cd scala-2.13.6
# 修改配置文件,设置SCALA_HOME路径
vim /etc/profile
export SCALA_HOME=/opt/scala-2.13.6
export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin
source /etc/profile
# 3.Install Spark
wget https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz --no-check-certificate
tar -xvf spark-3.2.0-bin-hadoop3.2.tgz
mv spark-3.2.0-bin-hadoop3.2 /opt/spark
cd /opt/spark/conf
# 修改spark环境配置
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
# 修改默认master端口
export SPARK_MASTER_PORT=17077
# 设置java路径
export JAVA_HOME=/usr/local/java
# 添加spark用户
useradd spark
chown -R spark:spark /opt/spark
# 4.Create a Systemd Service File for Spark
# master端配置
vim /etc/systemd/system/spark-master.service
[Unit]
Description=Apache Spark Master
After=network.target
[Service]
Type=forking
User=spark
Group=spark
ExecStart=/opt/spark/sbin/start-master.sh -h 127.0.0.1
ExecStop=/opt/spark/sbin/stop-master.sh
[Install]
WantedBy=multi-user.target
# worker端配置
vim /etc/systemd/system/spark-worker.service
[Unit]
Description=Apache Spark Slave
After=network.target
[Service]
Type=forking
User=spark
Group=spark
ExecStart=/opt/spark/sbin/start-worker.sh spark://127.0.0.1:17077
ExecStop=/opt/spark/sbin/stop-worker.sh
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
# 5.启动master端服务
systemctl start spark-master
systemctl enable spark-master
# 查看17077端口能否连接
nmap -p 7077 127.0.0.1
# 启动worker端服务
systemctl start spark-worker
systemctl enable spark-worker
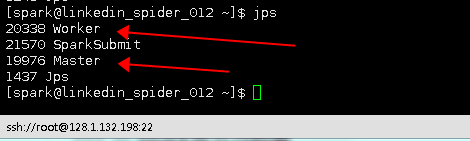
jps
二.pyspark DataFrame快速入门
# -*- coding: utf-8 -*-
# @Time : 2021/10/29 20:23
# @Author :
from datetime import datetime, date
import pandas as pd
from pyspark.sql import Row
from pyspark import SparkConf
from pyspark.sql import SparkSession
# 弹性分布式数据集(RDD),它是跨集群节点分区的元素集合,可以并行操作
# SparkSession这是 PySpark 的入口点
MASTER = "spark://127.0.0.1:17077"
APPName = "quickstart_df"
spark = SparkSession.builder.config(conf=SparkConf()).appName(APPName).master(MASTER).getOrCreate()
## 1.创建DataFrame
df = spark.createDataFrame([
Row(a=1, b=2., c='string1', d=date(2000, 1, 1), e=datetime(2000, 1, 1, 12, 0)),
Row(a=2, b=3., c='string2', d=date(2000, 2, 1), e=datetime(2000, 1, 2, 12, 0)),
Row(a=4, b=5., c='string3', d=date(2000, 3, 1), e=datetime(2000, 1, 3, 12, 0))
])
df = spark.createDataFrame([
(1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)),
(2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)),
(3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))
], schema='a long, b double, c string, d date, e timestamp')
# 从 Pandas DataFrame 创建 PySpark DataFrame
pandas_df = pd.DataFrame({
'a': [1, 2, 3],
'b': [2., 3., 4.],
'c': ['string1', 'string2', 'string3'],
'd': [date(2000, 1, 1), date(2000, 2, 1), date(2000, 3, 1)],
'e': [datetime(2000, 1, 1, 12, 0), datetime(2000, 1, 2, 12, 0), datetime(2000, 1, 3, 12, 0)]
})
df = spark.createDataFrame(pandas_df)
# 从包含元组列表的 RDD 创建 PySpark DataFrame
rdd = spark.sparkContext.parallelize([
(1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)),
(2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)),
(3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))
])
df = spark.createDataFrame(rdd, schema=['a', 'b', 'c', 'd', 'e'])
# 显示DataFrame信息
df.show()
# 显示schema信息
df.printSchema()
# 快速评估启用配置
# spark.conf.set('spark.sql.repl.eagerEval.enabled', True)
# 要显示的行数
# spark.conf.set('spark.sql.repl.eagerEval.maxNumRows', 3)
# df
# 显示 DataFrame 的描述
# df.select("a", "b", "c").describe().show()
# 将分布式数据作为本地数据收集到驱动端
# df.collect()
# df.take(1)
# df.tail(2)
# PySpark DataFrame 还提供转换回Pandas DataFrame以利用Pandas API
# df.toPandas()
## 2.选择和访问数据
# PySpark DataFrame 是惰性求值的,简单地选择一列不会触发计算,但会返回一个Column实例
# df.a
# 事实上,大多数列操作都返回Columns
from pyspark.sql import Column
from pyspark.sql.functions import upper
# type(df.c) == type(upper(df.c)) == type(df.c.isNull())
# 这些Columns 可用于从 DataFrame 中选择列
df.select(df.c).show()
# 分配新Column实例
df.withColumn('upper_c', upper(df.c)).show()
# 要选择行的子集
df.filter(df.a == 1).show()
## 3.应用函数
# PySpark 支持各种 UDF 和 API,以允许用户执行 Python 本机函数
import pandas
from pyspark.sql.functions import pandas_udf
@pandas_udf('long')
def pandas_plus_one(series: pd.Series) -> pd.Series:
# Simply plus one by using pandas Series.
return series + 1
df.select(pandas_plus_one(df.a)).show()
# DataFrame.mapInPandas允许用户直接使用Pandas DataFrame 中的 API,没有任何限制
def pandas_filter_func(iterator):
for pandas_df in iterator:
yield pandas_df[pandas_df.a == 1]
df.mapInPandas(pandas_filter_func, schema=df.schema).show()
## 4.分组数据
df = spark.createDataFrame([
['red', 'banana', 1, 10], ['blue', 'banana', 2, 20], ['red', 'carrot', 3, 30],
['blue', 'grape', 4, 40], ['red', 'carrot', 5, 50], ['black', 'carrot', 6, 60],
['red', 'banana', 7, 70], ['red', 'grape', 8, 80]], schema=['color', 'fruit', 'v1', 'v2'])
# df.show()
#
# 分组,然后将avg()函数应用于结果组。
df.groupby('color').avg().show()
# 还可以使用 Pandas API 对每个组应用 Python 本机函数
def plus_mean(pandas_df):
return pandas_df.assign(v1=pandas_df.v1 - pandas_df.v1.mean())
df.groupby('color').applyInPandas(plus_mean, schema=df.schema).show()
# 共同分组和应用功能
df1 = spark.createDataFrame(
[(20000101, 1, 1.0), (20000101, 2, 2.0), (20000102, 1, 3.0), (20000102, 2, 4.0)],
('time', 'id', 'v1'))
df2 = spark.createDataFrame(
[(20000101, 1, 'x'), (20000101, 2, 'y')],
('time', 'id', 'v2'))
def asof_join(l, r):
return pd.merge_asof(l, r, on='time', by='id')
df1.groupby('id').cogroup(df2.groupby('id')).applyInPandas(
asof_join, schema='time int, id int, v1 double, v2 string').show()
# 输入/输出数据
# df.write.csv('foo.csv', header=True)
# spark.read.csv('foo.csv', header=True).show()
## 5.使用 SQL
# # DataFrame 和 Spark SQL 共享相同的执行引擎,因此它们可以无缝地互换使用
df.createOrReplaceTempView("tableA")
spark.sql("SELECT count(*) from tableA").show()
# # UDF 可以开箱即用地在 SQL 中注册和调用
@pandas_udf("integer")
def add_one(s: pd.Series) -> pd.Series:
return s + 1
spark.udf.register("add_one", add_one)
spark.sql("SELECT add_one(v1) FROM tableA").show()
# 这些 SQL 表达式可以直接混合用作 PySpark 列
from pyspark.sql.functions import expr
df.selectExpr('add_one(v1)').show()
df.select(expr('count(*)') > 0).show()
参考: http://spark.apache.org/docs/latest/api/python/getting_started/quickstart_df.html
参考:https://www.cnblogs.com/freeweb/p/13873225.html
参考:https://blog.csdn.net/ybdesire/article/details/70666544
参考:cnblogs.com/cloucodeforfun/p/14808411.html