RDD
在之前的spark core中,所提到的数据类型,基本上都是rdd,各式各样的rdd,他有一个特点,就是只关注数据本身,并不关注数据的结构和类型,好比如下:所以在取到数据之后,我们需要人为的去对数据进行拆分和计算

DataFrame
相比于RDD,DataFrame还注重到了结构,这里的结构好比数据库表的列结构,所以在DataFrame可以根据列名进行一系列的操作。

DataSet
DataSet则在DataFrame的基础上,又进一步指定了数据类型,可以理解为,DataFrame是指定了列的结构,也就是说这个数据总共有多少列,但是DataSet在此基础上又指定了行结构,表示每一行里面的数据的具体类型(int或者string)的什么。
如何创建
rdd
在默认情况下,如果是从内存中读取,或者是读取非结构化数据,默认都是rdd数据类型,例如
# 输入的数据
data = [3,4,5,6]
rdd = sc.parallelize(data,2)
rdd1 = sc.textFile("../datas/apache.log")
DataFrame
通常,如果是读取结构化的数据,例如,数据库数据或者是json,csv这类结构化的数据,可直接得到DataFrame对象。
#DataFrame
df = spark.read.json("../datas/user.json")
DataSet
不可直接通过读取数据建立,需要指定结构类型
转换关系
rdd==>DataFrame
需要指定列结构
from pyspark.sql import SparkSession
# RDD ===>DataFrame
data = [(1,"zhangsan",30),(2,"lisi",40)]
rdd = spark.sparkContext.parallelize(data)
df1 = spark.createDataFrame(rdd,schema=['id','username','age']).show()
DataFrame ==>rdd
无需添加任何数据,直接转
from pyspark.sql import SparkSession
# 创建local表示只用单线程,loacal[*]表示用电脑全部的cpu核
spark = SparkSession.builder.appName("lichao_wordcount").master("local[*]").getOrCreate()
#DataFrame
df = spark.read.json("../datas/user.json")
# DataFrame ===> RDD
rdd2 = df.rdd
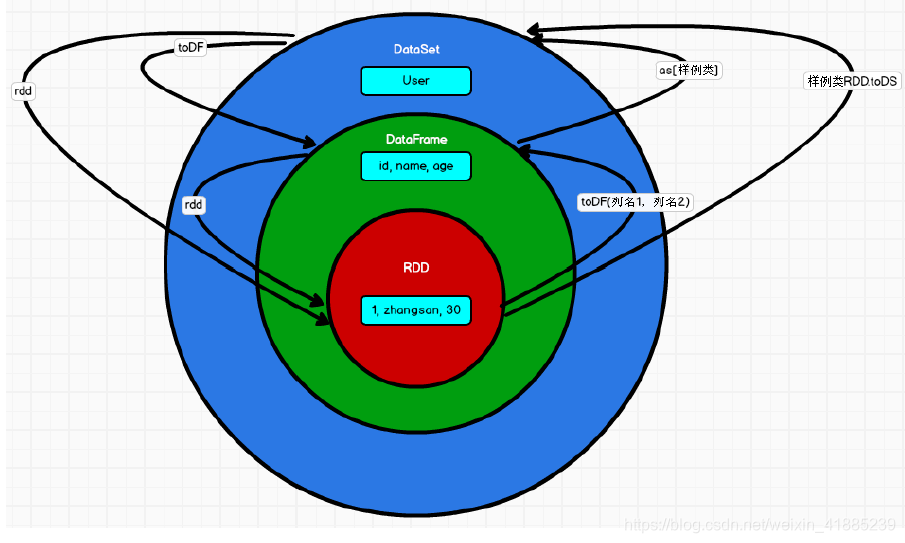
其他的不做过多介绍,放一张尚硅谷大神的原理图,便于以后回顾
DataFrame的读取
1.读取数据
2.建立试图
3.可以像数据库一样进行访问
4.也可以用dsl语法进行访问
from pyspark.sql import SparkSession
from pyspark import SparkConf
# 创建local表示只用单线程,loacal[*]表示用电脑全部的cpu核
spark = SparkSession.builder.appName("lichao_wordcount").master("local[*]").getOrCreate()
#DataFrame
df = spark.read.json("../datas/user.json")
#DataFrame ==> SQL
df.createOrReplaceTempView("user")
spark.sql("select * from user").show()
spark.sql("select age,username from user").show()
spark.sql("select avg(age) from user ").show()
#DataFrame -->DSL
#在dataframe中如果涉及到转换操作,需要引入转换规则
df.select("age","username").show()