选择题
以下代码的输出结果是?
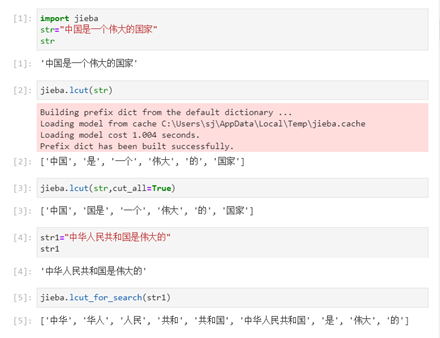
import jieba
str="中国是一个伟大的国家"
jieba.lcut(str)
选项:
A. ['中国是一个伟大的国家']
B. ['中国', '是', '一个', '伟大', '的', '国家']
C. ['中国', '国是', '一个', '伟大', '的', '国家']
D. '中国是一个伟大的国家'
问题解析
1.jieba是python中的中文分词第三方库,可以将中文的文本通过分词获得单个词语,返回类型为列表类型。
2.jieba分词共有三种模式:精确模式、全模式、搜索引擎模式。
(1)精确模式语法:jieba.lcut(字符串,cut_all=False),默认时为cut_all=False,表示为精确模型。精确模式是把文章词语精确的分开,并且不存在冗余词语,切分后词语总词数与文章总词数相同。
(2)全模式语法:ieba.lcut(字符串,cut_all=True),其中cut_all=True表示采用全模型进行分词。全模式会把文章中有可能的词语都扫描出来,有冗余,即在文本中从不同的角度分词,变成不同的词语。
(3)搜索引擎模式:在精确模式的基础上,对长词语再次切分。
3.在此题中,字符串为"中国是一个伟大的国家",jieba.lcut(str)表示以精确模式切分词语,不存在冗余词语且切分后词语总词数与"中国是一个伟大的国家"词数相同,所以答案为['中国', '是', '一个', '伟大', '的', '国家']。
答案
正确答案是:B
温馨期待
期待大家提出宝贵建议,互相交流,收获更大。
欢迎大家转发,一起传播知识和正能量,帮助到更多人。期待大家提出宝贵改进建议,互相交流,收获更大。辛苦大家转发时注明出处(也是咱们公益编程交流群的入口网址),刘经纬老师共享知识相关文件下载地址为:http://liujingwei.cn