一、集合大纲
Java中的集合包含多种数据结构,如链表、队列、哈希表等。从类的继承结构来说,可以分为两大类,一类是继承自Collection接口,这类集合包含List、Set和Queue等集合类。另一类是继承自Map接口,这主要包含了哈希表相关的集合类
结构图如下
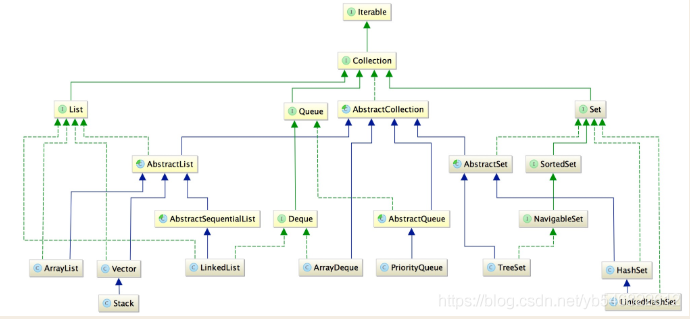

二、常见分类
Collection 接口的接口 对象的集合(单列集合)
├——-List 接口:元素按进入先后有序保存,可重复
│—————-├ LinkedList 接口实现类, 链表, 插入删除, 没有同步, 线程不安全
│—————-├ ArrayList 接口实现类, 数组, 随机访问, 没有同步, 线程不安全
│—————-└ Vector 接口实现类 数组, 同步, 线程安全
│ ———————-└ Stack 是Vector类的实现类
└——-Set 接口: 仅接收一次,不可重复,并做内部排序
├—————-└HashSet 使用hash表(数组)存储元素
│————————└ LinkedHashSet 链表维护元素的插入次序
└ —————-TreeSet 底层实现为二叉树,元素排好序
Map 接口 键值对的集合 (双列集合)
├———Hashtable 接口实现类, 同步, 线程安全
├———HashMap 接口实现类 ,没有同步, 线程不安全-
│—————–├ LinkedHashMap 双向链表和哈希表实现
│—————–└ WeakHashMap
├ ——–TreeMap 红黑树对所有的key进行排序
└———IdentifyHashMap
三、List实现原理
3.1 实现的接口
常用的实现List接口的主要有ArrayList、Vector、LinkedList 三个,
3.1.1 ArrayList
特点:ArrayList是List使用中最常用的实现类,它的查询速度快,效率高,但增删慢,线程不安全。
原理:ArrayList底层实现采用的数据结构是数组,并且数组默认大小为10,所以下面两种方式是等同的
List list = new ArrayList(); //没有指定数组大小,使用默认值(默认大小是10)
List list = new ArrayList(10); // 指定数组大小为10,传如的参数便是数组的大小,传入为10时,跟默认值相同,所以是等同的扩容机制:
jdk1.8的扩容算法:newCapacity = oldCapacity + ( oldCapacity >> 1 ) ; // oldCapacity >> 2 移位运算,此处相当于oldCapacity除以2,但是 >> 这种写法更加高效
jdk1.6的扩容算法:newCapacity = ( oldCapacity * 3 ) / 2 +1 ;
参数介绍:newCapacity 是扩容后的容量大小,oldCapacity 是扩容前的大小
查看jdk源码,移位运算需要学习下,换句话说,就是需要学习下二进制,比如:反码、补码,二进制与十进制、十六进制的相互转换。与机器交流的都是0110等,所以挺重要的。
3.1.2 Vector
特点:Vector的底层也是通过数组实现的,默认大小也是10。主要特点:查询快,增删慢 , 线程安全,但是效率低
原理:创建对象与ArrayList类似,但有一点不同,它可以设置扩容是容量增长大小。
根据Vector的三个构造器就可以很明了的理解 new Vector(); 与 new Vector(10);与 new Vector(10,0); 三个是等同的,很明了就不赘述了
1.无参构造器 public Vector() {
this(10);
}
2.传一个参数(容量大小) 容量大小即底层数组大小
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
3.传两个参数(容量大小,容量修正) 容量修正即扩容时的增加量
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}扩容机制:
jdk1.8的扩容算法:newCapacity = oldCapacity + ( ( capacityIncrement > 0 ) ? capacityIncrement : oldCapacity );
jdk1.6的扩容算法:newCapacity = ( capacityIncrement > 0 ) ? ( oldCapacity + capacityIncrement ) : ( oldCapacity * 2 );
参数介绍:capacityIncrement 是容量修正(即容量新增大小),没有设置,默认为0 ,newCapacity 是扩容后的容量大小,oldCapacity 是扩容前的大小
一观察,就会发现1.6与1.8的写法变化不大,但是仔细一分析,就会发现jdk1.6中有使用乘法运算,即 oldCapacity * 2。 在jdk1.8中换成了加法运算,这是因为乘法的效率是低于加法的,这应该算法的优化。
3.1.3 LinkedList
特点:LinkedList底层是一个双向链表,它增删快,效率高,但是查询慢,线程不安全
原理:构造器只有如下两种;
1.无参构造
public LinkedList() {
}
2.有参构造
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}由于它的底层实现是链表,所以没有容量大小的定义,只有上个节点,当前节点,下个节点,每个节点都有一个上级节点和一个下级节点。
新增元素实现代码如下
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}先获取头部节点元素,判断是否为null,若为null,说明原链表中没有元素,则把 first 和 last 都赋为当前新增节点。 若不为null,说明原链表中有元素,则把first赋为当前新增节点,把原头部节点f的上级节点修改为当前新增节点的下级节点
尾部新增
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}与头部新增元素类似,不再赘述。
删除元素:
删除元素有三种方式,删除第一元素,删除最后一个元素,删除中间部分的某个元素。 现介绍最后一个,最后一个搞懂了,前两个就懂了。
实现代码:
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}原理:要删除元素的当前节点x,将当前节点x的上级节点的下级节点设为当前节点x的下级节点,将当前节点x的下级节点的上级节点设为当前节点x的上级节点。
中间考虑上级节点或下级节点为空的情况,也就是头部删除与尾部删除。