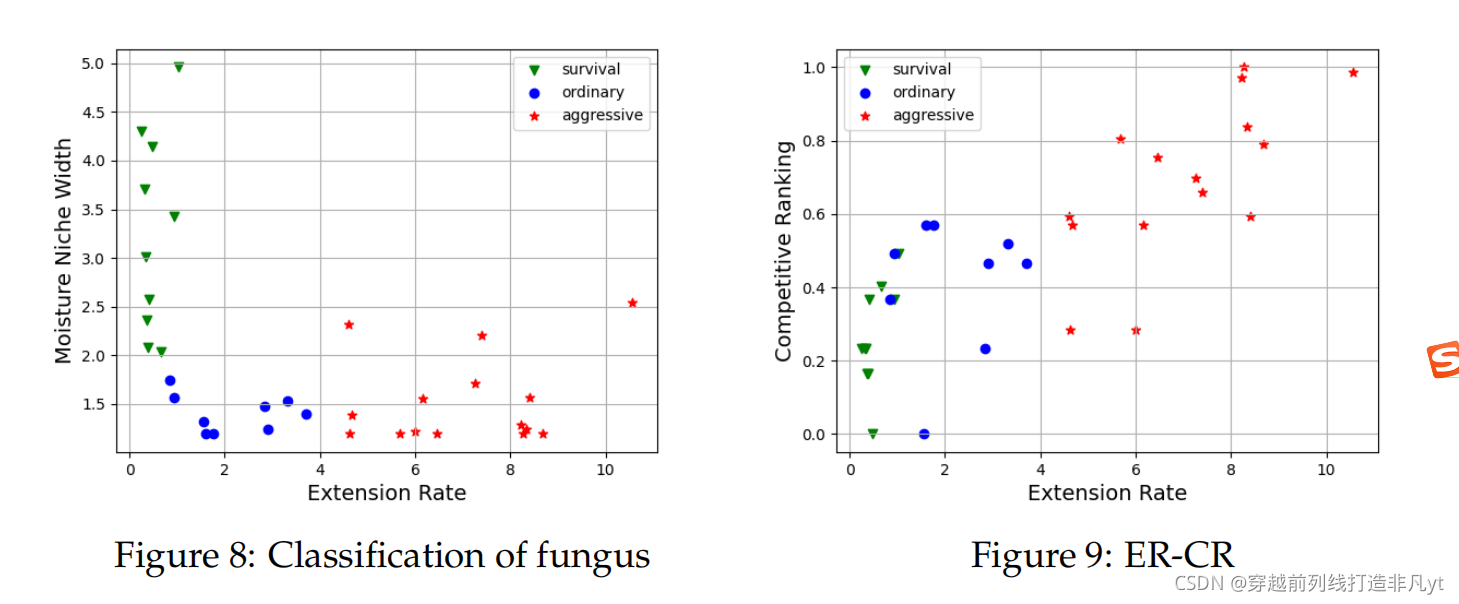
2021年美赛A题真菌种群K-means聚类算法Python实现及绘图
import random
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
# calculate the euler distance
def calcDis(dataSet, centroids, k):
clalist = []
for data in dataSet:
diff = np.tile(data, (k,
1)) - centroids
squaredDiff = diff ** 2
squaredDist = np.sum(squaredDiff, axis=1)
distance = squaredDist ** 0.5
clalist.append(distance)
clalist = np.array(clalist)
return clalist
# calculate the centroids
def classify(dataSet, centroids, k):
# calculate the distance between the samples and centroids
clalist = calcDis(dataSet, centroids, k)
# Grouping the samples and recalculate the centroids
minDistIndices = np.argmin(clalist, axis=1)
newCentroids = pd.DataFrame(dataSet).groupby(
minDistIndices).mean()
newCentroids = newCentroids.values
changed = newCentroids - centroids
return changed, newCentroids
def kmeans(dataSet, k):
centroids = random.sample(dataSet, k)
# renew the centroids until there is no change
changed, newCentroids = classify(dataSet, centroids, k)
while np.any(changed != 0):
changed, newCentroids = classify(dataSet, newCentroids, k)
centroids = sorted(newCentroids.tolist())
cluster = []
clalist = calcDis(dataSet, centroids, k)
minDistIndices = np.argmin(clalist, axis=1)
for i in range(k):
cluster.append([])
for i, j in enumerate(minDistIndices):
cluster[j].append(dataSet[i])
return centroids, cluster
def createDataSet():
# df1 = pd.read_excel(r'D:\MCM2021\data\MT-DR.xlsx')
# mt = df1['MT'].values
# dr = df1['DR'].values
# length = len(dr)
# ary1 = []
# for i in range(length):
# ary1.append([mt[i],dr[i]])
# df2 = pd.read_excel(r'D:\MCM2021\data\fungal_biogeography-master\fungi_data\fungal_trait_data.xlsx')
# rate2 = df2['rate.0.5'].values
# ranking = df2['ranking'].values
# wnw2 = df2['water.niche.width'].values
# length2 = len(rate2)
ary2 = []
df3 = pd.read_csv(r'D:\MCM2021\data\fungi classification.csv')
rate3 = df3['extension rate'].values
wnw3 = df3['water.niche.width'].values
length3 = len(rate3)
for i in range(length3):
ary2.append([rate3[i], wnw3[i]])
return ary2
def a_plot(k, cluster):
xlist = []
ylist = []
data_list = cluster[k]
length = len(data_list)
for j in range(0, length):
xlist.append(data_list[j][0])
ylist.append(data_list[j][1])
return xlist, ylist
def eluer(centroids, cluster, k):
i = 0
j = 0
dis = []
for i in range(0, k):
l = 0
length = len(cluster[i])
for j in range(length):
point = cluster[i][j]
l += math.sqrt((point[0] - centroids[i][0]) ** 2 + (point[1] - centroids[i][1]) ** 2)
dis.append(l)
return dis
if __name__ == '__main__':
k = 3
i = 0
dataset = createDataSet()
centroids, cluster = kmeans(dataset, k)
dis = eluer(centroids, cluster, k)
print('距离为:%s' % dis)
print('质心为:%s' % centroids)
print('集群为:%s' % cluster)
x_list = []
y_list = []
fig_1 = plt.figure()
ax_1 = fig_1.add_subplot(1, 1, 1)
for i in range(0, k):
x_list, y_list = a_plot(i, cluster)
color1 = ["g", "b", "r", 'k', 'y']
color2 = ["c", 'm', 'k', 'g', 'r']
style1 = ['v', 'o', '*', '>', '1']
label_list = ['survival', 'ordinary', 'aggressive']
str1 = color1[i]
str2 = color2[i]
ax_1.scatter(x_list, y_list, color=str1, marker=style1[i], label=label_list[i])
ax_1.grid()
# plt.scatter(centroids[i][0], centroids[i][1], color=str2, marker=style1[i])
print(centroids[i][0], centroids[i][1])
ax_1.set_xlabel('Extension Rate', size='14')
ax_1.set_ylabel('Moisture Niche Width', size='14')
ax_1.legend()
plt.savefig("fungi classification")
print('Saved')
plt.show()
df2 = pd.read_excel(r'D:\MCM2021\data\competitive ranking.xlsx')
cr = df2['ranking'].values
er = df2['extension'].values
fig = plt.figure(2)
ax = fig.add_subplot(1, 1, 1)
temx = []
temy = []
for m in range(10):
temx.append(er[m])
temy.append(cr[m])
ax.scatter(temx, temy, color='g', marker='v', label='survival')
print(temx)
temx = []
temy = []
for t in range(9):
temx.append(er[t+10])
temy.append(cr[t+10])
ax.scatter(temx, temy, color='b', marker='o', label='ordinary')
print(temx)
temx = []
temy = []
for y in range(15):
temx.append(er[y+19])
temy.append(cr[y+19])
ax.scatter(temx, temy, color='r', marker='*', label='aggressive')
print(temx)
ax.set_xlabel('Extension Rate', size='14')
ax.set_ylabel('Competitive Ranking', size='14')
ax.legend()
ax.grid()
plt.savefig('ER-CR')
plt.show()
结果图