关于numpy 操作
- 1.新增一个维度 np.newaxis 和 None
- 2. np设置print属性
- 3. np判断一个数是不是nan
- 4. np.array 多个掩码
- 5. numpy分块
- 6.矩阵的快速复制np.tile
- 7.生成一个所有数据都相同的数组
- 8.切片时保持数据维度
- 9. numpy实现padding功能
- 10. 多维数组某维度上调整顺序
- 11. 初始化为`nan或'NA'`
- 12.输出array中最大值/最小值的索引 ==np.unravel_index==
- 13.==np.unique==
- 14.关于numpy array的维度交换
- 15.==np.unpackbits==
- 16.np读取txt文件(structured data-type)
- 17.输出数组中各行第N大元素
- 参考文献
1.新增一个维度 np.newaxis 和 None
a=np.array([1,2,3]) #array([1, 2, 3])
a[:, np.newaxis] #array([[1],[2],[3]])
a[:, None] #array([[1],[2],[3]])
2. np设置print属性
这个功能还是比较赞的,可以设置整个python文件内numpy类型数据打印格式,使用起来不要太方便哦~
如:
np.set_printoptions(edgeitems=3, infstr='inf',
linewidth=75, nanstr='nan', precision=8,
suppress=False, threshold=1000, formatter=None)
其中:
- edgeitems: 数组开始/结束位置元素数目,Number of array items in summary at beginning and end of each dimension (default 3).
- precision: 设置浮点数位数
- suppress:如果为True,当前精度下接近0的数被设置为0
3. np判断一个数是不是nan
要使用np.isnan( ),官方解释nan只是一个 floating point representation of Not a Number。既然不是一个数,直接使用a==np.nan这个是不行的,也就能说通了。
import numpy as np
a=np.nan
print(a==np.nan)
#False
print(np.isnan(a))
#True
4. np.array 多个掩码
例如,求a和b中对应元素不相同且a中元素不为2的掩码。
import numpy as np
a=np.array([0,1,2])
b=np.array([0,2,1])
print((a!=b) & (a!=2))
#out:[False True False]
如果是“或”的关系,可以使用|.
5. numpy分块
使用np.lib.stride_tricks.as_strided.
需要注意,stride的设置与数据格式有关,这里置dtype=np.int8。则每个数据占1个字节,相应的stride各数再下方*1;
若无其他格式,如默认的np.int32,则需对应乘以4。
import numpy as np
X = np.arange(16, dtype=np.int8).reshape(4,4)
print("X:",X,"\n")
'''
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
'''
stride=np.array([8,2,4,1])*1
A = np.lib.stride_tricks.as_strided(X, shape=(2,2,2,2), strides=stride)
print("A:",A)
输出:
X: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
A: [[[[ 0 1]
[ 4 5]]
[[ 2 3]
[ 6 7]]]
[[[ 8 9]
[12 13]]
[[10 11]
[14 15]]]]
下面以一张图的来展示为什么stride=np.array([8,2,4,1])*1:
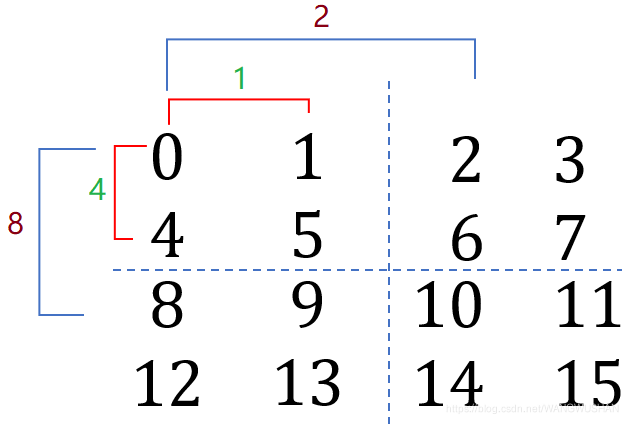
通过上图,可以看出来,这里的stride,其实就是分块后每个大块第一个元素行/宽的stride,及分割后小块的行/宽的stride。
6.矩阵的快速复制np.tile
如产生一个矩阵a:
import numpy as np
a=np.random.randint(5,size=(2,2))
#out:
array([[3, 4],
[4, 2]])
如果想要让它在第0维重复3次,该如何操作?
这个时候可以使用np.tile:
np.tile(a,(3,1))
#out:
array([[3, 4],
[4, 2],
[3, 4],
[4, 2],
[3, 4],
[4, 2]])
同样,可以对矩阵在多个方向同时进行复制:
np.tile(a,(2,2))
#out:
array([[3, 4, 3, 4],
[4, 2, 4, 2],
[3, 4, 3, 4],
[4, 2, 4, 2]])
和np.repeat的差别:
np.repeat(a,3,axis=0)
#Out:
array([[3, 4],
[3, 4],
[3, 4],
[4, 2],
[4, 2],
[4, 2]])
7.生成一个所有数据都相同的数组
比如,生成一个全为"NA"的数组。
np.full((2,2), fill_value='NA', dtype='<U3')
#out:
array([['NA', 'NA'],
['NA', 'NA']], dtype='<U3')
8.切片时保持数据维度
a=np.random.randint(0,5,(4,4))
#out:
array([[2, 4, 0, 2],
[1, 1, 2, 4],
[1, 3, 2, 3],
[1, 0, 3, 0]])
a[2]
#Out:
array([1, 3, 2, 3])
a[2:3]
#Out:
array([[1, 3, 2, 3]])
当然,使用np.newaxis之类的也是可以的,看个人喜好了~
9. numpy实现padding功能
def pad_with(vector, pad_width, iaxis, kwargs):
pad_value = kwargs.get('padder', 10)
vector[:pad_width[0]] = pad_value
vector[-pad_width[1]:] = pad_value
a = np.arange(6)
a = a.reshape((2, 3))
np.pad(a, 1, pad_with,padder=0)
#out:
array([[0, 0, 0, 0, 0],
[0, 0, 1, 2, 0],
[0, 3, 4, 5, 0],
[0, 0, 0, 0, 0]])
10. 多维数组某维度上调整顺序
import numpy as np
a=np.arange(12).reshape(2,2,3)
#out:
array([[[ 0, 1, 2],
[ 3, 4, 5]],
[[ 6, 7, 8],
[ 9, 10, 11]]])
在第3维数组上调整顺序
a[:,:,(2,1,0)]
#out:
array([[[ 2, 1, 0],
[ 5, 4, 3]],
[[ 8, 7, 6],
[11, 10, 9]]])
另外,img=img[:,:,::-1],将第三维数组顺序反转下,可用于图像BRG->RGB的操作。
11. 初始化为nan或'NA'
- 初始化为
'NA':
np.full((2,2), fill_value='NA', dtype='<U2')
#Out:
array([['NA', 'NA'],
['NA', 'NA']], dtype='<U2')
- 初始化为
np.nan
np.full((2,2), fill_value=np.nan)
#Out:
array([[nan, nan],
[nan, nan]])
12.输出array中最大值/最小值的索引 np.unravel_index
import numpy as np
a=np.array([[1,2],[3,4]])
print(np.unravel_index(a.argmax(), a.shape))
#(1, 1)
13.np.unique
numpy.unique(ar, return_index=False, return_inverse=False, return_counts=False, axis=None)
类似于python自带的set,输出排好序的唯一值。
np.unique还可设置return_index、axis等几个可以返回的参数。
a = np.array([[1, 0, 0], [1, 0, 0], [2, 3, 4]])
np.unique(a)
#Out: array([0, 1, 2, 3, 4])
14.关于numpy array的维度交换
两个维度之间交换可以用swapaxes,也可以用transpose。
import numpy as np
import torch
a=np.random.randint(0,5,(3,2))
b=a.swapaxes(0,1)
c=a.transpose(1,0)
输出结果:
#a:
array([[2, 1],
[0, 3],
[0, 3]])
#b:
array([[2, 0, 0],
[1, 3, 3]])
#c:
array([[2, 0, 0],
[1, 3, 3]])
注意维度交换和reshape是有差别的。
a.reshape(-1,3)
#Out:
array([[2, 1, 0],
[3, 0, 3]])
15.np.unpackbits
将无符号整数array变成对应的二进制bit格式:
import numpy as np
a=np.array([0,1,2,3,4,5,6,7],dtype=np.uint8)
b=np.unpackbits(a).reshape(-1,8)[:,-4:]
输出:
#Out:
array([[0, 0, 0, 0],
[0, 0, 0, 1],
[0, 0, 1, 0],
[0, 0, 1, 1],
[0, 1, 0, 0],
[0, 1, 0, 1],
[0, 1, 1, 0],
[0, 1, 1, 1]], dtype=uint8)
16.np读取txt文件(structured data-type)
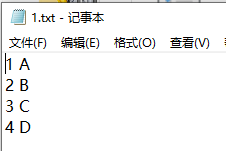
如上txt文件,每一行中既有数字,又有字符,读取时如果不设置dtype,则默认为dtype=<class 'float'>,就会报错。
16.1 强制为单一类型进行读取
import numpy as np
path=r'E:\1.txt'
np.loadtxt(path,delimiter=' ',dtype=str)
#out
# array([['1', 'A'],
# ['2', 'B'],
# ['3', 'C'],
# ['4', 'D']], dtype='<U1')
16.2 使用structured data-type读取
这种方法会保持某一列元素的数据类型。
import numpy as np
path=r'E:\1.txt'
np.loadtxt(path,delimiter=' ',dtype={
'names': ('indext', 'category'),'formats': ('i', '<U1')})
#out:
#array([(1, 'A'), (2, 'B'), (3, 'C'), (4, 'D')],
# dtype=[('indext', '<i4'), ('category', '<U1')])
这样就正确地读进来了。
当然也可以设置usecols参数,分开读取,也是没问题的。
17.输出数组中各行第N大元素
如下列数组:
a=np.random.randint(1,10,(3,3))
# array([[5, 2, 4],
# [6, 9, 1],
# [4, 2, 6]])
若是求最大值,很容易:
np.max(a,1)
# array([5, 9, 6])
若是求第N大/小值,如第2大值,可以尝试如下两种操作:
b=np.sort(a,1)
# array([[2, 4, 5],
# [1, 6, 9],
# [2, 4, 6]])
b[:,-2]
# array([4, 6, 4])
或者:
ai=np.argsort(a,1)
np.take_along_axis(a, ai, axis=1)[:,-2]
# array([4, 6, 4])
