摘要
人脸识别是一种可以在注册的人脸数据库中识别或验证查找某一人脸的算法。它给图像分析和计算机视觉领域提出了挑战,特别是对于处理视频序列、人脸重新识别或对强度图像进行操作并需要快速处理的应用程序。在这项工作中,我们介绍了一种高速人脸识别技术和一个高速FPGA实现。它使用一种新的相似度量来估计查询的人脸和数据库中人脸的距离。距离度量是多个直方图之间的标准偏差之和,这些直方图是从查询和数据库图像的每一行计算出来的。 最低距离分数是指与查询人脸所匹配的数据库人脸(间的距离)。该方法与环境光照无关,优于著名的人脸识别算法“Eigenfaces”(当两种算法在同一平台上运行时,其识别速度提高了16倍)。此外,我们利用我们提出的演算法中的资料平行性来设计硬体加速器,并在FPGA原型板上加以实现。结果表明,与软件版本相比,执行时间提高了10倍。
1 Introduction
随着计算机实时处理技术的发展,人们对动态环境下人脸识别的研究越来越感兴趣。由于其非侵入性和作为人类身份识别的主要方法,人脸识别是主要的生物识别技术之一[9]。由于图像捕捉设备(监控摄像机、移动电话中的摄像机)的快速发展、网络上大量人脸图像的可用性以及对更高安全性的要求的不断提高,它吸引了人们的极大兴趣。
光照、面部姿势、表情、年龄、头发颜色、面部穿着和运动等各种挑战都会影响人脸识别应用程序的性能[14,33]。然而,在大多数情况下,环境光照是大多数识别应用的首要挑战[30],尤其是如果图像/视频是从不同的摄像机拍摄以进行重新识别[3,17]。在这项工作中,我们介绍了一种新的人脸识别技术,它对环境光照是鲁棒的。
我们提出了一种新的基于标准差的人脸匹配技术,该技术以多幅人脸图像的直方图之间的距离函数为基础,解决了光照变化时性能下降的问题。该技术计算查询图像的每一行的直方图,然后找出该行直方图的标准差。然后比较标准差以找出图像之间的相似性。我们的技术可用于对象数据库中的任何对象识别,如道路交通标志[16]或比较立体视觉中的多个图像中的场景信息[23],我们的技术可与任何先前的最先进方法一起应用,以进一步提高其时间性能。
为了评估我们的技术,我们将其应用于Yale Face数据库[8],该数据库包含不同人脸的不同面部表情,并在不同的环境光照水平下测量性能。我们将该技术与最著名的人脸识别技术“Eigenfaces”的识别速度进行了比较,结果表明,当两种技术在同一平台上运行时,我们的技术比“Eigenfaces”快16倍。我们还提出了一种新的硬件加速器来提高人脸识别的速度,并在基于FPGA的平台上实现了该技术。
我们在这项工作中的软硬件贡献可以描述如下:
1.提出了一种新的基于行直方图标准差的相似性度量准则的人脸识别方法。无论环境照明度如何,新技术都能提供精确的结果。
2.与著名的人脸识别算法“Eigenfaces”相比,我们的技术明显减少了在不同的人脸数据库中识别一个查询人脸所需的时间。
3.利用该技术的数据并行性,并在FPGA原型板上实现,提出了一种新的硬件加速结构,极大地提高了处理速度。
论文的其余部分安排如下:在第2节,我们回顾了最近的相关工作,以突出我们的提案的新颖性。第3节介绍了我们新的基于多直方图的人脸识别算法的理论基础,并对所提出的算法进行了概述。第4节对所提出的人脸识别技术对光照的鲁棒性进行了实验评估。Gamma校正法是用来增加环境照度的。在第5节中,我们展示了如何利用所提出技术的数据并行性,并给出了FPGA硬件加速器的实现。第6节给出了实验结果和性能评估。我们在第7节结束这项工作。
2 相关工作
在这一部分,我们将回顾一些最新的人脸识别技术。我们从在加速FPGA平台上实现的应用程序开始。然后介绍了相关的人脸识别的一般实现方法。
人们已经做了许多尝试,用FPGA加速不同领域的识别过程[22,24]。[24]中的作者加速了自闭症谱系障碍儿童的面部情绪检测。这些孩子很难从面部理解情绪和心理状态。本文采用主成分分析(PCA)算法进行特征提取,并在virtex7 FPGA上实现,检测准确率达82.3%。在文献[13]中,作者提出了一种利用基于特征的方法来识别人脸的设计方案,该方法利用FPGA和PC机的结合来实现。FPGA捕获视频帧,提取人脸特征点的位置。计算机计算数据库中存储的每个人脸模板的不同得分,并找到最佳匹配。另一个尝试是在[22]中,作者提出了一个在家庭环境中快速原型化跌倒检测系统,该系统可用于帮助老年人的日常生活。他们的实现使用了一个摄像机和一个优化描述符适应实时任务使用系统芯片zynq FPGA。
在文献[27]中,作者提出了一种简单的基于球面散列(SHBC)的特征学习方法来学习二值人脸描述子。他们将学习到的二进制代码聚集并汇集到一个基于直方图的特征中,该特征描述了二进制代码的共现,并将基于直方图的特征作为每个人脸图像的最终特征表示。他们研究了他们的SHBC方法在不同人脸上的表现并得出结论,他们的SHBC描述符优于其他最先进的人脸描述符。在文献[12]中,作者提出了一种局部质心人脸(LCMF)方法来提取光照不敏感的人脸识别特征。LCMF提取选定邻域的质心和中心像素之间的梯度角。以质心与邻域中心像素之间的斜率角作为特征向量。他们使用这些特征向量的L1范数距离来对图像进行分类。他们的方法不涉及图像的训练。
在过去的几十年里,研究人员对解决人脸识别算法的准确性和复杂性的问题越来越感兴趣。从Pentland等人开创性的“Eigenfaces”开始。[29]Wolf等人的最新研究成果。在[26]中提出,DeepID由Wang等人。在[25]中,研究人员能够将识别率提高到近乎完美的程度。“Eigenfaces”是一种广泛用于人脸检测和识别的著名技术[21,28,29]。它的流行源于它的简单性和与其他技术相比的实时支持。判别特征仅仅是一组面孔的特征向量,而“Eigenfaces”这个名字就是从这个集合中产生的。
强度直方图作为一种统计图像描述[5],近年来一直受到研究界的关注[2,4,6,7]。文[6,7]提出了一种基于训练图像灰度直方图匹配的人脸识别方法。然而,如[6]所述的直接匹配并不能解释光照条件的变化。
人脸识别评估报告[18,19]以及上述相关工作的结论表明,许多最先进的人脸识别方法的性能随着光线、姿势和其他因素的变化而下降[20]。此外,像[1,15,29]中所述的线性方法无法保存区分个体所需的面流形。在本文中,我们提出匹配多行人脸图像的子直方图,并找出它们之间的标准偏差之间的差异,这种差异被发现对光照条件的变化是不变的。此外,它还便于在加速硬件上使用FPGA平台进行并行实现。
3 基于多直方图的人脸识别
提出了一种多直方图人脸识别方法。这里的多个直方图都是从图像的一行派生出来的,但是这个概念是在一个通用公式中提出的,以允许使用来自图像不同部分的多个直方图。在后文中,我们提出了图像直方图的概念,然后给出了图像的多个部分的直方图,特别是这些部分是图像的行。然后,我们提出了多个直方图之间的距离度量。
3.1 图像直方图的理论定义
假设图像 I ( x , y ) I(x,y) I(x,y)包含N行M列,像素总数为N×M,假设每个像素值 I ( x , y ) I(x,y) I(x,y)用8位表示,图像是单色图像,则 I ( x , y ) = r ∈ [ 0 , 255 ] I(x,y)=r∈[0,255] I(x,y)=r∈[0,255]。对于索引 i ∈ [ 1 , N M ] i∈[1,NM] i∈[1,NM]和坐标(x,y)的像素,颜色强度值表示为 I ( i ) = I ( x , y ) = r I(i)=I(x,y)=r I(i)=I(x,y)=r。
图像直方图是一个向量H®,表示离散变量r的所有可能值的出现次数 n r n_r nr。给定图像I(x,y)的直方图 H I ( r ) H_I(r) HI(r),可以用向量表示:
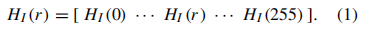
这个向量的每个元素都表示为:
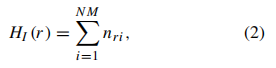
其中如果 I ( i ) = r , n r i = 1 I(i)=r,n_{ri}=1 I(i)=r,nri=1,否则 n r i = 0 n_{ri}=0 nri=0
我们在这项工作中的一个主要贡献是从人脸图像中使用单个行s∈[1,N]的直方图进行识别。特定行的直方图可以写成
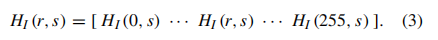
这个向量的每个元素都表示为:
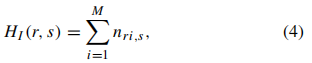
其中如果 I ( i ) = r , n r i , s = 1 I(i)=r,n_{ri,s}=1 I(i)=r,nri,s=1,否则 n r i , s = 0 n_{ri,s}=0 nri,s=0。注意这里 i ∈ [ 1 , M ] i∈[1,M] i∈[1,M],其中M是每行的像素数。
3.2 基于多直方图距离的人脸识别
我们提出了一种新的基于标准差的距离度量来比较两幅人脸图像。它具有很强的区分性,易于在加速的硬件平台上实现。在第4节中,所提出的方法经经验证明对照明条件的变化是鲁棒的。图像I中行s的直方图 H I ( s ) H_I(s) HI(s)的标准偏差 S T D I ( s ) STD_I(s) STDI(s)表示行s中出现的整个像素的强度与平均出现值的接近程度。具有大标准差的直方图具有分布在广泛值范围内的事件。图像I中行s的直方图 H I ( s ) H_I(s) HI(s)的标准偏差 S T D I ( s ) STD_I(s) STDI(s)在数学上定义如下:
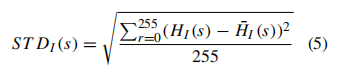
其中, H ¯ I ( s ) H¯_I(s) H¯I(s)是行直方图 H I ( r , s ) H_I(r,s) HI(r,s)的平均值。最终计算得出向量 S T D I STD_I STDI,它包含N个组件,每个组件代表图像I的第行的 S T D I ( s ) STD_I(s) STDI(s)。
给定一个查询人脸图像Q,任务是计算该图像到数据库中每个图像D的距离度量。我们提出的距离度量技术是 S T D Q STD_Q STDQ和 S T D D STD_D STDD之差的L1范数。这个距离也被称为城市街区距离度量。这些分别是查询图像和来自数据库的图像的标准偏差向量。数据库中每个图像对应的向量 S T D D STD_D STDD在离线步骤中计算,STDQ则在线计算。
从数学上讲,查询人脸“Q”和数据库人脸“D”之间的距离分数(DS)定义如下:
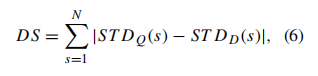
其中N是两个图像中每一个的行数, S T D Q ( s ) STD_Q(s) STDQ(s)是查询人脸图像的行直方图的标准偏差, S T D D ( s ) STD_D(s) STDD(s)是数据库人脸图像的行直方图的标准偏差。
下一节将概述所提出的算法。此外,我们将在下一节中说明,该距离度量对于改变光照条件是鲁棒的,并且不会对图像直方图的标准偏差估计产生显著影响。众所周知的Gamma校正方法被用来给图像添加照明效果。
3.3 我们的人脸识别技术
如第1节所述,我们的人脸识别技术涉及一对多匹配,将一个查询人脸与注册数据库中的多个人脸进行比较。在每次比较中,计算一个距离分数(在本节后面描述)。最低得分是指数据库中与查询最相似的人脸。我们的技术假设如下:
1.用户愿意合作,但他无法在相对于相机的有利条件下呈现面部。换句话说,我们的技术假设在查询人脸时不考虑面部姿势、表情、年龄跨度、头发、面部穿着和运动。
2.由于环境光照是大多数人脸识别应用的首要挑战,我们的技术在计算距离分数时考虑了这一因素。因此,改变光照强度不会影响我们的技术性能。用于改变图像环境光照的方法是伽马校正。
3.所有的面都是灰度级的,也就是说,每个像素都表示为8位值(0到255)。
如图1所示,我们提出的人脸识别算法经过以下步骤:

第一步,将一个新的查询人脸与注册数据库中的多个人脸进行比较,根据(4)和(2)分别计算查询人脸的每一行的直方图。为此,每一行被视为一个像素数组,相当于图像列的数量。每个像素可以是0到255之间的任意数字(像素值)。使用256个计数器从第一个像素扫描到最后一个像素。每个像素值一个计数器。每个计数器在遇到相同值的新像素时递增1。在扫描结束时,每个计数器在数组“hist”中存储了许多重复的像素值(bin count)。第五节介绍了直方图计算过程的硬件实现。此外,算法1提供用于计算图像行的直方图的伪代码。计算所有行的直方图后,每行直方图的标准差按(5)计算。
对于任何新的人脸、物体等数据库,直方图和标准差的计算必须离线完成(在设计阶段)。因此,花多长时间并不重要。

在下一步中,将计算查询和数据库面之间的距离分数,如(6)所示。它反映了查询面与数据库面的接近程度。分数越低意味着匹配越好。对数据库中注册的每个人脸图像重复此步骤,并计算其与查询人脸的距离分数。在我们技术的最后一步,比较器会比较距离分数并找到最小值。最小得分是指更接近查询面的数据库面。完整的硬件实现在第5节中介绍。
4 对光照鲁棒和Gamma方法
4.1 Gamma强度变换综述
Gamma是一个重要的因数,可以控制一个图像的强度水平。因此,gamma校正是一种非线性操作,广泛用于调节亮度通道,并生成具有不同亮度级别的图像[10]。Gamma相关技术可被视为直方图修改技术,可通过以下方式获得:
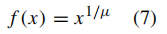
其中μ是Gamma值,x表示输入灰度值,f(x)表示图像的输出Gamma校正灰度值。这种方法对暗像素的增强效果要比亮像素大得多。图2显示了当图像的输入值从0变为1时,不同μ值(0.5、1、2和3)的输出Gamma校正灰度值。
 图2.不同Gamma值的Gamma校正方法
图2.不同Gamma值的Gamma校正方法
从图中可以看出,当μ=1时,输出值没有变化。要获得较暗的图像,μ值应小于1。在这种情况下,暗像素值比亮像素值减少(变暗)得多(参见图2,μ=0.5)。为了获得更亮的图像,μ应大于1。在这种情况下,暗像素值比亮像素值增加(变得更亮)(参见图2,μ=2和μ=3)。
4.2 该方法对环境光照的鲁棒性评估
为了评估我们的人脸识别技术,我们使用不同μ={1,0.5,2,3}的Gamma校正方法来改变查询图像的环境光照值。这些值分别对应于“不添加环境照明”、“添加黑暗环境照明”、“添加明亮环境照明”,以及“增加了更明亮的环境照明”。
如果查询人脸具有与数据库人脸不同的照明度,则直方图的差异将无法代表正确的比较。这是因为图像的像素值基于μ值增加/减少。例如,图3示出了不同μ值的查询人脸第一行的直方图:在图3a中,查询人脸没有附加的环境照明(μ=1)。此图中重复像素数最高的一个是“128”(像素计数=43)。当黑暗环境照明增加μ=0.5(图3b)时,直方图向左移动(朝向低像素值),高度重复的像素“128”(像素数=43)变为“64”(具有相同的像素计数)。将明亮的环境光照增加μ=2(图3c)使直方图向右移动(朝向高像素值)。现在,高重复像素变为“181”,其频率增加(像素数=44)。将μ值增加到3(图3d)使直方图进一步向高像素值移动。因此,高重复像素变为“202”,其频率增加(像素数=49)。

图3.不同μ值的查询人脸第一行的直方图和标准差:A:μ=1,B:μ=0.5,C:μ=2,D:μ=3
图3还显示了不同μ值的查询人脸直方图的标准偏差:在图3a中,第一行的直方图的标准偏差为25.92。在图3b中,STD几乎与图3a相同(实际上,两个值在小数部分的第三位数不同),因为μ的变化非常小(从1到0.5)。当μ=2(图3c)时,STD略微增加至25.951;当μ=3(图3d)时,STD增加至26.285。
从前面的讨论中,我们得出结论:使用Gamma校正方法改变图像的光照会改变直方图,但不会影响(或轻微影响)图像直方图的标准偏差。因此,如果查询人脸具有不同的照明级别,则标准差是比较查询人脸和数据库人脸的一个好选择。
5 FPGA实现
在这一部分中,我们将展示如何通过使用FPGA原型板来实现我们的人脸识别算法来提高它的时间性能。在实现该算法之前,我们首先要充分利用算法中的数据并行性,并在此基础上设计了一个基于数据并行的算法硬件加速器。
我们的算法可以通过两种方式来提高数据的并行性:首先,查询人脸的所有行都是独立的。这允许每一行与其他行并行处理。其次,计算直方图、标准差和距离分数是独立的。因此,可以在不同的阶段执行它们。
基于Xilinx1的FPGA-Zed板原型是实现该算法的一个很好的选择。该板包含ZYNQ-7000全可编程SoC FPGA[11],具有13300个逻辑片、220个DSP48E1和140个块的容量。Zynq芯片将ARM双核Cortex–A9 MPCore处理系统(PS)与Xilinx 28nm可编程逻辑(PL)相结合,用户可以在同一平台上创建自己的IP核奇普。那个两个部件通过提供高带宽的行业标准高级可扩展接口(AXI)互连相互通信,设备两部分之间的低延迟连接[31]。该电路板还包含512MB DDR3内存和一些其他外围设备,使用户能够对其嵌入式设计的各个方面进行实验。
图4显示了我们的在FPGA开发板上硬件实现流程图。它由以下IP块组成:

图4.我们的人脸识别算法在FPGA Zed板上的硬件加速器
–Zynq处理系统(PS),包括ARM处理器和DDR内存控制器。
–FPGA块RAM。
–AXI直接内存访问(DMA)。
–处理单元(PU)。
–功能单元(FU)。
–比较器IP。
查询人脸行(320×243像素)存储在DDR存储器中,块RAM用于存储每个数据库面的每行的STD。这些值仅在离线(设计时)计算一次。对于任何新的数据库人脸,必须计算每行的STD并将其存储在块RAM中。在图4中,如果我们的数据库有n个数据库人脸,则块RAM的每一行将具有n个STD值。每个值都引用相应数据库面的行的STD。
DMA通过高性能端口(HP)将数据从DDR内存传输到其他系统部件,而不干扰CPU。使用DMA将增加数据吞吐量,并将使处理器从涉及内存传输的任务中卸载。刚开始时需要处理器通过编程DMA控制器寄存器来启动传输。处理单元(PU)由两个IP块组成,即直方图和标准差(STD)。它通过DMA端口从DDR接收查询人脸行,并计算该行的直方图,然后计算该行的标准差。功能单元(FU)从PU中获取查询面的STD,从块RAM中获取数据库面的STD,然后根据(6)计算距离得分。它还将所有行的距离分数相加,找到查询面和数据库面之间的最后一个,然后将结果存储到寄存器中。例如,reg1将为每个数据库面以及仅对行1、5、9等的std求和。Reg2将得到行2、6、10等的结果,依此类推。比较器存储所有的距离分数,并找到与查询结果相匹配的数据库人脸的最小距离分数。算法2给出了在FPGA-Zed板上实现查询与数据库面匹配的硬件加速器伪码。

在FPGA Zed板中,高性能端口(HP)用于访问外部存储器(DDR3)。这些端口的最大带宽为4个端口×64位×150MHz=4.8GB/s。为了充分利用带宽,我们使用处理系统的四个32位DMA端口(HP0、HP1、HP2和HP3)从DDR接收数据,并将每个端口视为一个单独的线程。因此,我们的硬件加速器包含四个并行线程。每个线程由计算直方图和标准差的处理单元(PU)和计算距离分数的函数单元(FU)组成。因此,我们的加速器可以并行处理四行。
每个线程的执行经过不同的流水线阶段(见图5):开始时,第一行的直方图是通过第一个流水线阶段计算出来的。其他两个管道级是空的。一旦计算出直方图,第1行就被转移到第二阶段,并计算标准差。同时另一行进入直方图流水线阶段,以此类推。一旦DMA发送第3行并进入管道阶段,三个管道阶段将忙于计算。这将确保高水平的数据并行性,并将获得高执行性能。

图5.在硬件加速器中执行我们的算法的流水线阶段
我们的设计是在原型FPGA-Zed板上实现的,实验结果部分报告了执行时间和FPGA资源
6 实验结果
在这一节中,我们将展示我们的人脸识别技术的实验结果,并将其应用于Yale Face数据库[8]。测试的数据库包含480张人脸(320×243像素),包括8种不同的面部表情和4种不同的环境光照水平:原始水平(μ=1)、暗度(μ=0.5)、明亮度(μ=2)和明亮度(μ=3)。图6显示了没有环境光照(μ=1)的原始样本脸的八种不同面部表情(顶部)。图6还显示了相同的样本面,但有三个环境光照级别,即暗、亮和亮(底部)。对该方法的识别性能和识别效率进行了评估。

图6.不同面部表情(顶部)和不同环境光照水平(底部)的被测数据库样本
我们的技术与图像大小无关。它计算所有列中每一行的直方图,然后找到每一行图像的直方图的标准偏差。最后,我们的技术对每个图像行使用一个值(标准偏差),独立于许多列或行来计算距离分数
6.1 识别性能评估
我们技术的实验性能评估如图7、8、9、10、11、12、13和14所示。
哒啦啦啦啦啦啦,我就不写啦
7 总结
我们提出了一种新的技术来加速数据库中查询人脸的识别。用于评估的数据库包含来自Yale Face数据库的面部图像,具有不同的面部表情和环境噪声水平。我们的技术具有即使环境光照变化也能快速识别人脸的优点。我们将该方法与著名的人脸识别算法“特征脸”进行了比较,结果表明该算法的软件版本比“特征脸”算法识别数据库人脸的速度快16倍。我们也在一块FPGA-Zed板上实现了所提出的设计,并且表明所实现的硬件设计在FPGA资源利用率较低的情况下将软件版本提高了10倍(片查找表占18%,触发器寄存器占11%)。