目录
1背景与挖掘目标
客户关系管理是企业的核心业务。客户管理的关键在于客户分类。通过客户分类,区分无价值和高价值客户,再针对不同价值的客户制定个性化服务方案,不同的营销策略,将有限的企业资源集中于高价值客户,实现企业利润最大化。
面对激烈竞争,各个航空公司都推出了推广营销活动来吸引更多客户,国内某航空公司面临 旅客流失/竞争力下降和航空资源未充分利用等经营危机。
- 通过建立合理的客户价值评估模型,对客户进行分类,比较分析不同客户群体的价值并制定相应营销策略,提供个性化客户服务,是必须和有效的。
该航空公司已积累大量会员档案信息和乘坐航班记录,部分列见下:
1.1 航空信息属性表(一部分列)
- 客户基本信息
- MEMBER_NO: 会员卡号
- FFP_DATE: 入会时间
- FIRST_FLIGHT_DATE: 第一次飞行日期
- GENDER: 性别
- FFP_TLER: 会员卡级别
- WORK_CITY: 工作地城市
- WORK_PROVINCE: 工作地省份
- WORK_COUNTRY: 工作地国家
- AGE: 年龄
- 乘机信息
- FLIGHT_COUNT: 观测窗口内的飞行次数(观测窗口:观测的时间段)
- LOAD_TIME: 观测窗口的结束时间
- LAST_TO_END: 最后一次乘机时间至观测窗口结束时长
- AVG_DISCOUNT: 平均折扣率
- SUM_YR: 观测窗口的票价收入
- SEG_KM_SUM: 观测窗口的总飞行公里数
- LAST_FLIGHT_DATE: 末次飞行日期
- AVG_INTERVAL: 平均乘机时间间隔
- MAX_INTERVAL: 最大乘机间隔
- 积分信息
- EXCHANGE_COUNT: 积分兑换次数
- EP_SUM: 总精英积分
- PROMOPTIVE_SUM: 促销积分
- PARTNER_SUM: 合作伙伴积分
- POINTS_SUM: 总累计积分
- POINT_NOTELIGHT: 非乘机的积分变动次数
- PB_SUM: 总基本积分
根据这些数据,实现以下目标:
- 根据数据,对客户进行分类
- 对不同的客户类别进行特征分析,比较不同类客户的客户价值
- 对不同价值的客户类别提供个性化服务,指定相应营销策略
1.2 分析方法和过程
本案例目标是客户价值识别,识别客户价值最广泛的模型是通过三个指标进行客户细分,识别高价值客户,简称RFM模型
- 最近消费时间间隔,Recency
- 消费频率,Frequency
- 消费金额,Monetary
- 一段时间内,客户购买该企业产品金额的总和
- 由于航空票价受运输距离/仓位等级等多种因素影响,消费金额指导意义不大(如一个长航线低等仓位旅客与一个短航线高等仓位旅客,前者花费大但后者对航空公司可能更有价值。
- 我们选择
- 客户在一定时间内累积的飞行里程M
- 客户在一定时间内乘坐仓位所对应的折扣系数平均值C
两个指标代替消费金额。
此外,航空公司会员入会时间长短也能够影响客户价值,模型中增加客户关系长度L
总之:5个指标作为航空公司识别客户价值指标,记为LRFMC模型
航空公司LRFMC模型

- L:会员入会时间距观测窗口结束的月数
- R:客户最近一次乘坐公司飞机距观测窗口结束的月数(最近消费时间间隔)
- F:客户在观测窗口内乘坐公司飞机的次数
- M:客户在观测窗口内累计的飞行里程
- C:客户在观测窗口内乘坐仓位所对应的折扣系数的平均值
本例采用聚类来识别客户价值,通过5个指标进行K-Means聚类,识别出最有价值客户
航空客运信息挖掘主要包含以下步骤:
- 从航空公司数据源种进行选择性抽取与新增数据抽取,分别形成历史数据和增量数据
- 对上面两个数据集进行数据探索和预处理,包括缺失值异常值处理,属性规约,清洗/变换
- 利用完备数据,基于旅客价值LRFMC模型进行客户分群,对各个客户群进行特征分析,识别有价值客户
- 针对模型结果得到不同价值的客户,采用不同营销手段,提供定制化服务
- 导入需要用的库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
- 读取一下文件,parse_dates将目标列设置成日期格式
# 读取
data = pd.read_csv(r'data\air_data.csv',parse_dates=['FFP_DATE','FIRST_FLIGHT_DATE','LOAD_TIME','LAST_FLIGHT_DATE'])
data

- 检查数据类型
data.info(),data.shape


- 查看基本统计数据并手动计算缺失值
# 查看基本统计数据
explore = data.describe().T
explore
# 手动计算缺失值
# data.shape[0] # 客户量
# explore['count'] #统计有效计数量
explore['null'] = data.shape[0] - explore['count']
explore

# 指定列检查
e1 = explore[['null','max','min']]
e1

2 数据预处理
主要用数据清洗/属性规约和数据变换的预处理方法
数据清洗:数据中有缺失值,或 票价最小值为0,或(折扣率最小值为0 和 总飞行公里数大于0)的记录,
由于原始数据量大,这类数据比例很小,丢弃处理
- 丢弃票价为空的记录
- 保留:票价不为0,或 平均折扣率 和 总飞行公里数都大于0 的记录
# 删除两列票价值为空的数据行
data = data[(data['SUM_YR_1'].notnull()) & (data['SUM_YR_2'].notnull())]
data
数据量减少

- 删除两列票价值为0的数据行
- 保留:票价不为0,或 平均折扣率 和 总飞行公里数都大
# 删除两列票价值为0的数据行
# 保留:票价不为0,或 平均折扣率 和 总飞行公里数都大于0 的记录
index1 = data.SUM_YR_1 != 0
index2 = data.SUM_YR_2 != 0
index3 = (data.avg_discount == 0) & (data.SEG_KM_SUM == 0)
data = data[index1|index2|index3]
data
数据量再一次减少

- 属性规约:原始数据中属性太多,根据LRFMC模型,只保留和模型指标相关的6个属性
- FFP_DATE
- LOAD_TIME
- FLIGHT_COUNT
- avg_discount
- SEG_KM_SUM
- LAST_TO_END
# 属性规约:原始数据中属性太多,根据LRFMC模型,只保留和模型指标相关的6个属性
data2 = data[['FFP_DATE', 'LOAD_TIME', 'FLIGHT_COUNT', 'avg_discount', 'SEG_KM_SUM', 'LAST_TO_END']]
data2

- 数据变换:将数据转为适当的个数,以适应算法挖掘需要,本例采用属性构造和数据标准化方式
原始数据没有直接给出LRFMC五个指标,需要通过数据自行计算提取指标
L = LOAD_TIME - FFP_DATE,会员入会时间距观测窗口结束的月数 = 观测窗口结束时间 - 入会时间
R = LAST_TO_END,客户最近一次乘坐飞机距观测窗口结束的月数 = 最后一次乘机时间至观测窗口末端时长
F = FLIGHT_COUNT,客户在观测窗口内乘坐公司飞机的次数=观测窗口的飞行次数
M = SEG_KM_SUM,客户在观测时间内在公司累计飞行里程=观测窗口的总飞行公里数
C = avg_discount,客户在观测时间内乘坐仓位所对应的折扣系数的平均值=平均折扣率
- 检查数据类型
data2.info()

- 其他指标改列索引
# 其他指标改列索引
data3 = data2.rename(columns={
'FLIGHT_COUNT': 'F', 'avg_discount': 'C', 'SEG_KM_SUM': 'M', 'LAST_TO_END': 'R'}).drop(['FFP_DATE', 'LOAD_TIME'], axis=1)
data3

- 增加指标L
日期相减之后保留下来的值还是日期格式
# 增加指标L
data3['L'] = (data2.LOAD_TIME - data2.FFP_DATE).map(lambda x: x.days) # 时间相减,取日(padnas时间间隔默认没有月)
data3

- 按列重新排序
# 按列重新排序
data3 = data3.reindex(columns=['L','R','F','M','C'])
data3.head()

3 描述性分析
这里只做基本分析,同学们可进一步拓展内容
- 指标计算
# 描述性分析
# 指标计算
data3.describe().loc[['min','max']]

data3.mean(axis=0)

data3.std(axis=0)
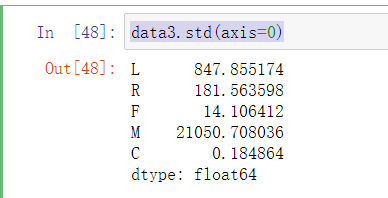
提取指标后,对每个指标数据分布情况进行分析,数据取值范围见下,可见指标数据差异较大,为消除数量级的影响,需对数据进行标准化处理
3.1 数据标准化方法,这里用 z-score
- z-score =(x - x_mean) / x_std
z-score会将数据按比例缩放,使之落入一个特定区间(平均值为0,标准差为1),
且保留本列数据之前,不同列数据之间的关系(大小差异、分布)
# 数据标准化
data4 = (data3-data3.mean()) / data3.std()
data4

data4.mean()

data4.std()

- 可视化
# 可视化
plt.scatter(data3.L,data3.R,s=1,alpha=0.1)

标准化之后的结果是一样的,x轴坐标不一样
plt.scatter(data4.L,data4.R,s=1,alpha=0.1)

- 直方图
data3.L.hist()

data4.L.hist()

- 查看5列特征的分布情况,看下区分度如何
# 查看5列特征的分布情况,看下区分度如何
data4.plot.kde(figsize=(16,16))
plt.xlim([-2,3])
- F和M两列特征分布高度重合,没有区分度
- C区分度最高
- 其他2列特征区分度还行

- 配对图,分布矩阵
# 配对图,分布矩阵
import seaborn as sns
sns.pairplot(data4)

3.2 模型构建
- 根据5个指标,对客户进行聚类分群
- 结合业务对每个客户群进行特征分析,分析客户价值,并对每个客户群进行排名
3.2.1 客户聚类
- 采用K-Means聚类算法对客户进行分群,聚成5档(需结合业务理解和数据预分析来确定客户的类别数量)
K-Means聚类是随机选择类标号,算法精度问题等,重复实验得到的结果会略有不同
- K-Means聚类 把一大坨分不开的点分成一堆一堆的就是聚类,具体算法原理后面的机器学习阶段有详细介绍
# 模型构建
# K-Means聚类 把一大坨分不开的点分成一堆一堆的就是聚类,具体算法原理后面的机器学习阶段有详细介绍
from sklearn.cluster import KMeans
kmodel = KMeans(n_clusters=5)
kmodel.fit(data4)

- 聚类中心
# 聚类中心
for i in kmodel.cluster_centers_: # 行是5个客户群,列是5个聚类属性中心,5维:LRFMC
print('聚类类别:')
# print(i)
for k,v in zip(['L', 'R', 'F', 'M', 'C'],i):
print(k,'---',v)

- 各样本对应类别,查询数据
# 各样本对应类别,查询数据
kmodel.labels_,kmodel.labels_.shape

- 各个类别聚类个数
# 各个类别聚类个数
# np.bincount(kmodel.labels_).sum()
np.bincount(kmodel.labels_)
pd.Series(kmodel.labels_).value_counts()

- 将特征降维绘制直观散点图
将5维特征降为2维,绘制散点图查看聚类的直观结果
# PCA降维
from sklearn.decomposition import PCA
先不聚类,看下各个特征的方差百分比(各个维度相对总数据的区分度/贡献率,总和为1)
# 先不聚类,看下各个特征的方差百分比(各个维度相对总数据的区分度/贡献率,总和为1)
pca = PCA(n_components=5)
pca.fit(data4)

方差百分比
# 方差百分比
pca.explained_variance_ratio_

5维降2维
# 5维降2维
pca2 = PCA(n_components=2)
pca2.fit(data4)
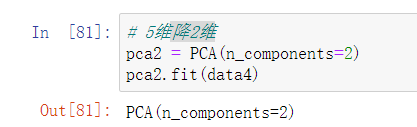
降2维后方差百分比,聚类后只保留了原信息的约64%
# 降2维后方差百分比
pca2.explained_variance_ratio_
pca2.explained_variance_ratio_.sum() # 聚类后只保留了原信息的约64%
- 将降维后的2维数据进行可视化
X_new = pca2.transform(data4)
X_new

plt.figure(figsize=(9,9))
plt.scatter(X_new[:,0],X_new[:,1],alpha=0.1,s=5,c=kmodel.labels_)
plt.xlim([-3,6])
plt.ylim([-3,4])

3.3 客户价值分析
客户分类完成后,对分好类的客户进行描述性分析
客户群体并不是简单的分三六九等,而是不同指标不同侧重,应该根据每个指标,对每个客户群进行分别比较
LRFMC模型:
- L:客户关系长度(航空公司会员入会时间长短)
- R:最近消费时间间隔
- F:消费频率
- M:累积的飞行里程
- C:乘坐仓位对应的折扣系数平均值
结合业务,通过比较各个指标在群间的大小,对某一个群的特征进行评价分析
雷达图,5个维度,5个客户群
例如客户群1在F/M属性最大,R最小,因此可以说F/M/R在客户群1是优势特征(区分度)
类推,FMR在客户群3是劣势特征
总结出每个群的优势和劣势特征
- 目前分类好的客户类型,即模型的标签
# 客户价值分析
# 目前分类好的客户类型,即模型的标签
kmodel.labels_
赋予新列,添加值进去
# 赋予新列,添加值进去
data4['cate'] = kmodel.labels_
data4

- 指标计算
# 指标计算
data4.groupby('cate').agg(['min', 'max', 'mean', 'median']).T

综合比较各个指标,决定使用平均值作为最终评价指标
# 综合比较各个指标,决定使用平均值作为最终评价指标
x = data4.groupby('cate').mean()
x
和刚刚添加的指标计算出来的数值的一样的

- 5个客户群体,每个群体的5个特征大小情况
# 5个客户群体,每个群体的5个特征大小情况
# 每类客户5个指标的不同数值
x.plot.bar()
每类客户5个指标的不同数值

- 5个指标中5种类型客户的比较数值
# 5个指标中5种类型客户的比较数值
x.T.plot.bar()

3.3.1 使用pyecharts绘制雷达图
PyEcharts是一个Web前端绘图库(Echarts)的Python版本,主要用于绘制显示在浏览器端的、和用户交互的统计图表
- https://echarts.apache.org/examples/zh/index.html
- https://pyecharts.org/#/zh-cn/intro
我们找一下能用的雷达图
基本图表

以下是目前得到的统计类数据
data4.groupby('cate').agg(['min', 'max', 'mean', 'median']).T

- 仍然使用平均值作为最终评价指标
- 传入PyCharts的数据必须是Python原生数据类型,该雷达图需要的数据要以列表嵌套列表的形式输入
# 传入PyCharts的数据必须是Python原生数据类型
x.loc[0].tolist() # series转list
# 该雷达图需要的数据要以列表嵌套列表的形式输入
[x.loc[0].tolist()]
- 画出雷达图
# 传入PyCharts的数据必须是Python原生数据类型
x.loc[0].tolist() # series转list
# 该雷达图需要的数据要以列表嵌套列表的形式输入
[x.loc[0].tolist()]

from pyecharts import options as opts
from pyecharts.charts import Page, Radar
def radar_base() -> Radar:
c = (
Radar()
.add_schema(
schema=[
opts.RadarIndicatorItem(name="L:会员时长", min_=-2, max_=1.5),
opts.RadarIndicatorItem(name="R:消费间隔", min_=-2, max_=2),
opts.RadarIndicatorItem(name="F:消费频率", min_=-2, max_=3),
opts.RadarIndicatorItem(name="M:飞行里程", min_=-2, max_=3),
opts.RadarIndicatorItem(name="C:折扣系数", min_=-2, max_=2.5),
]
)
.add("客户群1", [x.loc[0].tolist()], color='#ff0000')
.add("客户群2", [x.loc[1].tolist()], color='#00ff00')
.add("客户群3", [x.loc[2].tolist()], color='#0000ff')
.add("客户群4", [x.loc[3].tolist()], color='#ffff00')
.add("客户群5", [x.loc[4].tolist()], color='#ff00ff')
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title="客户价值 - 雷达图"))
)
return c
radar_base().render_notebook()

- 5个客户群的用户数
# 5个客户群的用户数
sort = pd.Series(kmodel.labels_).value_counts()
sort

其中,前三类客户可以归入客户生命周期管理的发展期、稳定期、衰退期 三个阶段
- 客户价值排名
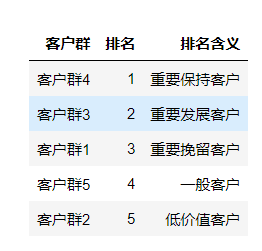
描述:每个客户群在每个指标上的大小(较大的和较小的,因为区分度)
每次运行客户群和特征对应是随机的,所以代码每次执行客户群和描述都不对应,根据实际情况写
- 客户群3:L会员时长最大;其他特征较均匀(比较小)
- 客户群5:R消费间隔最大,其他较均匀
- 客户群4:F消费频率/M平均里程最大,C折扣系数/L会员时长第二大,R消费间隔最小
- 客户群1:C折扣系数最大,其他特征较均匀
- 客户群2:5个特征都较均匀(较小)
LRFMC模型
- L:客户关系长度(航空公司会员入会时间长短)(老会员,越长越稳定)
- R:最近消费时间(上次坐飞机的时间,越小越好)
- F:消费频率(越大越好)
- M:累积的飞行里程(越大越好)
- C:乘坐仓位对应的折扣系数平均值(越大,意味着仓位档次越高)
3.3.2 用户画像
由上述特征分析的图表说明每个客户群都有显著不同的表现特征,基于特征描述,本例定义了5个等级的客户类别
- 客户群4:重要保持客户
- C 折扣率最高,表明仓位等级最高
- 其他指标较平均
- 这类客户是对航空公司最重要的VIP客户群,最理想的高价值客户类型,对公司贡献最大,所占比例最小
- 航空公司应该将资源优先投放到它们身上,对它们进行差异化管理和一对一营销,设法提高客户的忠诚度和满意度,尽可能延长这类客户的高水平消费
- 客户群3:重要发展客户
- F消费频率和M飞行里程最高
- C折扣系数/L会员时长,第二高
- R消费间隔最低,意味着上次坐飞机离现在很近
- 这类客户是公司潜在高价值客户,虽然这类客户当前的价值并不是最高,但却有很大发展潜力,公式要努力促使这类客户通过增加在本公司的乘机消费和合作伙伴处的消费(增加客户的钱包份额)。
- 通过客户价值的提升,加强客户满意度,提高他们转向竞争对手的转移成本,使他们逐渐转为公司的忠诚客户
- 客户群1:重要挽留客户
- L会员时长最长,老客户,其他特征一般
- 这类客户不确定性很高,这些客户衰退的原因不明,所以掌握客户最新信息、维持与客户的互动尤为重要。
- 航空公司应该根据这些客户最近的消费时间、消费次数变化情况,推测客户消费的异动状况,并列出客户名单,对其重点联系,采取一定的营销手段,延长客户的生命周期
- 客户群5:一般客户
- 所有指标都很平均,表明用户对公司没有太大贡献
- R较小,表面乘坐间隔短
- 他们是航空公司的一般客户,没什么价值但经常乘坐,应设法吸引它们提升消费等级
- 客户群2:低价值客户
- 各种指标全面低,注册时间短,里程少,消费频率低,打折比例低
- 唯独R高,较长时间没做过本公司航班了
- 他们是航空公司低价值客户,对公司没有归属感,只有在公司机票打折促销时候才会乘坐本公司航班
4 结论和建议
根据对各个客户群进行特征分析,采取下面营销手段和策略,为航空公司的价值客户群管理提供参考
- 会员的升级与保级
- 航空公司会员可分为:白金卡会员、金卡会员、银卡会员、普通卡会员,其中非普通卡会员可以统称为航空公司精英会员
- 各个公司会员制管理方法大同小异。成为精英会员一般要求在一定时间内(如1年)积累一定飞行里程或航段,达到要求后就会在有效期内(一般2年)成为精英会员并享受相应服务,有效期快结束时,根据相关评价方法确定客户是否有资格继续作为精英会员,然后对客户进行升级或降级
- 然而由于大部分客户没有意识到或根本不了解会员升级后保级的时间与要求(介绍文件往往复杂且不易理解),经常在评价期过后才发现自己只差一点就可以升级或保级,之前积累的里程白白损失,还会导致客户不满,干脆放弃在本公司的后续消费
- 因此公司可以在对会员升级或保级进行评价的时间点之前,对那些接近但尚未达到要求的较高消费客户进行适当提醒甚至采取一些促销活动,刺激消费,既可以获得收益,也能提高客户满意度,增加精英会员数量
- 首次兑换
- 航空公司旅客计划中比较吸引客户的一点是客户可以通过消费累计的里程来兑换免票或免费升舱。
- 大部分公司的里程积累会随着时间削减,如在年末对该年累计里程折半处理。
- 这样会导致许多不了解情况的会员白白损失掉费力积累的里程,总是难以实现首次兑换。同样会引起客户的不满
- 解决:提取接近但尚未达到首次兑换标准的会员,对他们进行提醒或促销,使他们通过消费达到标准
- 一旦实现首次兑换,客户在本公司再次消费兑换就比在其他公司进行兑换要容易的多,等于提高了转移成本
- 交叉销售
- 通过发现联名卡等与非航空类企业的合作,使客户在其他企业消费过程中获得本公司的积分,增强与公司的联系,提高忠诚度,
- 例如可以查看重要客户在非航空类合作伙伴处的里程积累情况,找出他们习惯的里程积累方式(是否经常在合作伙伴处消费,更喜欢消费哪种类型合作伙伴的产品),对他们进行相应促销
客户识别期和发展期为客户关系打下基石,但这两个时期的客户关系是短暂的、不稳定的,企业要获取长期利润,必须有稳定的、高质量的客户。保持客户对企业是至关重要的。
- 不仅因为争取一个新客户的成本远高于维持老客户
- 还因为客户流失会造成公司收益的直接损失
因此,在这一时期,公司应该努力维系客户关系,使之处于较高水准,最大化生命周期内公司与客户的互动价值,并使这样的高水平关系尽可能延长。
对这一阶段的客户,主要通过提供优质服务产品和提高服务水平来提高客户满意度。
4.1 用户画像
通过对旅客数据的挖掘、客户细分,可获得重要客户的保持名单。这类客户一般
- 所乘航班平均折扣率(C)较高
- 最近乘坐过本公司航班(R)低
- 乘坐频率 F或里程 M 也较高
他们是航空公司的价值客户,最理想的客户类型,对航空公司的贡献最大,所占比例却极小
公司应该优先将资源投放到他们身上,对他们进行差异化管理和一对一营销,提高这类客户的忠诚度与满意度,尽可能延长这类客户的高水平消费
5 拓展思考
后续拓展思考,进阶分析
5.1 客户流失分析:构建客户流失模型
本例主要对客户价值进行分析,对客户流失没有具体分析,
客户流失对例如增长造成的负面影响,仅次于 公司规模、市场占有率和单位成本的影响,获得一个新客户,需要在销售、市场、广告、人员工资上花费很多,且大部分新客户产生的利润不如流失的老客户多
因此,航空公司应该对客户流失引起足够重视,如何改善流失问题,提高客户满意度/忠诚度是航空公司维护自身市场并面对激烈竞争的一件大事,
客户流失分析将成为帮助航空公司开展持续改进活动的指南
客户流失分析可以针对目前老客户进行分类预测。针对客户信息数据(data表)可以进行老客户以及客户类型的定义
- 将飞行次数大于6次的客户定义为老客户,
- 已流失客户定义为:第二年飞行次数与第一年飞行次数比例小于50%的客户
- 准流失客户定义为:第二年飞行次数与第一年飞行次数比例在[50%, 90%)内的客户
- 未流失客户定义为:第二年飞行次数与第一年飞行次数比例大于90%的客户
同时,需要选取客户信息中的关键属性,如会员卡级别/客户类型(流失/准流失/未流失)/平均乘机时间间隔/平均折扣率/积分兑换次数/非乘机积分总和/单位里程票价/单位里程积分等等,随机选取数据的80%做分类训练样本,剩余20%做测试样本,构建客户流失模型,运用模型预测未来客户的类别归属(三种流失情况)
5.2 模型的实际应用
本模型采用历史数据建模,随着时间变化,分析数据的观测窗口也在变换
因此对应新增客户的分析,考虑业务实际情况,该模型检验一个月运行一次,对新增客户信息通过聚类中心进行判断,同时对本次新增客户的特征进行分析。
如果增量数据的实际情况与判断情况差异大,需要业务部门重点关注,查看变化大的原因以及确认模型的稳定性。如果模型稳定性变化大,需要重新训练模型进行调整。目前模型重新训练的时间没有统一标准。大部分都是根据经验决定。根据经验,每个月能训练一次模型比较合适