一.引言
本篇文章是根据航空公司提供的乘客个人信息,通过建立合理的客户价值评估模型,对客户进行分群,比较分析不同客户群的特点和价值,来指定相应的营销策略,从而减少客户流失,挖掘出潜在客户,实现盈利。在这里是用K-means聚类方法来对乘客进行分群的。
源数据部分如下图所示:

各属性解释如下:

二.数据探索
通过调用describe()函数对数据进行一个大致的了解,主要是查看缺失值和异常值。通过观察发现,存在票价为零,折扣率为0,总飞行数为0的情况。通过简单处理,我输出了一个包含个属性空值个数,最大值,最小值数据的表格。部分如下:
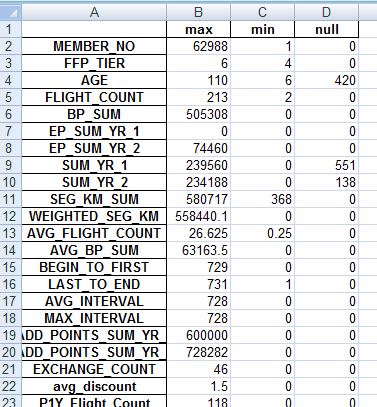
对应代码:
import pandas as pd datafile='D:/航空公司客户价值分析/data/air_data2.csv' resultfile='D:/航空公司客户价值分析/explore.xls' data=pd.read_csv(datafile) explore=data.describe().T#对数据的统计性描述,T是我进行了转置 explore['null']=len(data)-explore['count'] df=explore[['max','min','null']] df.to_excel(resultfile)
三.数据预处理
1.数据清洗
通过上一步的数据探索分析发现数据中存在缺失值,而这一部分的比例相对较小,故直接删掉。具体处理如下:
- 丢弃票价为空的记录
- 丢弃票价为0,平均折扣率不为0且总飞行公里数大于零的记录。
2.属性规约与数据变换
原始数据中的属性太多。而评估航空公司客户价值通常根据LRFMC模型,与其相关的只有6个属性即,FFP_DATE、LOAD_TIME、FLIGHT_COUNT、AVG_DISCOUNT、SEG_KM_SUM、LAST_TO_END。
简单介绍下LRFMC模型,即客户关系长度L、消费时间间隔R、消费频率F、飞行里程M和折扣系数的平均值C。这五个指标为评价客户价值的重要因素,而上面6个属性与这5个指标的关系如下:
- L=LOAD_TIME-FFP_DATE
会员入会时间距观测窗口结束的月数=观测窗口结束的时间-入会时间
- R=LAST_TO_END
- F=FLIGHT_COUNT
- M=SEG_KM_SUM
- C=AVG_DISCOUNT
客户在观测时间内乘坐舱位所对应的折扣系数的平均值=平均折扣率
提取了相关的数据后,发现这5个指标的取值范围相差较大所以需对数据进行标准化处理。
代码如下:
import pandas as pd
import datetime
#数据清洗
#删除空值,异常值
datafile='D:/航空公司客户价值分析/data/air_data2.csv'
resultfile='D:/航空公司客户价值分析/data_cleaned.csv'
data=pd.read_csv(datafile)
data=data[data['SUM_YR_1'].notnull()&data['SUM_YR_2'].notnull()]#剔除掉票价为空的
#保留票价非零的或者折扣率和飞行公里数同时为0的
index1=data['SUM_YR_1']!=0
index2=data['SUM_YR_2']!=0
index3=(data['SEG_KM_SUM'])==0&(data['avg_discount']==0)
data=data[index1|index2|index3]
data.to_csv(resultfile,encoding = 'utf_8_sig')#输出为utf8格式,不然excel打开中文会乱码
#属性规约与数据变换
#根据航空公司的LRFMC价值指标,删除掉无关属性
d1,d2=[],[]
for x in data['LOAD_TIME']:
d1.append(datetime.datetime.strptime(x,'%Y/%m/%d'))
for y in data['FFP_DATE']:
d2.append(datetime.datetime.strptime(y,'%Y/%m/%d'))
d3=[d1[i]-d2[i] for i in range(len(d1))]
data['L']=[round((x.days/30),2) for x in d3]
data2=data[['L','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']]
data2.columns=['L','R','F','M','C']
data2.to_csv('D:/航空公司客户价值分析/zscoredata.csv',encoding = 'utf_8_sig',index=False)
输出为:
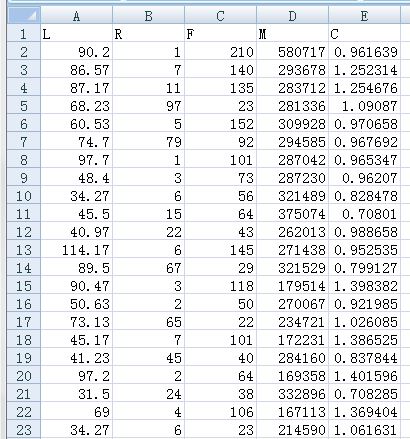
将以上数据进行零—均值标准化:
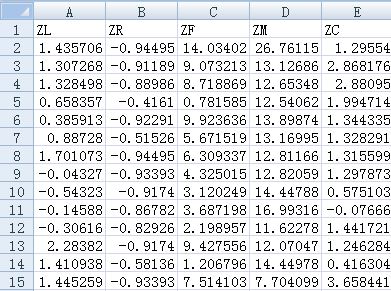
import pandas as pd datafile='D:/航空公司客户价值分析/zscoredata.csv' resultfile='D:/航空公司客户价值分析/standard_data.csv' data=pd.read_csv(datafile) data=(data-data.mean(axis=0))/(data.std(axis=0)) data.columns=['Z'+i for i in data.columns] data.to_csv(resultfile,encoding = 'utf_8_sig',index=False)
此时输出为:
四.模型构建
客户价值分析模型由两个部分构成。第一个部分是根据航空公司客户5个指标,对客户进行聚类分群,第二部分是对分群后的客户群进行特征分析,并对客户群的客户价值进行排名。
1.K-Means聚类算法对客户数据进行分群,k=5,即把客户分成5类。k-means位于scikit-Learn库中,需要先安装这个库。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.externals import joblib
from sklearn.cluster import KMeans
if __name__=='__main__':#防止模块范围内的代码在子进程中被重新执行,因为Windows中没有fork()函数
datafile='D:/航空公司客户价值分析/standard_data.csv'
resultfile='D:/航空公司客户价值分析/kmeans.csv'
k=5
data=pd.read_csv(datafile)
#调用K-Means方法进行聚类分析
kmodel=KMeans(n_clusters=k,n_jobs=4)#n_jobs是并行数,一般赋值为电脑的CPU数。
# #save model
# joblib.dump(kmodel,'kmeans.model',compress=3)
# #load model to model
# model=joblib.load('kmeans.model')
kmodel.fit(data)
r1=pd.Series(kmodel.labels_).value_counts()
r2=pd.DataFrame(kmodel.cluster_centers_)
r3=pd.Series(['客户群1','客户群2','客户群3','客户群4','客户群5',])
r=pd.concat([r3,r1,r2],axis=1)
r.columns=['聚类类别','聚类个数']+list(data.columns)
r.to_csv(resultfile,encoding = 'utf_8_sig',index=False)
输出聚类分析结果:
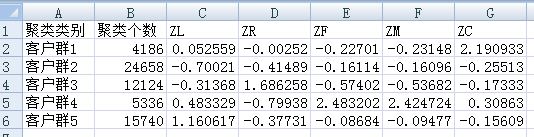
上图可以看到各个类群的客户个数,及聚类中心。
2.客户价值分析
针对上面的聚类结果,对客户进行特征分析,绘制雷达图。
#绘制雷达图
labels = np.array(list(data.columns))#标签
dataLenth = 5#数据个数
r4=r2.T
r4.columns=list(data.columns)
fig = plt.figure()
y=[]
for x in list(data.columns):
dt= r4[x]
dt=np.concatenate((dt,[dt[0]]))
y.append(dt)
ax = fig.add_subplot(111, polar=True)
angles = np.linspace(0, 2*np.pi, dataLenth, endpoint=False)
angles = np.concatenate((angles, [angles[0]]))
ax.plot(angles, y[0], 'b-', linewidth=2)
ax.plot(angles, y[1], 'r-', linewidth=2)
ax.plot(angles, y[2], 'g-', linewidth=2)
ax.plot(angles, y[3], 'y-', linewidth=2)
ax.plot(angles, y[4], 'm-', linewidth=2)
plt.rcParams['font.sans-serif']=['SimHei']
ax.legend(r3,loc=1)
ax.set_thetagrids(angles * 180/np.pi, labels, fontproperties="SimHei")
ax.set_title("matplotlib雷达图", va='bottom', fontproperties="SimHei")
ax.grid(True)
plt.show()
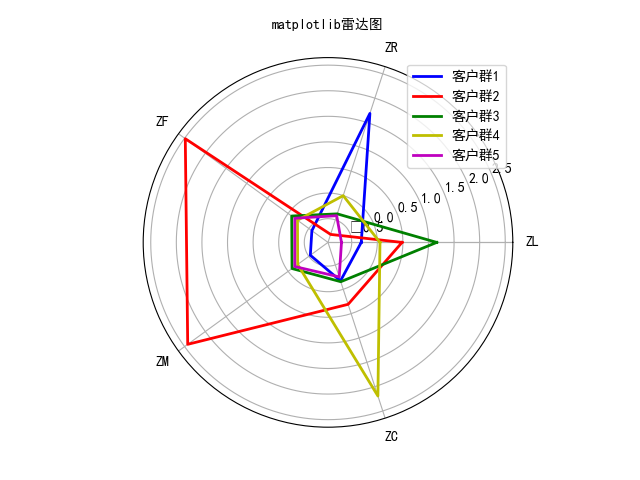
由上图可以很清晰的看到每个客户群的指标情况,将每个客户群的优势特征,劣势特征总结如下:
优势特征:
客户群1:R
客户群2:F、M、L
客户群3:L
客户群4:C
客户群5:无
劣势特征:
客户群1:F、M
客户群2:R
客户群3:R、F、M、C
客户群4:F、M
客户群5:R、L、C
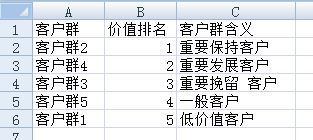
- 重要保持客户:这类客户平均折扣率(C)和入会员时间(L)都很高(入会员时间越长,会员级别越高,折扣越大),最近乘坐过本航班时间间隔(R)低,乘坐的次数(F)或(M)高。说明他们经常乘坐飞机,且有一定经济实力,是航空公司的高价值 客户。对应客户群2。
- 重要发展客户:这类客户平均折扣率高(C),最近乘坐过本航班时间间隔(R)短,但是乘坐的次数(F)和(M)都很低。说明这些乘客刚入会员不久,所以乘坐飞机次数少,是重要发展客户,对应客户群4。
- 重要挽留客户:这类客户入会时间长(L),最近乘坐过本航班时间间隔(R)较长,里程数和乘坐次数都变低,为重要挽留客户。对应客户群3
- 一般与低价值客户:这类客户乘坐时间间隔长(R)或乘坐次数(F)和总里程(M)低,平均折扣也很低。对应客户群5和客户群1.