- 什么是插值
Interpolation is a method of constructing new data points within the range of a discrete set of known data points. Image interpolation refers to the“guess”of intensity values at missing locations.
简单来说,插值指利用已知的点来“猜”未知的点,图像领域插值常用在修改图像尺寸的过程,由旧的图像矩阵中的点计算新图像矩阵中的点并插入,不同的计算过程就是不同的插值算法 下图是自己实现双线性插值的效果

- 常用的插值算法
插值算法有很多种,这里列出关联比较密切的三种
最近邻法(Nearest Interpolation):计算速度最快,但是效果最差
双线性插值(Bilinear Interpolation):双线性插值是用原图像中4(2*2)个点计算新图像中1个点,效果略逊于双三次插值,速度比双三次插值快,属于一种平衡美,在很多框架中属于默认算法
双三次插值(Bicubic interpolation):双三次插值是用原图像中16(4*4)个点计算新图像中1个点,效果比较好,但是计算代价过大
- 最近邻法(Nearest Interpolation)
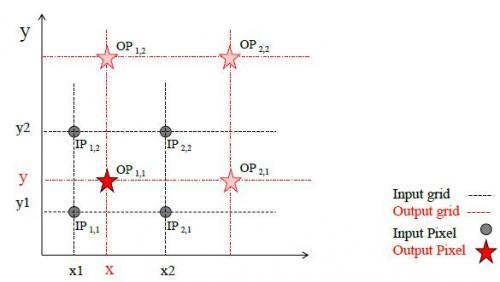
双线性插值法由原图中4个点计算新图中的1个点,在介绍计算过程前,需要先了解如何找到这4个点,双线性插值法找寻4个点的方式和最近邻法相似,这里顺带的了解下最近邻法的计算流程
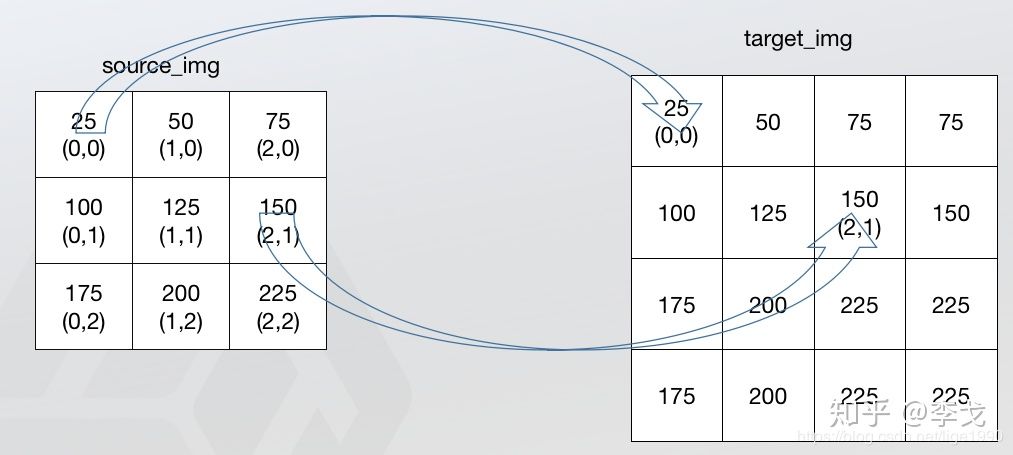
最近邻法实际上是不需要计算新图像矩阵中点的数值的,直接找到原图像中对应的点,将数值赋值给新图像矩阵中的点,根据对应关系找到原图像中的对应的坐标,这个坐标可能不是整数,这时候找最近的点进行插值。对应关系如下:

- 总结
上图效果是最近邻法的计算过程示意图,由上图可见,最近邻法不需要计算只需要寻找原图中对应的点,所以最近邻法速度最快,但是会破坏原图像中像素的渐变关系,原图像中的像素点的值是渐变的,但是在新图像中局部破坏了这种渐变关系。
- 双线性插值对应关系
双线性插值的对应公式和前面的最近邻法一样,不一样的是根据对应关系不再是找最近的1个点,而是找最近的4个点,如下图所示。
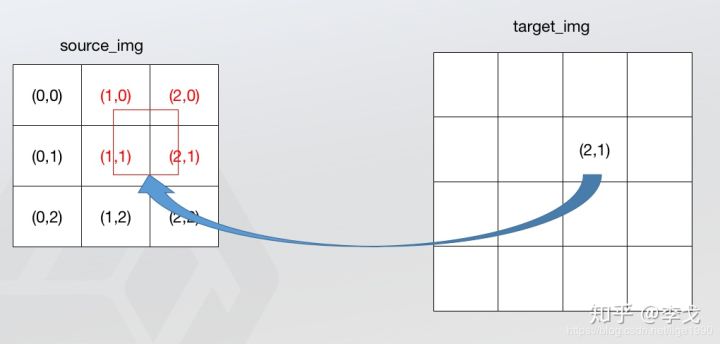
这里可能还会有点小疑问,如果根据对应关系找到原图中的点不是在不同的点之间,而是跟原图像中的点重合,那该如何找4个点?关于这个问题要看一下双线性插值的计算公式,双线性插值实际上是从2个方向一共进行了3次单线性插值,咱们先了解单线性插值的计算方式。
单线性插值
已知中P1点和P2点,坐标分别为(x1, y1)、(x2, y2),要计算 [x1, x2] 区间内某一位置 x 在直线上的y值
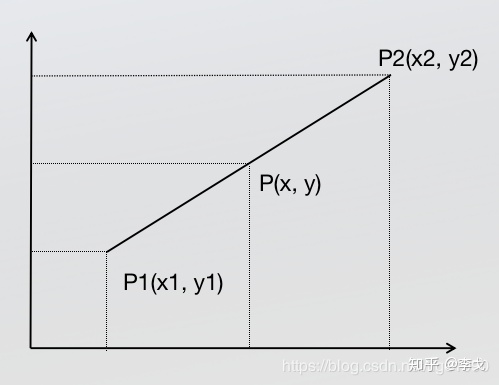
根据初中的只是,2点求一条直线公式(这是双线性插值所需要的唯一的基础公式)
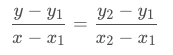
经过简单整理成下面的格式:
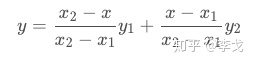
这里没有写成经典的AX+B的形式,因为这种形式从权重的角度更好理解。

权,要返回来思考一下,咱们先要明确一下根本的目的:咱们现在不是在求一个公式,而是在图像中根据2个点的像素值求未知点的像素值。这样一个公式是不满足咱们写代码的要求的。
现在根据实际的目的理解,就很好理解这个加权了,$y_1$与$y_2$分别代表原图像中的像素值,上面的公式可以写成如下形式:
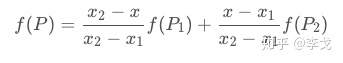
双线性插值
已知Q11(x1,y1)、Q12(x1,y2)、Q21(x2,y1)、Q22(x2,y2),求其中点P(x,y)的值。
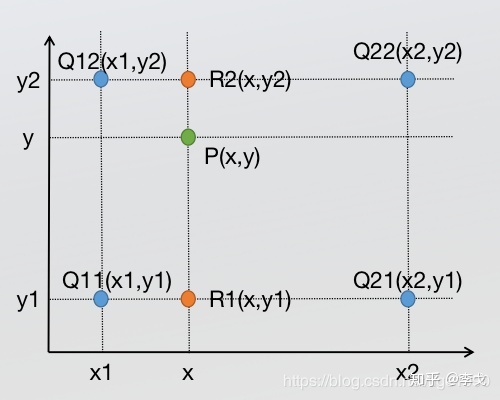
前面介绍过双线性插值是分别在两个方向计算了共3次单线性插值,如图所示,先在x方向求2次单线性插值,获得R1(x, y1)、R2(x, y2)两个临时点,再在y方向计算1次单线性插值得出P(x, y)(实际上调换2次轴的方向先y后x也是一样的结果)
- x方向单线性插值
直接带入前一步单线性插值最后的公式

- y方向单线性插值
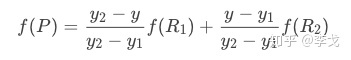
将第一步结果带入第二步
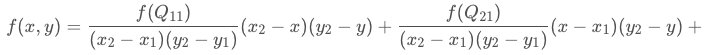
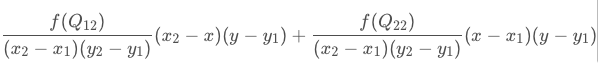

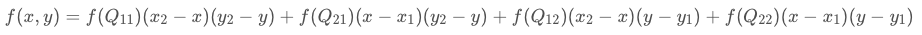
在有些资料中,会写成权重的形式,上面的展开式是下面的权重表达式的正确求法
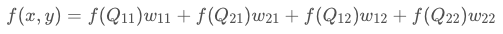
这种权重的表达式也不难理解,观察一下可以发现每个点的权重都和待求点和对角点的距离有关,
![]()
- 遗留问题
上面遗留了个小问题,就是当对应关系公式带入后跟原图像中的点发生重合后怎么选取剩下3个点,根据上面的公式可以发现,无论我们怎么选取,其实其余3点的权重都至少1项为0,所以不论我们怎么取剩下的3个点,对最终的结果都不会产生影响
- 总结
到此双线性插值的计算已经完成了,但是我们现在只能说是勉强的完成双线性插值算法,为什么这么说,现在的计算方式有比较大的问题,看下面的内容
- 双线性插值的优化
原始公式:

双线性插值的对应关系看似比较清晰,但还是有2个问题,我画图片进行说明
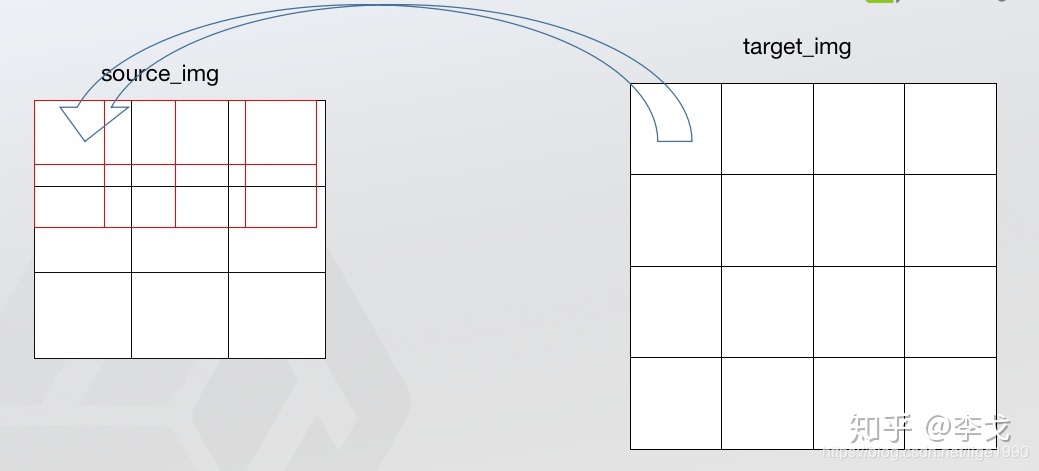
- 根据坐标系的不同,产生的结果不同
这张图是左上角为坐标系原点的情况,我们可以发现最左边x=0的点都会有概率直接复制到目标图像中(至少原点肯定是这样),而且就算不不和原图像中的点重合,也相当于进行了1次单线性插值(仔细想想为什么,带入到权重公式中会发现结果)
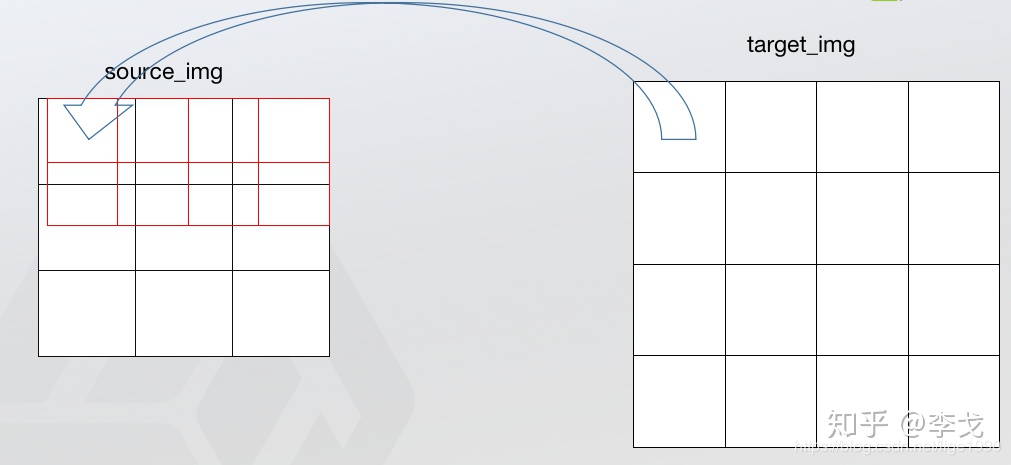
现在这张图是右上角为坐标系原点的情况,我们可以发现最右面的点都会有概率直接复制到目标图像中(至少原点肯定是这样),而且就算不不和原图像中的点重合,也相当于进行了1次单线性插值。这样如果我们采用不用的坐标系产生的结果是不一样的,而且无论我们采用什么坐标系,最左侧和最右侧(最上侧和最下侧)的点是不“公平的”,这是第一个问题
- 整体的图像相对位置会发生变化
看下面这张图,左侧是原图像(33),右侧是目标图像(55),原图像的几何中心点是(1, 1),目标图像的几何中心点是(2, 2),根据对应关系,目标图像的几何中心点对应的原图像的位置是(1.2, 1.2),如图所示,那么问题来了,目标图像的原点(0, 0)点和原始图像的原点是重合的,但是目标图像的几何中心点相对于原始图像的几何中心点偏右下,那么整体图像的位置会发生偏移,为什么这样说,其实图像是由1个个的像素点组成,单纯说1个像素点是没有太大的意义的,1个像素点跟相邻像素点的值的渐变或者突变形成图像颜色的渐变或者边界,所以参与计算的点相对都往右下偏移会产生相对的位置信息损失。这是第二个问题

- 计算机视觉中的蝴蝶效应
其实对于咱们人眼,上面的2个问题都不会产生太大的结果,但是对于现在的基于学习的学习类算法,计算机通过卷积神经网络提取图像中的深层信息,在这个过程中,我们人眼难以发现的变化也许会发生想象之外的变化,所以不要小看这两个问题
- 解决方案
几何中心点重合对应公式:
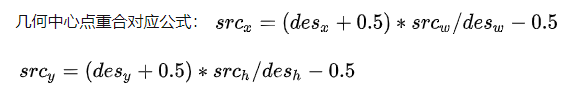
再带入到上面的情况,可以发现问题解决了,到此,才算完成完整的双线性插值法,当然如果这样计算发现结果跟OpenCV的结果不一样,是因为OpenCV还进行了很多速度上的优化,比如用整形计算代替浮点数计算
- 代码
# --*-- encoding: utf-8 --*--
'''
Date: 2018.09.13
Content: python3 实现双线性插值图像缩放算法
'''
import numpy as np
import cv2
import math
def bi_linear(src, dst, target_size):
pic = cv2.imread(src) # 读取输入图像
th, tw = target_size[0], target_size[1]
emptyImage = np.zeros(target_size, np.uint8)
for k in range(3):
for i in range(th):
for j in range(tw):
# 首先找到在原图中对应的点的(X, Y)坐标
corr_x = (i+0.5)/th*pic.shape[0]-0.5
corr_y = (j+0.5)/tw*pic.shape[1]-0.5
# if i*pic.shape[0]%th==0 and j*pic.shape[1]%tw==0: # 对应的点正好是一个像素点,直接拷贝
# emptyImage[i, j, k] = pic[int(corr_x), int(corr_y), k]
point1 = (math.floor(corr_x), math.floor(corr_y)) # 左上角的点
point2 = (point1[0], point1[1]+1)
point3 = (point1[0]+1, point1[1])
point4 = (point1[0]+1, point1[1]+1)
fr1 = (point2[1]-corr_y)*pic[point1[0], point1[1], k] + (corr_y-point1[1])*pic[point2[0], point2[1], k]
fr2 = (point2[1]-corr_y)*pic[point3[0], point3[1], k] + (corr_y-point1[1])*pic[point4[0], point4[1], k]
emptyImage[i, j, k] = (point3[0]-corr_x)*fr1 + (corr_x-point1[0])*fr2
cv2.imwrite(dst, emptyImage)
# 用 CV2 resize函数得到的缩放图像
new_img = cv2.resize(pic, (200, 300))
cv2.imwrite('pic/1_cv_img.png', new_img)
def main():
src = 'pic/raw_1.jpg'
dst = 'pic/new_1.png'
target_size = (300, 200, 3) # 变换后的图像大小
bi_linear(src, dst, target_size)
if __name__ == '__main__':
main()参考文献: