主要思路
抖音上面有许多精彩有趣的视频,如果我们想把这些短视频下载下来离线观看的话,该怎么写爬虫呢?
对于手机app的爬虫,一般要利用模拟器,本文使用fiddler和模拟器来抓取抖音和后台之间的https数据包,将其中的视频的地址提取出来,再利用python对这些视频进行下载保存。
思路很简单,但是这个环境的搭建并不容易,浪费了不少时间。
开发环境
- win10 x64
- Fiddler 一个http代理工具,用于进行软件测试
- 雷电模拟器
- vscode 用于编辑代码
- python3.7 (Anaconda 3)
fiddler的安装和配置
从fiddler的官网(https://www.telerik.com/fiddler)下载最新版本安装。
以管理员权限运行
在Tools->Options中进行如下配置
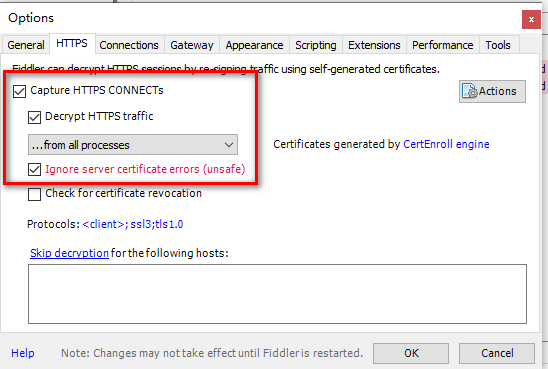
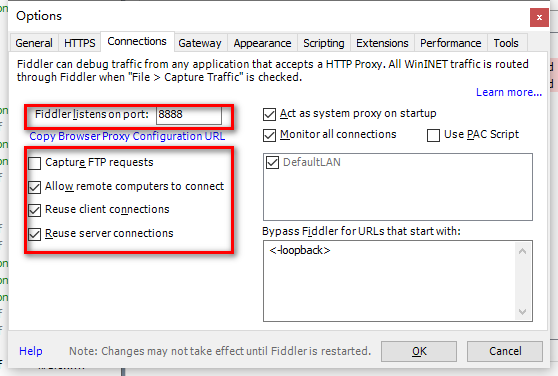
点击界面右上角的Online会显示出代理的IP地址。
重启fiddler.
雷电模拟器的安装和配置
在雷电模拟器的官网(https://www.ldmnq.com/)上下载安装。
打开雷电模拟器,安装抖音app
配置网络
在设置->WLAN,找到已经连接的wifi,长按,点击修改网络
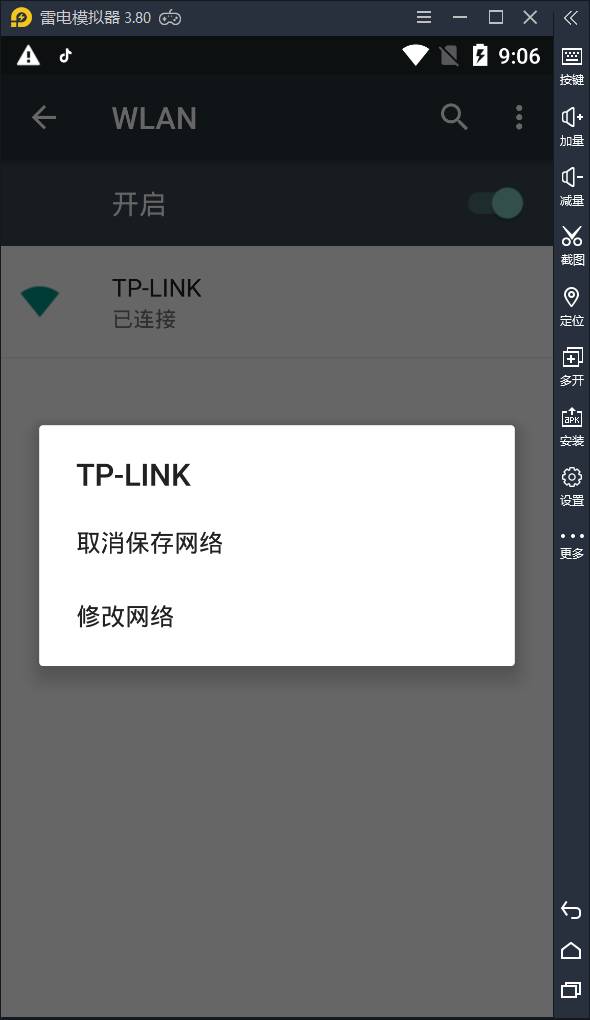
勾选高级设置
设置静态的IP地址和代理IP和端口,注意手机的IP地址要与本机的地址在同一网段内,代理的地址为前文中fiddler中显示的地址,一般为本地的地址。如下图所示。
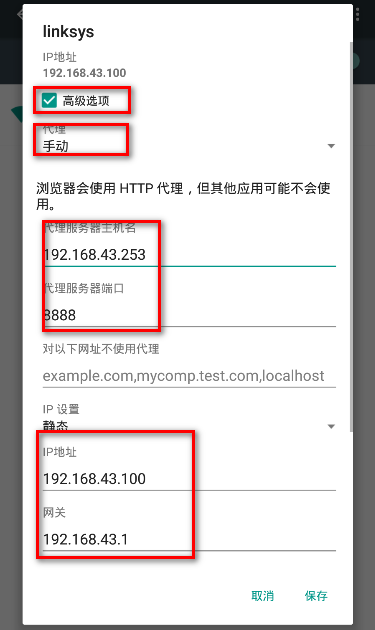
设置网络后重启模拟器。
安装https证书
在浏览器中打开https://[proxy_ip:proxy_port],打开如下页面。
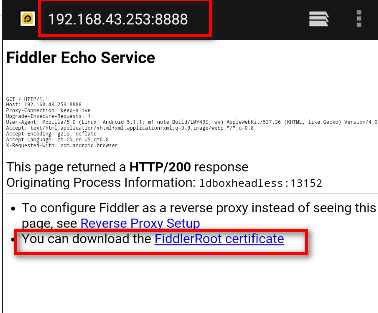
下载并安装证书,安装过程中需要为证书命名并设置开机密码。然后重启。
Fiddler抓包
如果上面的环境搭建过程没有问题的话,在fiddler中就可以看到app的中数据包了。
比如在抖音中打开"私人飞机花生哥"的主页,下面列出了他的作品。在fiddler中可以看到app向后台的发现的https请求包。
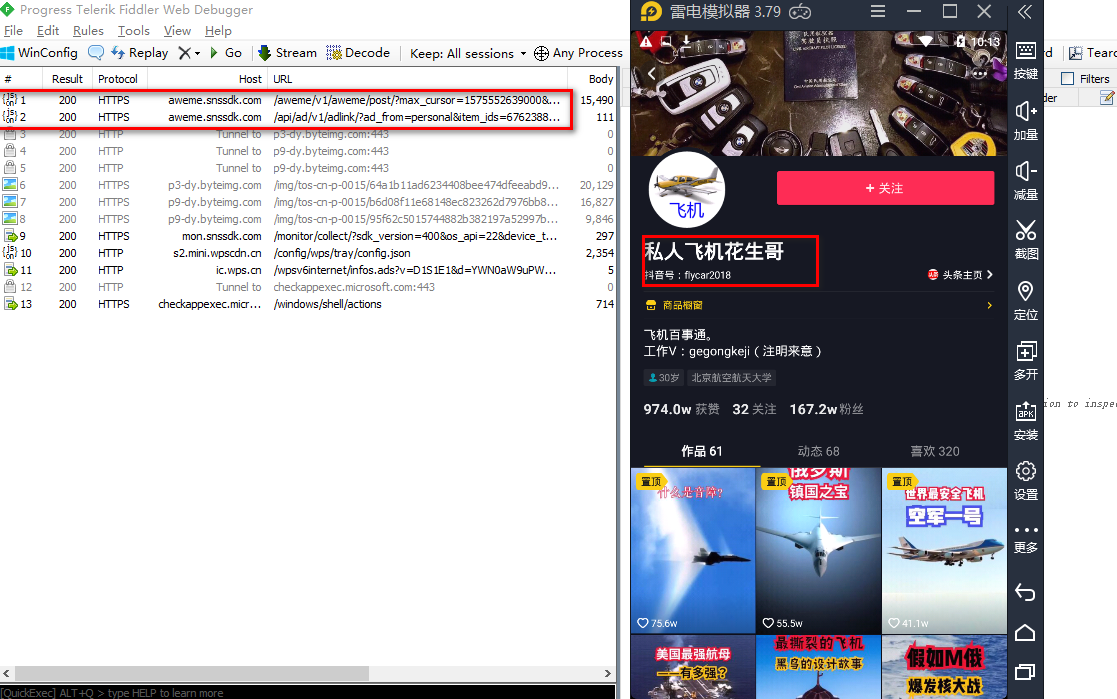
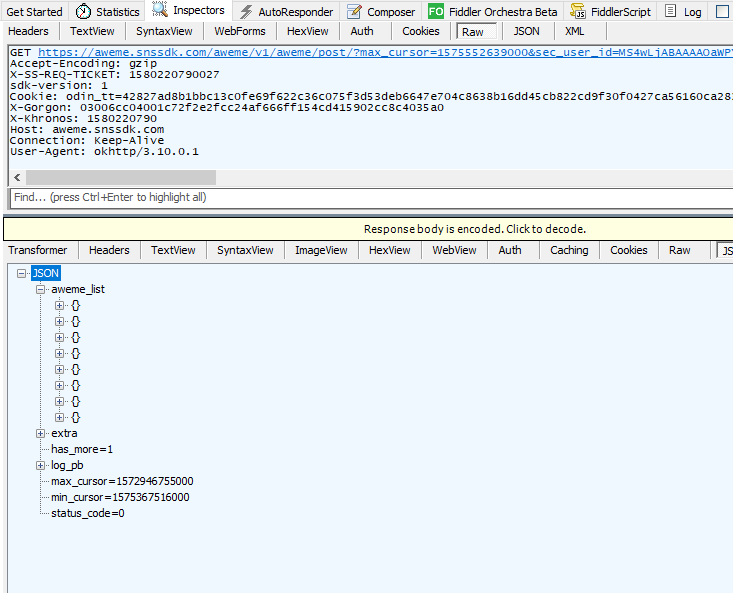
aweme_list中含有视频的播放和下载地址。
通过观察不难发现,随着向上滑动,会有多次这个请求,每次都会返回一些视频信息,如果一直滑到底的话,这个作者的所有作品信息都可以拿到了。
下面我们利用这一点,利用fiddler将视频这些请求以文本形式保存下来。
在菜单Rules->Customize Rules,打开fidder脚本编辑器。
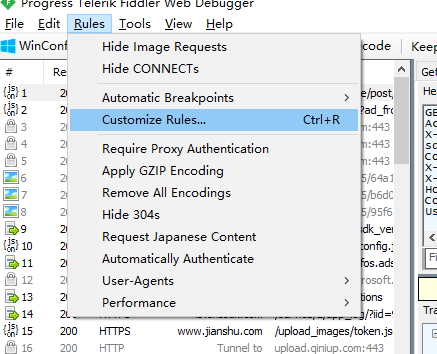
跳转到OnBeforeRequest函数,该函数可拦截requests。
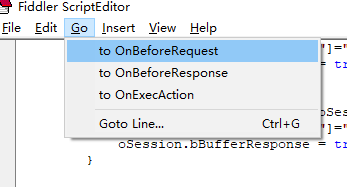
添加如下js代码。
//过滤无关请求,只关注特定请求
if (oSession.fullUrl.Contains("aweme.snssdk.com/aweme/v1/aweme/post"))
{
var fso;
var file;
fso = new ActiveXObject("Scripting.FileSystemObject");
//文件保存路径,可自定义
file = fso.OpenTextFile("D:\\douyin\\requests.txt",8 ,true, true);
file.writeLine("Request url: " + oSession.url);
file.writeLine("Request header:" + "\n" + oSession.oRequest.headers);
file.writeLine("Request body: " + oSession.GetRequestBodyAsString());
file.writeLine("\n");
file.close();
}
定位到OnBeforeResponse函数,该函数用于拦截response,添加如下js代码。
//过滤无关请求,只关注特定请求
if (oSession.fullUrl.Contains("aweme.snssdk.com/aweme/v1/aweme/post"))
{
//oSession.utilDecodeResponse();//消除保存的请求可能存在乱码的情况
var fso;
var file;
fso = new ActiveXObject("Scripting.FileSystemObject");
//文件保存路径,可自定义
file = fso.OpenTextFile("D:\\douyin\\response.txt",8 ,true, true);
file.writeLine(oSession.GetResponseBodyAsString());
file.writeLine("+++++++++");
file.close();
}
这样会将所有url中含有aweme.snssdk.com/aweme/v1/aweme/post的请求和响应都以追加形式保存为文本文件。其中响应以’’+++++++++’'进行分割。
下面测试一下,删除requests.txt和response.txt文件,在模拟器将这个作者主页滑动到最下面,fiddler会将所有的请求都保存在requests.txt中,将所有的响应都保存在response.txt文件中。
response为一个json格式,其内容为
{
...
"aweme_list": [
{
"aweme_id": "6754926284817698060",
"desc": "什么是热障? @全球飞机榜 @抖音小助手 #干货都在这",
...
"video": {
...
"download_addr": {
"uri": "v0200ff80000bmv538fff778hm097jog",
"url_list": [
"https://aweme.snssdk.com/aweme/v1/play/?video_id=v0200ff80000bmv538fff778hm097jog\u0026line=0\u0026ratio=540p\u0026watermark=1\u0026media_type=4\u0026vr_type=0\u0026improve_bitrate=0\u0026logo_name=aweme\u0026quality_type=11\u0026source=PackSourceEnum_PUBLISH",
"https://api.amemv.com/aweme/v1/play/?video_id=v0200ff80000bmv538fff778hm097jog\u0026line=1\u0026ratio=540p\u0026watermark=1\u0026media_type=4\u0026vr_type=0\u0026improve_bitrate=0\u0026logo_name=aweme\u0026quality_type=11\u0026source=PackSourceEnum_PUBLISH"
],
}
...
}
}
...
}
不难发现其中含有短视频的描述信息和下载地址。
下载视频
这里使用python从response.txt文件中提取出每个response,将其中的视频地址提取出来,结合利用requests.txt中的头信息,将这些视频抓取到本地。
代码如下。
#-*- coding:utf-8 -*-
# written by wlj @22:46 2020/1/28
import requests
from requests.packages import urllib3
import json
urllib3.disable_warnings()
def download_video(url,title):
#这里requests使用的headers信息,其中含有用户鉴权信息和cookie
#这是从requests.txt文件中拷贝的
t = """
Accept-Encoding: gzip
X-SS-REQ-TICKET: 1580217939813
sdk-version: 1
Cookie: odin_tt=42827ad8b1bbc13c0fe69f622c36c075f3d53deb6647e704c8638b16dd45cb822cd9f30f0427ca56160ca283338839d5e18de02ace41a64011d118065abb7c87; install_id=99098965031; ttreq=1$1aac280ead74ddb2d334de2b131dbca9e5eb1df4
X-Gorgon: 03006cc04001df5db027cc24af666ff154cd415902cc8cae7ff2
X-Khronos: 1580217939
Host: aweme.snssdk.com
Connection: Keep-Alive
User-Agent: okhttp/3.10.0.1
"""
#构造headers字典
headers = {
}
for line in t.strip().split('\n'):
k,v = line.strip().split(': ')
headers[k] = v
#过滤掉title中非法字符
illege_chars = ['<','>','/','\\','|',':','"','*','?']
for char in illege_chars:
title = title.replace(char,'_')
#下载视频文件,保存为mp4
res1 = requests.get(url = url, headers=headers,stream=True,verify=False)
with open('%s.mp4' % title, "wb") as f:
for chunk in res1.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
def main():
#从reponse.txt文件中分离中各个reponse
#注意fiddler保存的文件不是utf-8编码,需要将其转化为utf-8编码,才能正确读取,推荐使用Notepad++
data = open('response.txt','r',encoding='utf-8').read().split("+++++++++")[:-1]
for x in data:
x = json.loads(x)
#从中提取视频信息,包括视频的描述信息和下载地址
video_list = [(item['video']['download_addr']['url_list'][0],item['desc']) for item in x['aweme_list']]
for item in video_list:
#调用download_video下载视频
download_video(item[0],item[1])
main()
结果
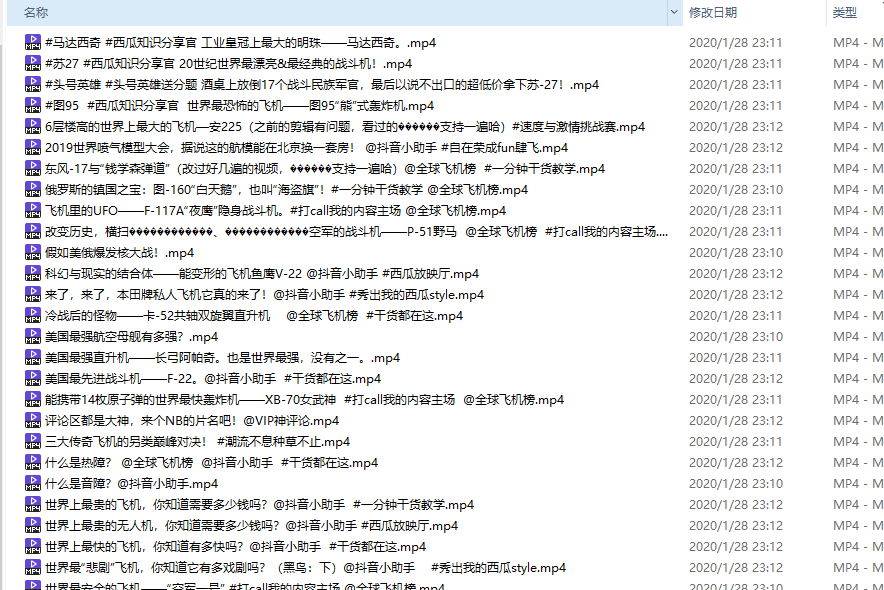
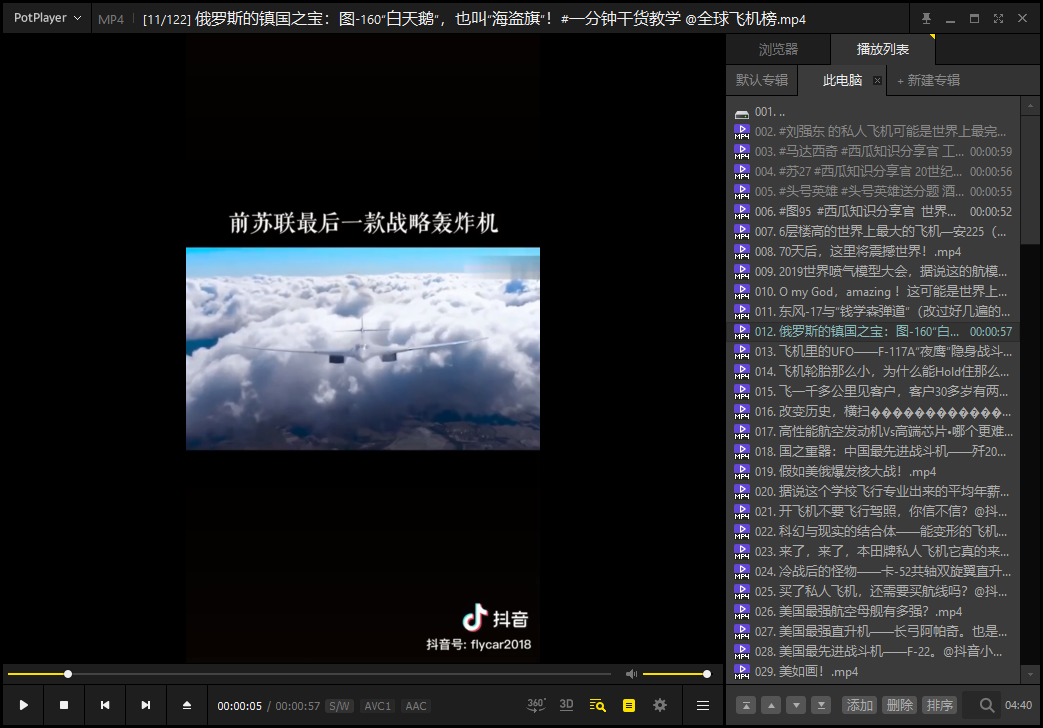
参考资料
- 雷电模拟器使用
https://www.cnblogs.com/techliang666/p/9909027.html - fiddler如何使用
https://www.hangge.com/blog/cache/detail_1697.html - fiddler脚本
http://www.manongzj.com/blog/5-ofplcuxsfdqxgwp.html