一、配置
首先对fiddler和模拟器进行配置,下篇具体讲述
二、测试、分析

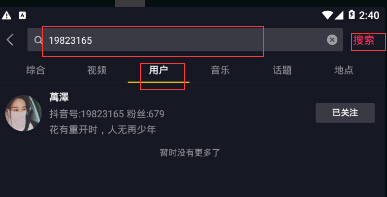
点击搜索后 fiddler上就有了个post请求
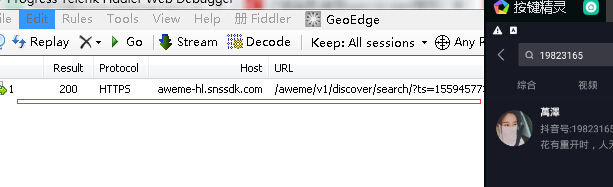

而用户内的内容已经给出,看如下json数据 aweme_count=103 。103个内容

现在进入主页
 aweme_list 下每一个{}就是一个短视频 使用鼠标一直下拉会有多个json链接出现
aweme_list 下每一个{}就是一个短视频 使用鼠标一直下拉会有多个json链接出现


我们的视频链接在:aweme_list中,每个视频下的video下的play_addr下的url_list中,忽悠6个url链接,都是同样的视频,个人理解这应该是应对各个场合的需求。
刚进入主页的同时 只有最初的20个视频,我们可以向下滑动加载,也可以自动化来向下模拟滑动,就会不断的出现如上图加载的json数据包
将json数据包保存到本地,fiddler提供了一个自带的脚本,在里面添加规则,当视频json包刷出来后自动保存json包
方法一:
菜单栏找到 Rules => Customize

找到 OnBeforeResponse
在下面添加规则:
filename 是本地保存路径
strBody 是获取到的json数据包,
-
# 抖音会经常变动这个url,所以需要经常改 -
oSession.uriContains("https://aweme-hl.snssdk.com/aweme/v1/aweme/post/")
注意: 有一点要注意的就是 有一个json数据包 写入一个,有多个就写入多个,这多个json数据写入进去后 每个包和每个包中间没有任何内容 就像是拼接成的字符串,在提取的时候会报错。我用了如下方法解决的 此方法有点low 各位大佬有好的方法可以不吝赐教。
至于我所添加的比较low的"aaaaa" ,主要作用是 便于正则匹配。
-
static function OnBeforeResponse(oSession: Session) { -
if (m_Hide304s && oSession.responseCode == 304) { -
oSession["ui-hide"] = "true"; -
} -
if (oSession.uriContains("https://aweme-hl.snssdk.com/aweme/v1/aweme/post/")){ -
var strBody=oSession.GetResponseBodyAsString(); -
var sps = oSession.PathAndQuery.slice(-58,); -
//FiddlerObject.alert(sps) -
var filename = "C:/Users/Administrator/Desktop/抖音爬虫json/raw_data" + "/" + sps + ".json"; -
var curDate = new Date(); -
var sw : System.IO.StreamWriter; -
if (System.IO.File.Exists(filename)){ -
sw = System.IO.File.AppendText(filename); -
sw.Write("aaaaa"+ strBody + "aaaaa"); -
} -
else{ -
sw = System.IO.File.CreateText(filename); -
sw.Write('aaaaa' + strBody + 'aaaaa'); -
} -
sw.Close(); -
sw.Dispose(); -
} -
}
比如:json数据为
-
#比如下面是初始添加的一条数据 -
j1 = '{"li": {"zzz":"111","xxx":"222","ccc":"333"}}' -
#然后又添加一条数据 -
j2 = '{"li": {"zzz":"111","xxx":"222","ccc":"333"}}{"li":{"zzz":"111","xxx":"222","ccc":"333"}}' -
#这就导致了 在解析json数据上会出现错误 从而解析不出来 获取不到所想要的内容,并且也遍历不出来 -
#所以 在每个json数据前后都添加一些字符,字符不固定,主要是以便于能够更好的提取出出来。可能也有更好的办法。 -
j3 = 'aaaaa{"li": {"zzz":"111","xxx":"222","ccc":"333"}}aaaaaaaaaa{"li":{"zzz":"111","xxx":"222","ccc":"333"}}aaaaa' -
#正则匹配 -
p = r'"aaaaa"(.*?})"aaaaa"' -
ss = re.findall(p,a) -
#输出为:['{"li": {"zzz":"111","xxx":"222","ccc":"333"}}', '{"li":{"zzz":"111","xxx":"222","ccc":"333"}}'] -
#这样就可以遍历内容提取数据
第二个输入方法:
打开他 也是把规则写进去 就OK了

而后你在重新进入主页 你所保存的json数据包就出现了。

三、撸代码
-
import os, json, requests, re, random -
# 伪装头 -
USER_AGENTS = [ -
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", -
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)", -
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", -
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)", -
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", -
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", -
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", -
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", -
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", -
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", -
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", -
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5", -
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6", -
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11", -
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20", -
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52", -
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11", -
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER", -
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)", -
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)", -
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER", -
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)", -
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)", -
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)", -
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)", -
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)", -
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)", -
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1", -
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1", -
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5", -
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre", -
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0", -
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11", -
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10" -
] -
headers = {'User-Agent': random.choice(USER_AGENTS)} -
# 获取文件夹内所有json包名 -
videos_list = os.listdir('C:/Users/Administrator/Desktop/抖音爬虫json/raw_data/') -
# 用来方便查看视频总数 -
count = 1 -
# 循环json列表,对每个json包进行操作 -
for videos in videos_list: -
# 用来拼接视频名称,使其不出现重复video名 -
numb = 1 -
# 打开json包 -
a = open('C:/Users/Administrator/Desktop/抖音爬虫json/raw_data/{}'.format(videos), encoding='utf-8') -
# 获取文件内容 -
a = a.read() -
# 使用正则匹配出里面的数据 -
p = r'aaaaa(.*?})aaaaa' -
ss = re.findall(p, a) -
for i in ss: -
# 取出json包中所有视频 -
content = json.loads(i)['aweme_list'] -
# 循环视频列表,选取每个视频 -
for video in content: -
# 获取用户名称 -
vieo_name = video['author']['nickname'] -
# 获取用户id -
vieo_id = video['author']['short_id'] -
# 获取视频url,每条数据有6个url,都是一样的视频 -
video_url = video['video']['play_addr']['url_list'][0] -
# 获取视频二进制代码 -
videoMp4 = requests.request('get', video_url, headers=headers).content -
#查询目标文件夹 -
isExists = os.path.exists('C:/Users/Administrator/Desktop/抖音爬虫json/VIDEO/{}'.format(vieo_name)) -
# 判断是否有次文件夹,没有就创建 -
if not isExists: -
os.makedirs('C:/Users/Administrator/Desktop/抖音爬虫json/VIDEO/{}'.format(vieo_name)) -
print('{}文件夹创建成功,开始写入..'.format(vieo_name)) -
else: -
# 以二进制方式写入路径,要先创建路径 -
with open('C:/Users/Administrator/Desktop/抖音爬虫json/VIDEO/{}/{}.mp4'.format(vieo_name, vieo_name + '_' + str(numb)), -
'wb') as f: -
# 写入 -
f.write(videoMp4) -
# 下载提示 -
print('视频下载完成-{}'.format(vieo_name + '_' + str(numb)), '...共计第{}个视频'.format(count)) -
count += 1 -
numb += 1 -
print('下载完成!')