01、案例实现
下面以综合实战项目为例,从“北京链家网”爬取包括城区名(district)、街道名(street)、小区名(community)、楼层信息(floor)、有无电梯(lift)、面积(area)、房屋朝向(toward)、户型(model)和租金(rent)等租房信息。
爬取数据的程序流程图如图1所示。
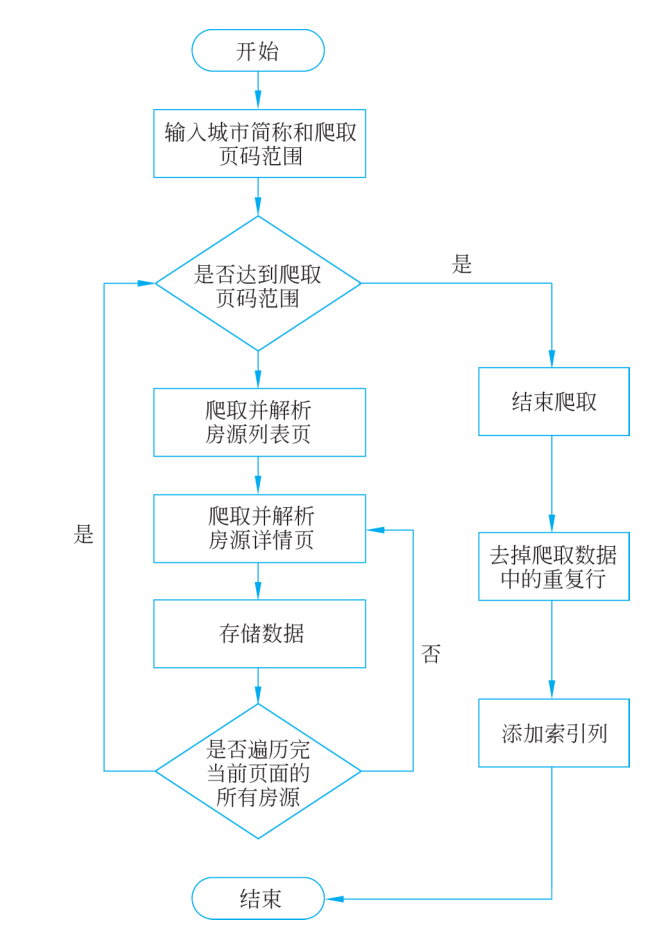
■ 图1 “北京链家网”租房数据爬取流程图
(1) 导入库。代码如下。首先导入爬取过程中所需的库,这里仅对库进行简单说明,后面会详细讲解。
import csv
import random
import time
import requests
import pandas as pd
from Ixml import etree其中,requests库用于请求指定页面并获取响应,etree库对返回的页面进行XPath解析,以获取指定的数据,random库和time库用于爬取过程中的一些设置,Pandas库和csv库用于处理和保存文件。
(2) 输入“北京链家网”的城市简称和要爬取的房源页面的页码范围。打开租房页面,首先展现的是房源列表页,通过观察不同城市的链家网租房页面的URL链接可知,一个房源列表页的URL链接主要分为3部分:城市的拼音简写、页码和其他相同部分,例如下面给出三个房源列表页的URL。
#北京
https://bj.lianjia.com/zufang/pg4/#contentList
#重庆
https://cq.lianjia.com/zufang/pg5/#contentList
#上海
https://sh.lianjia.com/zufang/pg6/#contentList
其中,第一条URL中的“bj”表示城市北京的拼音简写,“pg4”表示第4页。通过设置房源列表页URL的城市拼音简写,除了可以爬取北京的租房数据外,也可以爬取其他城市的租房数据。
本案例使用城市(如bj)和页码(pg4)的拼音简称构造一条房源列表页的URL链接,其中“#contentList”用于页内定位,可以忽略。
(3) 爬取并解析房源列表页。由于本案例拟爬取的房源信息在房源列表页和每一个房源的详情页均有分布,因此首先需要获取每一个房源详情页的URL链接。另外,房源列表页中还包含每一个房源所在的地理位置(所在城区、街道和小区)。下面介绍如何对房源列表页的页面信息进行分析,以获得房源详情页的URL链接和每一个房源的地理位置。
使用火狐浏览器打开“北京链家网”的租房页面北京租房信息_北京出租房源|房屋出租价格【北京贝壳租房】 ,在页面空白位置右击,在弹出的快捷菜单中选择“检查”功能,单击页面最左侧小箭头形状的按钮,随后指向其中的一个房源信息,在“查看器”子窗口中右击蓝色文字的MTML代码,选择“复制”→“整体HTML”,得到如下的HTML内容(为简化分析难度,仅保留部分代码)。
<div class="content list">
<div class="content list--item">
<div class="content list--item--main"><p class="content list--item--title"><a class="twoline" target=" blank"href="/zufang/BJ2840486736310837248.html">整租·长阳国际城二区 3 室 1厅南/北< /a>
</p><p class="content list--item--des"><a target="blank"href="/zufang/fangshan/">房山</a>-<ahref="/zufang/changyang1/"target=" blank">长阳</a>-<atitle="长阳国际城二区"href="/zufang/c1111053458322/"target=" blank">长阳国际城二区< /a>
<i>/</i>
89.00m2
<i> /< /i>南北<i> /< /i>
3室1厅1卫<span class="hide"><i>/</i>
中楼层(20 层)</span></p>
< /div>
</div>
</div>通过观察会发现,房源详情页的URL链接包含在
标签中的 标签的href属性中,房源的地理位置(城区名、街道名和小区名)包含在标签中的3个“a”标签内。
获得房源的URL链接和地理位置的具体过程如下。
① 首先,通过XPath获取房源的URL链接,路径为//a[@class="content list--item--aside"]/@href。使用该路径可以获取当前页面中所有class属性为“contentlist--item--aside”的“a”标签的href属性值,得到的结果为当前页面所有房源的URL链接列表detailsUrl。
② 然后,通过XPath获取房源的地理位置(城区名、街道名和小区名),路径为 //p[@class="contentlist--item--des"]/a/text()。使用该路径可以获取当前页面中所有class属性为“contentlist--item--des”的“p”标签下“a”标签的文本内容,得到的结果为当前页面所有房源的地理位置列表location。需要注意的是,每一个“p”标签下共有3个“a”标签,分别对应房源的城区名、街道名和小区名。
③ 最后,通过遍历列表detailsUrl和列表location,将房源详情页URL链接和对应的城区名、街道名和小区名存放在字典中。
该部分代码如下。
defgetPageLines(city, page):
//获取指定城市和页码所在页面中的房源 URL 链接、所在地理位置 (district streetcommunity),并分别存入 house 字典中
:param city:城市简称
:param page:要爬取的页码
:return:字典列表
#构造房源列表页的 URL 链接
URI="https://"+ city +",lianjia.com/zufang/pg"+ str(page)
# 构造房源详情页 URL 链接的公共部分
baseUrl=URL.split("/")[0] +"//+ URL.split("/")[2
# 爬取房源列表页,并处理响应信息
response=reguests .get(url=URL)
# 获取页面 HTML,并对其进行解析
html=response.text
mvelement=etree .HTML (html)
# 提取本页面所有房源的 URL 链接和地理位置
detailsUrl=myelement.xpath('//al@class="content list--item--aside"]/@href门)
location=myelement.xpath('//p @class="content list--item--des"7/a/text
07
#将数据存入字典列表中
houses=list()
foriin range(len(detailsurl)):
# 获取房源详情页的 URI 链接detailsLink=baseUrl + detailsUrl i# 获取房源所在地理位置
slineIndex=i *
district=location lineIndex
street=location lineIndex + 17
community=location lineIndex + 2
# 将房源详情页 URI 链接和所在地理位置存入字典
house=[}
house "detailsLink" =detailsLink
house["districtu]=district
housel"street"=street
house "community"=community
houses.append(house)
return houses(4) 爬取并解析房源详情页。从房源详情页中可以获取房屋楼层、电梯、面积、朝向、户型和租金等信息。在浏览器中打开一个房源详情页,通过火狐浏览器的“检查”功能获取房源详情页面的部分HTML源码。房源详情页的部分HTML源码如下。
<div class="content aside--title">
<span>5500</span>元/月
(季付价)
<div class="operate-box">······</div></div>
<ul class="content aside list">
<li><span class="label">租赁方式:</span>整租</li><li><span class="label">房屋类型:</span>3室1厅1卫 89.00m’精装修</li>
<li class="floor"><span class="label">朝向楼层:</span><span class="">南/北中楼层/20 层< /span></li>
<li>
< span class="label">风险提示:</span></li>
</ul>
<div class="contentarticle info" id="info"><h3 id="info">房屋信息< /h3>
<ul>
<li class="fl oneline">基本信息</li>
<li class="fl oneline">面积: 89.00m2< /li>
<li class="fl oneline">朝向: 南北< /li>
<li class="fl oneline"> </li>
<li class="fl oneline">维护:7天前< /li>
<li class="fl oneline">入住:随时人住< /li>
<li class="fl oneline"> </li>
<l class="fl oneline">楼层:中楼层/20 层</li>
<li class="fl oneline">电梯: 有</li>
...
</ul>通过分析该段HTML源码可知,房屋租金位于class属性为“contentaside--title”的标签下的标签中,房屋户型位于class属性为“contentaside list”的标签下的第二个“li”标签中,楼层、电梯、面积和朝向4个房屋信息都存在于class属性为“contentarticle__info”的标签下的“ul”标签下的“li”标签中。通过XPath获取“li”标签中的内容,并对文本内容进行数据清洗,以得到字典类型的目标数据,最后将其存入对应的house字典。
获得房源的楼层、电梯、面积、朝向、户型和租金等信息的具体过程如下。
① 在上一步得到的house字典中读取房源详情页的URL链接,发送请求获取房源详情页面的HTML源码,并对其进行解析。
② 通过XPath获取房屋租金rent和房屋户型model,得到的结果存入house字典。
③ 通过XPath获取房屋楼层、电梯、面积和朝向。因为HTML内容中解析得到的数据含有空格,使用dataCleaning()方法对其进行数据清洗,该方法同时对数据进行类型转换,最终将得到的房屋楼层、电梯、面积和朝向数据存入house字典。
至此,所需的数据都保存在house字典中,该部分代码如下。
defgetDetail(house) :
爬取并解析房源详情页的数据,将其存入字典中。
:param house:含有房源详情页 URL 链接和地理位置的字典
: return:含有案例拟爬取数据的字典
# 读取房源详情页的 URL 链接
url=house"detailsLink"
try:
response=requests.get(url=url,timeout=10)except:
return None,None
# 获取房源详情页面 HTML,并对其进行解析myelement=etree.HTML(response.text)# 获取房屋租金和房屋户型
house["rent"]=myelement.xpath('//div[@ class="content aside- - title"]/span/text()')[0house["model"]=(myelement.xpath('//ul[@class="content aside list"]/li[2]/text()'))[o].split("")[o]
# 获取房屋其他信息:楼层,电梯,面积,朝向
details=myelement.xpath('//div[@class="content article info"]/ul[1]/li/text())
details=dataCleaning(details)
house_"floor"=details"楼层
house["lift"=details["电梯
house"area”=details "面积"
house "toward"=details "朝向
return house,response.status code在上面的代码中,使用dataCleaning()函数对一条房屋的信息进行数据清洗,以获取房屋的楼层、电梯、面积和朝向等数据。数据清洗包括两部分:删除数据中的空格'\xa0';将数据由列表类型转换成字典类型,以方便存储。例如,一条房屋信息原本的类型是列表类型:['基本信息','面积:89.00m2','朝向:南','\xa0','维护:5天前','入住:随时入住','\xa0','楼层:中楼层/28层','电梯:有','\xa0','车位:暂无数据','用水:暂无数据','\xa0','用电:暂无数据','燃气:有','\xa0','采暖:集中供暖'],经过dataCleaning()函数后,该房屋类型被转换为字典类型:{'面积': '89.00','朝向': '南','维护': '5天前','入住': '随时入住','楼层': '中楼层/28层','电梯': '有','车位': '暂无数据','用水': '暂无数据','用电': '暂无数据','燃气': '有','采暖': '集中供暖' }。dataCleaning()函数的具体实现如下。
def dataCleaning(details):
//对房屋信息进行清洗
:param details: 列表类型,一条房屋信息
:return: 字典类型,清洗后的房屋信息
details=detailsnew details=list()for detail in details:if detail="xa0":continuedetail=str(detail).split(':')new details.append(detail)
return dict(new details)爬取网页时,不可避免会遇到“\xa0”字符串。“\xa0”其实表示空格。“\xa0”属于latin1(ISO/IEC_8859-1) 中的扩展字符集字符,代表空白符nbsp(non-breaking space)。latin1字符集可向下兼容ASCII码。
(5) 保存数据。通过Python的内置库CSV实现对字典数据按行保存。该部分代码如下。
save(row,fileName) :def
//按行保存数据
:param row:字典类型,每一行的数据
:param fileName: 数据保存的文件名
with open(fileName,"a+",newline= ,encoding='qbk') as f:writer=csv.DictWriter(f,fieldnames=fieldnames)writer.writerow(row)(6) 主程序。在主函数中,从键盘输入链家网的城市简称和爬取的页码范围,并新建CSV文件,以保存爬取的数据。然后调用上述步骤中的各个函数进行数据爬取。
所有数据爬取完成后,通过第三方库Pandas对数据去除重复行,并在数据中添加一列“ID”作为索引列。至此,爬取任务完成。
该部分代码如下。
if name == main
city = input("请输人要爬取的城市拼音(如北京: bj,上海: sh):").strip().lower()pageRange=input("请输人要爬取的页码范围(如第 1页到第 100 页:1-100):")strip()startPage=int(pageRange.split("-")[0])endPage=int(pageRange.split("-")[17) + 1
#将爬取的数据保存在 CSv 表
fileName=city n lianJia.csv"
fieldnames='floor','lift','district','street','community','area','toward''model''rent'
"w",newline='') as f:with open(fileName,#将表头写入 CSv 表
writer=csv.DictWriter(f,fieldnames=fieldnames)writer.writeheader()startTime=time .time ()
for page in range(startPager endPage):print("\n--->>正在爬取第”+ str(page) +"页”)houses=getPageLines(city=city,page=page)for house in houses:
data,statusCode=getDetail(house=house)
if data= None:
continueprint('响应状态:,statusCode)# CSV 文件不需要保存链接网址,所以删除 detailsLink 键值对del data "detailsLink"save(data,fileName)time.sleep(3)endTime=time .time ()print(耗时:,round(endTime- startTime,2),'s')# 使用 pandas 对数据表进行处理df=pd.read csv(fileName,encoding='gbk')# 删除重复行
df=df.drop duplicates ()index=list()
for i in range(1,len(df) + 1):id="rent" + str(i).zfill(4)index.append(id)
#插入 id列
df.insert(0,"id",index)
df.to csv(fileName,index=False,encoding='gbk')