xpath 是在XML文档中搜索内容的一门语言,而html 是xml的一个子集
首先我们需要先导入模块,在pycharm3.0版本后都自带了,如果没有自带就先自行下载
from lxml import etree#导入etree模块,因为etree模块中才有xpath
然后接下来将一些简单的用法,我们这里以一个简单的网页为模板举例:
<html>
<head>
<meta charset='utf-8' />
<title>Title</title>
</head>
<body>
<ul>
<li><a href="http://www.baidu.com">百度</a></li>
<li><a href="http://www.google.com">谷歌</a></li>
<li><a href="http://ww.sogou.com">搜狗</a></li>
</ul>
<ol>
<li><a href="tutu">涂涂</a></li>
<li><a href="guapi">瓜皮</a></li>
<li><a href="lige">李哥</a></li>
</ol>
<div calss="joy">周杰伦</div>
<div class="Tom">汤姆</div>
</body>
</html>
然后我们把把html的内容加载成一个tree的对象
html="""
<html>
<head>
<meta charset='utf-8' />
<title>Title</title>
</head>
<body>
<ul>
<li><a href="http://www.baidu.com">百度</a></li>
<li><a href="http://www.google.com">谷歌</a></li>
<li><a href="http://ww.sogou.com">搜狗</a></li>
</ul>
<ol>
<li><a href="tutu">涂涂</a></li>
<li><a href="guapi">瓜皮</a></li>
<li><a href="lige">李哥</a></li>
</ol>
<div calss="joy">周杰伦</div>
<div class="Tom">汤姆</div>
</body>
</html>
"""
tree=etree.HTML(html)
#tree=etree.parse("文件")#etree.parse()接收文件
查取我们想要的内容时,/表示层级关系。第一个/是根节点:
result=tree.xpath("/html/body/ul/li/a")#查取a标签的内容
print(result)
运行结果:

拿去文本内容:
result=tree.xpath('/html/body/ul/li/a/text()')#text()拿取文本内容返回一个表格
print(result)
运行结果:
xpath中通过索引拿到指定的内容:
result=tree.xpath('/html/body/ul/li[1]/a/text()')#xpath的索引顺序是从1开始,[]表示索引
print(result)
运行结果:

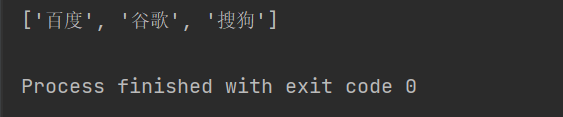
xpath通过筛选属性拿到指定的内容:
result = tree.xpath('/html/body/ol/li/a[@href="tutu"]/text()')#[@xxx='xxx'] 属性的筛选
print(result)
运行结果:

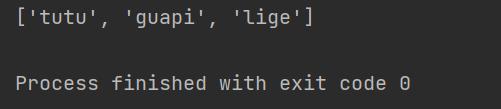
遍历拿取属性值(也可拿去内容):
ol_li_list=tree.xpath("/html/body/ol/li")
for li in ol_li_list:
#从每一个li中提取到文字信息
# result=li.xpath("./a/text()")#运用相对查询,./ 表示当前节点
result = li.xpath("./a/@href")#拿到href这个属性的值
print(result)
运行结果:
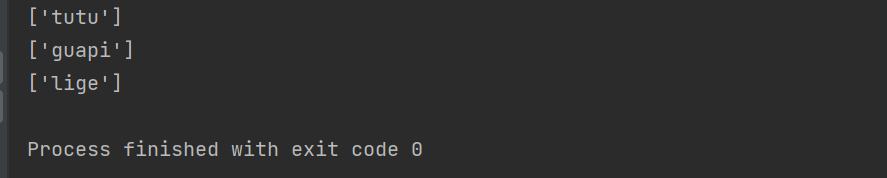
一次性拿取所有属性值:
reslut=tree.xpath('/html/body/ol/li/a/@href')#拿取href这个属性的值
print(reslut)
运行结果: