ZynqNet CNN Accelerator: Schedule
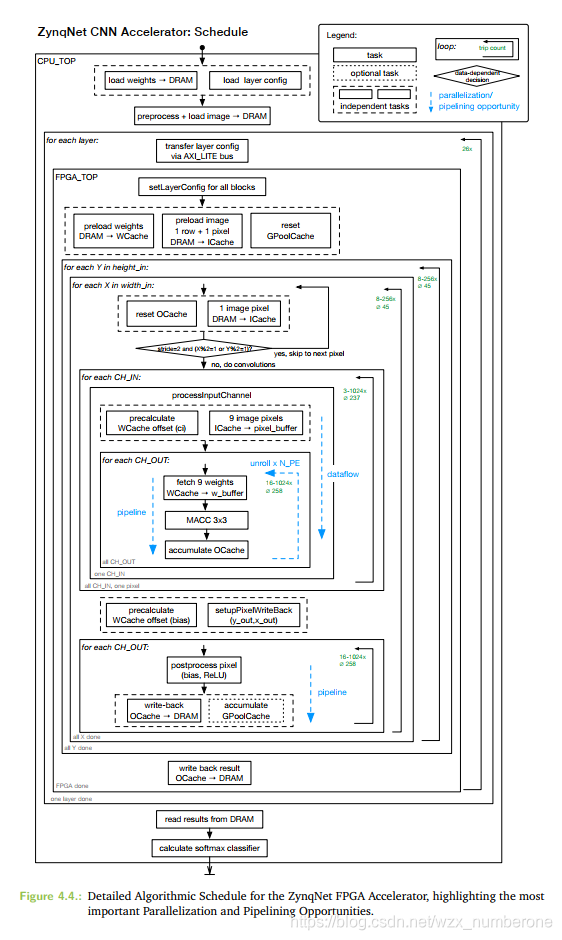
分析FPGA端顶层函数
首先CPU端会通过AXI_Lite总线将一层网络的参数传输到FPGA的PL端进行硬件加速计算,接下来将详细进行分析
首先关注HLS端的顶层函数,这些参数是用来生成IPcore的接口,需要使用相应的#pragma语法进行限定
void fpga_top(layer_t layer, data_t *SHARED_DRAM, unsigned int weights_offset,
weightaddr_t num_weights, unsigned int input_offset){
/*map pointer SHARED_DRAM to AXI-master interface for global memory access*/
#pragma HLS INTERFACE m_axi port=SHARED_DRAM offset=slave bundle=gmem
/*we also need to map SHARED_DRAM and return to a bundled axilite slave interface*/
#pragma HLS INTERFACE s_axilite port=SHARED_DRAM bundle=control
#pragma HLS INTERFACE s_axilite port = layer bundle = control
#pragma HLS INTERFACE s_axilite port = num_weights bundle = control register
#pragma HLS INTERFACE s_axilite port = weights_offset bundle = control register
#pragma HLS INTERFACE s_axilite port = input_offset bundle = control register
#pragma HLS INTERFACE s_axilite port = return bundle = control register
...
}
这里放一篇关于如何对顶层函数接口进行设置的文章
P_TOP_SETUP
P_TOP_SETUP : {
// Setup Memory Controller
MemoryController::setup(SHARED_DRAM, weights_offset, input_offset);
// Setup Global Pooling Cache
// if (layer.pool == POOL_GLOBAL) GPoolCache::reset(); -> in loop.
}
用于设置weight和data的地址偏移量,将顶层函数的weights_offset和input_offset写入以下两个全局变量
unsigned int MemoryController::dram_weights_offset;
unsigned int MemoryController::dram_data_offset;
P_setLayerConfigs
P_layer_setup : {
P_setLayerConfigs : {
ImageCache::setLayerConfig(layer);
WeightsCache::setLayerConfig(layer, num_weights);
MemoryController::setLayerConfig(layer);
ProcessingElement::setLayerConfig(layer);
}
LOG_LEVEL_DECR;
// Load Weights from DRAM
WeightsCache::loadFromDRAM(SHARED_DRAM);
// Preload Row 0 + Pixel (1,0)
MemoryController::setPixelLoadRow(0);
ImageCache::preloadRowFromDRAM(SHARED_DRAM);
MemoryController::setPixelLoadRow(1);
ImageCache::preloadPixelFromDRAM(SHARED_DRAM);
}
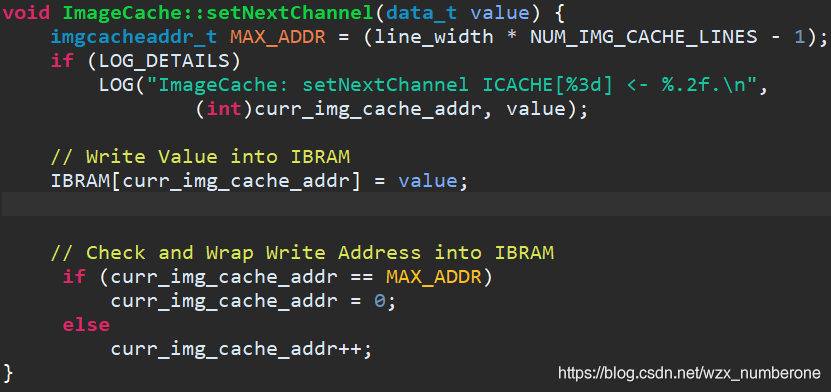
注意ImageCache::setLayerConfig函数里两个变量的设置,为什么要这样设计呢?这两个变量与地址计算相关
line_width = ch_in * width_in;
loads_left = line_width * height_in;
以第一层网络为例,width=256,height=256,ch=3
那么line_width=3*256,loads_left=256,
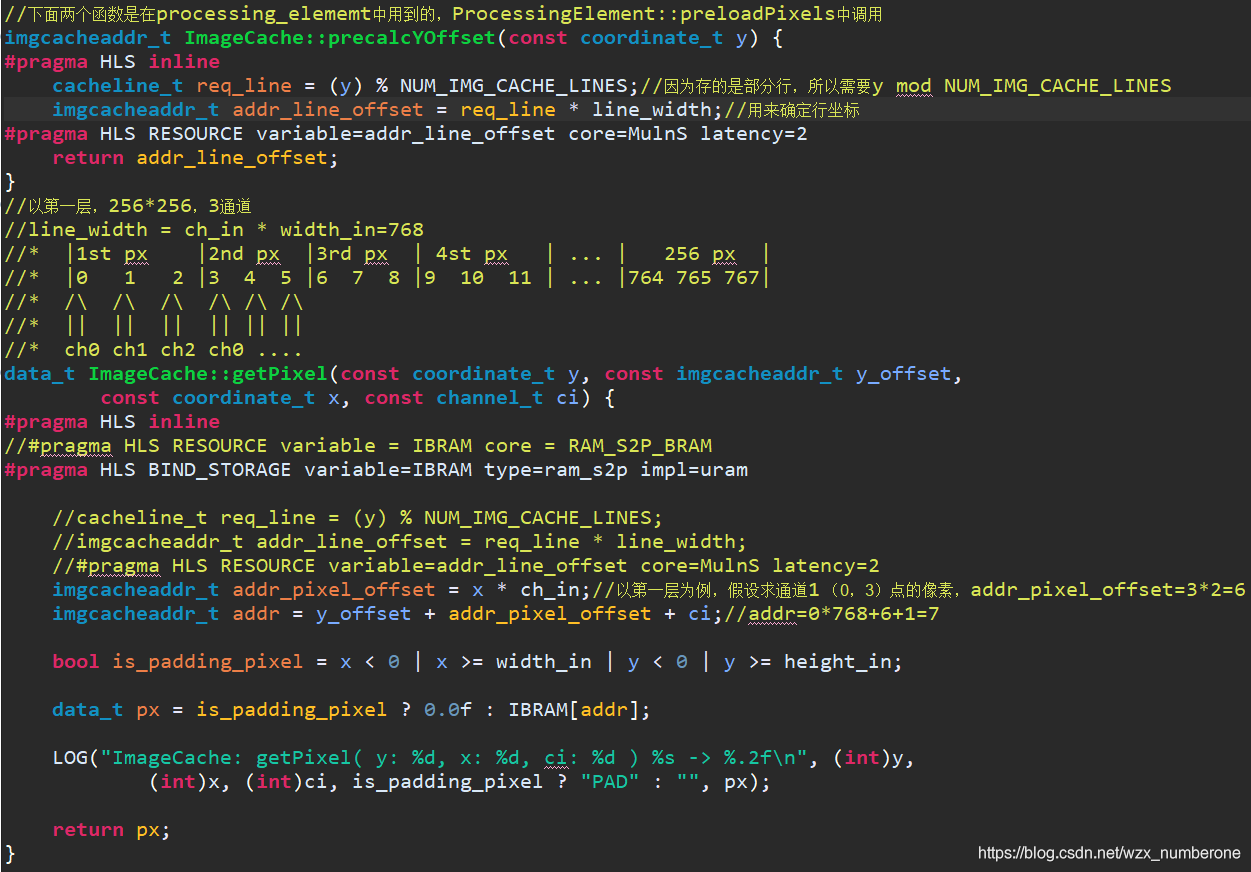
接下来看preloadRowFromDRAM函数,意思是从DRAM中,每个像素都取出3通道,这256个3个通道组成新的1行数据。如上图所示:
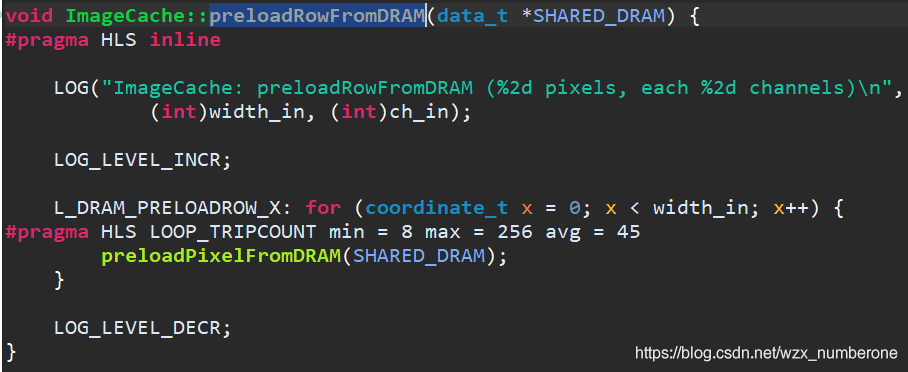
再来看被调用的preloadPixelFromDRAM函数,从SHARED_DRAM中取数据,并存入IBRAM
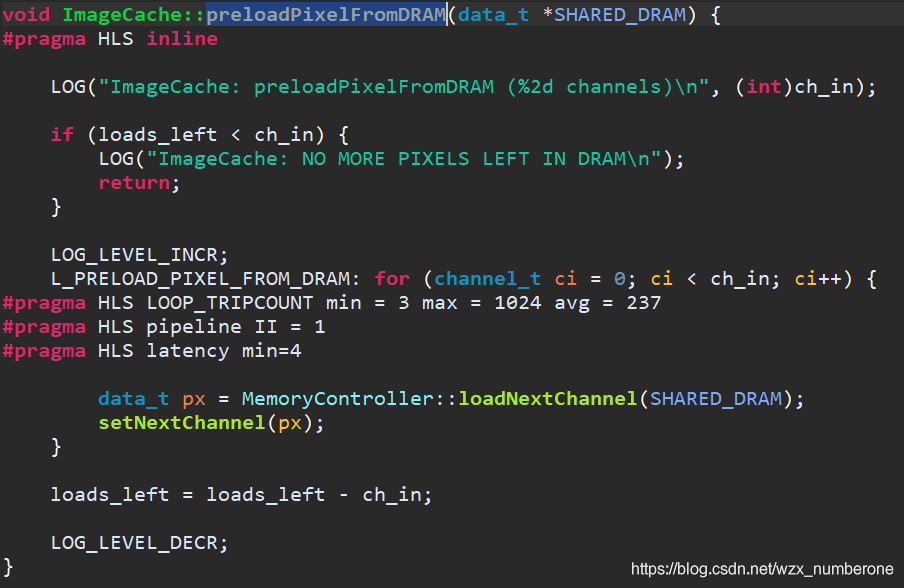
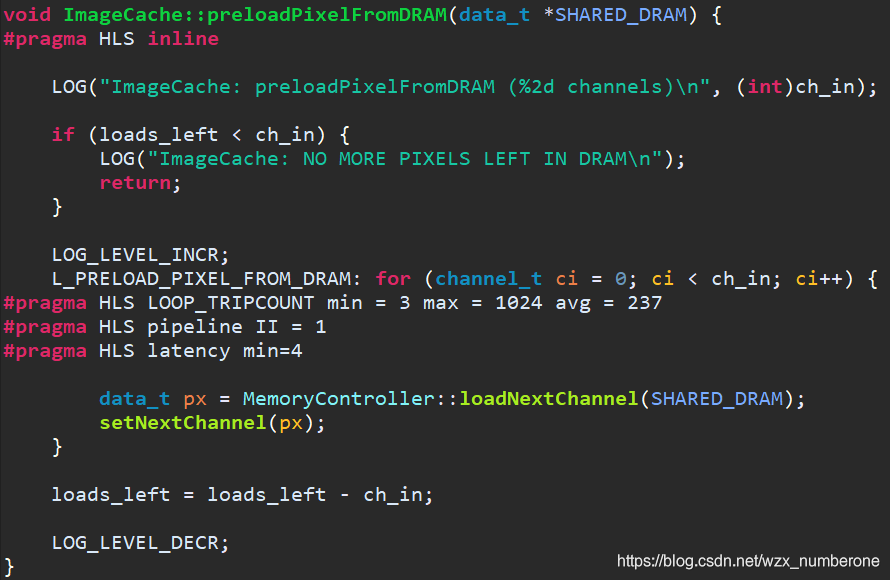
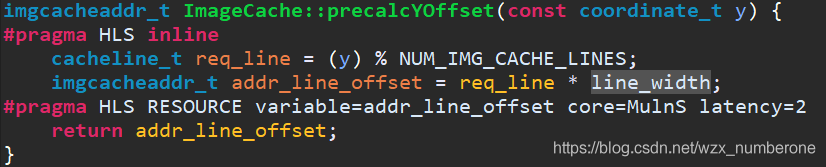
为什么设置NUM_IMG_CACHE_LINES=4
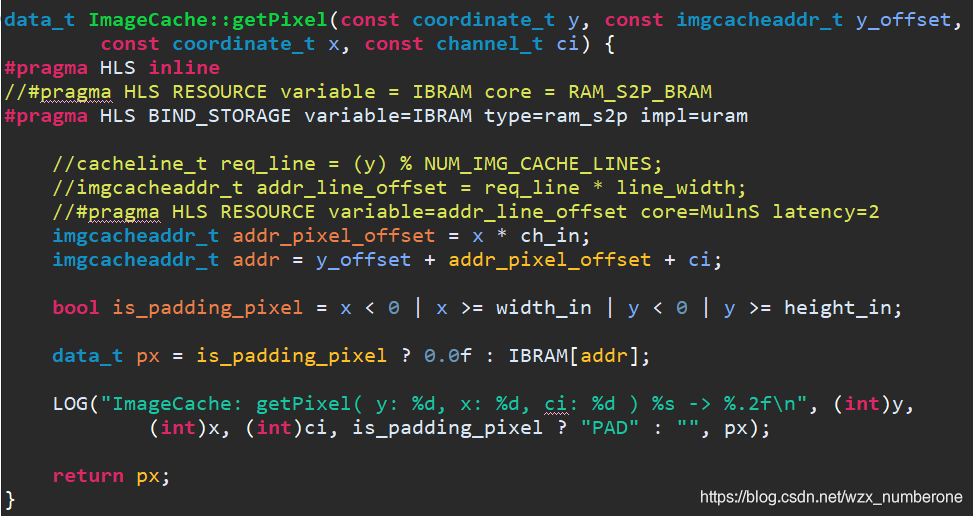
算法
