近期在刚搭建完Hadoop集群时感到有点懵。主机中jps后出现的ResourceManager、SecondaryNameNode、NameNode、NodeManager、Jps以及DataNode是什么鬼。为何主机出现六个进程,而从机只有三个。基于这些问题,今天打算对Hadoop的整体框架做一个简单的整理。(如果想深入了解Hadoop的底层构建,最好去阅读一下Google的三大论文。此处附上博客和论文资料:Google三大论文(一)——Bigtable:一个分布式的结构化数据存储系统)
一、概述
1.1、Hadoop是什么?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等成员组成,其中最基础最重要的两种组成元素为底层用于存储集群中所有存储节点文件的文件系统HDFS(Hadoop Distributed File System)和上层用来执行MapReduce程序的MapReduce引擎。
Hadoop=HDFS+MapReduce+HBase+...
1.2、为什么要开发使用Hadoop?
开发背景:我们处理的数据日趋庞大,无论是入库和查询,都出现性能瓶颈,用户的应用分析结果呈整合趋势,对实时性和响应时间要求越来越高。使用的模型越来越复杂,计算量指数级上升。简单说就是,需要储存的数据量和计算量都非常大,但用户对实时性和响应时间的要求却更高。
所以,人们希望出现一种技术或者工具来解决性能瓶颈,在可见未来不容易出现新瓶颈,并且学习成本尽量低,使得过去所拥有的技能可以平稳过渡。比如SQL、R等,还有转移平台的成本能否控制最低,比如平台软硬件成本,再开发成本,技能再培养成本,维护成本等。(能解决问题,适用时间长、容易上手、转移平台成本低)。而Hadoop就能解决如上问题——分而治之,化繁为简。
1.3、怎么使用Hadoop?
使用Hadoop,其实就是使用Hadoop的各个组件。所以我们要先来了解一下Hadoop的各个组成组件。
二、子项目组成
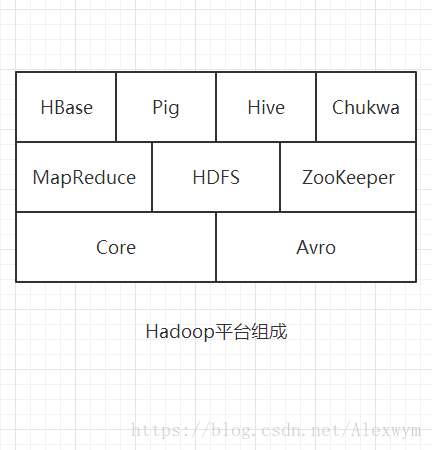
2.1、Core
hadoop的核心代码
2.2、Avro
Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态吐艳可以方便地处理 Avro数据。它是一个新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。
概念:序列化
序列化 (Serialization)将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
目的:1、以某种存储形式使自定义对象持久化;2、将对象从一个地方传递到另一个地方。3、使程序更具维护性。
技术:二进制序列化保持类型保真度,这对于在应用程序的不同调用之间保留对象的状态很有用。例如,通过将对象序列化到剪贴板,可在不同的应用程序之间共享对象。您可以将对象序列化到流、磁盘、内存和网络等等。远程处理使用序列化“通过值”在计算机或应用程序域之间传递对象。
因为后面的MapReduce需要对程序进行划分,同一个对象很可能会被不同的从机调用。
2.3、MapReduce
MapReduce是一种编程模型,一种并行计算框架,用于大规模数据集(大于1TB)的并行运算。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
Map和Reduce的理解:在函数式语言里,map表示对一个列表(List)中的每个元素做计算,reduce表示对一个列表中的每个元素做迭代计算。它们具体的计算是通过传入的函数来实现的,map和reduce提供的是计算的框架。再仔细看,reduce计算中的元素是相关的,比如我想对列表中的所有元素做求和计算,那么列表中的数据至少都是数值。而map中的元素可以是杂乱无章的。在MapReduce里,Map处理的是原始数据,自然是杂乱无章的;到了Reduce阶段,数据是以key后面跟着若干个value来组织的,这些value有相关性。——简单说就是,Map和Reduce都是对数据进行处理,只不过Map处理的数据是无关的,而Reduce处理的数据是相关的。
2.4、HDFS
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
2.5、Zookeeper
Zookeeper是一个高效的分布式协调服务,可以提供配置信息管理、命名、分布式同步、集群管理、数据库切换等服务。它不适合用来存储大量信息,可以用来存储一些配置、发布与订阅等少量信息。Hadoop、Storm、消息中间件、RPC服务框架、分布式数据库同步系统,这些都是Zookeeper的应用场景。
Zookeeper集群中节点个数一般为奇数个(>=3),若集群中Master挂掉,剩余节点个数在半数以上时,就可以推举新的主节点,继续对外提供服务。它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper负责服务器节点和进程间的通信,是一个协调工具,因为Hadoop的几乎每个子项目都是用动物做logo,故这个协调软件叫动物园管理员。
2.6、HBase
HBase是一个开源的,基于列存储模型的分布式数据库。分布式NoSQL列数据库,类似谷歌公司BigTable。
HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
2.7、Pig
Apache Pig 是一个高级过程语言,适合于使用 Hadoop 和 MapReduce 平台来查询大型半结构化数据集。通过允许对分布式数据集进行类似 SQL 的查询,Pig 可以简化 Hadoop 的使用。
它基于Hadoop的大规模数据分析平台,为复杂的海量数据并行计算提供了一个简易的操作和编程接口。因为hadoop是Java写的,为了方便其他对Java语言不熟悉的程序员,于是提供了Pig这个轻量级的语言,用户可以使用Pig用于数据分析和处理,系统会自动把它转化为MapReduce程序。
2.8、Hive
Hive是构建于hadoop之上的数据仓库,通过一种类SQL语言HiveQL为用户提供数据的归纳、查询和分析等功能。是基于Hadoop的一个工具,提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
2.9、Chukwa
chukwa 是一个开源的用于监控大型分布式系统的数据收集系统。这是构建在 hadoop 的 hdfs 和 map/reduce 框架之上的,继承了 hadoop 的可伸缩性和健壮性。Chukwa 还包含了一个强大和灵活的工具集,可用于展示、监控和分析已收集的数据。
三、Hadoop架构
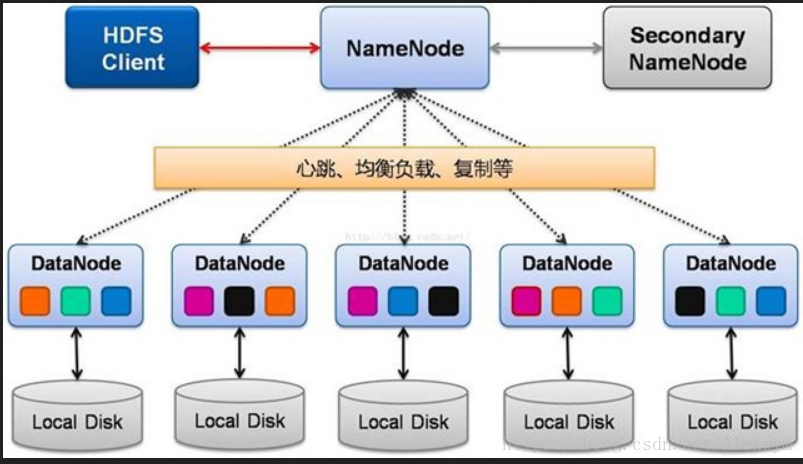
支柱一——HDFS集群的组成:NameNode(管理者)+SecondaryNameNode(助理)+DataNode(工作者)
3.1、NameNode
NameNode也叫名称节点,它管理文件系统的命名空间,维护着文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。对整个分布式文件系统进行总控制,会纪录所有的元数据分布存储的状态信息。比如文件是如何分割成数据块的,以及这些数据块被存储到哪些节点上,还有对内存和I/O进行集中管理。用户首先会访问Namenode,获取文件分布的状态信息,然后访问相应的节点,把文件拿到。
整个HDFS可存储的文件数受限于NameNode的内存大小。
不过这是个单点,如果NameNode宕机,那么整个集群就瘫痪了。
3.2、Secondary Namenode
Secondary NameNode,该部分主要是定时对NameNode数据进行备份,这样尽量降低NameNode崩溃之后,导致数据的丢失,其实所作的工作就是从NameNode获得fsimage(命名空间镜像文件)和edits(编辑日志文件)把二者重新合并然后发给NameNode,这样,既能减轻NameNode的负担又能保险地备份。
3.3、DataNode
数据节点,提供真实文件数据的存储服务。每台从服务器节点都运行一个,负责把HDFS数据块读、写到本地文件系统。
支柱二——MapReduce,包括两个后台应用:JobTracker(总经理——分配任务)+TaskTracker(监督员——监督任务完成情况)。
MapReduce采用Master/Slave结构。
*Master:是整个集群的唯一的全局管理者,功能包括:作业管理、状态监控和任务调度等,即MapReduce中的JobTracker。
*Slave:负责任务的执行和任务状态的回报,即MapReduce中的TaskTracker。
3.4、JobTracker
作业跟踪器,运行在主节点(Namenode)上的一个很重要的进程,是MapReduce体系的调度器。用于处理作业(用户提交的代码)的后台程序,决定有哪些文件参与作业的处理,然后把作业切割成为一个个的小task,并把它们分配到所需要的数据所在的子节点。(程序跟着数据跑,这样子就可以避免对数据进行重新分配)
3.5、TaskTracker
任务跟踪器,运行在每个slave节点上,与datanode结合(代码与数据一起的原则),管理各自节点上的task(由jobtracker分配),每个节点只有一个tasktracker,但一个tasktracker可以启动多个JVM,用于并行执行map或reduce任务,它与jobtracker交互通信,可以告知jobtracker子任务完成情况。
两者联系:JobTracker会给TaskTracker下达各种命令,主要包括:启动任务(LaunchTaskAction)、提交任务(CommitTaskAction)、杀死任务(KillTaskAction)、杀死作业(KillJobAction)和重新初始化(TaskTrackerReinitAction)。
四、总结
我们再回到一开始的那两个问题。
1.为何主机出现六个进程,而从机只有三个?
这个问题现在应该很容易理解了,简答说就是Master比Slave多了负责管理的进程。
2.主机中jps后出现的ResourceManager、SecondaryNameNode、NameNode、NodeManager、Jps以及DataNode是什么鬼?
这里我们只解析了Hadoop的两个重要支柱——HDFS和MapReduce。
其中Jps(Java Virtual Machine Process Status Tool)是JDK 1.5提供的一个显示当前所有java进程pid的命令,简单实用,非常适合在linux/unix平台上简单察看当前java JVM进程的一些简单情况。
NameNode、SecondaryNameNode、DataNode是HDFS的组成进程。
resourcemanager和nodemanager是YARN的组成进程。YARN总体上仍然是master/slave结构,在整个资源管理框架中,resourcemanager为master,nodemanager是slave。
总而言之,一句话——Hadoop由许多子平台组成,而每一个子平台又由不同的进程构成。