Attention(续)
Multi-Head Attention
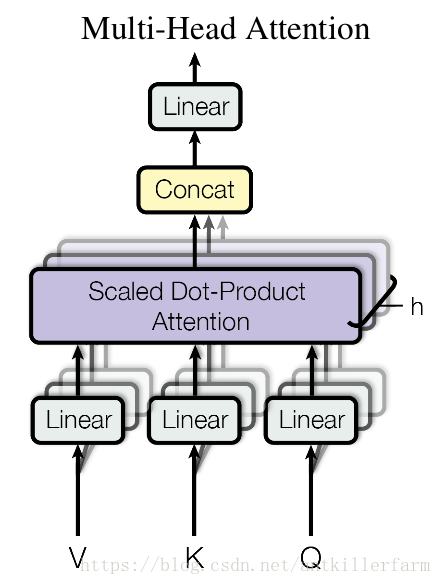
这个是Google提出的新概念,是Attention机制的完善。不过从形式上看,它其实就再简单不过了,就是把Q,K,V通过参数矩阵映射一下,然后再做Attention,把这个过程重复做h次,结果拼接起来就行了,可谓“大道至简”了。具体来说:
所谓“多头”(Multi-Head),就是只多做几次同样的事情(参数不共享),然后把结果拼接。
Self Attention
到目前为止,对Attention层的描述都是一般化的,我们可以落实一些应用。比如,如果做阅读理解的话,Q可以是篇章的词向量序列,取K=V为问题的词向量序列,那么输出就是所谓的Aligned Question Embedding。
而在Google的论文中,大部分的Attention都是Self Attention,即“自注意力”,或者叫内部注意力。
所谓Self Attention,其实就是Attention(X,X,X),X就是前面说的输入序列。也就是说,在序列内部做Attention,寻找序列内部的联系。
Position Embedding
然而,只要稍微思考一下就会发现,这样的模型并不能捕捉序列的顺序!换句话说,如果将K,V按行打乱顺序(相当于句子中的词序打乱),那么Attention的结果还是一样的。这就表明了,到目前为止,Attention模型顶多是一个非常精妙的“词袋模型”而已。
这问题就比较严重了,大家知道,对于时间序列来说,尤其是对于NLP中的任务来说,顺序是很重要的信息,它代表着局部甚至是全局的结构,学习不到顺序信息,那么效果将会大打折扣(比如机器翻译中,有可能只把每个词都翻译出来了,但是不能组织成合理的句子)。
于是Google再祭出了一招——Position Embedding,也就是“位置向量”,将每个位置编号,然后每个编号对应一个向量,通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了。
Hard Attention
论文:
《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》
我们之前所描述的传统的Attention Mechanism是Soft Attention。Soft Attention是参数化的(Parameterization),因此可导,可以被嵌入到模型中去,直接训练。梯度可以经过Attention Mechanism模块,反向传播到模型其他部分。
相反,Hard Attention是一个随机的过程。Hard Attention不会选择整个encoder的输出做为其输入,Hard Attention会依概率Si来采样输入端的隐状态一部分来进行计算,而不是整个encoder的隐状态。为了实现梯度的反向传播,需要采用蒙特卡洛采样的方法来估计模块的梯度。
两种Attention Mechanism都有各自的优势,但目前更多的研究和应用还是更倾向于使用Soft Attention,因为其可以直接求导,进行梯度反向传播。
Local Attention
论文:
《Effective Approaches to Attention-based Neural Machine Translation》
Thang Luong,越南人,Stanford博士(2016),现为Google研究员。导师是Christopher Manning。
个人主页:
https://nlp.stanford.edu/~lmthang/Christopher Manning,澳大利亚人,Stanford博士(1994),现为Stanford教授。从事NLP近三十年,率先将统计方法引入NLP。
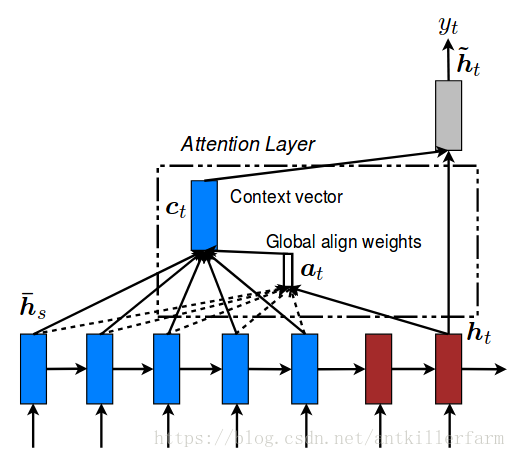
传统的Attention model中,所有的hidden state都被用于计算Context vector的权重,因此也叫做Global Attention。
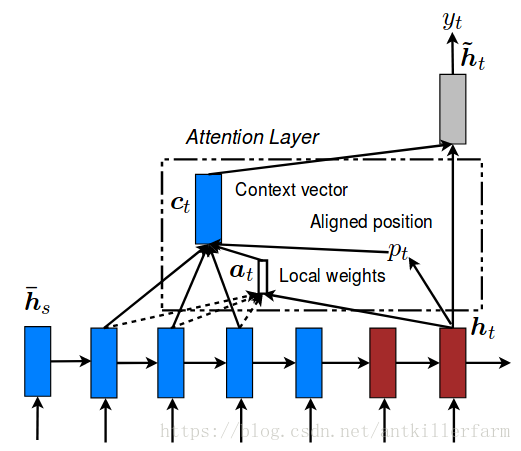
Local Attention:Global Attention有一个明显的缺点就是,每一次,encoder端的所有hidden state都要参与计算,这样做计算开销会比较大,特别是当encoder的句子偏长,比如,一段话或者一篇文章,效率偏低。因此,为了提高效率,Local Attention应运而生。
Local Attention是一种介于Kelvin Xu所提出的Soft Attention和Hard Attention之间的一种Attention方式,即把两种方式结合起来。其结构如下图所示。
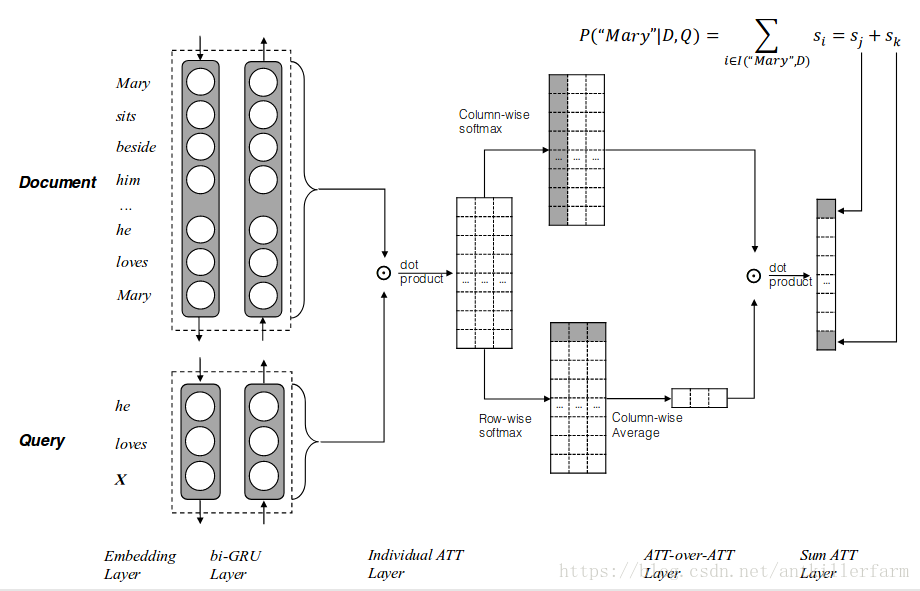
Attention over Attention
《Attention-over-Attention Neural Networks for Reading Comprehension》
总结
从最初的原始Attention,到后面的各种示例,不难看出Attention实际上是一个大箩筐,凡是不好用CNN、RNN、FC概括的累计乘加,基本都可冠以XX Attention的名义。
虽然,权重的确代表了Attention的程度,然而直接叫累计乘加,似乎更接近操作本身一些。
考虑到神经网络的各种操作基本都是累计乘加的变种,因此,Attention is All You Need实际上是很自然的结论,你总可以对Attention进行修改,让它实现CNN、RNN、FC的效果。
这点在AI芯片领域尤为突出,无论IC架构差异如何巨大,硬件底层基本就是乘累加器。
Transformer
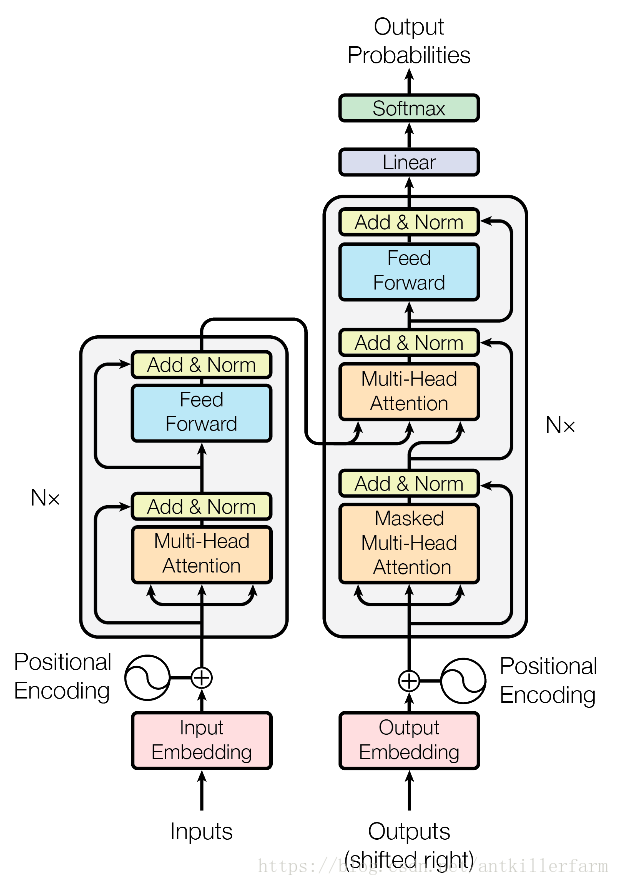
Attention的介绍到此为止,但《Attention is All You Need》的传奇继续,该文不仅提出了两种Attention模块,而且还提出了如下图所示的Transformer模型。该模型主要用于NMT领域,由于Attention不依赖上一刻的数据,同时精度也不弱于LSTM,因此有很好并行计算特性,在工业界得到了广泛应用。阿里巴巴和搜狗目前的NMT方案都是基于Transformer模型的。
参考:
https://mp.weixin.qq.com/s/HquT_mKm7x_rbDGz4Voqpw
阿里巴巴最新实践:TVM+TensorFlow提高神经机器翻译性能
https://mp.weixin.qq.com/s/S_xhaDrOaPe38ZvDLWl4dg
从技术到产品,搜狗为我们解读了神经机器翻译的现状
参考
http://geek.csdn.net/news/detail/106118
Attention and Augmented Recurrent Neural Networks译文
http://blog.csdn.net/rtygbwwwerr/article/details/50548311
Neural Turing Machines
http://www.robots.ox.ac.uk/~tvg/publications/talks/NeuralTuringMachines.pdf
Neural Turing Machines
http://blog.csdn.net/malefactor/article/details/50550211
自然语言处理中的Attention Model
https://yq.aliyun.com/articles/65356
图文结合详解深度学习Memory & Attention
http://www.cosmosshadow.com/ml/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/2016/03/08/Attention.html
Attention
https://mp.weixin.qq.com/s/b5d_jNNDB_a_VFdT3J3Vog
通俗易懂理解Attention机制
http://geek.csdn.net/news/detail/50558
深度学习和自然语言处理中的attention和memory机制
https://zhuanlan.zhihu.com/p/25928551
用深度学习(CNN RNN Attention)解决大规模文本分类问题-综述和实践
http://blog.csdn.net/leo_xu06/article/details/53491400
视觉注意力的循环神经网络模型
https://mp.weixin.qq.com/s/XrlveG0kwij2qNL45TZdBg
Attention的另类用法
https://zhuanlan.zhihu.com/p/31547842
深度学习中Attention Mechanism详细介绍:原理、分类及应用
https://zhuanlan.zhihu.com/p/32089282
Attention学习笔记
https://mp.weixin.qq.com/s/0yb-YRGe-q4-vpKpuE4D_w
多种注意力机制互补完成VQA(视觉问答)
https://mp.weixin.qq.com/s/LQ7uv0-AakkHE5b17yemqw
Awni Hannun:序列模型Attention Model中的问题与挑战
https://mp.weixin.qq.com/s/xr_1ZYbvADMMwgxLEAflCw
如何在语言翻译中理解Attention Mechanism?
https://mp.weixin.qq.com/s/Nyq_36aFmQYRWdpgbgxpuA
将注意力机制引入RNN,解决5大应用领域的序列预测问题
https://mp.weixin.qq.com/s/2gxp7A38epQWoy7wK8Nl6A
谷歌翻译最新突破,“关注机制”让机器读懂词与词的联系
https://mp.weixin.qq.com/s/g2PcmsDW9ixUCh_yP8W-Vg
各类Seq2Seq模型对比及《Attention Is All You Need》中技术详解
https://mp.weixin.qq.com/s/FtI94xY6a8TEvFCHfjMnmA
小组讨论谷歌机器翻译Attention is All You Need
https://mp.weixin.qq.com/s/SqIMkiP1IZMGWzwZWGOI7w
谈谈神经网络的注意机制和使用方法
https://mp.weixin.qq.com/s/POYTh4Jf7HttxoLhrHZQhw
基于双向注意力机制视觉问答pyTorch实现
https://mp.weixin.qq.com/s/EMCZHuvk5dOV_Rz00GkJMA
近年火爆的Attention模型,它的套路这里都有!
https://mp.weixin.qq.com/s/y_hIhdJ1EN7D3p2PVaoZwA
阿里北大提出新attention建模框架,一个模型预测多种行为
https://mp.weixin.qq.com/s/Yq3S4WrsQRQC06GvRgGjTQ
打入神经网络思维内部
https://mp.weixin.qq.com/s/MJ1578NdTKbjU-j3Uuo9Ww
基于文档级问答任务的新注意力模型
https://mp.weixin.qq.com/s/C4f0N_bVWU9YPY34t-HAEA
UNC&Adobe提出模块化注意力模型MAttNet,解决指示表达的理解问题
https://mp.weixin.qq.com/s/V3brXuey7Gear0f_KAdq2A
基于注意力机制的交易上下文感知推荐,悉尼科技大学和电子科技大学最新工作
http://mp.weixin.qq.com/s/Bt6EMD4opHCnRoHKYitsUA
结合人类视觉注意力进行图像分类
https://zhuanlan.zhihu.com/p/27464080
从《Convolutional Sequence to Sequence Learning》到《Attention Is All You Need》
http://www.cnblogs.com/robert-dlut/p/8638283.html
自然语言处理中的自注意力机制!
https://mp.weixin.qq.com/s/l4HN0_VzaiO-DwtNp9cLVA
循环注意力区域实现图像多标签分类
https://mp.weixin.qq.com/s/zhZLK4pgJzQXN49YkYnSjA
自适应注意力机制在Image Caption中的应用
https://mp.weixin.qq.com/s/uvr-G5-_lKpyfyn5g7ES0w
基于注意力机制,机器之心带你理解与训练神经机器翻译系统
https://mp.weixin.qq.com/s/ANpBFnsLXTIiW6WHzGrv2g
自注意力机制学习句子embedding
https://mp.weixin.qq.com/s/49fQX8yiOIwDyof3PD01rA
CMU&谷歌大脑提出新型问答模型QANet:仅使用卷积和自注意力,性能大大优于RNN
https://mp.weixin.qq.com/s/c64XucML13OwI26_UE9xDQ
滴滴披露语音识别新进展:基于Attention显著提升中文识别率