文章目录
简介
Spark Application 提交运行时部署模式 Deploy Mode ,表示的是 Driver Program 运行的地方。要么是提交应用的 Client:client ,要么就是集群中从节点(Standalone:Worker,YARN:NodeManager):cluster 。
默认值为 client,当在实际的开发环境中,尤其是生产环境,使用 cluster 部署模式提交应用运行。
Client 模式演示讲解
以 Spark Application 运行到 Standalone 集群上为例,前面提交运行圆周率PI或者词频统计 WordCount 程序时,默认 DeployMode 为Client,表示应用 Driver Program 运行在提交应用 Client 主机上(启动 JVM Process 进程),示意图如下:
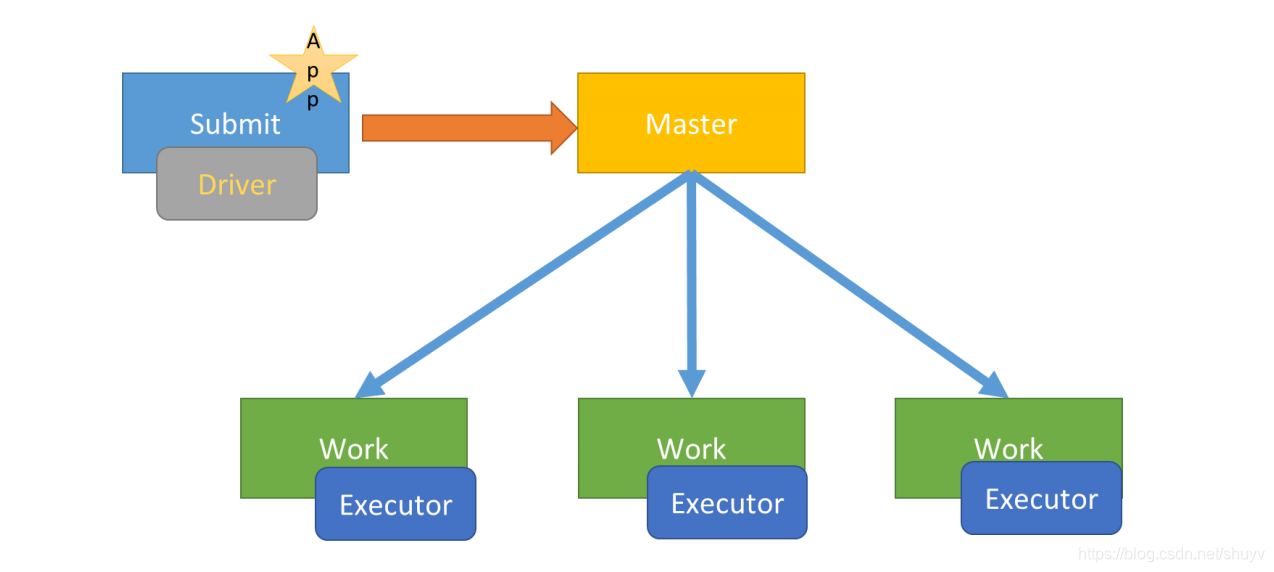
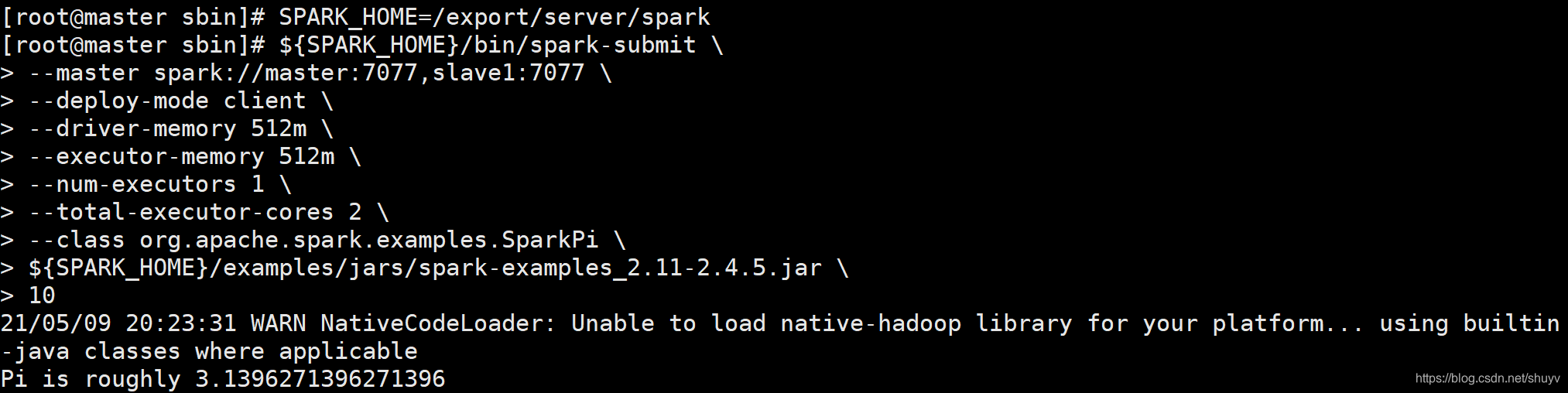
运行圆周率PI程序,采用 client 模式,命令如下:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master spark://master:7077,slave1:7077 \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 1 \
--total-executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \
10
Cluster 模式演示讲解
如果采用cluster模式运行应用,应用Driver Program运行在集群从节点Worker某台机器上,示意图如下:
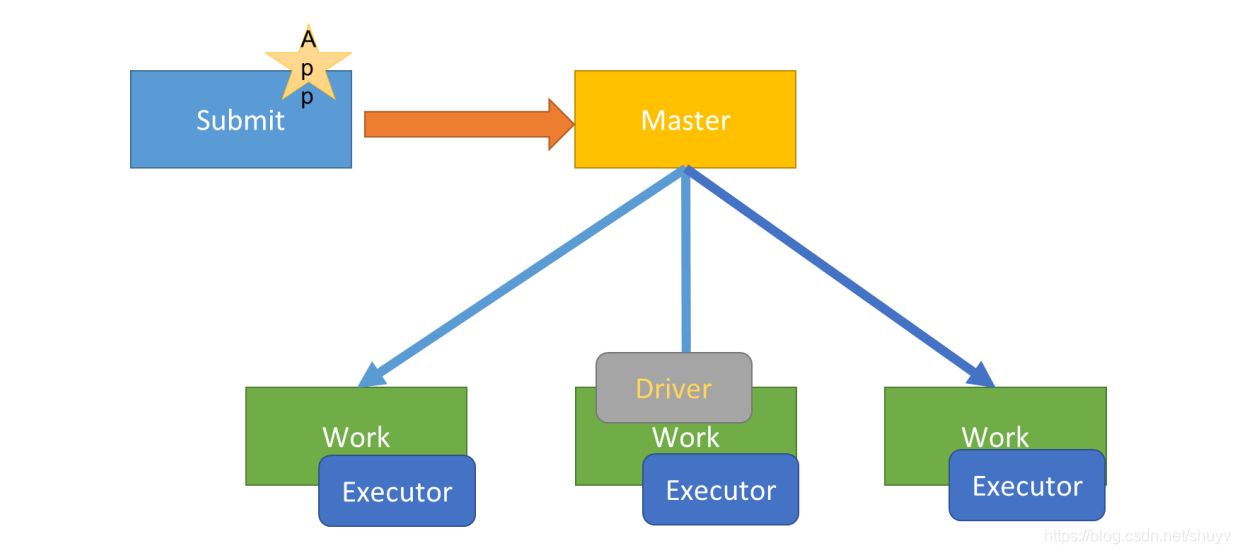
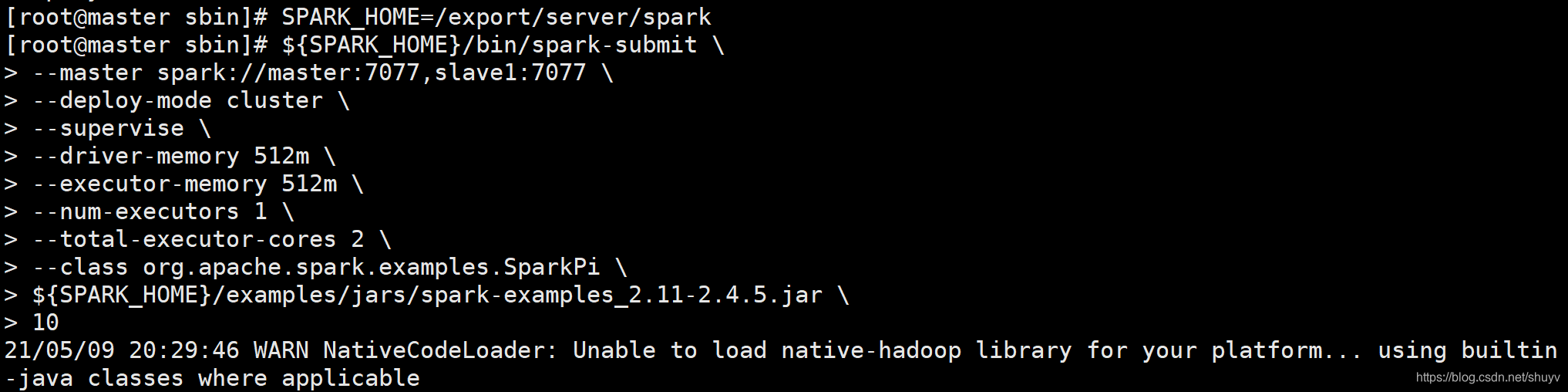
假设运行圆周率PI程序,采用cluster模式,命令如下:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master spark://master:7077,slave1:7077 \
--deploy-mode cluster \
--supervise \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 1 \
--total-executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \
10
运行时注意区别!!!
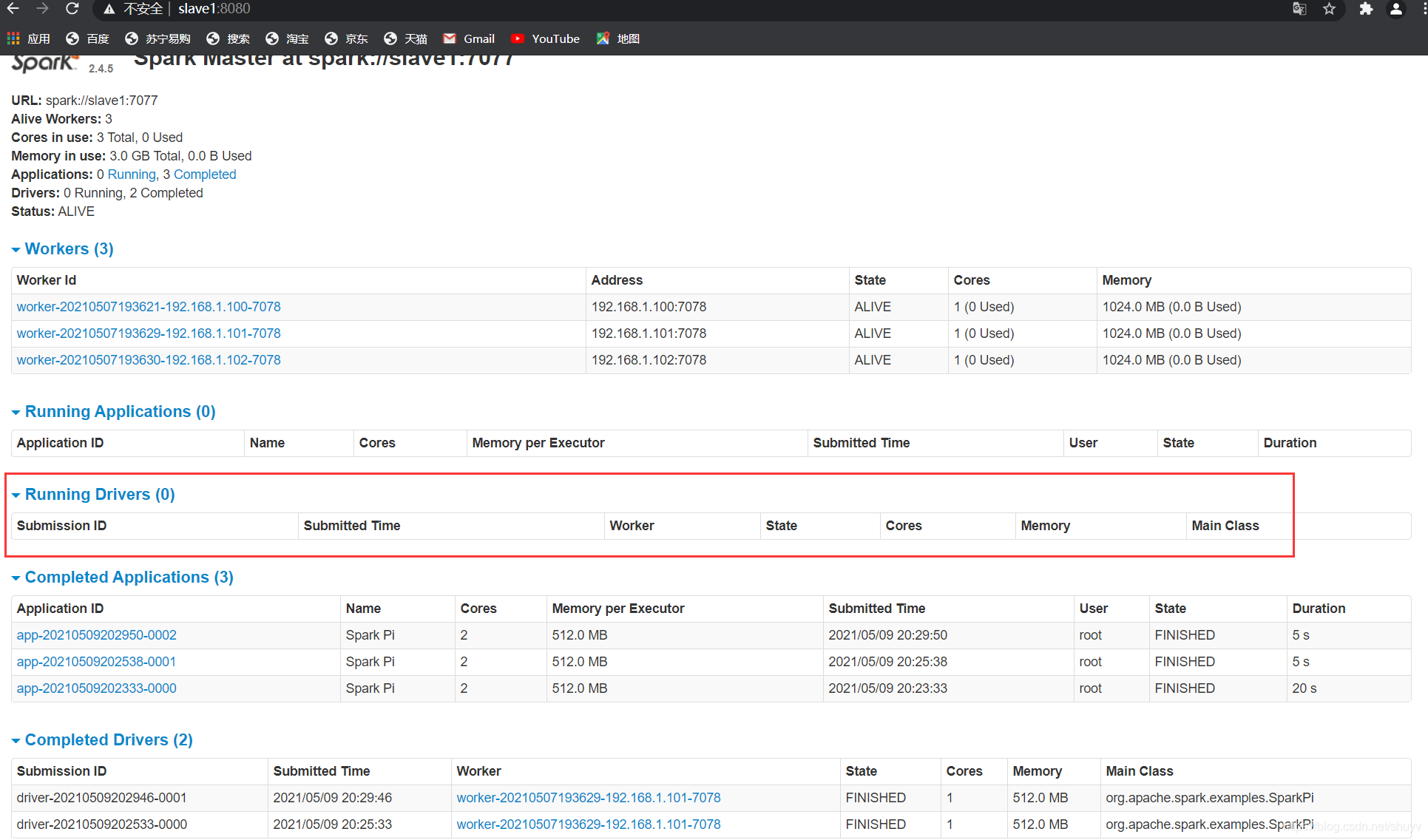
Cilent模式和Cluster模式的不同之处
Cluster和Client模式最最本质的区别是:Driver程序运行在哪里。
- cluster模式:生产环境中使用该模式
- Driver程序在YARN集群当中
- 应用的运行结果不能在客户端显示
- client模式:学习测试时使用,开发用不了
- Driver运行在Client上的SparkSubmit进程中
- 应用程序运行结果会在客户端显示
Spark on YARN
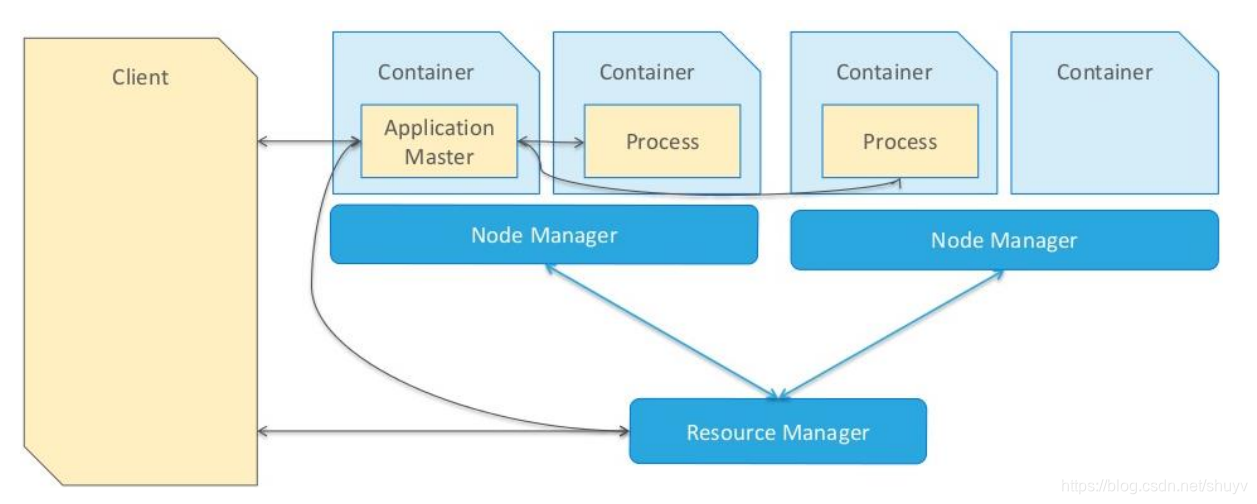
应用程序运行 YARN 组成:
- 1.AppMaster,应用管理者,负责整个应用运行时资源申请(RM)及 Task 运行和监控。
- 2.启动进程 Process,运行 Task 任务,比如运行 MapReduce 程序,此时这些进程就是 MapTask 和 ReduceTask,都是运行在 Container 容器中。
Spark 应用运行集群 组成:
- 1.Driver Program,应用管理者,负责整个应用运行时资源申请及 Task 运行和监控。申请资源运行 Executor 。
- 2.Executor,进程运行 Task 任务,和缓存数据。
当应用提交运行到Hadoop YARN上时,包含两个部分:应用管理者AppMaster和于运行应用进程Process(如MapReduce程序MapTask和ReduceTask任务),如下图所示:
Spark Application提交运行在集群上时,应用架构有两部分组成:Driver Program(资源申请和调度Job执行)和Executors(运行Job中Task任务和缓存数据),都是JVM Process进程:
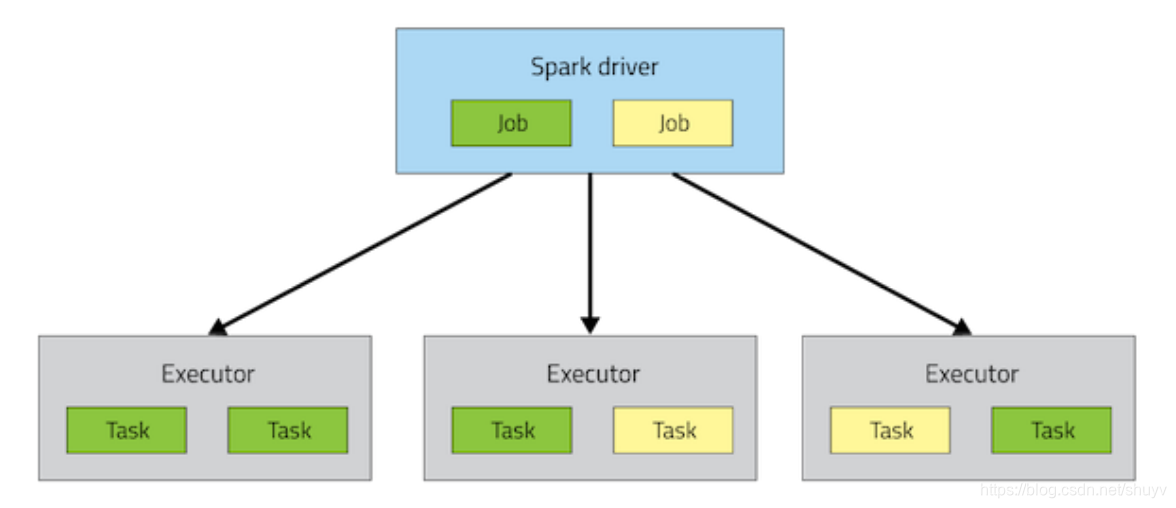
所以Spark Application运行在YARN上时,采用不同DeployMode时架构不一样,企业实际生产环境还是以cluster模式为主,client模式用于开发测试,两者的区别面试中常问。
YARN Client 模式演示说明
在YARN Client模式下,Driver在任务提交的本地机器上运行,示意图如下:

具体流程步骤如下:
- 1.Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster;
- 2.、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申 请Executor内存;
- 3.ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程;
- 4.Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数;
- 5.之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分Stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行。
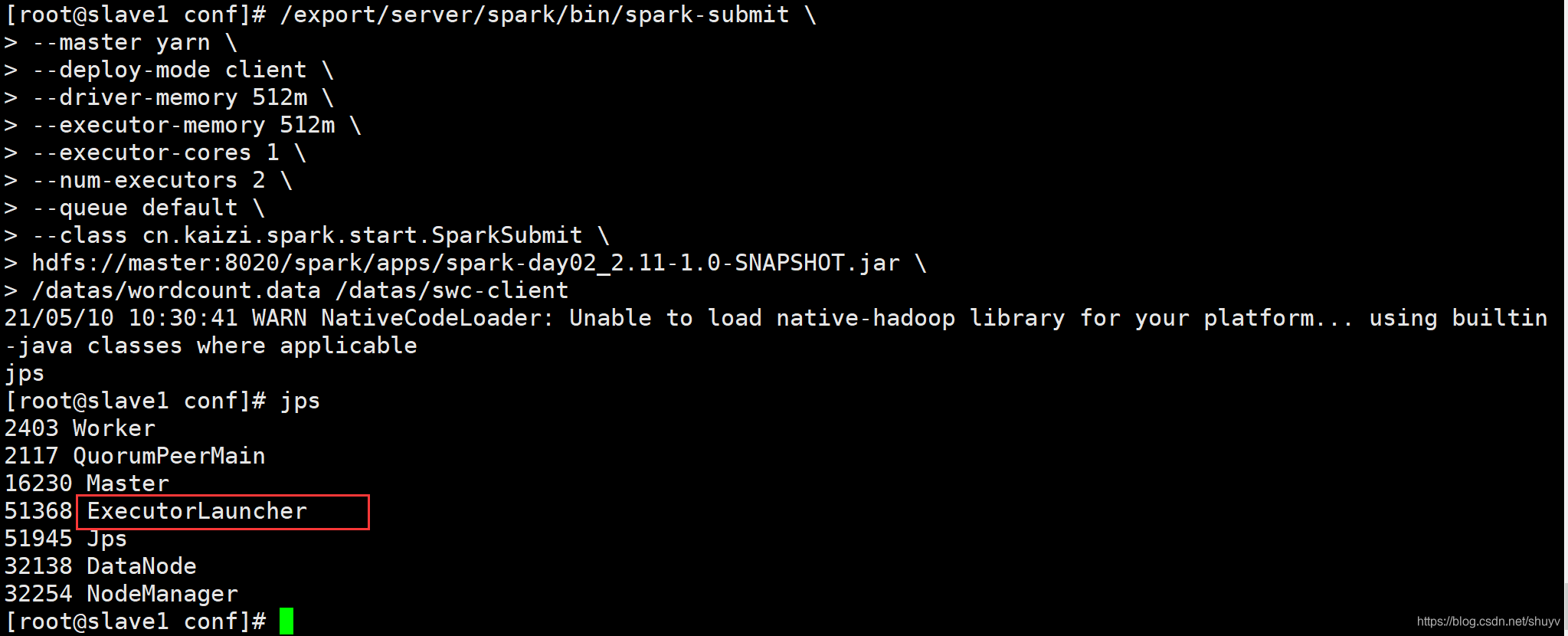
以运行词频统计WordCount程序为例,提交命令如下:
/export/server/spark/bin/spark-submit \
--master yarn \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
--num-executors 2 \
--queue default \
--class cn.kaizi.spark.start.SparkSubmit \
hdfs://master:8020/spark/apps/spark-day02_2.11-1.0-SNAPSHOT.jar \
/datas/wordcount.data /datas/swc-client
YARN Cluster 模式演示说明
在YARN Cluster模式下,Driver运行在NodeManager Contanier中,此时Driver与AppMaster合为一体,示意图如下:
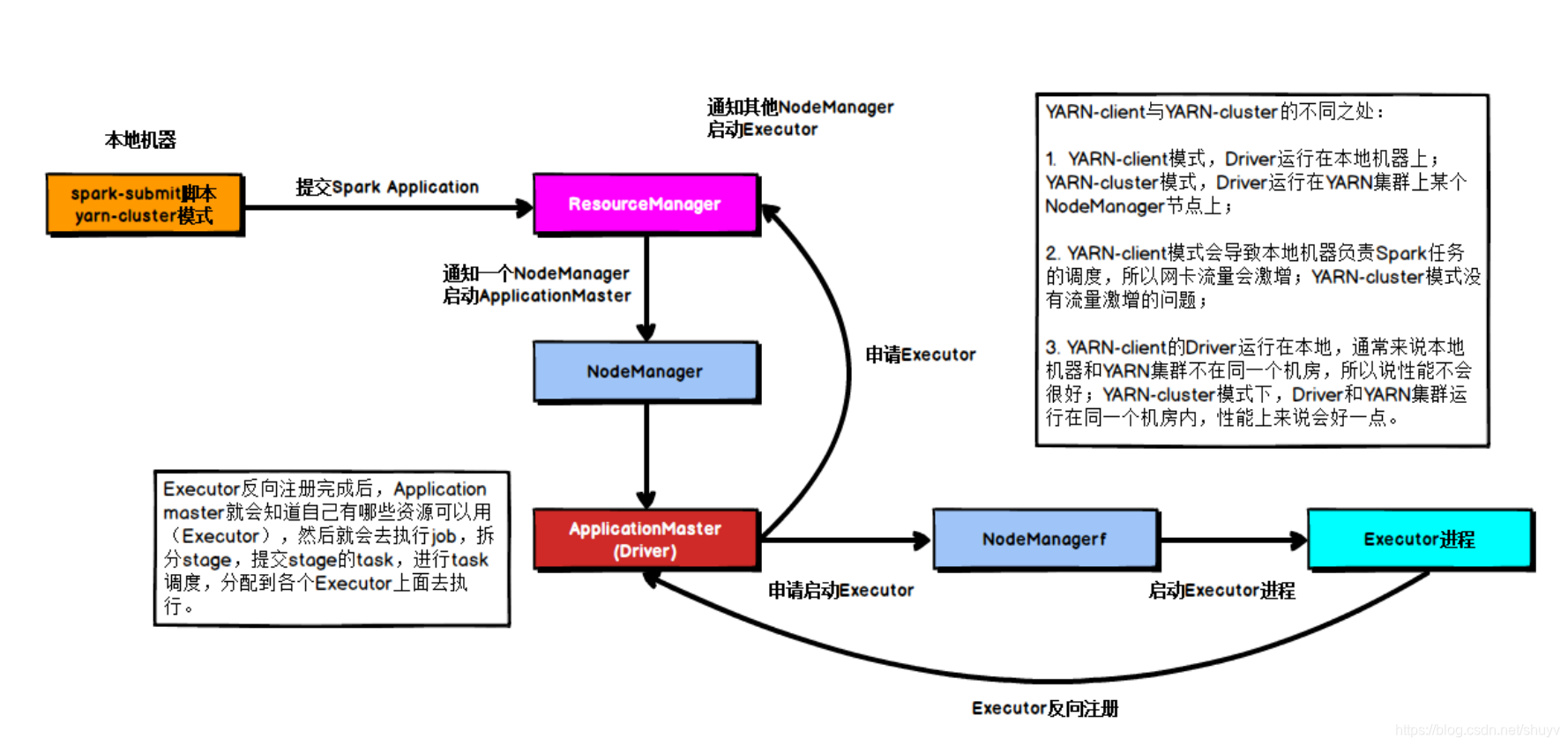
具体流程步骤如下:
- 1.任务提交后会和ResourceManager通讯申请启动ApplicationMaster;
- 2.、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver;
- 3.Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后在合适的NodeManager上启动Executor进程;
- 4.Executor进程启动后会向Driver反向注册;
- 5.Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行;
以运行词频统计WordCount程序为例,提交命令如下:
/export/server/spark/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
--num-executors 2 \
--queue default \
--class cn.kaizi.spark.start.SparkSubmit \
hdfs://master:8020/spark/apps/spark-day02_2.11-1.0-SNAPSHOT.jar \
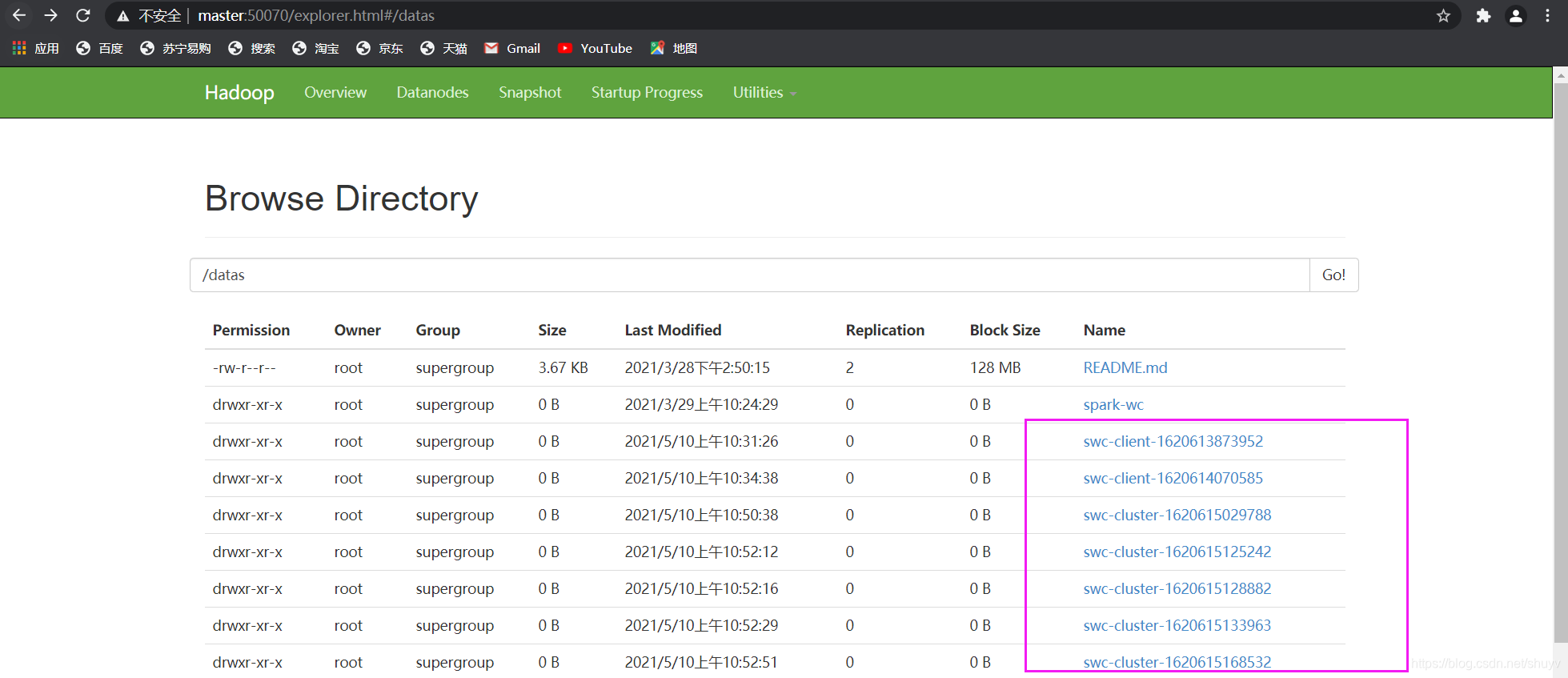
/datas/wordcount.data /datas/swc-cluster
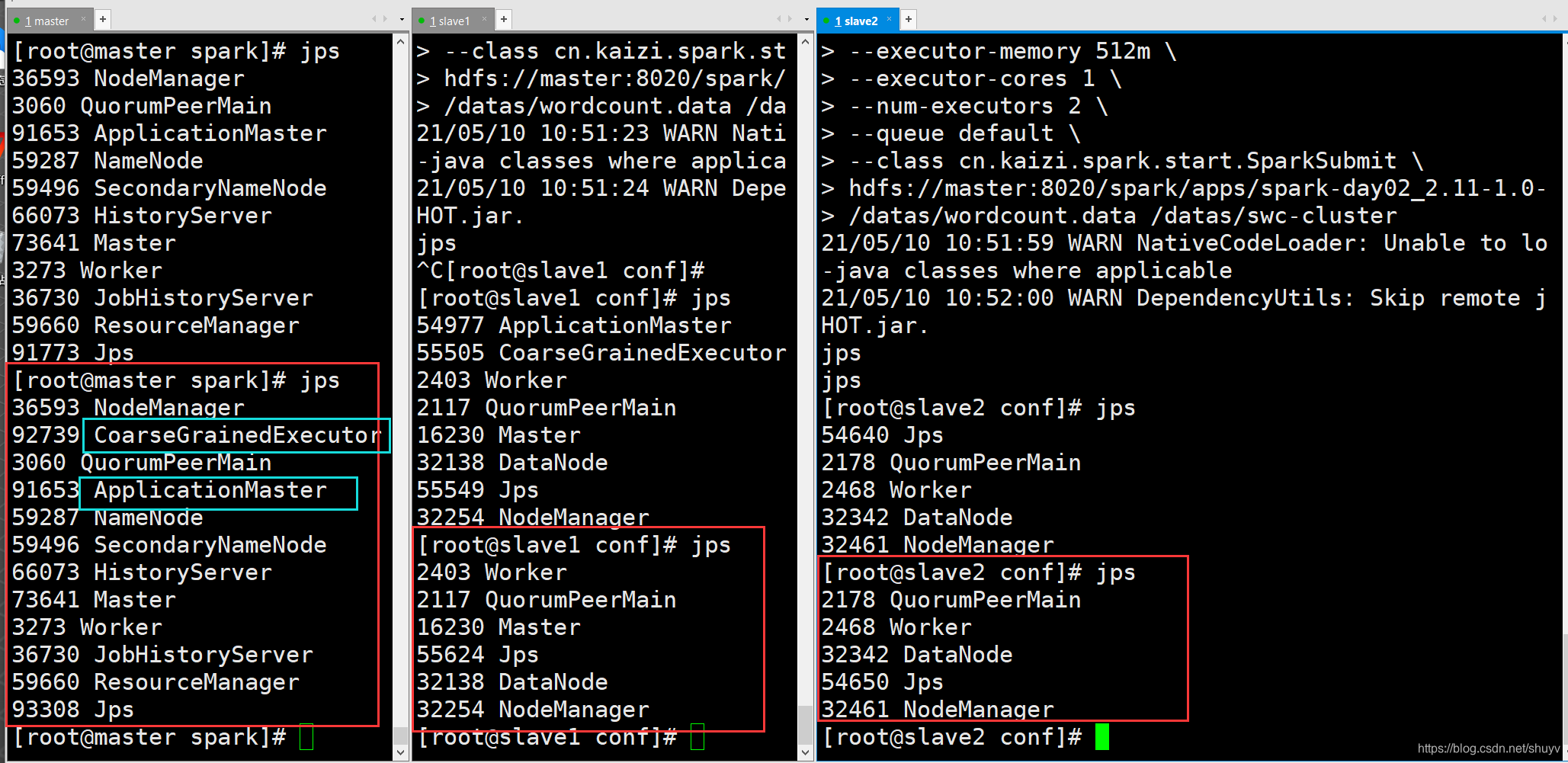
我在 slave2 中运行上述命令:(同时查看三台主机的jps进程情况,注意蓝色标注内容)
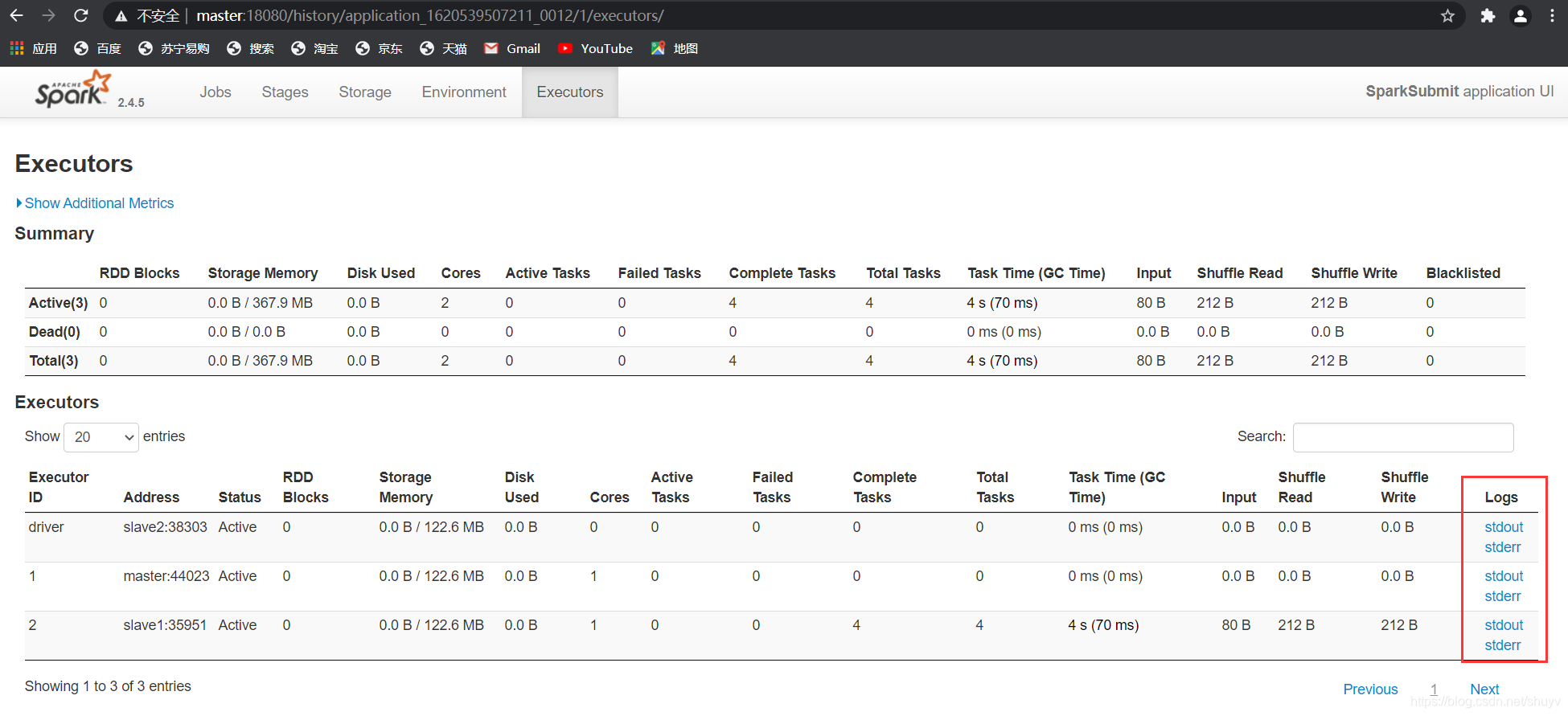
通过历史服务器对比的产看俩种模式下的executor情况
如下是 client 模式下的,发现 driver 不可以查看日志信息。
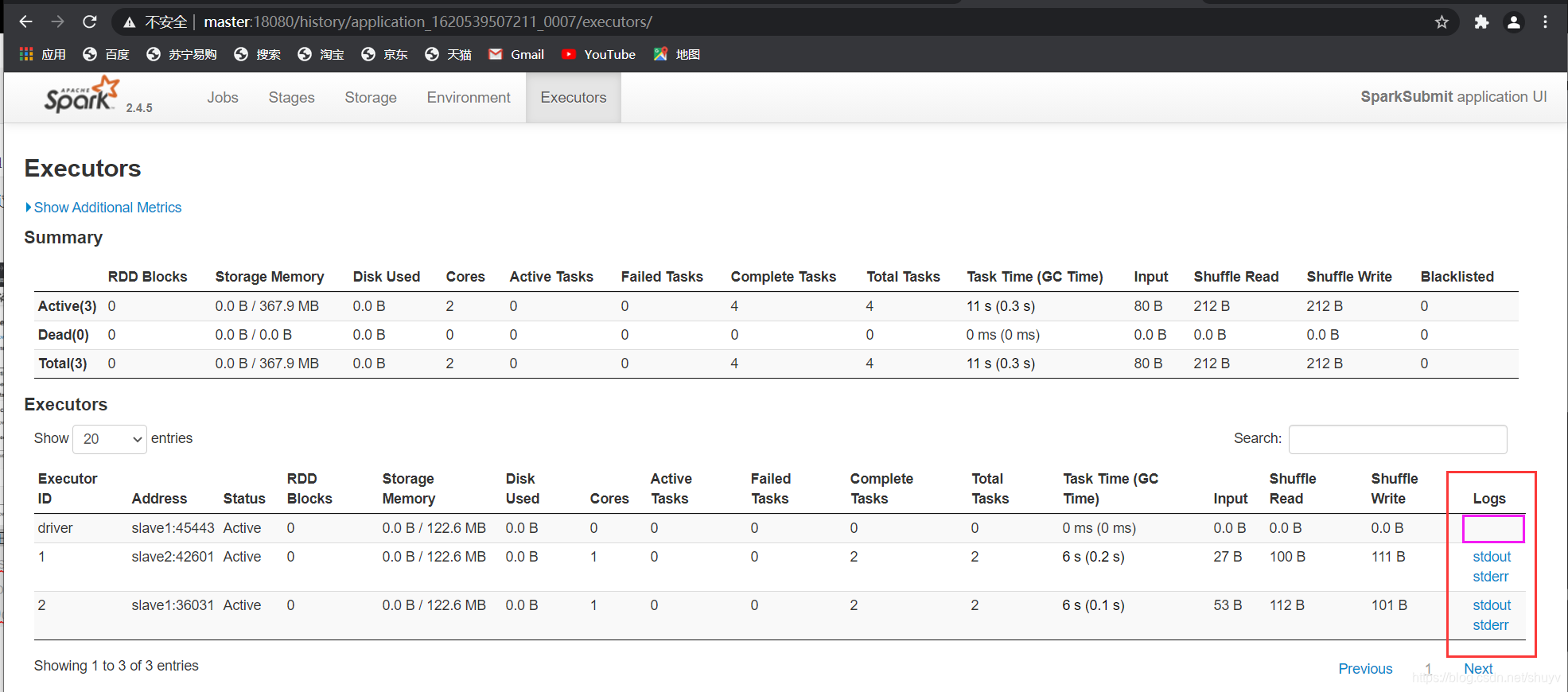
对比查看 cluster 模式下 driver 可以查看日志信息。
程序的main函数执行情况
Spark Application应用程序运行时,无论client还是cluster部署模式DeployMode,当Driver Program和Executors启动完成以后,就要开始执行应用程序中MAIN函数的代码,以词频统计WordCount程序为例剖析讲解。
如下图:是之前做的 WordCount 程序案例代码
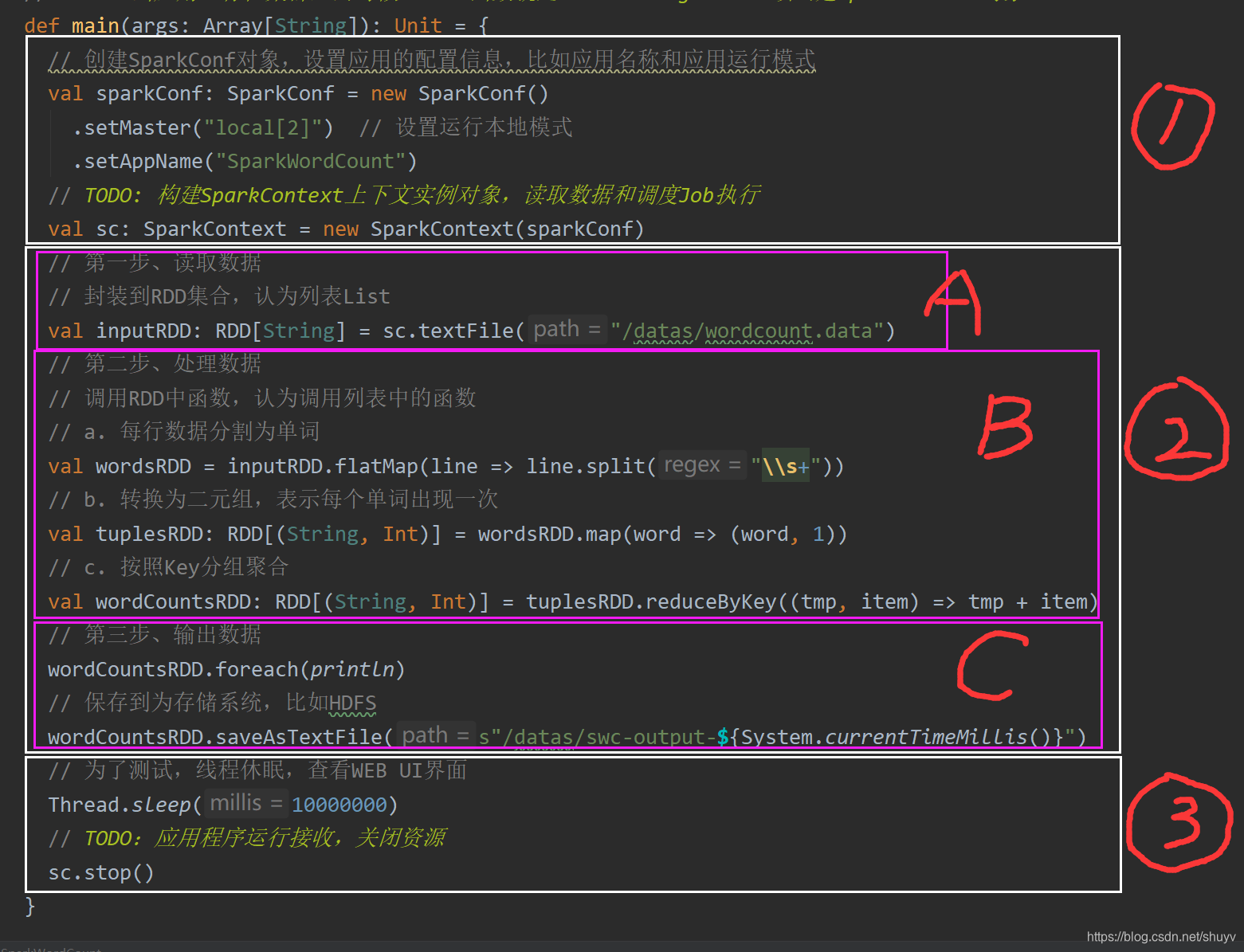
- 1.构建 SparkContext 对象和关闭 SparkContext 资源,都是在 Driver Program 中执行,上述图中①和③都是。如下图解释:

- 2.上图中②的加载数据据【A】、处理数据【B】和输出数据【C】代码,都在 Executors 上执行,从 WEB UI 监控页面可以看到此 Job(RDD#action触发一个Job)对应DAG图,如下图所示:
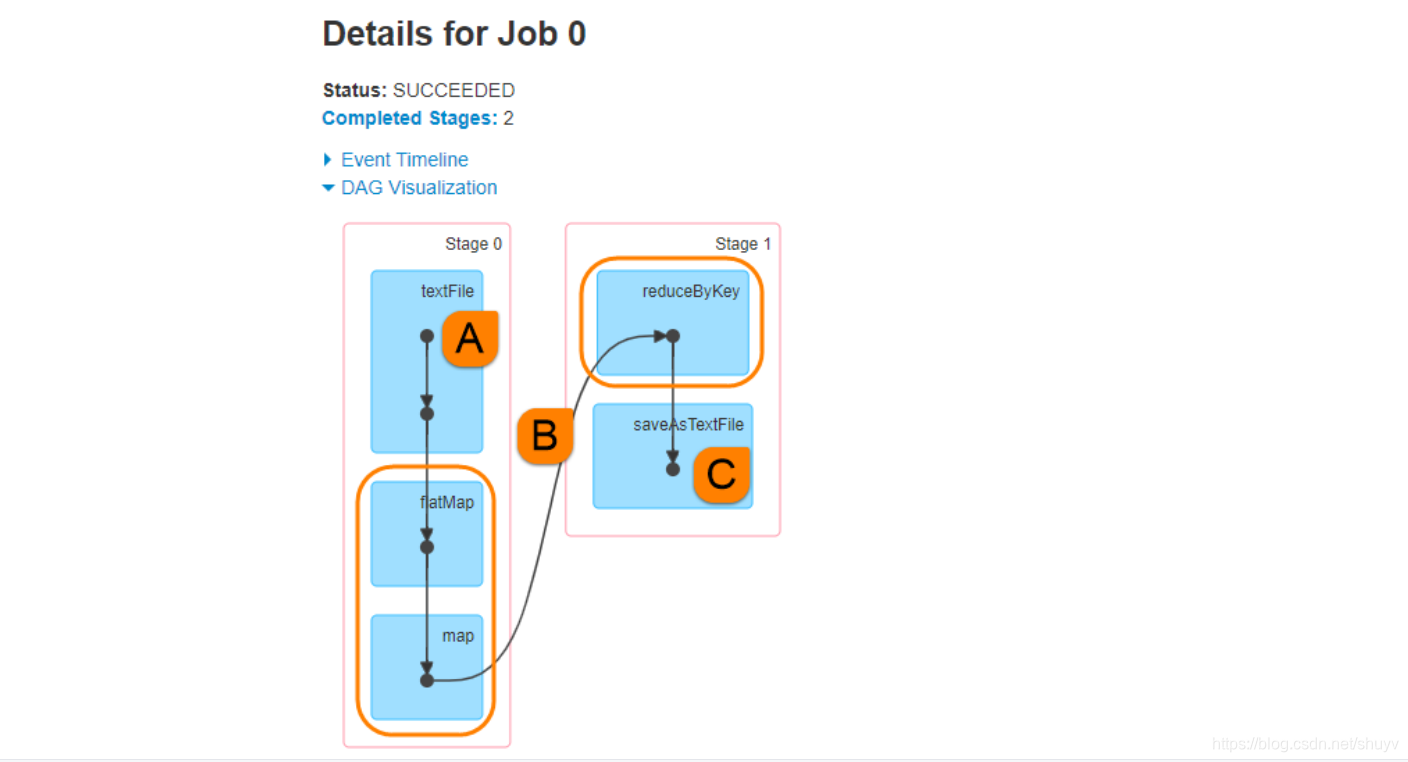
将结果数据 resultRDD调用 saveAsTextFile 方法,保存数据到外部存储系统中,代码在 Executor 中执行的。但是如果 resultRDD 调用 take、collect 或 count 方法时,获取到最终结果数据返回给 Driver , 代码如下:
val resultArray: Array[(String, Int)] = resultRDD.collect()
resultArray.foreach(println)
运行应用程序时,将数组resultArray数据打印到标准输出,Driver Program端日志打印结果:

综上所述Spark Application中Job执行有两个主要点:
- 1.RDD输出函数分类两类
- 第一类:返回值给Driver Progam,比如count、first、take、collect等
- 第二类:没有返回值,比如直接打印结果、保存至外部存储系统(HDFS文件)等
- 2.在Job中从读取数据封装为RDD和一切RDD调用方法都是在Executor中执行,其他代码都是在Driver Program中执行
- SparkContext创建与关闭、其他变量创建等在Driver Program中执行
- RDD调用函数都是在Executors中执行
补充
当Spark Application运行在集群上时,主要有四个部分组成,如下示意图:
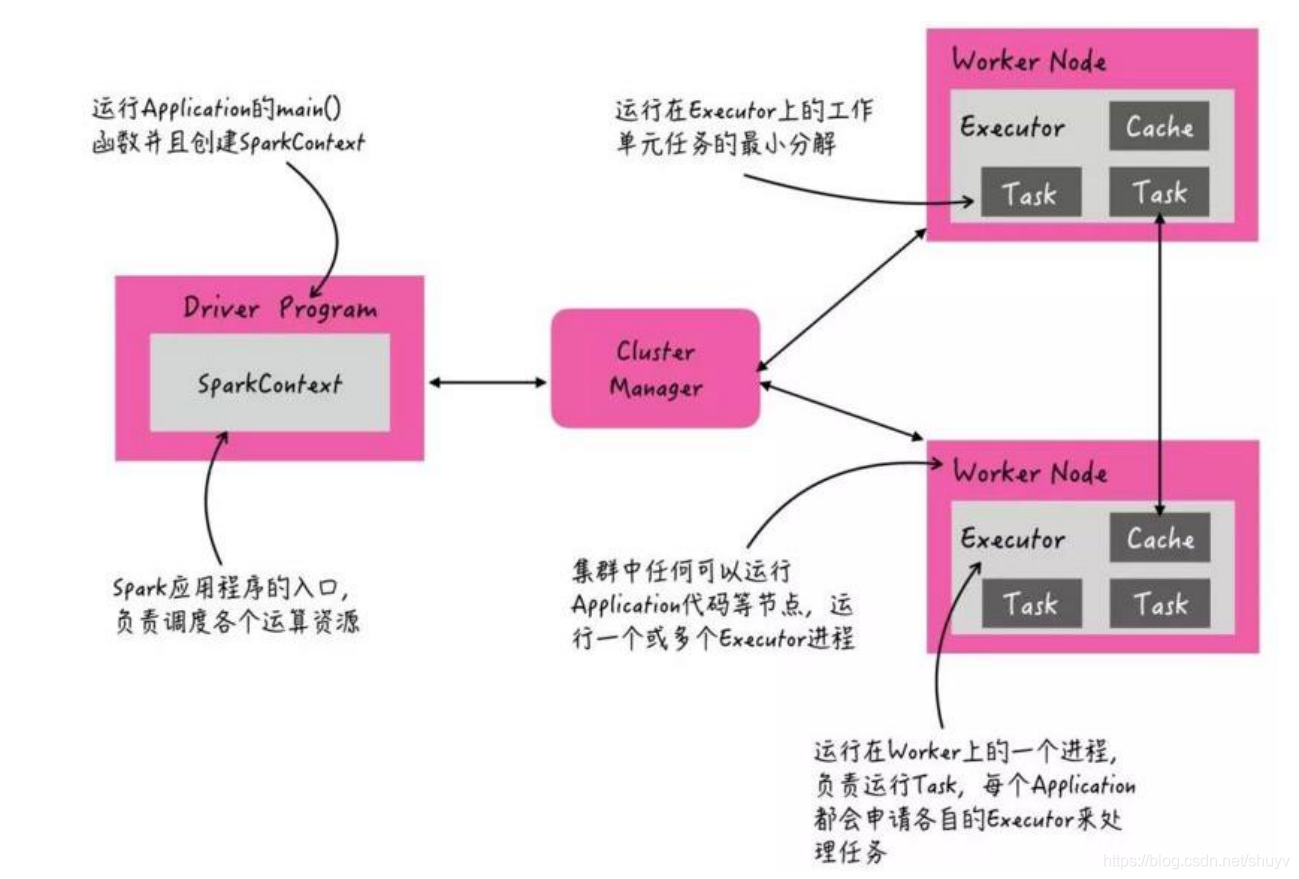
- 1.Driver:是一个JVM Process 进程,编写的Spark应用程序就运行在Driver上,由Driver进程执行。
- 2.Master(ResourceManager):是一个JVM Process 进程,主要负责资源的调度和分配,并进行集群的监控等职责。
- 3.Worker(NodeManager):是一个JVM Process 进程,一个Worker运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算。
- 4.Executor:是一个JVM Process 进程,一个Worker(NodeManager)上可以运行多个Executor,Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算,也就是执行我们对RDD定义的例如map、flatMap、reduce等算子操作。
Spark 支持多种集群管理器(Cluster Manager),取决于传递给 SparkContext 的MASTER环境变量的值:local、spark、yarn,区别如下:
| Master URL | Meaning |
|---|---|
| local | 在本地运行,只有一个工作进程,无并行计算能力。 |
| local[K] | 在本地运行,有K个工作进程,通常设置K为机器的CPU核心数量。 |
| local[*] | 在本地运行,工作进程数量等于机器的CPU核心数量。 |
| spark://HOST:PORT | 以Standalone模式运行,这是Spark自身提供的集群运行模式,默认端口号: 7077。Client部署模式:7077 。Cluster部署模式:6066 |
| mesos://HOST:PORT | 在Mesos集群上运行,Driver进程和Worker进程运行在Mesos集群上,部署模式必须使用固定值:–deploy-mode cluster。 |
| yarn-client --master yarn --deploy-mode client | 在Yarn集群上运行,Driver进程在本地,Executor进程在Yarn集群上,部署模式必须使用固定值:–deploy-mode client。Yarn集群地址必须在HADOOP_CONF_DIR or YARN_CONF_DIR变量里定义。 |
| yarn-cluster --master yarn --deploy-mode cluster | 在Yarn集群上运行,Driver进程在Yarn集群上,Executor进程也在Yarn集群上,部署模式必须使用固定值:–deploy-mode cluster。Yarn集群地址必须在HADOOP_CONF_DIR or YARN_CONF_DIR变量里定义。 |