目录
网络配置
192.168.81.157 node1 master
192.168.81.158 node2 slave1
192.168.81.159 node3 slave2
相同的配置先在一个节点上配置,配置完成后复制到其它节点上。
vi /etc/hosts
192.168.81.157 node1
192.168.81.158 node2
192.168.81.159 node3
分别对应每一台主机修改主机名;
依次修改所有节点 node[1-3]上分别执行
hostnamectl set-hostname node1
拷贝文件到其他节点
for a in {2..3} ; do scp /etc/hosts node$a:/etc/hosts ; done
SSH 免密码登录
1.在集群node1的 /etc/ssh/sshd_config 文件
vi /etc/ssh/sshd_config
RSAAuthentication yes #开启私钥验证 PubkeyAuthentication yes #开启公钥验证
2.将集群node1 修改后的 /etc/ssh/sshd_config 通过 scp 命令复制发送到集群的每一个节点
for a in {2..3} ; do scp /etc/ssh/sshd_config node$a:/etc/ssh/sshd_config ; done
3.生成公钥、私钥
1.在集群的每一个节点节点输入命令 ssh-keygen -t rsa -P '',生成 key,一律回车
ssh-keygen -t rsa -P ''
4.在集群的node1 节点输入命令
将集群每一个节点的公钥id_rsa.pub放入到自己的认证文件中authorized_keys;
for a in {1..3}; do ssh root@node$a cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys; done
5.在集群的node1 节点输入命令
将自己的认证文件 authorized_keys 通过 scp 命令复制发送到每一个节点上去: /root/.ssh/authorized_keys`
for a in {2..3}; do scp /root/.ssh/authorized_keys root@node$a:/root/.ssh/authorized_keys ; done
6.在集群的每一个节点节点输入命令
接重启ssh服务
sudo systemctl restart sshd.service
7.验证 ssh 无密登录
开一个其他窗口测试下能否免密登陆
例如:在node3
ssh root@node2
exit 退出
部署
node1机器上
部署/opt/目录
tar xzvf spark-2.4.4-bin-hadoop2.7.tgz
cd spark-2.4.4-bin-hadoop2.7
cp conf/slaves.template conf/slaves
将slave机器名添加上
node2
node3
cp conf/spark-env.sh.template conf/spark-env.sh
所有机器都
yum install -y java-1.8.0-openjdk
vi conf/spark-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.232.b09-0.el7_7.x86_64/jre/
拷贝到其他机器上
for a in {2..3}; do scp -r /opt/spark-2.4.4-bin-hadoop2.7 node$a:/opt ; done
关闭防火墙(各台均执行)
systemctl stop firewalld.service
systemctl disable firewalld
node1机器上启动集群
./sbin/start-all.sh
关闭集群
./sbin/stop-all.sh
netstat -tunlp #看到8080端口已经被监听
浏览器访问页面
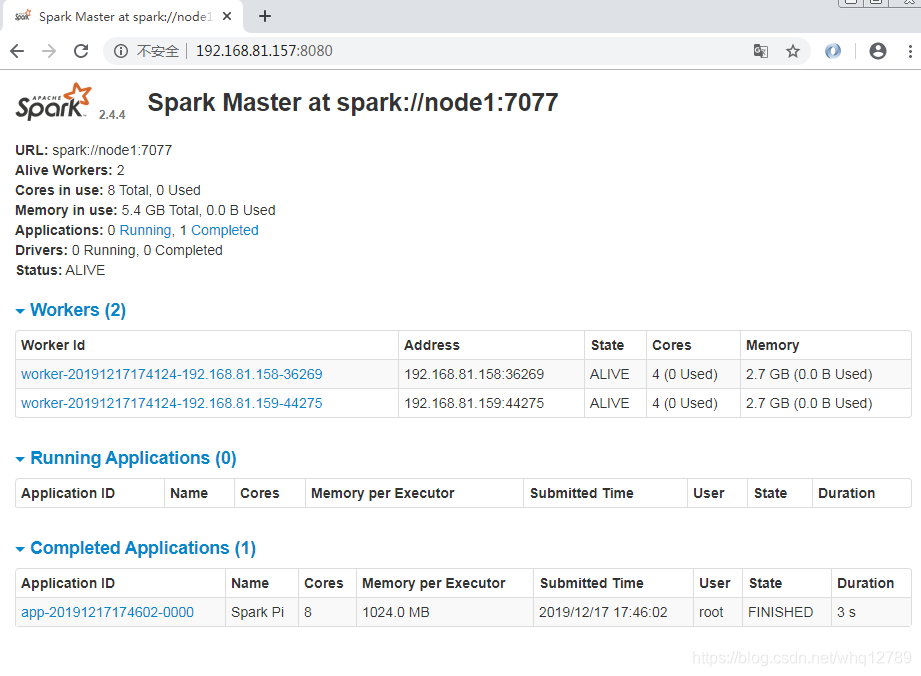
可以看到slave也加入到集群中了。
执行测试
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://node1:7077 --num-executors 2 /opt/spark-2.4.4-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.4.4.jar
……
19/12/17 17:46:05 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 2.072959 s
Pi is roughly 3.141275706378532
……
